Understanding the Challenges and Opportunities of Generative AI Apps: An Empirical Study
Pith reviewed 2026-05-19 08:33 UTC · model grok-4.3
The pith
Analysis of over a million reviews from generative AI mobile apps reveals three opportunities and three challenges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
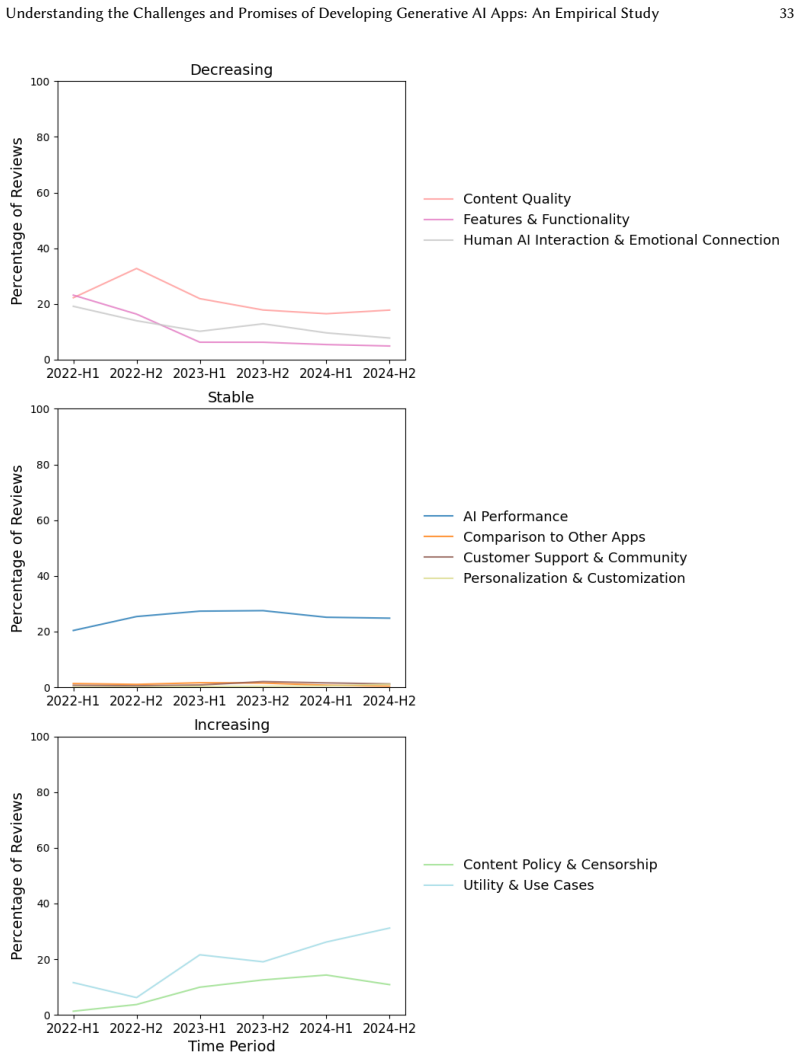
Through qualitative analysis of 762 reviews, the study uncovers three opportunities (AI for Accessibility and Wellbeing, AI as a Collaborative Creative Tool, and AI Versatility) and three challenges (Managing User Expectations and AI Limitations, Balancing Content Moderation and Creative Freedom, and Strategic Integration of Gen-AI Features).
What carries the argument
The SARA (Selection, Acquisition, Refinement, and Analysis) framework that applies prompt-based large language models to extract and assign topics from large review datasets, validated at 91 percent accuracy.
If this is right
- Developers can prioritize accessibility and wellbeing features to increase user satisfaction.
- Clear communication about AI capabilities helps reduce frustration from unmet expectations.
- Apps must carefully tune content moderation to preserve creative freedom.
- Strategic and gradual integration of generative AI features prevents user overload.
- User concerns evolve over time, so ongoing monitoring of reviews can guide updates.
Where Pith is reading between the lines
- The same review-analysis approach could be applied to other categories of AI-driven consumer tools.
- Similar patterns may appear when studying user feedback on desktop or web-based generative AI services.
- Developers in non-mobile domains might adapt the identified opportunities to design more inclusive AI products.
Load-bearing premise
The chosen apps and their reviews from one major app store accurately represent the experiences and perceptions of users with generative AI apps overall.
What would settle it
A follow-up study applying the same method to reviews from a different platform or a fresh collection of generative AI apps that surfaces a substantially different set of opportunities and challenges.
