Model Context Protocol (MCP) at First Glance: Studying the Security and Maintainability of MCP Servers
Pith reviewed 2026-05-19 09:28 UTC · model grok-4.3
The pith
MCP's AI-driven control flow creates eight new vulnerability types that traditional checks miss in open servers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
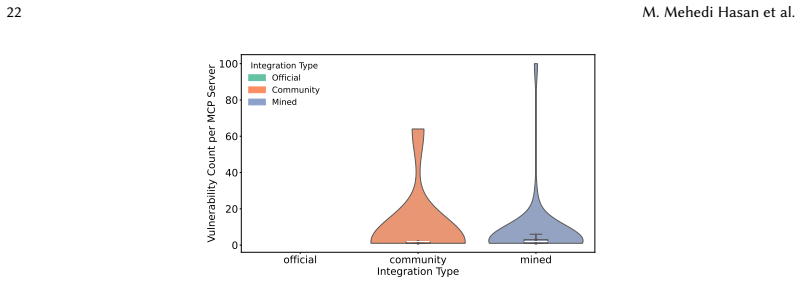
An analysis of 1,899 open-source MCP servers shows strong overall health metrics but identifies eight distinct vulnerabilities, with only three overlapping traditional software vulnerabilities. The study further reports that 7.2 percent of servers contain general vulnerabilities and 5.5 percent exhibit MCP-specific tool poisoning, while 66 percent display code smells and 14.4 percent contain ten bug patterns documented in prior work. The authors conclude that MCP's AI-driven non-deterministic control flow introduces risks that call for MCP-specific vulnerability detection alongside continued use of traditional refactoring and scanning practices.
What carries the argument
The hybrid analysis pipeline that pairs a general-purpose static analysis tool with a custom MCP-specific scanner to classify vulnerabilities as traditional or protocol-unique.
If this is right
- MCP-specific vulnerability detection techniques should supplement traditional analysis methods.
- MCP vulnerabilities need to be added to standardized vulnerability databases.
- Automated security scanning should be built into MCP registries.
- Responsible development practices can help maintain the safety and sustainability of the MCP ecosystem.
Where Pith is reading between the lines
- Other emerging AI tool-interface standards may encounter similar non-deterministic risks that general scanners overlook.
- Teams adopting MCP could add targeted checks for tool poisoning during code review or deployment.
- Longer-term monitoring of MCP server growth might reveal whether the observed vulnerability rates change as the ecosystem matures.
Load-bearing premise
The hybrid analysis pipeline accurately separates MCP-specific vulnerabilities from traditional ones without large numbers of misclassifications, and the 1,899 servers represent the wider open MCP ecosystem.
What would settle it
A manual review of a random subset of the servers that finds substantially higher or lower counts of tool poisoning or different vulnerability classifications than the automated pipeline produced.
