DRP: Distilled Reasoning Pruning with Skill-aware Step Decomposition for Efficient Large Reasoning Models
Pith reviewed 2026-05-22 14:06 UTC · model grok-4.3
The pith
Distilled Reasoning Pruning lets student models solve math problems with far fewer tokens while matching or exceeding original accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
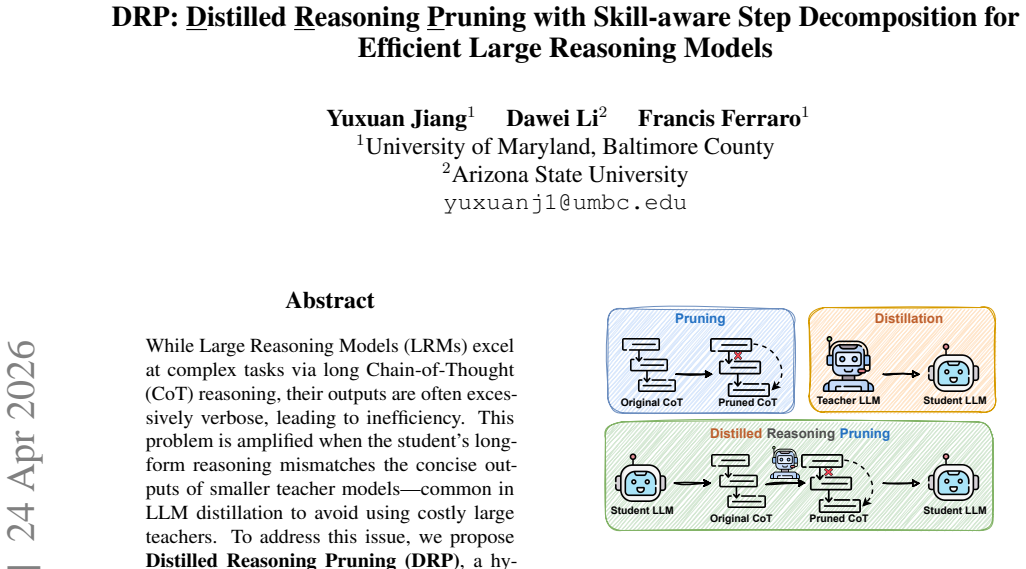
DRP uses a teacher model to perform skill-aware step decomposition and content pruning, then distills the resulting shorter reasoning paths into a student model. This hybrid of inference-time pruning and distillation produces models that reason efficiently and accurately. On GSM8K average token usage falls from 917 to 328 while accuracy rises from 91.7 percent to 94.1 percent; on AIME the method delivers a 43 percent token reduction with no performance drop. Further analysis indicates that aligning the structure of the training chains of thought with the student's reasoning capacity is essential for successful knowledge transfer.
What carries the argument
Skill-aware step decomposition performed by the teacher, which identifies reasoning steps according to required skills and prunes content to create concise paths suitable for distillation to the student.
Load-bearing premise
The teacher model's skill-aware decomposition produces pruned paths that match the student's own reasoning capacity and support effective knowledge transfer during distillation.
What would settle it
Training the same student on unpruned teacher traces versus DRP-pruned traces and finding no measurable gain in token efficiency or accuracy would show the pruning step adds no benefit.
