On the Robustness of Tabular Foundation Models: Test-Time Attacks and In-Context Defenses
Pith reviewed 2026-05-19 10:46 UTC · model grok-4.3
The pith
Tabular foundation models drop in accuracy from small structured test-time perturbations even with fixed context, and can generate transferable attacks on other models, but incremental adversarial replacement of context instances improves,
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Small structured perturbations to test inputs significantly degrade prediction accuracy of tabular foundation models even when the training context remains fixed. Tabular foundation models can be repurposed to generate transferable evasion attacks against conventional models such as random forests and XGBoost. Formulating the robustification problem as optimization over context via incremental replacement with adversarial perturbed instances, without updating model weights, yields improved robustness across the tested tabular benchmarks.
What carries the argument
In-context adversarial learning strategy that incrementally replaces context instances with adversarial perturbed instances to optimize robustness without updating model weights.
Load-bearing premise
The assumption that incremental replacement of context instances with adversarial perturbations produces a general and stable robustness improvement that holds beyond the three specific benchmarks and particular tabular models tested without further validation of transfer or long-term stability.
What would settle it
A controlled experiment applying the incremental context-replacement procedure to a previously untested tabular foundation model on a new domain benchmark and measuring whether robustness gains disappear would settle the claim.
Figures
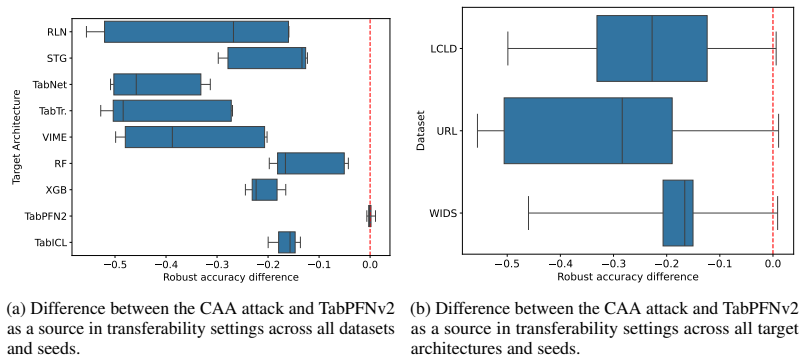

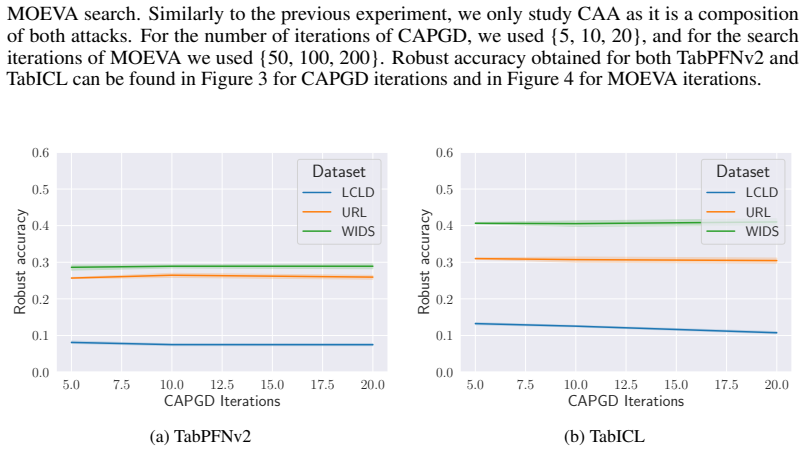
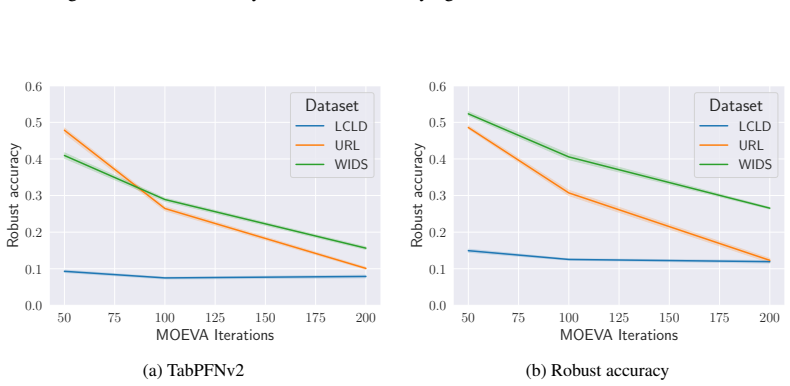
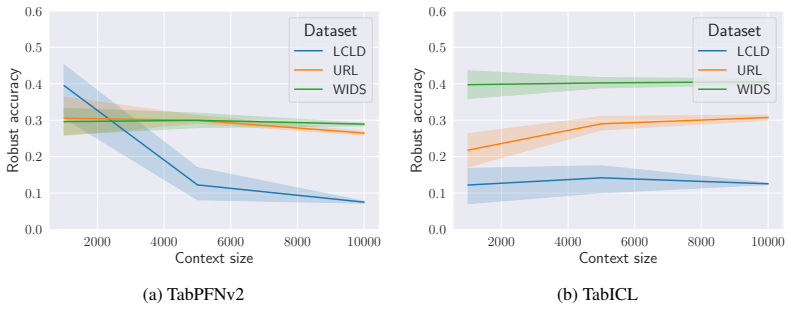
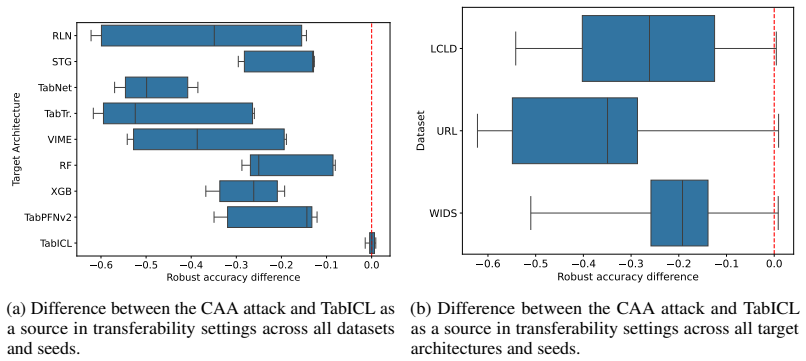
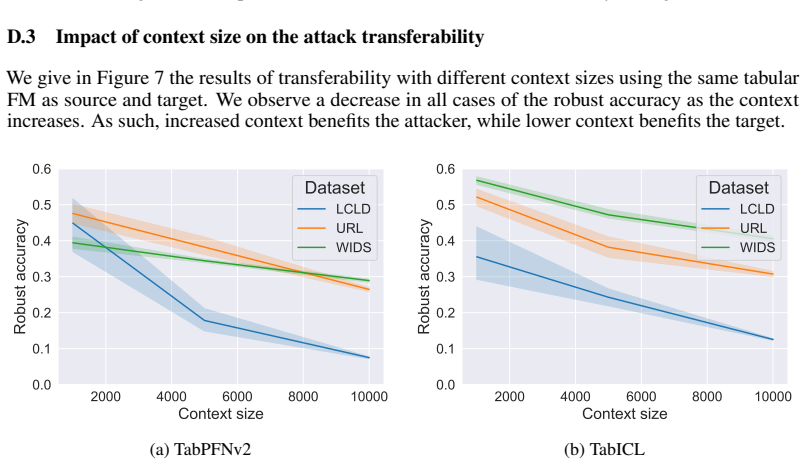
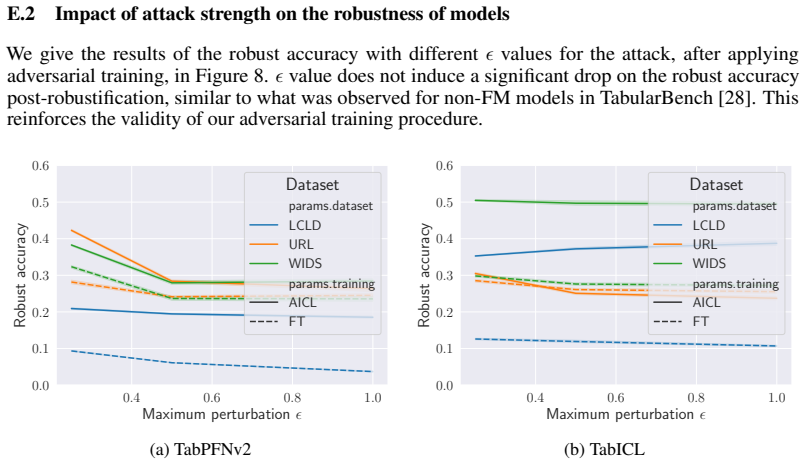
read the original abstract
