ReaMOT: A Benchmark and Framework for Reasoning-based Multi-Object Tracking
Pith reviewed 2026-05-19 12:54 UTC · model grok-4.3
The pith
ReaMOT defines a new tracking task requiring logical reasoning over implicit constraints in language instructions instead of direct visual matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReaTrack decouples high-level cognitive localization from low-level physical motion continuity by dynamically aligning the semantic detections of a Thinking-variant LVLM with the robust motion priors of SAM2, establishing a new leading performance standard on the ReaMOT Challenge benchmark and achieving a more than threefold improvement in RHOTA on the High Level Reasoning subset.
What carries the argument
ReaTrack framework that dynamically aligns LVLM semantic detections with SAM2 motion priors to preserve temporal consistency while performing implicit logical inference.
If this is right
- Trackers gain the ability to satisfy implicit logical constraints expressed in natural language without explicit visual-textual matching at every step.
- The benchmark supplies standardized evaluation across six scenarios with emphasis on high-level reasoning, enabling direct comparison of cognitive tracking methods.
- Training-free integration of vision-language models with motion priors becomes a viable route to adding reasoning capacity to existing trackers.
- Performance gains concentrate on the high-level reasoning cases, indicating the approach scales to instructions that require inference beyond appearance matching.
Where Pith is reading between the lines
- The same separation of reasoning from motion continuity could reduce temporal drift in other video-language tasks that currently combine LVLM outputs with optical flow.
- Extending the six-scenario taxonomy to include longer videos or multi-camera sequences would test whether the alignment mechanism remains stable over extended time horizons.
- Replacing the specific LVLM or SAM2 with newer foundation models could be tested directly on the public ReaMOT dataset to measure further gains without retraining.
Load-bearing premise
Semantic detections from a Thinking-variant LVLM can be reliably aligned with SAM2 motion priors without introducing temporal inconsistencies or requiring task-specific fine-tuning.
What would settle it
Demonstration that the LVLM-SAM2 alignment produces temporally inconsistent tracks or drops RHOTA on the High Level Reasoning subset of the ReaMOT dataset would falsify the central claim.
Figures










read the original abstract