Figures






read the original abstract
Although Foundation Models (FMs), such as GPT-4, are increasingly used in domains like finance and software engineering, reliance on textual interfaces limits these models' real-world interaction. To address this, FM providers introduced a tool called -- triggering a proliferation of frameworks with distinct tool interfaces. In late 2024, Anthropic introduced the Model Context Protocol (MCP) to standardize this tool ecosystem. MCP is rapidly emerging as a de facto industry standard. Despite its adoption, MCP's AI-driven, non-deterministic control flow introduces new risks to sustainability, security, and maintainability, warranting closer examination. Towards this end, we present the first large-scale empirical study of MCP. Using state-of-the-art health metrics and a hybrid analysis pipeline that combines a general-purpose static analysis tool with an MCP-specific scanner, we evaluate 1,899 open-source MCP servers to assess their health, security, and maintainability. Despite MCP servers demonstrating strong health metrics, we identify eight distinct vulnerabilities -- only three of which overlap with traditional software vulnerabilities. Additionally, 7.2% of servers contain general vulnerabilities, and 5.5% exhibit MCP-specific tool poisoning. Regarding maintainability, while 66% exhibit code smells, 14.4% contain ten bug patterns overlapping prior research. These findings highlight the need for MCP-specific vulnerability detection techniques while reaffirming the value of traditional analysis and refactoring practices. Furthermore, we advocate for stronger governance across the MCP ecosystem by incorporating MCP-specific vulnerabilities into standardized vulnerability databases, enabling automated security scanning within MCP registries, and promoting responsible development practices to ensure the long-term safety and sustainability of the MCP ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first large-scale empirical study of 1,899 open-source MCP servers, employing state-of-the-art health metrics and a hybrid analysis pipeline that combines general-purpose static analysis with an MCP-specific scanner. It reports strong overall health metrics but identifies eight distinct vulnerabilities (only three overlapping traditional software vulnerabilities), with 7.2% of servers containing general vulnerabilities and 5.5% exhibiting MCP-specific tool poisoning; additionally, 66% of servers show code smells and 14.4% contain ten bug patterns overlapping prior research. The work concludes by advocating MCP-specific vulnerability detection, integration into standardized databases, and improved governance for the ecosystem.
Significance. If the hybrid pipeline's classification of MCP-specific vulnerabilities holds, the study offers a timely empirical baseline for an emerging protocol that standardizes tool interfaces for foundation models. The scale of the analysis (1,899 servers) and the explicit separation of novel versus traditional risks provide a useful foundation for future work on AI-driven control flow security. The call for incorporating MCP-specific issues into vulnerability databases is a concrete, actionable contribution.
major comments (1)
- [Abstract / hybrid analysis pipeline description] Abstract and the description of the hybrid analysis pipeline: the central claim that eight distinct vulnerabilities exist with only three overlaps, and that 5.5% of servers exhibit MCP-specific tool poisoning, depends on the MCP-specific scanner correctly partitioning findings from the general static analyzer. No validation details (false-positive rates, held-out test set, or inter-rater audit) are reported for the scanner's rules on tool poisoning, unsafe parameter handling, or prompt-like injection vectors in tool schemas. This directly affects the headline distinction between new protocol risks and conventional issues such as command injection or deserialization flaws.
minor comments (2)
- The representativeness of the 1,899 collected servers should be discussed more explicitly, including any sampling biases or coverage of the open MCP ecosystem.
- Consider adding a limitations section that addresses potential false negatives in the general static analysis tools when applied to MCP-specific code patterns.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the timeliness and scale of our empirical study on MCP servers. We address the major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: Abstract and the description of the hybrid analysis pipeline: the central claim that eight distinct vulnerabilities exist with only three overlaps, and that 5.5% of servers exhibit MCP-specific tool poisoning, depends on the MCP-specific scanner correctly partitioning findings from the general static analyzer. No validation details (false-positive rates, held-out test set, or inter-rater audit) are reported for the scanner's rules on tool poisoning, unsafe parameter handling, or prompt-like injection vectors in tool schemas. This directly affects the headline distinction between new protocol risks and conventional issues such as command injection or deserialization flaws.