Figures




















read the original abstract
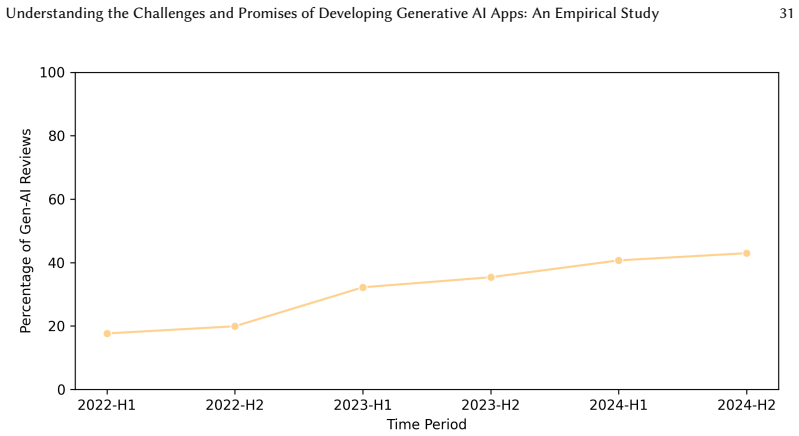
The release of ChatGPT in 2022 triggered a rapid surge in generative artificial intelligence mobile apps (Gen-AI apps). Despite widespread adoption, little is known about how end users perceive and evaluate these Gen-AI functionalities. We conduct a user-centered analysis of 1,035,342 reviews from 171 Gen-AI apps from the Google Play Store. We propose SARA (Selection, Acquisition, Refinement, and Analysis), a four-phase framework that leverages prompt-based LLMs for large-scale review analysis. We validate the reliability of LLM-based topic extraction and assignment using 4,353 manually evaluated reviews, achieving 91% accuracy with five-shot prompting and filtering of non-informative reviews. We identify the top ten topics (e.g., AI Performance and Emotional Connection) and perform a cross-platform comparison with Apple App Store reviews. Through qualitative analysis of 762 reviews, we uncover three opportunities (AI for Accessibility and Wellbeing, AI as a Collaborative Creative Tool, and AI Versatility) and three challenges (Managing User Expectations and AI Limitations, Balancing Content Moderation and Creative Freedom, and Strategic Integration of Gen-AI Features). Finally, we analyze temporal trends, revealing how user concerns shift as users mature. Our findings enable researchers and developers to better leverage the capabilities of Gen-AI apps and address potential challenges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study analyzing 1,035,342 user reviews from 171 generative AI apps on the Google Play Store. It introduces the SARA framework for LLM-based large-scale review analysis, validates LLM topic extraction and assignment at 91% accuracy on a 4,353-review manually evaluated subset using five-shot prompting, identifies the top ten topics, conducts a cross-platform comparison with Apple App Store reviews, performs qualitative analysis on 762 reviews to derive three opportunities (AI for Accessibility and Wellbeing, AI as a Collaborative Creative Tool, AI Versatility) and three challenges (Managing User Expectations and AI Limitations, Balancing Content Moderation and Creative Freedom, Strategic Integration of Gen-AI Features), and examines temporal trends in user concerns.
Significance. If the methodological details are clarified and the qualitative findings are shown to be robust, the work would offer useful empirical insights for software engineering researchers and practitioners on user perceptions of generative AI features in mobile apps, particularly the identified opportunities and challenges that could inform feature design and integration strategies.
major comments (2)
- [Qualitative analysis section] The selection criteria and sampling method for the 762 reviews used in the qualitative analysis (e.g., random, stratified by topic/sentiment, or LLM-confidence threshold) are not described. This is load-bearing for the central claim of uncovering the three opportunities and three challenges, as non-random selection could over-represent extreme or high-engagement reviews and bias the resulting themes relative to the filtered 1M-review corpus.
- [Methods and validation subsections] Details on app selection criteria for the 171 Gen-AI apps, the exact prompt engineering used in five-shot prompting, and any post-hoc filtering effects after SARA's refinement phase are insufficiently specified. These omissions limit assessment of whether the 91% accuracy on the 4,353-review validation set extends without major bias to the full dataset and whether the sample is representative of generative AI apps overall.
minor comments (2)
- [Cross-platform comparison section] Clarify the scale and selection process for the Apple App Store comparison dataset to provide better context for the cross-platform findings.
- [Qualitative analysis section] Add explicit inter-rater agreement metrics or saturation criteria for the qualitative coding of the 762 reviews to improve replicability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will incorporate clarifications to enhance methodological transparency.
read point-by-point responses
-
Referee: [Qualitative analysis section] The selection criteria and sampling method for the 762 reviews used in the qualitative analysis (e.g., random, stratified by topic/sentiment, or LLM-confidence threshold) are not described. This is load-bearing for the central claim of uncovering the three opportunities and three challenges, as non-random selection could over-represent extreme or high-engagement reviews and bias the resulting themes relative to the filtered 1M-review corpus.
