Search-Based Multi-Trajectory Refinement for Safe C-to-Rust Translation with Large Language Models
Pith reviewed 2026-05-22 14:32 UTC · model grok-4.3
The pith
LAC2R applies Monte Carlo Tree Search to explore multiple LLM refinement trajectories for translating C code to safe Rust.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
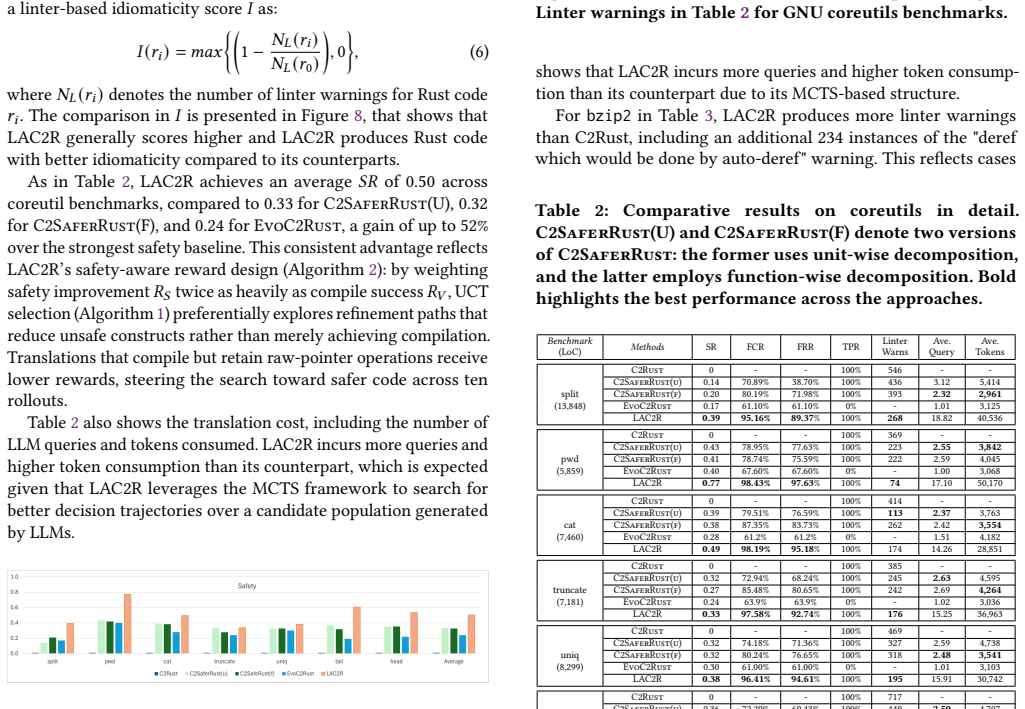
LAC2R uses MCTS to systematically explore multiple refinement trajectories and organize the LLM-induced intermediate steps for correct translation, demonstrating effectiveness on large-scale real-world benchmarks and uniquely attaining the highest safety ratio, perfect project-level correctness, and the fewest linter warnings on small-scale benchmarks among compared methods.
What carries the argument
The MCTS-guided LLM refinement technique in LAC2R, which organizes and cascades intermediate steps across multiple trajectories to produce safe Rust code.
Load-bearing premise
Monte Carlo Tree Search can effectively organize and cascade the LLM-induced intermediate steps, which are not well-defined, into correct translation trajectories despite scarce parallel C-to-Rust datasets.
What would settle it
Finding a set of C programs where a non-MCTS LLM refinement method produces Rust code with higher safety ratio or fewer warnings than LAC2R, or where LAC2R introduces more errors.