Authors: We agree that explicit validation of the MCP-specific scanner is necessary to substantiate the distinction between the eight reported vulnerabilities and traditional issues. The current manuscript describes the hybrid pipeline and the rule-based scanner but omits quantitative validation metrics. In the revised version we will add a new subsection (Section 3.3) that details the scanner's rule development process, reports false-positive rates obtained from manual inspection of a random sample of 100 servers, and describes the inter-rater audit performed by two authors on a held-out set of 50 servers for tool-poisoning and unsafe-parameter classifications. These additions will directly support the headline claims regarding MCP-specific risks versus conventional vulnerabilities. revision: yes
Circularity Check
No circularity: purely empirical data collection and tool application
full rationale
The paper reports a large-scale empirical study that collects 1,899 open-source MCP servers and applies a hybrid pipeline of general static analysis plus an MCP-specific scanner. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. Vulnerability counts and classifications are presented as direct outputs of the analysis on external data rather than reductions to author-defined quantities. The work is self-contained against the collected corpus and external tools, with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- Vulnerability classification thresholds in MCP scanner
axioms (2)
- domain assumption The 1,899 open-source MCP servers are representative of the broader ecosystem
- domain assumption Static analysis combined with the MCP-specific scanner reliably identifies the reported vulnerabilities
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid analysis pipeline that combines a general-purpose static analysis tool with an MCP-specific scanner... 7.2% of servers contain general vulnerabilities, and 5.5% exhibit MCP-specific tool poisoning
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MCP servers demonstrate strong health metrics... median commit frequency (5.5 commits/week)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 20 Pith papers
-
A First Measurement Study on Authentication Security in Real-World Remote MCP Servers
First measurement study of 7,973 remote MCP servers finds 40.55% lack authentication and all 119 tested OAuth servers have flaws that risk data leaks or account takeover.
-
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
26.1% of analyzed AI agent skills contain vulnerabilities across 14 patterns, with executable scripts raising risk 2.12x, based on static and LLM analysis of 31k skills.
-
Parasites in the Toolchain: A Large-Scale Analysis of Attacks on the MCP Ecosystem
This paper defines a new Parasitic Toolchain Attack pattern (MCP-UPD) that assembles legitimate tools into privacy-exfiltrating workflows and reports the first large-scale scan of 12230 MCP tools across 1360 servers r...
-
DADL: A Declarative Description Language for Enterprise Tool Libraries in LLM Agent Systems
DADL is a declarative YAML format that lets a single runtime handle many REST API tools for LLM agents, cutting tool advertisement context cost by 142x from 142,000 to 1,000 tokens on a catalog of 1,833 definitions.
-
MCP-DPT: A Defense-Placement Taxonomy and Coverage Analysis for Model Context Protocol Security
MCP-DPT creates a defense-placement taxonomy that organizes MCP threats and defenses across six architectural layers, revealing mostly tool-centric protections and gaps at orchestration, transport, and supply-chain layers.
-
From Component Manipulation to System Compromise: Understanding and Detecting Malicious MCP Servers
Presents a component-centric PoC dataset of malicious MCP servers and a two-stage behavioral deviation detector Connor achieving 94.6% F1-score.
-
AgentBound: Securing Execution Boundaries of AI Agents
AgentBound is the first declarative access control framework for Model Context Protocol servers that generates policies from source code at 80.9% accuracy and blocks most threats in malicious servers with negligible overhead.
-
An Empirical Study of Testing Practices in Open Source AI Agent Frameworks and Agentic Applications
Empirical study of open-source AI agents shows testing effort concentrates on deterministic tools and workflows (over 70%) while the FM-based plan body gets under 5% and prompts appear in only 1% of tests.
-
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
MCP lifecycle is defined with four phases and 16 activities; a threat taxonomy of 16 scenarios is constructed, validated via case studies, and paired with phase-specific safeguards.
-
OpenAaaS: An Open Agent-as-a-Service Framework for Distributed Materials-Informatics Research
OpenAaaS is a hierarchical agent-as-a-service system that enables secure multi-agent collaboration for materials informatics by moving code to data rather than data to code.
-
When Agents Overtrust Environmental Evidence: An Extensible Agentic Framework for Benchmarking Evidence-Grounding Defects in LLM Agents
EnvTrustBench is a new agentic benchmark that measures evidence-grounding defects where LLM agents overtrust faulty environmental observations and take incorrect actions.
-
When Agents Overtrust Environmental Evidence: An Extensible Agentic Framework for Benchmarking Evidence-Grounding Defects in LLM Agents
EnvTrustBench benchmarks evidence-grounding defects in LLM agents and finds they occur consistently across workflows.