Authors: We agree that the selection criteria and sampling method for the 762 reviews require explicit description. These reviews were drawn from the post-SARA filtered corpus of informative reviews, with sampling designed to ensure coverage across the top topics while prioritizing reviews with clear user sentiment. We will revise the qualitative analysis section to detail the exact procedure (including any stratification by topic or confidence thresholds) and add a brief discussion of how this approach relates to the broader corpus. This change will be included in the revised manuscript. revision: yes
-
Referee: [Methods and validation subsections] Details on app selection criteria for the 171 Gen-AI apps, the exact prompt engineering used in five-shot prompting, and any post-hoc filtering effects after SARA's refinement phase are insufficiently specified. These omissions limit assessment of whether the 91% accuracy on the 4,353-review validation set extends without major bias to the full dataset and whether the sample is representative of generative AI apps overall.
Authors: We acknowledge that additional specification is needed for reproducibility and to support claims about generalizability. We will expand the methods and validation subsections to include the precise app selection criteria (search keywords, minimum review count, and verification steps), the full five-shot prompts employed for topic extraction and assignment, and a description of any post-refinement filtering steps and their impact on the dataset. These additions will allow readers to better evaluate the extension of the 91% validation accuracy to the full 1M-review corpus. revision: yes
Circularity Check
No circularity: purely empirical analysis of external review data
full rationale
The paper conducts a user-centered empirical study of 1,035,342 reviews from 171 Gen-AI apps using the SARA framework for LLM-assisted filtering and topic extraction, followed by qualitative coding of 762 reviews to identify opportunities and challenges. Validation is performed via manual evaluation of a 4,353-review sample achieving 91% accuracy. No mathematical derivations, equations, fitted parameters, predictions, or self-referential loops exist. Themes emerge directly from external user-review data rather than being defined in terms of themselves or imported via self-citation chains. The analysis is self-contained against external benchmarks and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User reviews posted on app stores accurately and representatively reflect real user experiences with generative AI features.
Forward citations
Cited by 4 Pith papers
-
Collaborator or Assistant? How AI Coding Agents Partition Work Across Pull Request Lifecycles
AI coding agents are classified along a Collaborator-Assistant spectrum using an Initiator x Approver taxonomy on 29,585 PR lifecycles, revealing agent initiation in collaborator tools but near-universal human merge g...
-
Collaborator or Assistant? How AI Coding Agents Partition Work Across Pull Request Lifecycles
AI coding tools divide into collaborators that initiate most PRs and assistants that support human-led ones, yet humans retain merge authority across all five tools examined.
-
From Assistance to Agency: Rethinking Autonomy and Control in CI/CD Pipelines
The central challenge in AI-augmented CI/CD is designing authority transfer from humans to agents under constraints, as current systems remain limited to bounded data-plane autonomy backed by external governance.
-
A Survey of Context Engineering for Large Language Models
The survey organizes Context Engineering into retrieval, processing, management, and integrated systems like RAG and multi-agent setups while identifying an asymmetry where LLMs handle complex inputs well but struggle...
Reference graph
Works this paper leans on
-
[1]
Zarif Bin Akhtar. 2024. Unveiling the evolution of generative AI (GAI): a comprehensive and investigative analysis toward LLM models (2021–2024) and beyond. Journal of Electrical Systems and Information Technology 11, 1 (June 2024), 22. https://doi.org/10.1186/s43067-024-00145-1
-
[2]
Zakaria, Wan Mohd Amir Fazamin Wan Hamzah, and Stenin N P
Hassan Al Wahshat, Waheeb Abu-ulbeh, M Hafiz Yusoff, Muhammad D. Zakaria, Wan Mohd Amir Fazamin Wan Hamzah, and Stenin N P. 2023. The Detection of E-Commerce Manipulated Reviews Using GPT-4. In 2023 International Conference on Computer Science and Emerging Technologies (CSET) . IEEE, Bangalore, India, 1–6. https://doi.org/10.1109/CSET58993.2023.10346848
-
[3]
Nimasha Arambepola, Waruni Lalendra Wimalasena, and Lankeshwara Munasinghe. 2025. From Conventional Methods to Large Language Models: A Systematic Review of Techniques in Mobile App Review Analysis. Interdisciplinary Journal of Information, Knowledge, and Management 20 (2025), 016. https://doi.org/10.28945/5491
-
[4]
Nimasha Arambepola, Lankeshwara Munasinghe, and Nalin Warnajith. 2024. Factors Influencing Mobile App User Experience: An Analysis of Education App User Reviews. In 2024 4th International Conference on Advanced Research in Computing (ICARC). 223–228. https://doi.org/10.1109/ICARC61713.2024.10499727
-
[5]
Ilham Firman Ashari, Eko Dwi Nugroho, Randi Baraku, Ilham Novri Yanda, and Ridho Liwardana. 2023. Analysis of Elbow, Silhouette, Davies-Bouldin, Calinski-Harabasz, and Rand-Index Evaluation on K-Means Algorithm for Classifying Flood-Affected Areas in Jakarta. Journal of Applied Informatics and Computing 7, 1 (July 2023), 89–97. https://doi.org/10.30871/ja...