Figures










read the original abstract
The C programming language has been foundational in building system-level software. However, its manual memory management model frequently leads to memory safety issues. In response, Rust has emerged as a memory-safe alternative. Moreover, automating the C-to-Rust translation empowered by the rapid advancements of the generative capabilities of LLMs is gaining growing interest for large volumes of legacy C code. Leveraging LLM for the C-to-Rust translation introduces distinct challenges, unlike the math or commonsense QA domains where the LLMs have been predominantly applied. First, the scarcity of parallel C-to-Rust datasets hinders the retrieval of suitable code translation exemplars for in-context learning. Second, unlike math or commonsense QA problems, the intermediate steps required for C-to-Rust are not well-defined. Third, it remains unclear how to organize and cascade these intermediate steps to construct a correct translation trajectory. While existing LLM-based approaches have achieved some success, they have relied on iterative code refinement along a single search trajectory on a C-to-Rust problem space and have not explored the use of systematic search mechanisms to navigate the space of possible refinement trajectories. To address these challenges in the C-to-Rust translation, we propose the MCTS-Guided LLM refinement technique for automated C-to-safe-Rust translation (LAC2R). LAC2R uses MCTS to systematically explore multiple refinement trajectories and organize the LLM-induced intermediate steps for correct translation. We experimentally demonstrated that LAC2R effectively conducts C-to-Rust translation on large-scale, real-world benchmarks. On small-scale benchmarks, LAC2R is the only method that simultaneously attains the highest safety ratio, perfect project-level correctness, and the fewest linter warnings among the compared methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LAC2R, an MCTS-guided LLM refinement technique for automated C-to-safe-Rust translation. It identifies three challenges (scarce parallel datasets, ill-defined intermediate steps, and lack of systematic organization of LLM outputs) and claims that MCTS enables systematic exploration of multiple refinement trajectories. On small-scale benchmarks, LAC2R is reported as the only method attaining the highest safety ratio, perfect project-level correctness, and fewest linter warnings; the work also claims effectiveness on large-scale real-world benchmarks.
Significance. If the central experimental claims hold after clarification of the search formulation, the work would demonstrate a concrete way to combine tree search with LLMs for code translation tasks whose intermediate steps lack clear definitions. This could influence future research on reliable automated migration of legacy systems to memory-safe languages and would constitute a positive example of search-based organization of LLM-generated code edits.
major comments (2)
- [§3] §3 (LAC2R Method): the MCTS state representation, action space (refinement operations), and reward function must be specified with sufficient concreteness to show that the search is not reducible to repeated LLM prompting. The introduction states that 'the intermediate steps required for C-to-Rust are not well-defined,' yet the central performance claim (highest safety ratio + perfect project-level correctness) depends on MCTS providing structured guidance rather than simply increasing the number of LLM calls. Without explicit definitions or pseudocode for how partial translations become states and how safety/linter signals become rewards, the multi-trajectory advantage remains unverified.
- [§4] §4 (Experiments): the small-scale benchmark results are presented without statistical details (number of runs, variance, or error bars) or a clear description of how project-level correctness and linter warnings were measured across the compared baselines. Because the abstract already summarizes outcomes without methods, the load-bearing claim that LAC2R is 'the only method' simultaneously satisfying all three metrics requires the full experimental protocol and raw data to be reproducible.
minor comments (2)
- [Abstract / §1] The abstract and introduction use the phrase 'large-scale, real-world benchmarks' without citing the specific corpora or providing a pointer to the dataset release; this should be clarified in the experimental section.
- [§2] Notation for safety ratio and project-level correctness is introduced without an explicit equation or definition in the early sections; a short formal definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity in the method description and experimental reporting. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (LAC2R Method): the MCTS state representation, action space (refinement operations), and reward function must be specified with sufficient concreteness to show that the search is not reducible to repeated LLM prompting. The introduction states that 'the intermediate steps required for C-to-Rust are not well-defined,' yet the central performance claim (highest safety ratio + perfect project-level correctness) depends on MCTS providing structured guidance rather than simply increasing the number of LLM calls. Without explicit definitions or pseudocode for how partial translations become states and how safety/linter signals become rewards, the multi-trajectory advantage remains unverified.
Authors: We agree that the current description of the MCTS components in Section 3 would benefit from greater concreteness to demonstrate the structured guidance beyond repeated prompting. In the revised manuscript, we will explicitly define the state as a partial Rust translation paired with accumulated safety and borrow-checker annotations; the action space as a set of targeted LLM refinement operations (e.g., ownership insertion, unsafe-block refactoring, and error-specific fixes); and the reward as a composite function of static safety ratio, linter warning count, and compilation outcome. We will also add pseudocode illustrating the MCTS selection, expansion, simulation, and backpropagation phases as applied to C-to-Rust trajectories. These additions will substantiate how the search organizes intermediate steps that the introduction correctly notes are not well-defined a priori. revision: yes
-
Referee: [§4] §4 (Experiments): the small-scale benchmark results are presented without statistical details (number of runs, variance, or error bars) or a clear description of how project-level correctness and linter warnings were measured across the compared baselines. Because the abstract already summarizes outcomes without methods, the load-bearing claim that LAC2R is 'the only method' simultaneously satisfying all three metrics requires the full experimental protocol and raw data to be reproducible.