-
Unsafe by Flow: Uncovering Bidirectional Data-Flow Risks in MCP Ecosystem
MCP-BiFlow detects 93.8% of known bidirectional data-flow vulnerabilities in MCP servers and identifies 118 confirmed issues across 87 real-world servers from a scan of 15,452 repositories.
-
Bridging Protocol and Production: Design Patterns for Deploying AI Agents with Model Context Protocol
The paper proposes Context-Aware Broker Protocol, Adaptive Timeout Budget Allocation, and Structured Error Recovery Framework to address gaps in identity, budgeting, and error handling for production AI agent deployme...
-
Semantic Attacks on Tool-Augmented LLMs: Securing the Model Context Protocol Against Descriptor-Level Manipulation
Descriptor-level manipulation in the Model Context Protocol can drive LLMs to unsafe tool selections in up to 36% of cases; a layered defense of integrity checks, auxiliary-LLM vetting, and runtime guardrails reduces ...
-
VIPER-MCP: Detecting and Exploiting Taint-Style Vulnerabilities in Model Context Protocol Servers
VIPER-MCP detects and exploits taint-style vulnerabilities in Model Context Protocol servers via anchor-query static analysis and feedback-driven prompt evolution, uncovering 106 zero-day vulnerabilities across 39,884...
-
Train the Trainers -- An Agentic AI Framework for Peer-Based Mental Health Support in Battlefield Environments
The paper introduces an agentic AI platform to train and support recovered soldiers as peer facilitators providing mental health triage and interventions in austere battlefield environments.
-
Security Threat Modeling for Emerging AI-Agent Protocols: A Comparative Analysis of MCP, A2A, Agora, and ANP
The paper identifies twelve protocol-level security risks across MCP, A2A, Agora, and ANP and quantifies wrong-provider tool execution risk in MCP via a measurement-driven case study on multi-server composition.
-
CASCADE: A Cascaded Hybrid Defense Architecture for Prompt Injection Detection in MCP-Based Systems
CASCADE is a cascaded hybrid detector that combines fast regex/entropy filtering, BGE embeddings with local LLM fallback, and output pattern checks to achieve 95.85% precision and 6.06% false-positive rate against pro...
-
Flowr -- Scaling Up Retail Supply Chain Operations Through Agentic AI in Large Scale Supermarket Chains
Flowr is an agentic AI framework that decomposes retail supply chain workflows into coordinated LLM-based agents with human-in-the-loop oversight to automate operations in large supermarket chains.
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed, Premkumar Devanbu, Christoph Treude, and Michael Pradel. 2025. Can LLMs Replace Manual Annotation of Software Engineering Artifacts?. InIEEE/ACM International Conference on Mining Software Repositories
work page 2025
-
[2]
Glama AI. 2025. Glama: Your #1 Platform for Discovering Every MCP Server. https://glama.ai/mcp, last visited: May 15
work page 2025
-
[3]
Pydantic AI. 2025. Pydantic-AI: Agent Framework / shim to use Pydantic with LLMs. https://ai.pydantic.dev/, last visited: May 22
work page 2025
-
[4]
Adem Ait, Javier Luis Cánovas Izquierdo, and Jordi Cabot. 2022. An empirical study on the survival rate of GitHub projects. In Proceedings of the 19th International Conference on Mining Software Repositories . 365–375