-
[6]
Maram Assi, Safwat Hassan, Yuan Tian, and Ying Zou. 2021. FeatCompare: Feature comparison for competing mobile apps leveraging user reviews. Empirical Software Engineering 26, 5 (Sept. 2021), 94. https://doi.org/10.1007/s10664- 021-09988-y
-
[7]
Maram Assi, Safwat Hassan, Yuan Tian, and Ying Zou. 2021. FeatCompare: Feature comparison for competing mobile apps leveraging user reviews. Empirical Software Engineering 26, 5 (2021), 94
work page 2021
-
[8]
Maram Assi, Safwat Hassan, and Ying Zou. 2025. LLM-Cure: LLM-based Competitor User Review Analysis for Feature Enhancement. ACM Trans. Softw. Eng. Methodol. (June 2025). https://doi.org/10.1145/3744644
-
[9]
Maram Assi, Safwat Hassan, and Ying Zou. 2025. Unraveling Code Clone Dynamics in Deep Learning Frameworks. ACM Trans. Softw. Eng. Methodol. (Feb. 2025). https://doi.org/10.1145/3721125 Just Accepted
-
[10]
Robert J. Cabin and Randall J. Mitchell. 2000. To Bonferroni or Not to Bonferroni: When and How Are the Questions. Bulletin of the Ecological Society of America 81, 3 (2000), 246–248. http://www.jstor.org/stable/20168454
-
[11]
Laura Ceci. 2025. Mobile App Usage - Statistics & Facts. https://www.statista.com/topics/1002/mobile-app-usage/ #topicOverview [Online]. Accessed: 2025-03-07
work page 2025
-
[12]
Yvonne Chan and Roy P Walmsley. 1997. Learning and Understanding the Kruskal-Wallis One-Way Analysis-of- Variance-by-Ranks Test for Differences Among Three or More Independent Groups. Physical Therapy 77, 12 (Dec. 1997), 1755–1761. https://doi.org/10.1093/ptj/77.12.1755
-
[13]
Bissyandé, Jacques Klein, and Li Li
Daihang Chen, Yonghui Liu, Mingyi Zhou, Yanjie Zhao, Haoyu Wang, Shuai Wang, Xiao Chen, Tegawendé F. Bissyandé, Jacques Klein, and Li Li. 2025. LLM for Mobile: An Initial Roadmap. ACM Trans. Softw. Eng. Methodol. 34, 5, Article 128 (May 2025), 29 pages. https://doi.org/10.1145/3708528
-
[14]
Ning Chen, Jialiu Lin, Steven C. H. Hoi, Xiaokui Xiao, and Boshen Zhang. 2014. AR-miner: mining informative reviews for developers from mobile app marketplace. InProceedings of the 36th International Conference on Software Engineering . ACM, Hyderabad India, 767–778. https://doi.org/10.1145/2568225.2568263
-
[15]
Xiang Chen, Chaoyang Gao, Chunyang Chen, Guangbei Zhang, and Yong Liu. 2025. An Empirical Study on Challenges for LLM Application Developers. ACM Transactions on Software Engineering and Methodology (Jan. 2025), 3715007. https://doi.org/10.1145/3715007
-
[16]
J. Cohen. 1960. A Coefficient of Agreement for Nominal Scales. Educational and Psychological Measurement 20, 1 (1960), 37–46. https://doi.org/10.1177/001316446002000104
-
[17]
Manoranjan Dash and Poon Wei Koot. 2009. Feature Selection for Clustering . Springer US, Boston, MA, 1119–1125. https://doi.org/10.1007/978-0-387-39940-9_613
-
[18]
Data Science Horizons. 2023. Mastering Generative AI and Prompt Engineering. https://datasciencehorizons.com/ pub/Mastering_Generative_AI_Prompt_Engineering_Data_Science_Horizons_v1.pdf
work page 2023
-
[19]
Rushali Deshmukh, Rutuj Raut, Mayur Bhavsar, Sanika Gurav, and Yash Patil. 2025. Optimizing Human-AI Interaction: Innovations in Prompt Engineering. In2025 3rd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT). IEEE, Bengaluru, India, 1240–1246. https://doi.org/10.1109/IDCIOT64235.2025.10914815
-
[20]
Paulo Sérgio Henrique Dos Santos, Alberto Dumont Alves Oliveira, Thais Bonjorni Nobre De Jesus, Wajdi Aljedaani, and Marcelo Medeiros Eler. 2023. Evolution may come with a price: analyzing user reviews to understand the impact of updates on mobile apps accessibility. InProceedings of the XXII Brazilian Symposium on Human Factors in Computing Systems. ACM,...