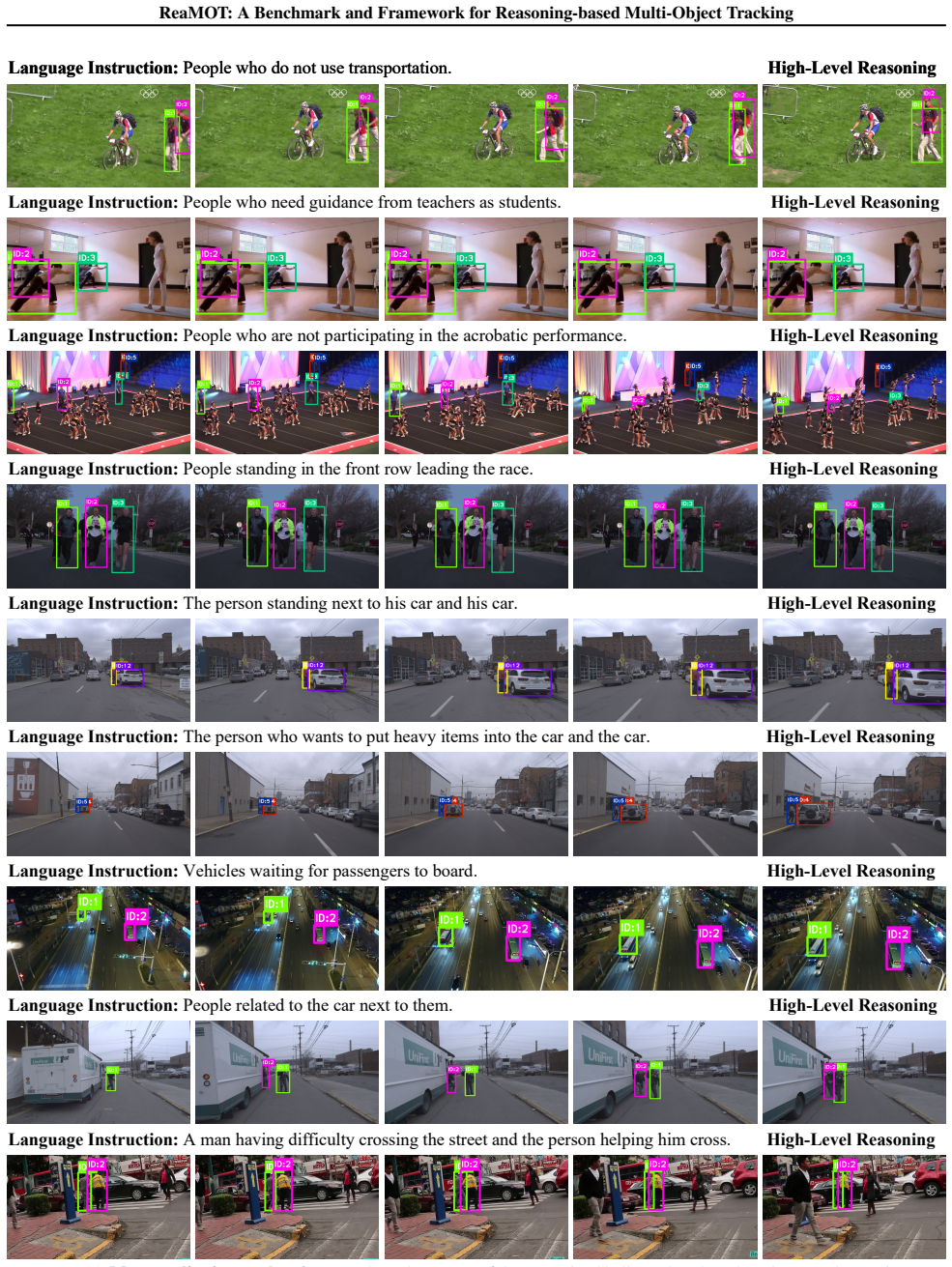
Referring Multi-Object Tracking (RMOT) aims to track targets specified by language instructions. However, existing RMOT paradigms heavily rely on explicit visual-textual matching and consequently fail to generalize to complex instructions that require logical reasoning. To overcome this, we propose Reasoning-based Multi-Object Tracking (ReaMOT), a novel task that elevates tracking to a cognitive level, requiring models to infer and track specific targets satisfying implicit constraints via logical reasoning. To advance this field, we construct the ReaMOT Challenge, a comprehensive benchmark featuring a tailored metric suite and a large scale dataset. This dataset comprises 1,156 language instructions, 423,359 image language pairs, and 869 distinct video sequences systematically categorized into six distinct evaluation scenarios, with over 75\% of the instructions dedicated to High Level Reasoning. Furthermore, recognizing that traditional trackers lack cognitive capacity while direct application of Large Vision-Language Model (LVLM) yields severe temporal inconsistencies, we propose ReaTrack. Driven by the insight to decouple high-level cognitive localization from low-level physical motion continuity, this training-free framework dynamically aligns the semantic detections of a Thinking-variant LVLM with the robust motion priors of SAM2. Extensive experiments on the ReaMOT Challenge benchmark demonstrate that ReaTrack establishes a new leading performance standard. Notably, it achieves a more than threefold improvement in RHOTA on the High Level Reasoning subset. Our dataset and code will be available at https://github.com/chen-si-jia/ReaMOT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Reasoning-based Multi-Object Tracking (ReaMOT) as a new task extending referring multi-object tracking to require logical reasoning over implicit constraints in language instructions. It constructs the ReaMOT Challenge benchmark comprising 1,156 language instructions, 423,359 image-language pairs, and 869 video sequences across six scenarios (with over 75% dedicated to high-level reasoning), along with a tailored metric suite. The authors propose ReaTrack, a training-free framework that decouples high-level cognitive localization via a Thinking-variant LVLM from low-level motion continuity via SAM2 through dynamic alignment of semantic detections with motion priors. Experiments on the benchmark show ReaTrack establishing new leading performance, including a more than threefold improvement in RHOTA on the High Level Reasoning subset.