work page 2022
-
[5]
Jehad Al Dallal and Anas Abdin. 2017. Empirical evaluation of the impact of object-oriented code refactoring on quality attributes: A systematic literature review. IEEE Transactions on Software Engineering 44, 1 (2017), 44–69
work page 2017
-
[6]
Mahmoud Alfadel, Diego Elias Costa, and Emad Shihab. 2023. Empirical analysis of security vulnerabilities in python packages. Empirical Software Engineering 28, 3 (2023), 59
work page 2023
-
[7]
Malak Aljabri, Maryam Aldossary, Noor Al-Homeed, Bushra Alhetelah, Malek Althubiany, Ohoud Alotaibi, and Sara Alsaqer. 2022. Testing and exploiting tools to improve owasp top ten security vulnerabilities detection. In 2022 14th International Conference on Computational Intelligence and Communication Networks (CICN) . IEEE, 797–803
work page 2022
-
[8]
Eman Abdullah AlOmar, Anushkrishna Venkatakrishnan, Mohamed Wiem Mkaouer, Christian Newman, and Ali Ouni. 2024. How to refactor this code? An exploratory study on developer-ChatGPT refactoring conversations. In Proceedings of the 21st International Conference on Mining Software Repositories . 202–206
work page 2024
-
[9]
Idan Amit and Dror G Feitelson. 2021. Corrective commit probability: a measure of the effort invested in bug fixing. Software Quality Journal 29, 4 (2021), 817–861
work page 2021
-
[10]
Anthropic. 2025. Introducing the Model Context Protocol. https://www.anthropic.com/news/model-context-protocol, last visited: Apr 23
work page 2025
-
[11]
Anthropic. 2025. Model Context Protocol: NPM package. https://www.npmjs.com/package/%40modelcontextprotocol/ sdk, last visited: May 18
work page 2025
-
[12]
Anthropic. 2025. Model Context Protocol: PyPi package. https://pypistats.org/packages/mcp, last visited: May 18
work page 2025
-
[13]
Anthropic. 2025. Tool Calling: Tool Usage with Claude. https://docs.anthropic.com/en/docs/agents-and-tools/tool- use/overview, last visited: May 15
work page 2025
-
[14]
Apple. 2025. App Review Guidelines. https://developer.apple.com/app-store/review/guidelines/, last visited: June 03
work page 2025
- [15]
-
[16]
Microsoft Autogen. 2025. AutoGen: A framework for building AI agents and applications. https://microsoft.github.io/ autogen/stable/, last visited: Apr 23
work page 2025
-
[17]
Guilherme Avelino, Eleni Constantinou, Marco Tulio Valente, and Alexander Serebrenik. 2019. On the abandonment and survival of open source projects: An empirical investigation. In 2019 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM) . IEEE, 1–12
work page 2019
-
[18]
Nathaniel Ayewah, William Pugh, J David Morgenthaler, John Penix, and YuQian Zhou. 2007. Evaluating static analysis defect warnings on production software. In Proceedings of the 7th ACM SIGPLAN-SIGSOFT workshop on Program analysis for software tools and engineering . 1–8
work page 2007
-
[19]
Sebastian Baltes, Jascha Knack, Daniel Anastasiou, Ralf Tymann, and Stephan Diehl. 2018. (No) influence of continuous integration on the commit activity in GitHub projects. In Proceedings of the 4th ACM SIGSOFT International Workshop on Software Analytics. 1–7. ACM Trans. Softw. Eng. Methodol., Vol. , No. , Article . Publication date: TBD. Studying the Se...