Recent tabular Foundational Models (FM) such as TabPFN and TabICL, leverage in-context learning to achieve strong performance without gradient updates or fine-tuning. However, their robustness to adversarial manipulation remains largely unexplored. In this work, we present a comprehensive study of the adversarial vulnerabilities of tabular FM, focusing on both their fragility to targeted test-time attacks and their potential misuse as adversarial tools. We show on three benchmarks in finance, cybersecurity and healthcare, that small, structured perturbations to test inputs can significantly degrade prediction accuracy, even when training context remain fixed. Additionally, we demonstrate that tabular FM can be repurposed to generate transferable evasion to conventional models such as random forests and XGBoost, and on a lesser extent to deep tabular models. To improve tabular FM, we formulate the robustification problem as an optimization of the weights (adversarial fine-tuning), or the context (adversarial in-context learning). We introduce an in-context adversarial training strategy that incrementally replaces the context with adversarial perturbed instances, without updating model weights. Our approach improves robustness across multiple tabular benchmarks. Together, these findings position tabular FM as both a target and a source of adversarial threats, highlighting the urgent need for robust training and evaluation practices in this emerging paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the adversarial robustness of tabular foundation models such as TabPFN and TabICL that rely on in-context learning without gradient updates. It empirically demonstrates on three benchmarks (finance, cybersecurity, healthcare) that small structured perturbations to test inputs can significantly degrade prediction accuracy even when the training context is held fixed. The work further shows that these models can be repurposed to generate transferable evasion attacks against conventional models including random forests and XGBoost (and to a lesser extent deep tabular models). To mitigate vulnerabilities, the authors formulate robustification either via adversarial fine-tuning of weights or via adversarial in-context learning; they introduce an incremental replacement strategy that substitutes context instances with adversarially perturbed examples and report improved robustness across the benchmarks.