Significance. If the performance gains and temporal consistency claims hold after detailed validation, this work could meaningfully advance the field by providing a benchmark for cognitive-level tracking and demonstrating the value of decoupling reasoning from motion priors. The dataset and code release supports reproducibility and future extensions. The empirical focus on a new task with large-scale data is a positive contribution, though the absence of parameter-free derivations or machine-checked elements limits the strength of the assessment.
major comments (2)
- [Methods (ReaTrack framework)] Methods section (ReaTrack framework): The dynamic alignment of LVLM semantic detections with SAM2 motion priors is described only at the level of 'dynamically aligns' without specifying the exact procedure (e.g., whether it uses IoU, feature similarity, nearest-neighbor matching, or any explicit temporal regularization for consistency). This mechanism is load-bearing for the central claim that the framework suppresses frame-to-frame semantic drift on high-level reasoning instructions without task-specific fine-tuning.
- [Experiments] Experiments section (results on High Level Reasoning subset): The more than threefold RHOTA improvement is presented as a headline result, but the manuscript provides no error bars, multiple-run statistics, or ablations isolating the alignment step from LVLM/SAM2 choices. This undermines confidence that the gain is general rather than tied to particular dataset statistics or checkpoint selection.
minor comments (2)
- [Abstract] Abstract: The phrase 'a tailored metric suite' is used without even a brief parenthetical definition or forward reference to the specific metrics (including RHOTA); this reduces immediate clarity for readers.
- [Dataset] Dataset section: The distribution of the 1,156 instructions across the six evaluation scenarios and the precise criteria for labeling 'High Level Reasoning' should be tabulated or exemplified to allow independent assessment of benchmark difficulty.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to improve clarity and empirical support where appropriate.
read point-by-point responses
-
Referee: Methods section (ReaTrack framework): The dynamic alignment of LVLM semantic detections with SAM2 motion priors is described only at the level of 'dynamically aligns' without specifying the exact procedure (e.g., whether it uses IoU, feature similarity, nearest-neighbor matching, or any explicit temporal regularization for consistency). This mechanism is load-bearing for the central claim that the framework suppresses frame-to-frame semantic drift on high-level reasoning instructions without task-specific fine-tuning.
Authors: We thank the referee for identifying this lack of specificity. The original description was intentionally high-level to emphasize the decoupling insight. In the revised manuscript we have expanded the Methods section (now Section 3.2) with the precise alignment procedure: semantic detections from the Thinking-variant LVLM are matched to SAM2 motion priors via IoU-based bipartite matching with a 0.5 overlap threshold; unmatched detections are discarded and associations are propagated across frames using a greedy temporal consistency rule that penalizes large displacements relative to the previous frame. Pseudocode and an illustrative diagram have been added to the supplementary material. revision: yes
-
Referee: Experiments section (results on High Level Reasoning subset): The more than threefold RHOTA improvement is presented as a headline result, but the manuscript provides no error bars, multiple-run statistics, or ablations isolating the alignment step from LVLM/SAM2 choices. This undermines confidence that the gain is general rather than tied to particular dataset statistics or checkpoint selection.