work page 2018
-
[20]
Lingfeng Bao, Xin Xia, David Lo, and Gail C Murphy. 2019. A large scale study of long-time contributor prediction for github projects. IEEE Transactions on Software Engineering 47, 6 (2019), 1277–1298
work page 2019
-
[21]
Setu Kumar Basak, Lorenzo Neil, Bradley Reaves, and Laurie Williams. 2022. What are the practices for secret management in software artifacts?. In 2022 IEEE Secure Development Conference (SecDev) . IEEE, 69–76
work page 2022
-
[22]
João Helis Bernardo, Daniel Alencar Da Costa, Sérgio Queiroz de Medeiros, and Uirá Kulesza. 2024. How do machine learning projects use continuous integration practices? an empirical study on GitHub actions. In Proceedings of the 21st International Conference on Mining Software Repositories . 665–676
work page 2024
-
[23]
Ethan Bommarito and Michael Bommarito. 2019. An empirical analysis of the python package index (pypi). arXiv preprint arXiv:1907.11073 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Hudson Borges, Andre Hora, and Marco Tulio Valente. 2016. Understanding the factors that impact the popularity of GitHub repositories. In 2016 IEEE international conference on software maintenance and evolution (ICSME) . IEEE, 334–344
work page 2016
-
[26]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901
work page 2020
-
[27]
Simon Butler, Jonas Gamalielsson, Björn Lundell, Christoffer Brax, Anders Mattsson, Tomas Gustavsson, Jonas Feist, Bengt Kvarnström, and Erik Lönroth. 2022. Considerations and challenges for the adoption of open source components in software-intensive businesses. Journal of Systems and Software 186 (2022), 111152
work page 2022
-
[28]
Paolo Calciati and Alessandra Gorla. 2017. How do apps evolve in their permission requests? a preliminary study. In 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR) . IEEE, 37–41
work page 2017
-
[29]
G Ann Campbell and Patroklos P Papapetrou. 2013. SonarQube in action. Manning Publications Co
work page 2013
-
[30]
Giuseppe Castagna and Victor Lanvin. 2017. Gradual typing with union and intersection types. Proceedings of the ACM on Programming Languages 1, ICFP (2017), 1–28
work page 2017
-
[31]
CHAOSS Project. 2025. Community Health Analytics in Open Source Software: Topic - All Metrics. https://chaoss. community/kbtopic/all-metrics/. Accessed: Jun 10, 2025
work page 2025
-
[32]
CHAOSS Project. 2025. Practitioner Guide: Responsiveness. https://chaoss.community/practitioner-guide- responsiveness/. Accessed: May 15, 2025
work page 2025
-
[33]
Bihuan Chen, Linlin Chen, Chen Zhang, and Xin Peng. 2020. Buildfast: History-aware build outcome prediction for fast feedback and reduced cost in continuous integration. InProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. 42–53
work page 2020
-
[34]
Celia Chen, Shi Lin, Michael Shoga, Qing Wang, and Barry Boehm. 2018. How do defects hurt qualities? an empirical study on characterizing a software maintainability ontology in open source software. In 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS) . IEEE, 226–237
work page 2018
-
[35]
Zhifei Chen, Lin Chen, Wanwangying Ma, and Baowen Xu. 2016. Detecting code smells in python programs. In 2016 international conference on Software Analysis, Testing and Evolution (SATE) . IEEE, 18–23
work page 2016
-
[36]
Henry Chesbrough. 2023. Measuring the economic value of open source. San Francisco: Linux Foundation (2023)
work page 2023
-
[37]
Steve Christey and Robert A Martin. 2007. Vulnerability type distributions in CVE. Mitre report, May (2007)
work page 2007
-
[38]
Cloudflare. 2025. Cloudflare Agents Docs: Model Context Protocol (MCP). https://developers.cloudflare.com/agents/ model-context-protocol, last visited: Apr 23
work page 2025
-
[39]
Jailton Coelho and Marco Tulio Valente. 2017. Why modern open source projects fail. In Proceedings of the 2017 11th Joint meeting on foundations of software engineering . 186–196