-
[21]
Rahul Dwivedi and Lavanya Elluri. 2024. Exploring Generative Artificial Intelligence Research: A Bibliometric Analysis Approach. IEEE Access 12 (2024), 119884–119902. https://doi.org/10.1109/ACCESS.2024.3450629
-
[22]
Stefan Feuerriegel, Jochen Hartmann, Christian Janiesch, and Patrick Zschech. 2024. Generative AI. Business & Information Systems Engineering 66, 1 (Feb. 2024), 111–126. https://doi.org/10.1007/s12599-023-00834-7
-
[23]
Necmiye Genc-Nayebi and Alain Abran. 2017. A systematic literature review: Opinion mining studies from mobile app store user reviews. Journal of Systems and Software 125 (March 2017), 207–219. https://doi.org/10.1016/j.jss.2016.11.027
-
[24]
Tanmai Kumar Ghosh, Atharva Pargaonkar, and Nasir U. Eisty. 2024. Exploring Requirements Elicitation from App Store User Reviews Using Large Language Models. (2024). https://doi.org/10.48550/ARXIV.2409.15473
-
[25]
Louie Giray. 2023. Prompt Engineering with ChatGPT: A Guide for Academic Writers.Annals of Biomedical Engineering 51, 12 (Dec. 2023), 2629–2633. https://doi.org/10.1007/s10439-023-03272-4
-
[26]
Golding, Anne Lippert, Jeffrey S
Jonathan M. Golding, Anne Lippert, Jeffrey S. Neuschatz, Ilyssa Salomon, and Kelly Burke. 2024. Generative AI and College Students: Use and Perceptions. Teaching of Psychology (Sept. 2024), 00986283241280350. https://doi.org/10. 1177/00986283241280350
work page 2024
-
[27]
Roberto Gozalo-Brizuela and Eduardo C. Garrido-Merchán. 2023. A survey of Generative AI Applications. https: //doi.org/10.48550/arXiv.2306.02781 arXiv:2306.02781 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.02781 2023
-
[28]
Jennifer Haase, Djordje Djurica, and Jan Mendling. 2023. The art of inspiring creativity: Exploring the unique impact of AI-generated images. (2023)
work page 2023
-
[29]
Muhammad Usman Hadi, Qasem Al Tashi, Rizwan Qureshi, Abbas Shah, Amgad Muneer, Muhammad Irfan, Anas Zafar, Muhammad Bilal Shaikh, Naveed Akhtar, Jia Wu, and Seyedali Mirjalili. 2023. Large Language Models: A , Vol. 1, No. 1, Article . Publication date: September 2025. Understanding the Challenges and Promises of Developing Generative AI Apps: An Empirical...
-
[30]
Safwat Hassan, Heng Li, and Ahmed E. Hassan. 2022. On the Importance of Performing App Analysis Within Peer Groups. In Proceedings of the 29th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) (SANER ’22). 1–12
work page 2022
-
[31]
Kimberly Hau, Safwat Hassan, and Shurui Zhou. 2025. LLMs in Mobile Apps: Practices, Challenges, and Opportunities. In 2025 IEEE/ACM 12th International Conference on Mobile Software Engineering and Systems (MOBILESoft) . 3–14. https://doi.org/10.1109/MOBILESoft66462.2025.00008
-
[32]
Jia He, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X. Wang, and Sadid Hasan. 2024. Does Prompt Formatting Have Any Impact on LLM Performance? arXiv:2411.10541 (Nov. 2024). https://doi.org/10.48550/arXiv. 2411.10541 arXiv:2411.10541 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[33]
Michael V. Heinz, Daniel M. Mackin, Brianna M. Trudeau, Sukanya Bhattacharya, Yinzhou Wang, Haley A. Banta, Abi D. Jewett, Abigail J. Salzhauer, Tess Z. Griffin, and Nicholas C. Jacobson. 2025. Randomized Trial of a Generative AI Chatbot for Mental Health Treatment. NEJM AI 2, 4 (March 2025). https://doi.org/10.1056/AIoa2400802
-
[34]
Brittany Ho, Ta’Rhonda Mayberry, Khanh Linh Nguyen, Manohar Dhulipala, and Vivek Krishnamani Pallipuram
-
[35]
Machine Learning with Applications 15 (March 2024), 100522
ChatReview: A ChatGPT-enabled natural language processing framework to study domain-specific user reviews. Machine Learning with Applications 15 (March 2024), 100522. https://doi.org/10.1016/j.mlwa.2023.100522
-
[36]