Figures



read the original abstract
While Large Reasoning Models (LRMs) have demonstrated success in complex reasoning tasks through long chain-of-thought (CoT) reasoning, their inference often involves excessively verbose reasoning traces, resulting in substantial inefficiency. To address this, we propose Distilled Reasoning Pruning (DRP), a hybrid framework that combines inference-time pruning with tuning-based distillation, two widely used strategies for efficient reasoning. DRP uses a teacher model to perform skill-aware step decomposition and content pruning, and then distills the pruned reasoning paths into a student model, enabling it to reason both efficiently and accurately. Across several challenging mathematical reasoning datasets, we find that models trained with DRP achieve substantial improvements in token efficiency without sacrificing accuracy. Specifically, DRP reduces average token usage on GSM8K from 917 to 328 while improving accuracy from 91.7% to 94.1%, and achieves a 43% token reduction on AIME with no performance drop. Further analysis shows that aligning the reasoning structure of training CoTs with the student's reasoning capacity is critical for effective knowledge transfer and performance gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Distilled Reasoning Pruning (DRP), a hybrid framework that uses a teacher model to perform skill-aware step decomposition and content pruning on chain-of-thought traces, followed by distillation of the resulting shorter paths into a student model. The central empirical claim is that this alignment of reasoning structure with student capacity yields large gains in token efficiency on mathematical reasoning benchmarks without accuracy loss: average tokens on GSM8K drop from 917 to 328 while accuracy rises from 91.7% to 94.1%, and a 43% token reduction is achieved on AIME with no performance drop.
Significance. If the results are robust, DRP offers a practical route to more efficient inference in large reasoning models by combining pruning and distillation. The emphasis on matching pruned CoT structure to the student's capacity is a useful conceptual contribution, and the reported token reductions on standard benchmarks (GSM8K, AIME) are large enough to be practically relevant for deployment. The work ships concrete empirical measurements rather than self-referential quantities.
major comments (1)
- [§4 and Table 1] §4 (Experimental Setup) and Table 1: the headline token and accuracy numbers (917→328 tokens and 91.7%→94.1% on GSM8K; 43% reduction on AIME) are presented without reported variance across seeds, statistical significance tests, or an explicit description of the exact pruning criteria and baseline models used for comparison. These details are load-bearing for assessing whether the claimed efficiency gains are reproducible and attributable to the skill-aware decomposition rather than other factors.
minor comments (2)
- [§3.2] The abstract and §3.2 use the phrase 'skill-aware step decomposition' without a concise formal definition or pseudocode; adding a short algorithmic sketch would improve clarity for readers.
- [Figure 2] Figure 2 (or equivalent ablation plot) would benefit from error bars or multiple runs to visually support the claim that alignment with student capacity is critical.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We agree that additional details on reproducibility are valuable and will incorporate them in the revised manuscript.
read point-by-point responses
-
Referee: [§4 and Table 1] §4 (Experimental Setup) and Table 1: the headline token and accuracy numbers (917→328 tokens and 91.7%→94.1% on GSM8K; 43% reduction on AIME) are presented without reported variance across seeds, statistical significance tests, or an explicit description of the exact pruning criteria and baseline models used for comparison. These details are load-bearing for assessing whether the claimed efficiency gains are reproducible and attributable to the skill-aware decomposition rather than other factors.
Authors: We agree that variance, significance testing, and explicit criteria strengthen the claims. In the revised manuscript we will add: (i) results averaged over three random seeds with standard deviations for token count and accuracy on both GSM8K and AIME; (ii) paired t-tests (or Wilcoxon tests) reporting p-values against the main baselines; and (iii) an expanded §4 that lists the precise skill-aware decomposition rules (step-level skill tags and pruning thresholds), content-pruning heuristics, and the exact baseline configurations (unpruned LRM, standard CoT distillation, and length-only pruning). These additions will make clear that the reported gains arise from capacity-aligned structure rather than other factors. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical hybrid framework (DRP) combining teacher-driven skill-aware pruning with distillation, then evaluates the resulting student models on standard benchmarks (GSM8K, AIME). All reported outcomes—token reductions from 917 to 328 on GSM8K with accuracy rising from 91.7% to 94.1%, and 43% reduction on AIME—are direct measurements from training and inference runs, not quantities derived from equations or parameters that are defined in terms of the target results themselves. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the method or results chain; the central claims rest on external benchmark performance rather than internal redefinition or renaming of inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DRP uses a teacher model to perform skill-aware step decomposition and content pruning, and then distills the pruned reasoning paths into a student model
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
aligning the reasoning structure of training CoTs with the student's reasoning capacity is critical
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
Cornerstones or Stumbling Blocks? Deciphering the Rock Tokens in On-Policy Distillation
Persistent 'Rock Tokens' in on-policy distillation resist teacher corrections, consume large gradient norms, yet add negligible value to reasoning, allowing targeted bypassing to streamline alignment.