work page 2017
-
[40]
CrewAI. 2025. CrewAI: The leading multi-agent platform. https://www.crewai.com/, last visited: May 27
work page 2025
-
[41]
Dinis Barroqueiro Cruz, João Rafael Almeida, and José Luís Oliveira. 2023. Open source solutions for vulnerability assessment: A comparative analysis. IEEE Access 11 (2023), 100234–100255
work page 2023
-
[42]
Ozren Dabic, Emad Aghajani, and Gabriele Bavota. 2021. Sampling projects in github for MSR studies. In 2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR) . IEEE, 560–564
work page 2021
-
[43]
Andrey Loskutov Keith Lea David Hovemeyer, Bill Pugh. 2025. An extensible multilanguage static code analyzer. https://findbugs.sourceforge.net/, last visited: May 18
work page 2025
-
[44]
DI De Silva, RD New Kandy, BLO Sachethana, SMDTH Dias, PYC Perera, ME Katipearachchi, and TDDH Jayasuriya
-
[45]
Journal of Software Engineering Research and Development 11, 1 (2023), 1
The Relationship between Code Complexity and Software Quality: An Empirical Study. Journal of Software Engineering Research and Development 11, 1 (2023), 1
work page 2023
-
[46]
Alexandre Decan, Tom Mens, and Eleni Constantinou. 2018. On the impact of security vulnerabilities in the npm package dependency network. In Proceedings of the 15th international conference on mining software repositories . 181–191. ACM Trans. Softw. Eng. Methodol., Vol. , No. , Article . Publication date: TBD. 34 M. Mehedi Hasan et al
work page 2018
-
[47]
Kerstin Denecke, Richard May, LLMHealthGroup, and Octavio Rivera Romero. 2024. Potential of large language models in health care: Delphi study. Journal of Medical Internet Research 26 (2024), e52399
work page 2024
-
[48]
Dify. 2025. Dify: Build Production Ready Agentic Solution. https://dify.ai/, last visited: May 27
work page 2025
-
[49]
Inc Docker et al. 2020. Docker. lınea].[Junio de 2017]. Disponible en: https://www. docker. com/what-docker (2020)
work page 2020
-
[50]
Tore Dybå, Vigdis By Kampenes, and Dag IK Sjøberg. 2006. A systematic review of statistical power in software engineering experiments. Information and Software Technology 48, 8 (2006), 745–755
work page 2006
-
[51]
Filipe Falcão, Caio Barbosa, Baldoino Fonseca, Alessandro Garcia, Márcio Ribeiro, and Rohit Gheyi. 2020. On relating technical, social factors, and the introduction of bugs. In 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER) . IEEE, 378–388
work page 2020
-
[52]
Rosa Falotico and Piero Quatto. 2015. Fleiss’ kappa statistic without paradoxes.Quality & Quantity 49 (2015), 463–470
work page 2015
-
[53]
Amir Hossein Ghapanchi. 2015. Predicting software future sustainability: A longitudinal perspective. Information Systems 49 (2015), 40–51
work page 2015
-
[54]
Sean Goggins, Kevin Lumbard, and Matt Germonprez. 2021. Open source community health: Analytical metrics and their corresponding narratives. In 2021 IEEE/ACM 4th International Workshop on Software Health in Projects, Ecosystems and Communities (SoHeal) . IEEE, 25–33
work page 2021
-
[55]
Software Improvement Group. 2025. State of Software 2025: A Global Report on the Hidden Costs and Risks of Software. https://www.softwareimprovementgroup.com/wp-content/uploads/State-of-software-2025.pdf, last visited: May 08
work page 2025
-
[56]
Aakanshi Gupta, Rashmi Gandhi, Nishtha Jatana, Divya Jatain, Sandeep Kumar Panda, and Janjhyam Venkata Naga Ramesh. 2023. A severity assessment of python code smells. IEEE Access 11 (2023), 119146–119160
work page 2023
-
[57]
Md Shariful Haque, Jeff Carver, and Travis Atkison. 2018. Causes, impacts, and detection approaches of code smell: a survey. In Proceedings of the 2018 ACM Southeast Conference . 1–8
work page 2018
- [58]
-
[59]
https://github.com/SAILResearch/replication-25-mcp- server-empirical-study, last visited: Jun 11
The replication package of our study on MCP Servers. https://github.com/SAILResearch/replication-25-mcp- server-empirical-study, last visited: Jun 11