Abiodun M. Ikotun, Absalom E. Ezugwu, Laith Abualigah, Belal Abuhaija, and Jia Heming. 2023. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Information Sciences 622 (April 2023), 178–210. https://doi.org/10.1016/j.ins.2022.11.139
-
[37]
Aamo Iorliam and Joseph Abunimye Ingio. 2024. A Comparative Analysis of Generative Artificial Intelligence Tools for Natural Language Processing. Journal of Computing Theories and Applications 1, 3 (Feb. 2024), 311–325. https://doi.org/10.62411/jcta.9447
-
[38]
I Don’t Know Why I Should Use This App
Seungwan Jin, Bogoan Kim, and Kyungsik Han. 2025. “I Don’t Know Why I Should Use This App”: Holistic Analysis on User Engagement Challenges in Mobile Mental Health. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM, Yokohama Japan, 1–23. https://doi.org/10.1145/3706598.3713732
-
[39]
Charles M. Judd, Gary H. McClelland, and Carey S. Ryan. 2017. Data Analysis: A Model Comparison Approach to Regression, ANOV A, and Beyond (3 ed.). Routledge, Third Edition. | New York: Routledge, 2017. | Revised edition. https://doi.org/10.4324/9781315744131
-
[40]
Aakriti Kheterpal and Kanwarpartap Singh Gill. 2024. Therapeutic Tech: A Comparative Study of AI-Driven Mental Health Interventions. In 2024 4th International Conference on Advancement in Electronics & Communication Engineering (AECE). 1187–1190. https://doi.org/10.1109/AECE62803.2024.10911418
-
[41]
Grohs, Hoda Eldardiry, James Weichert, Larry A
Junghwan Kim, Michelle Klopfer, Jacob R. Grohs, Hoda Eldardiry, James Weichert, Larry A. Cox, and Dale Pike. 2025. Examining Faculty and Student Perceptions of Generative AI in University Courses. Innovative Higher Education (Jan. 2025). https://doi.org/10.1007/s10755-024-09774-w
-
[42]
Jinhee Kim, Seongryeong Yu, Rita Detrick, and Na Li. 2025. Exploring students’ perspectives on Generative AI-assisted academic writing. Education and Information Technologies 30, 1 (Jan. 2025), 1265–1300. https://doi.org/10.1007/s10639- 024-12878-7
-
[43]
Anil Koyuncu. 2025. Exploring Fine-Grained Bug Report Categorization with Large Language Models and Prompt Engineering: An Empirical Study. ACM Trans. Softw. Eng. Methodol. (May 2025). https://doi.org/10.1145/3736408 Just Accepted
-
[44]
Jannis Kreienkamp, Maximilian Agostini, Rei Monden, Kai Epstude, Peter De Jonge, and Laura F. Bringmann. 2025. A Gentle Introduction and Application of Feature-Based Clustering with Psychological Time Series. Multivariate Behavioral Research 60, 2 (March 2025), 362–392. https://doi.org/10.1080/00273171.2024.2432918
-
[45]
Daniel Lee, Matthew Arnold, Amit Srivastava, Katrina Plastow, Peter Strelan, Florian Ploeckl, Dimitra Lekkas, and Edward Palmer. 2024. The impact of generative AI on higher education learning and teaching: A study of educators’ perspectives. Computers and Education: Artificial Intelligence 6 (June 2024), 100221. https://doi.org/10.1016/j.caeai. 2024.100221
-
[46]
Seung-Cheol Lee, Dong-Gun Lee, and Yeong-Seok Seo. 2024. Determining the best feature combination through text and probabilistic feature analysis for GPT-2-based mobile app review detection. Applied Intelligence 54, 2 (Jan. 2024), 1219–1246. https://doi.org/10.1007/s10489-023-05201-3
-
[47]
Raga Madhuri, Jaya Sankar Krishna Bandaru, Medisetti Srinu, and Gangadhari Midhun Anand Vardhan
C H. Raga Madhuri, Jaya Sankar Krishna Bandaru, Medisetti Srinu, and Gangadhari Midhun Anand Vardhan. 2025. AI-Powered Mental Health Screening and Support for Homeless Children. In 2025 AI-Driven Smart Healthcare for Society 5.0. 115–120. https://doi.org/10.1109/IEEECONF64992.2025.10963316
-
[48]
H. B. Mann and D. R. Whitney. 1947. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. The Annals of Mathematical Statistics 18, 1 (March 1947), 50–60. https://doi.org/10.1214/aoms/1177730491 , Vol. 1, No. 1, Article . Publication date: September 2025. 44 Buthayna AlMulla, Maram Assi, and Safwat Hassan
-
[49]