Authors: We acknowledge that the experimental section would be strengthened by including statistical details and a fuller protocol description. The small-scale results were obtained from five independent runs using different random seeds for both LLM sampling and MCTS tree exploration; we will report means with standard-deviation error bars in the revised tables and figures. Project-level correctness was assessed by attempting full-project compilation and executing any available test suites, while linter warnings were quantified via the standard Rust clippy tool applied to the final translated artifacts. We will add a dedicated evaluation-protocol subsection and indicate that raw per-run data will be released in a supplementary artifact. These changes will make the uniqueness claim fully reproducible. revision: yes
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper describes LAC2R as an MCTS-guided search procedure applied to LLM outputs to organize refinement trajectories for C-to-Rust translation. Central claims rest on experimental results (highest safety ratio, perfect project-level correctness, fewest linter warnings on small-scale benchmarks) evaluated against external benchmarks rather than any derivation, equations, or fitted parameters. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via citation appear in the abstract or method description. The approach is presented as addressing explicitly noted challenges (scarce datasets, ill-defined intermediate steps) via an external search mechanism, making the evaluation self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LAC2R uses MCTS to systematically explore multiple refinement trajectories and organize the LLM-induced intermediate steps for correct translation.
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define S to represent the reduction rate in five categories of unsafe Rust constructs... R = C(ri) − C(ri−1) + w·(S(ri) − S(ri−1))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
ReCodeAgent: A Multi-Agent Workflow for Language-agnostic Translation and Validation of Large-scale Repositories
ReCodeAgent uses a multi-agent system to translate and validate large code repositories across multiple programming languages, achieving 60.8% higher test pass rates than prior neuro-symbolic and agentic methods on 11...
-
Project-Level C-to-Rust Translation via Pointer Knowledge Graphs
PtrTrans builds a Pointer Knowledge Graph with points-to flows, struct abstractions, and Rust annotations to guide LLMs toward project-level C-to-Rust translations that cut unsafe code by 99.9% and raise functional co...
-
SafeTrans: LLM-assisted Transpilation from C to Rust
SafeTrans achieves up to 80% successful C-to-Rust translations via LLM iterative repair on 2653 programs and two real projects, with some C vulnerabilities carrying over to the Rust output.
-
LLM4C2Rust: Large Language Models for Automated Memory-Safe Code Transpilation
A RAG-enhanced LLM pipeline with segmentation improves C-to-Rust transpilation correctness and eliminates raw pointer dereferences and unsafe type casts in several Coreutils programs.
-
Dependency-Guided Repository-Level C-to-Rust Translation with Reinforcement Alignment
DepTrans translates entire C repositories to Rust at 60.7% compilation success and 43.5% functional accuracy by combining reinforcement-aligned syntax training with dependency-guided iterative refinement.
Reference graph
Works this paper leans on
- [1]
-
[2]
Yubo Bai and Tapti Palit. 2025. RustAssure: Differential Symbolic Testing for LLM-Transpiled C-to-Rust Code. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). 534–546. doi:10.1109/ASE63991.2025. 00051
-
[3]
Browne, Edward Powley, Daniel Whitehouse, Simon M
Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Pe- ter I. Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. 2012. A Survey of Monte Carlo Tree Search Methods.IEEE Transactions on Computational Intelligence and AI in Games4, 1 (2012), 1–43. doi:10.1109/TCIAIG.2012.2186810
-
[4]
Cameron Bytheway. 2024. Bolero Book: Fuzzing and Property Testing for Rust. https://camshaft.github.io/bolero/ Accessed: 2025-10-10
work page 2024
-
[5]
Xuemeng Cai, Jiakun Liu, Xiping Huang, Yijun Yu, Haitao Wu, Chunmiao Li, Bo Wang, Imam Nur Bani Yusuf, and Lingxiao Jiang. 2025. Rustmap: Towards project-scale c-to-rust migration via program analysis and llm. InInternational Conference on Engineering of Complex Computer Systems. Springer, 283–302
work page 2025
-
[6]
DARPA TRACTOR Program. 2026. PUBLIC Test Corpus. https://github.com/ DARPA-TRACTOR-Program/PUBLIC-Test-Corpus. Accessed: 2026-03-26
work page 2026
-
[7]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL] doi:10.48550/arXiv.2412.19437 arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2024
-
[8]
Mehmet Emre, Ryan Schroeder, Kyle Dewey, and Ben Hardekopf. 2021. Translat- ing C to safer Rust.Proc. ACM Program. Lang.5, OOPSLA, Article 121 (oct 2021), 29 pages. doi:10.1145/3485498
- [9]
-
[10]
Muhammad Farrukh, Smeet Shah, Baris Coskun, and Michalis Polychron- akis. 2025. SafeTrans: LLM-assisted Transpilation from C to Rust. arXiv:2505.10708 [cs.CR] https://arxiv.org/abs/2505.10708
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
Adrian Herrera, Hendra Gunadi, Shane Magrath, Michael Norrish, Mathias Payer, and Antony L. Hosking. 2021. Seed selection for successful fuzzing. InProceed- ings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis(Virtual, Denmark)(ISSTA 2021). Association for Computing Machinery, New York, NY, USA, 230–243. doi:10.1145/346031...