Significance. If the empirical results hold under broader validation, the paper is significant for identifying previously unexplored test-time vulnerabilities in tabular FMs and for proposing a lightweight, weight-update-free defense based on in-context adversarial replacement. The dual positioning of tabular FMs as both attack targets and attack generators is a timely contribution that could influence evaluation standards in this emerging area. The concrete demonstration of transferable attacks and the in-context defense strategy provide actionable insights, though their generality remains to be confirmed.
major comments (2)
- [Experimental Evaluation] The central defense claim—that incremental replacement of context instances with perturbed examples yields a general and stable robustness improvement—rests on evaluation limited to TabPFN and TabICL on three specific benchmarks. No cross-dataset ablations, tests on additional tabular FMs, or analysis of stability under varying context sizes, perturbation budgets, or distribution shifts are reported, which is load-bearing for asserting generality beyond the chosen setups.
- [Abstract and Section 4] While the abstract and introduction assert that small perturbations significantly degrade accuracy and enable transferable evasion, the high-level empirical outcomes lack accompanying quantitative metrics such as attack success rates, accuracy drops with error bars, or detailed ablation controls in the reported results, weakening support for the vulnerability claims.
minor comments (2)
- [Abstract] The phrase 'on a lesser extent' in the abstract should be corrected to 'to a lesser extent'.
- [Methods] Notation for context replacement and perturbation budgets could be introduced more explicitly in the methods section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work examining the adversarial robustness of tabular foundation models. We address the major comments point by point below, clarifying the scope of our evaluation and enhancing the presentation of results where appropriate.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central defense claim—that incremental replacement of context instances with perturbed examples yields a general and stable robustness improvement—rests on evaluation limited to TabPFN and TabICL on three specific benchmarks. No cross-dataset ablations, tests on additional tabular FMs, or analysis of stability under varying context sizes, perturbation budgets, or distribution shifts are reported, which is load-bearing for asserting generality beyond the chosen setups.