- [60]
-
[61]
Runzhi He, Hao He, Yuxia Zhang, and Minghui Zhou. 2023. Automating dependency updates in practice: An exploratory study on github dependabot. IEEE Transactions on Software Engineering 49, 8 (2023), 4004–4022
work page 2023
-
[62]
Israel Herraiz, Jesus M Gonzalez-Barahona, and Gregorio Robles. 2008. Determinism and evolution. In Proceedings of the 2008 international working conference on Mining software repositories . 1–10
work page 2008
-
[63]
Michael Hilton, Timothy Tunnell, Kai Huang, Darko Marinov, and Danny Dig. 2016. Usage, costs, and benefits of continuous integration in open-source projects. In Proceedings of the 31st IEEE/ACM international conference on automated software engineering. 426–437
work page 2016
-
[64]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. arXiv preprint arXiv:2503.23278 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
IBM. 2025. Cost of a Data Breach Report 2024. https://www.ibm.com/reports/data-breach, last visited: May 27
work page 2025
-
[66]
Samuel Idowu, Yorick Sens, Thorsten Berger, Jacob Krüger, and Michael Vierhauser. 2024. A large-scale study of ml-related python projects. In Proceedings of the 39th ACM/SIGAPP Symposium on Applied Computing . 1272–1281
work page 2024
-
[67]
Alphabet Inc. 2025. Security checklist. https://developer.android.com/privacy-and-security/security-tips, last visited: June 03
work page 2025
-
[68]
Nenad Jovanovic, Christopher Kruegel, and Engin Kirda. 2006. Pixy: A static analysis tool for detecting web application vulnerabilities. In 2006 IEEE Symposium on Security and Privacy (S&P’06) . IEEE, 6–pp
work page 2006
- [69]
-
[70]
Arvinder Kaur and Ruchikaa Nayyar. 2020. A comparative study of static code analysis tools for vulnerability detection in c/c++ and java source code. Procedia Computer Science 171 (2020), 2023–2029
work page 2020
-
[71]
Noureddine Kerzazi, Foutse Khomh, and Bram Adams. 2014. Why do automated builds break? an empirical study. In 2014 IEEE international conference on software maintenance and evolution . IEEE, 41–50
work page 2014
- [72]
-
[73]
Invariant Lab. 2025. Introducing MCP-Scan: Protecting MCP with Invariant. https://invariantlabs.ai/blog/introducing- mcp-scan, last visited: May 29
work page 2025
-
[74]
Tuan Dung Lai, Anj Simmons, Scott Barnett, Jean-Guy Schneider, and Rajesh Vasa. 2024. Comparative analysis of real issues in open-source machine learning projects. Empirical Software Engineering 29, 3 (2024), 60. ACM Trans. Softw. Eng. Methodol., Vol. , No. , Article . Publication date: TBD. Studying the Security and Maintainability of MCP Servers 35
work page 2024
-
[75]
LangChain. 2025. LangChain: composable framework to build with LLMs . https://www.langchain.com/, last visited: Apr 23
work page 2025
-
[76]
Jasmine Latendresse, Suhaib Mujahid, Diego Elias Costa, and Emad Shihab. 2022. Not all dependencies are equal: An empirical study on production dependencies in npm. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–12
work page 2022
-
[77]
Luigi Lavazza, Sandro Morasca, and Davide Tosi. 2021. Comparing static analysis and code smells as defect predictors: an empirical study. In IFIP international conference on open source systems . Springer, 1–15
work page 2021
-
[78]
Valentina Lenarduzzi, Francesco Lomio, Heikki Huttunen, and Davide Taibi. 2020. Are sonarqube rules inducing bugs?. In 2020 IEEE 27th international conference on software analysis, evolution and reengineering (SANER) . IEEE, 501–511
work page 2020
-
[79]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474
work page 2020
-
[80]
Hao Li and Cor-Paul Bezemer. 2025. Bridging the language gap: an empirical study of bindings for open source machine learning libraries across software package ecosystems. Empirical Software Engineering 30, 1 (2025), 6
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.