Ggaliwango Marvin, Nakayiza Hellen, Daudi Jjingo, and Joyce Nakatumba-Nabende. 2024. Prompt Engineering in Large Language Models. Springer Nature Singapore, Singapore, 387–402. https://doi.org/10.1007/978-981-99-7962-2_30
-
[50]
J. Mingyu. n.d.. Google Play Scraper. GitHub repository. https://github.com/JoMingyu/google-play-scraper Accessed: 13-Oct-2024
work page 2024
-
[51]
Nadia Nahar, Christian Kästner, Jenna Butler, Chris Parnin, Thomas Zimmermann, and Christian Bird. 2024. Be- yond the Comfort Zone: Emerging Solutions to Overcome Challenges in Integrating LLMs into Software Products. arXiv:2410.12071 (Dec. 2024). https://doi.org/10.48550/arXiv.2410.12071 arXiv:2410.12071 [cs]
-
[52]
OpenAI. 2023. GPT-4: Generative Pre-trained Transformer. Online. Available at https://openai.com/research/gpt-4, Accessed: 03-Mar-2025
work page 2023
-
[53]
OpenAI. 2024. ChatGPT Edu. https://openai.com/chatgpt/education/. Accessed: 2025-06-13
work page 2024
-
[54]
OpenAI. 2024. gpt-4o-mini Model Overview. https://platform.openai.com/docs/models/o4-mini Accessed: 2025-05-24
work page 2024
-
[55]
Jonas Oppenlaender, Johanna Silvennoinen, Ville Paananen, and Aku Visuri. 2023. Perceptions and Realities of Text-to- Image Generation. In Proceedings of the 26th International Academic Mindtrek Conference (Tampere, Finland) (Mindtrek ’23). Association for Computing Machinery, New York, NY, USA, 279–288. https://doi.org/10.1145/3616961.3616978
-
[56]
Dennis Pagano and Walid Maalej. 2013. User feedback in the appstore: An empirical study. In2013 21st IEEE International Requirements Engineering Conference (RE) . IEEE, Rio de Janeiro-RJ, Brazil, 125–134. https://doi.org/10.1109/RE.2013. 6636712
-
[57]
Victor Dos Santos Paulino and Sveinn Vidar Gudmundsson. 2024. Do early adopters raise barriers to the commercial take- up of strategic high-technology products? Innovation (aug 2024), 1–18. https://doi.org/10.1080/14479338.2024.2386239
-
[58]
Vitali Petsiuk, Alexander E. Siemenn, Saisamrit Surbehera, Zad Chin, Keith Tyser, Gregory Hunter, Arvind Raghavan, Yann Hicke, Bryan A. Plummer, Ori Kerret, Tonio Buonassisi, Kate Saenko, Armando Solar-Lezama, and Iddo Drori
- [59]
-
[60]
Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer. 2024. TopicGPT: A Prompt-based Topic Modeling Framework. arXiv:2311.01449 (April 2024). https://doi.org/10.48550/arXiv.2311.01449 arXiv:2311.01449 [cs]
-
[61]
Nirmalendu Prakash, Han Wang, Nguyen Khoi Hoang, Ming Shan Hee, and Roy Ka-Wei Lee. 2023. PromptMTopic: Unsupervised Multimodal Topic Modeling of Memes using Large Language Models. In Proceedings of the 31st ACM International Conference on Multimedia . ACM, Ottawa ON Canada, 621–631. https://doi.org/10.1145/3581783.3613836
-
[62]
Societal biases in language generation: Progress and challenges
Inioluwa Deborah Raji, I. Elizabeth Kumar, Aaron Horowitz, and Andrew Selbst. 2022. The Fallacy of AI Functionality. In 2022 ACM Conference on Fairness Accountability and Transparency . ACM, Seoul Republic of Korea, 959–972. https: //doi.org/10.1145/3531146.3533158
-
[63]
Harish Rathod and Sanjay Agal. 2023. A Study and Overview on Current Trends and Technology in Mobile Applications & Its Development. Lecture Notes in Networks and Systems, Vol. 754. Springer Nature Singapore, 383–395. https: //doi.org/10.1007/978-981-99-4932-8_35
-
[64]
Shuaicai Ren, Hiroyuki Nakagawa, and Tatsuhiro Tsuchiya. 2024. Combining Prompts with Examples to Enhance LLM- Based Requirement Elicitation. In 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC) . 1376–1381. https://doi.org/10.1109/COMPSAC61105.2024.00181
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/compsac61105.2024.00181 2024
-
[65]
Ali Rezaei Nasab, Maedeh Dashti, Mojtaba Shahin, Mansooreh Zahedi, Hourieh Khalajzadeh, Chetan Arora, and Peng Liang. 2025. Fairness Concerns in App Reviews: A Study on AI-Based Mobile Apps. ACM Transactions on Software Engineering and Methodology 34, 2 (Feb. 2025), 1–30. https://doi.org/10.1145/3690633