Authors: We thank the referee for this observation. TabPFN and TabICL were selected as representative tabular foundation models that rely exclusively on in-context learning without gradient updates, and the three benchmarks (finance, cybersecurity, healthcare) were chosen to reflect diverse real-world tabular domains with differing feature characteristics and label distributions. While we acknowledge that exhaustive cross-dataset ablations, tests on every emerging tabular FM, or full sweeps over context sizes, budgets, and shifts would provide additional support, the consistent patterns of vulnerability and the improvements from incremental adversarial context replacement across our setups indicate the defense's practical value. In the revised manuscript we have added a limitations subsection that explicitly discusses these scope choices and includes new analysis of stability under varying context sizes and perturbation budgets drawn from supplementary runs. revision: partial
-
Referee: [Abstract and Section 4] While the abstract and introduction assert that small perturbations significantly degrade accuracy and enable transferable evasion, the high-level empirical outcomes lack accompanying quantitative metrics such as attack success rates, accuracy drops with error bars, or detailed ablation controls in the reported results, weakening support for the vulnerability claims.
Authors: We agree that foregrounding quantitative support strengthens the claims. Detailed accuracy drops, attack success rates for both direct and transferable attacks, and ablation results are already present in Section 4 (with tables and figures). To address the referee's concern directly, we have revised the abstract to include explicit numerical summaries of the observed accuracy degradations and attack success rates, and we have augmented Section 4 with additional error bars from repeated runs and clearer ablation controls. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential definitions
full rationale
The paper contains no equations, derivations, or mathematical chains. All claims rest on empirical demonstrations of test-time attacks and an in-context defense strategy (incremental replacement of context instances with perturbed examples) evaluated on three fixed benchmarks using TabPFN and TabICL. The proposed robustification method is introduced as a new procedure rather than derived from or defined in terms of its own outputs. No self-citation load-bearing steps, fitted parameters renamed as predictions, or ansatz smuggling appear. The work is self-contained against external benchmarks and therefore exhibits no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three chosen benchmarks in finance, cybersecurity and healthcare are sufficiently representative to support general claims about tabular FM robustness.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce an in-context adversarial training strategy that incrementally replaces the context with adversarial perturbed instances, without updating model weights.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
formulate the robustification problem as an optimization of the weights (adversarial fine-tuning), or the context (adversarial in-context learning)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Sercan Ö Arik and Tomas Pfister. 2021. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI conference on artificial intelligence, V ol. 35. 6679–6687
work page 2021
-
[3]
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. 2024. Deep Neural Networks and Tabular Data: A Survey. IEEE Transactions on Neural Networks and Learning Systems 35, 6 (2024), 7499–7519. https://doi.org/10. 1109/TNNLS.2022.3229161
-
[4]
Tianqi Chen and Carlos Guestrin. 2016. XGBoost: A scalable tree boosting system. In Proceed- ings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). 785–794
work page 2016
-
[5]
Alesia Chernikova and Alina Oprea. 2022. Fence: Feasible evasion attacks on neural networks in constrained environments. ACM Transactions on Privacy and Security 25, 4 (2022), 1–34
work page 2022
-
[6]
Myung Jin Choi, Antonio Torralba, and Alan S Willsky. 2011. A tree-based context model for object recognition. IEEE transactions on pattern analysis and machine intelligence 34, 2 (2011), 240–252
work page 2011
- [7]
-
[8]
Salijona Dyrmishi, Salah Ghamizi, Thibault Simonetto, Yves Le Traon, and Maxime Cordy
-
[9]
In 2023 IEEE symposium on security and privacy (SP)
On the empirical effectiveness of unrealistic adversarial hardening against realistic adversarial attacks. In 2023 IEEE symposium on security and privacy (SP). IEEE, 1384–1400
work page 2023
-
[10]
Nathan George. 2018. Lending Club loan data. https://www.kaggle.com/datasets/ wordsforthewise/lending-club
work page 2018
-
[11]
Abdelhakim Hannousse and Salima Yahiouche. 2021. Towards benchmark datasets for machine learning based website phishing detection: An experimental study. Engineering Applications of Artificial Intelligence 104 (2021), 104347
work page 2021
-
[12]
Xuanli He, Yuxiang Wu, Oana-Maria Camburu, Pasquale Minervini, and Pontus Stenetorp
-
[13]
https://arxiv.org/abs/2311.07556
Using Natural Language Explanations to Improve Robustness of In-context Learning. https://arxiv.org/abs/2311.07556
-
[14]
Kai Helli, David Schnurr, Noah Hollmann, Samuel Müller, and Frank Hutter. 2024. Drift- Resilient TabPFN: In-Context Learning Temporal Distribution Shifts on Tabular Data. In Advances in Neural Information Processing Systems , A. Globerson, L. Mackey, D. Bel- grave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), V ol. 37. Curran Associates, Inc., 9874...