Authors: We agree that additional statistical validation would strengthen the claims. Because of the substantial compute required to run the LVLM and SAM2 pipeline over the full 869-sequence benchmark, we reported single deterministic runs. In the revision we have inserted a new ablation table that isolates the dynamic alignment component by comparing full ReaTrack against variants that replace it with direct LVLM output or naive nearest-neighbor matching. We have also added standard-deviation bars computed over three random seeds on the High-Level Reasoning subset (approximately 25 % of the data) and discuss the deterministic nature of the post-initialization stages. Full multi-seed evaluation on the entire benchmark remains computationally prohibitive but the added ablation directly addresses the concern about the alignment step. revision: partial
Circularity Check
No circularity: empirical benchmark results independent of any self-referential derivation
full rationale
The paper defines a new task (ReaMOT), releases a dataset with language instructions and videos, and describes a training-free ReaTrack framework that decouples LVLM semantic detections from SAM2 motion priors via dynamic alignment. All reported gains, including the >3× RHOTA improvement on the High Level Reasoning subset, are presented as outcomes of running this framework on the new benchmark. No equations, fitted parameters, or self-citations are shown that would make any performance number equivalent to its own inputs by construction. The central claims rest on external evaluation against the constructed test set rather than on any internal reduction or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large vision-language models can produce reliable semantic detections for objects satisfying implicit logical constraints in video frames.
- domain assumption SAM2 provides robust low-level motion priors that can be aligned with semantic detections without fine-tuning.
invented entities (2)
-
ReaMOT task
no independent evidence
-
ReaTrack framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decouple high-level cognitive localization from low-level physical motion continuity... dynamically aligns the semantic detections of a Thinking-variant LVLM with the robust motion priors of SAM2
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mask-Based Temporal Propagation... SAM2... Reasoning-Motion Association... Hungarian Matching
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
PET-DINO: Unifying Visual Cues into Grounding DINO with Prompt-Enriched Training
PET-DINO unifies visual and text prompts in Grounding DINO via an alignment-friendly generation module and prompt-enriched training strategies to improve zero-shot open-set object detection.
Reference graph
Works this paper leans on
-
[1]
datasets:The datasets folder includes Argoverse-HD (Li et al., 2020), DanceTrack (Sun et al., 2022), GMOT-40 (Bai et al., 2021), KITTI (Geiger et al., 2012), MOT17 (Milan, 2016), MOT20 (Dendorfer, 2020), MPHOI (Qiao et al., 2022), PathTrack (Manen et al., 2017), PoseTrack (Andriluka et al., 2018), SportsMOT (Cui et al., 2023), UA-DETRAC (Wen et al., 2020)...
work page 2020
-
[2]
source dataset video sequence language instruction
labels:The labels folder stores the annotated language instruc- tions with reasoning characteristics, which are created by us for the ReaMOT Challenge. 2.1train:The ReaMOT Challenge’s training set annotations. (A) name1:Each folder named in the format “source dataset video sequence language instruction”. a) gt:The gt folder includes the ground truth (gt) ...
-
[3]
Number 17: [242, 582, 273, 717]
-
[4]
The player running with ball: [346, 354, 376, 447]
-
[5]
The player near center: [498, 216, 517, 307]
-
[6]
Number 8: [817, 606, 839, 748]
-
[7]
bbox_2d": [242, 581, 273, 718],
Number 9: [817, 527, 839, 622] Wait, let's confirm jersey colors. In German football, Leipzig (RB Leipzig) often wears white with red stripes, and Bayern Munchen wears red and white. In this image, the players with white jerseys and red shorts are Leipzig. The other team (Bayern) has dark jerseys (probably black or dark blue with red), so the ones in whit...
-
[8]
The person in the bright green jacket (neon) with "UCA" on the shirt: [425, 228, 544, 796]
-
[9]
The person in black outfit on the right: [594, 208, 708, 832]
-
[10]
The person in black and gray on the left: [285, 213, 391, 792]
-
[11]
The person in pink: [247, 296, 305, 734]
-
[12]
The person in black behind the neon one: [395, 283, 454, 743]
-
[13]
The person in white with pink design: [542, 292, 616, 764]
-
[14]
The person in dark clothes on the leftmost: [117, 387, 178, 657] Wait, but the question says "front row, the front-runners". So the ones in the front, maybe the leading group. Let's see the order. The people in the front are the ones closest to the camera. The neon jacket person, the black outfit on the right, and the black and gray one on the left are mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.