-
[66]
Konstantinos I. Roumeliotis, Nikolaos D. Tselikas, and Dimitrios K. Nasiopoulos. 2024. LLMs in e-commerce: A comparative analysis of GPT and LLaMA models in product review evaluation. Natural Language Processing Journal 6 (March 2024), 100056. https://doi.org/10.1016/j.nlp.2024.100056
-
[67]
Dharshini S, Samson Arun Raj A, and Venkatesan R. 2025. MindMate: AI-Powered Multilingual Mental Health Chatbot with Personalized Voice and Text Support with Rasa and Streamlit. In 2025 International Conference on Intelligent Computing and Control Systems (ICICCS) . 1104–1109. https://doi.org/10.1109/ICICCS65191.2025.10985281
-
[68]
Sandeep Singh Sengar, Affan Bin Hasan, Sanjay Kumar, and Fiona Carroll. 2024. Generative artificial intelligence: a systematic review and applications. Multimedia Tools and Applications (Aug. 2024). https://doi.org/10.1007/s11042- 024-20016-1
-
[69]
Yuchen Shao, Yuheng Huang, Jiawei Shen, Lei Ma, Ting Su, and Chengcheng Wan. 2025. Are LLMs Correctly Integrated into Software Systems?. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, Los Alamitos, CA, USA, 1178–1190. https://doi.org/10.1109/ICSE55347.2025.00204
-
[70]
Dhruv S. Sharma and Jitendra Patel. 2024. AI and Mental Health: A New Era of Healing. In 2024 2nd DMIHER International Conference on Artificial Intelligence in Healthcare, Education and Industry (IDICAIEI) . 1–5. https://doi.org/ 10.1109/IDICAIEI61867.2024.10842666 , Vol. 1, No. 1, Article . Publication date: September 2025. Understanding the Challenges a...
-
[71]
Aya Shata and Kendall Hartley. 2025. Artificial intelligence and communication technologies in academia: faculty perceptions and the adoption of generative AI. International Journal of Educational Technology in Higher Education 22, 1 (March 2025), 14. https://doi.org/10.1186/s41239-025-00511-7
-
[72]
Aakash Sorathiya and Gouri Ginde. 2024. Beyond Keywords: A Context-based Hybrid Approach to Mining Ethical Concern-related App Reviews. arXiv:2411.07398 (Nov. 2024). https://doi.org/10.48550/arXiv.2411.07398 arXiv:2411.07398 [cs]
-
[73]
Yuying Tang, Ningning Zhang, Mariana Ciancia, and Zhigang Wang. 2024. Exploring the Impact of AI-generated Image Tools on Professional and Non-professional Users in the Art and Design Fields. In Companion Publication of the 2024 Conference on Computer-Supported Cooperative Work and Social Computing (San Jose, Costa Rica) (CSCW Companion ’24). Association ...
-
[74]
Liang Wang, Nan Yang, and Furu Wei. 2023. Learning to Retrieve In-Context Examples for Large Language Models. (2023). https://doi.org/10.48550/ARXIV.2307.07164
-
[75]
T. Warren Liao. 2005. Clustering of time series data—a survey. Pattern Recognition 38, 11 (Nov. 2005), 1857–1874. https://doi.org/10.1016/j.patcog.2005.01.025
-
[76]
Jialiang Wei, Anne-Lise Courbis, Thomas Lambolais, Binbin Xu, Pierre Louis Bernard, and Gérard Dray. 2023. Zero-shot Bilingual App Reviews Mining with Large Language Models. In 2023 IEEE 35th International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, Atlanta, GA, USA, 898–904. https://doi.org/10.1109/ICTAI59109.2023.00135
-
[77]
Connie Levina Yuen and Nadja Schlote. 2024. Learner Experiences of Mobile Apps and Artificial Intelligence to Support Additional Language Learning in Education. Journal of Educational Technology Systems 52, 4 (June 2024), 507–525. https://doi.org/10.1177/00472395241238693
-
[78]
Ye Zhang, Jinrui Zhang, Sheng Yue, Wei Lu, Ju Ren, and Xuemin Shen. 2024. Mobile Generative AI: Opportunities and Challenges. IEEE Wireless Communications 31, 4 (2024), 58–64. https://doi.org/10.1109/MWC.006.2300576 , Vol. 1, No. 1, Article . Publication date: September 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.