work page 2024
-
[15]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. 2023. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum? id=cp5PvcI6w8_ 10
work page 2023
-
[16]
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. 2025. Accurate predictions on small data with a tabular foundation model. Nature (01 2025). https://doi.org/10.1038/ s41586-024-08328-6
work page 2025
-
[17]
Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. 2020. Tabtransformer: Tabular data modeling using contextual embeddings. arXiv preprint arXiv:2012.06678 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [18]
-
[19]
Meredith Lee, Jesse Raffa, Marzyeh Ghassemi, Tom Pollard, Sharada Kalanidhi, Omar Badawi, Karen Matthys, and Leo Anthony Celi. 2020. WiDS (Women in Data Science) Datathon 2020: ICU Mortality Prediction. PhysioNet
work page 2020
- [20]
-
[21]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In Inter- national Conference on Learning Representations. https://openreview.net/forum?id= Bkg6RiCqY7
work page 2019
-
[22]
Cresswell, Keyvan Golestan, Guangwei Yu, Maksims V olkovs, and Anthony L
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Hamidreza Kamkari, Alex Labach, Jesse C. Cresswell, Keyvan Golestan, Guangwei Yu, Maksims V olkovs, and Anthony L. Caterini. 2024. TabDPT: Scaling Tabular Foundation Models. (2024)
work page 2024
-
[23]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu
-
[24]
In International Con- ference on Learning Representations
Towards Deep Learning Models Resistant to Adversarial Attacks. In International Con- ference on Learning Representations. https://openreview.net/forum?id=rJzIBfZAb
-
[25]
Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z Berkay Celik, and Ananthram Swami. 2016. The limitations of deep learning in adversarial settings. In Security and Privacy (EuroS&P), 2016 IEEE European Symposium on. IEEE, 372–387
work page 2016
- [26]
-
[27]
Sergio Ruiz-Villafranca, José Roldán-Gómez, Juan Manuel Castelo Gómez, Javier Carrillo- Mondéjar, and José Luis Martinez. 2024. A TabPFN-based intrusion detection system for the industrial internet of things. The Journal of Supercomputing 80, 14 (2024), 20080–20117
work page 2024
-
[28]
Ira Shavitt and Eran Segal. 2018. Regularization learning networks: deep learning for tabular datasets. Advances in Neural Information Processing Systems 31 (2018)
work page 2018
-
[29]
Thibault Simonetto, Salijona Dyrmishi, Salah Ghamizi, Maxime Cordy, and Yves Le Traon
-
[30]
A Unified Framework for Adversarial Attack and Defense in Constrained Feature Space. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, Lud De Raedt (Ed.). International Joint Conferences on Artificial Intelligence Organi- zation, 1313–1319. https://doi.org/10.24963/ijcai.2022/183 Main Track
-
[31]
Thibault Simonetto, Salah Ghamizi, and Maxime Cordy. 2024. Constrained Adaptive At- tack: Effective Adversarial Attack Against Deep Neural Networks for Tabular Data. In Ad- vances in Neural Information Processing Systems , A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), V ol. 37. Curran Associates, Inc., 27817–278...
work page 2024
-
[32]
Thibault Simonetto, Salah Ghamizi, and Maxime Cordy. 2024. TabularBench: Bench- marking Adversarial Robustness for Tabular Deep Learning in Real-world Use-cases. In Advances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), V ol. 37. Curran Associates, Inc., 78394–78430. htt...
work page 2024
- [33]
-
[34]
Yutaro Yamada, Ofir Lindenbaum, Sahand Negahban, and Yuval Kluger. 2020. Feature Selection using Stochastic Gates. In Proceedings of Machine Learning and Systems 2020. 8952–8963
work page 2020
- [35]
-
[36]
Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar. 2020. Vime: Extending the success of self-and semi-supervised learning to tabular domain. Advances in Neural Information Processing Systems 33 (2020), 11033–11043
work page 2020
- [37]
-
[38]
Shuai Zhao, Meihuizi Jia, Luu Anh Tuan, Fengjun Pan, and Jinming Wen. 2024. Universal Vulnerabilities in Large Language Models: Backdoor Attacks for In-context Learning. https: //arxiv.org/abs/2401.05949 12 A Additional experimental protocol details A.1 Datasets Table 6: The datasets evaluated in the empirical study, with the class imbalance of each datas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.