-
[13]
The White House. 2024. Back to the Building Blocks: A Path toward Secure and Measurable Software. https://bidenwhitehouse.archives.gov/wp-content/ uploads/2024/02/Final-ONCD-Technical-Report.pdf
work page 2024
-
[14]
The White House. 2024. National Cybersecurity Strategy Implementa- tion Plan. https://bidenwhitehouse.archives.gov/wp-content/uploads/2024/05/ National-Cybersecurity-Strategy-Implementation-Plan-Version-2.pdf
work page 2024
- [15]
-
[16]
Kani Developers. 2025. The Kani Rust Verifier. https://model-checking.github. io/kani/ Accessed: 2025-10-10
work page 2025
- [17]
- [18]
- [19]
- [20]
- [21]
-
[22]
Rust Project Developers. 2024.Clippy (rust-clippy). https://github.com/rust- lang/rust-clippy
work page 2024
-
[23]
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy P. Lillicrap, and David Silver. 2019. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model.CoRRabs/1911.08265 (2019). arXiv:1911.08265 http://arxiv.org/abs/1911.08265
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Manish Shetty, Naman Jain, Adwait Godbole, Sanjit A. Seshia, and Koushik Sen
-
[25]
arXiv:2412.14234 [cs.SE] https://arxiv.org/abs/2412.14234
Syzygy: Dual Code-Test C to (safe) Rust Translation using LLMs and Dynamic Analysis. arXiv:2412.14234 [cs.SE] https://arxiv.org/abs/2412.14234
-
[26]
Jeff Vander Stoep and Chong Zhang. 2019. Queue the Hardening Enhancements. https://security.googleblog.com/2019/05/queue-hardening-enhancements.html
work page 2019
-
[27]
Maciej Swiechowski, Konrad Godlewski, Bartosz Sawicki, and Jacek Mandziuk
-
[28]
arXiv:2103.04931 https://arxiv.org/abs/2103
Monte Carlo Tree Search: A Review of Recent Modifications and Applica- tions.CoRRabs/2103.04931 (2021). arXiv:2103.04931 https://arxiv.org/abs/2103. 04931
-
[29]
Microsoft MSRC Team. 2019. We need a safer systems programming lan- guage. https://msrc.microsoft.com/blog/2019/07/we-need-a-safer-systems- programming-language/
work page 2019
-
[30]
Chen Wang, Yujun Huang, Peng Li, Lina Gong, and Fei Wu. 2026. Rustify: Towards Repository-Level C to Safer Rust via Workflow-Guided Multi-Agent Transpiler. https://openreview.net/forum?id=tjZHVvgmZt
work page 2026
- [31]
-
[32]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International 11 Conference’17, July 2017, Washington, DC, USA Trovato et al. Conference on Neural Information Processing Systems(New Or...
work page 2022
- [33]
-
[34]
Zhuosheng Zhang, Yao Yao, Aston Zhang, Xiangru Tang, Xinbei Ma, Zhiwei He, Yiming Wang, Mark Gerstein, Rui Wang, Gongshen Liu, and Hai Zhao. 2025. Igniting Language Intelligence: The Hitchhiker’s Guide from Chain-of-Thought Reasoning to Language Agents.ACM Comput. Surv.57, 8, Article 206 (March 2025), 39 pages. doi:10.1145/3719341
-
[35]
Tianyang Zhou, Haowen Lin, Somesh Jha, Mihai Christodorescu, Kirill Levchenko, and Varun Chandrasekaran. 2025. LLM-Driven Multi-step Translation from C to Rust using Static Analysis. arXiv:2503.12511 [cs.SE] https://arxiv.org/abs/2503. 12511 Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.