-
Post Reasoning: Improving the Performance of Non-Thinking Models at No Cost
Post-Reasoning boosts LLM accuracy by reversing the usual answer-after-reasoning order, delivering mean relative gains of 17.37% across 117 model-benchmark pairs with zero extra cost.
-
MUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality
MUSE decouples reconstruction and semantic learning in visual tokenization via topological orthogonality, yielding SOTA generation quality and improved semantic performance over its teacher model.
-
ActorMind: Emulating Human Actor Reasoning for Speech Role-Playing
ActorMind is a four-agent chain-of-thought framework that emulates human actors to produce spontaneous, emotion-infused speech responses for role-playing scenarios.
-
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
A survey organizing techniques to achieve efficient reasoning in LLMs by shortening chain-of-thought outputs.
-
Reinforcement Learning for Scalable and Trustworthy Intelligent Systems
Reinforcement learning is advanced for communication-efficient federated optimization and for preference-aligned, contextually safe policies in large language models.
Reference graph
Works this paper leans on
-
[1]
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning. arXiv preprint arXiv:2504.01296. Yuxuan Jiang and Francis Ferraro. 2024. Memo- rization over reasoning? exposing and mitigating verbatim memorization in large language models’ character understanding evaluation. arXiv preprint arXiv:2412.14368. Dawei Li, Bohan Jiang, Liangjie Hu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Let’s verify step by step. In The Twelfth Inter- national Conference on Learning Representations. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437. Xinyin Ma, Guangnian Wan, Runpeng Yu, Gongfan Fang, and Xi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop overthinking: A survey on efficient rea- soning for large language models. arXiv preprint arXiv:2503.16419. Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Man- sooreh Karami, Jundong Li, Lu Cheng, and Huan Liu. 2024. Large language models for data annota- tion and synthesis: A survey. In Proceedings of the 2024 C...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
arXiv preprint arXiv:2504.15895
Dynamic early exit in reasoning models. arXiv preprint arXiv:2504.15895. Yiyao Yu, Yuxiang Zhang, Dongdong Zhang, Xiao Liang, Hengyuan Zhang, Xingxing Zhang, Ziyi Yang, Mahmoud Khademi, Hany Awadalla, Junjie Wang, et al. 2025. Chain-of-reasoning: Towards unified mathematical reasoning in large language models via a multi-paradigm perspective. arXiv prepri...
- [5]
-
[6]
DELETE: The step is unnecessary and should be removed entirely
-
[7]
SINGLE-STEP COMPRESS: The step is necessary but verbose; rewrite it in a more concise way
-
[8]
MULTI-STEP COMPRESS: The step can be merged with neighboring steps; write a combined, cleaner version. If the final step clarifies the final answer (e.g., “The answer is...”), retain it. After completing the revision of each step, synthesize the revised steps into a coherent explanation. Ensure the output is fluent, log- ically sound, and matches the spea...
work page 2023
-
[9]
SINGLE-STEP COMPRESS: Joy reads 8 pages in 20 minutes, so she reads 0.4 pages per minute (8 ÷ 20)
-
[11]
SINGLE-STEP COMPRESS: To find the time for 120 pages, divide 120 by 0.4 pages per minute
-
[12]
DELETE: This step is now included in the previous step
-
[13]
SINGLE-STEP COMPRESS: Convert 300 minutes to hours by dividing by 60
-
[14]
Final Answer: Okay, let’s calculate the time it takes Joy to read 120 pages
DELETE: This step is now included in the previous step. Final Answer: Okay, let’s calculate the time it takes Joy to read 120 pages. Joy reads 8 pages in 20 minutes, which means she reads 0.4 pages per minute (8 ÷ 20). To find out how many minutes it takes her to read 120 pages, divide 120 by 0.4, resulting in 300 minutes. Convert 300 minutes into hours b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.