xRFM: Accurate, scalable, and interpretable feature learning models for tabular data
Pith reviewed 2026-05-18 23:03 UTC · model grok-4.3
The pith
xRFM combines feature learning kernel machines with trees to achieve top accuracy on tabular regression while scaling to unlimited data and supplying native interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
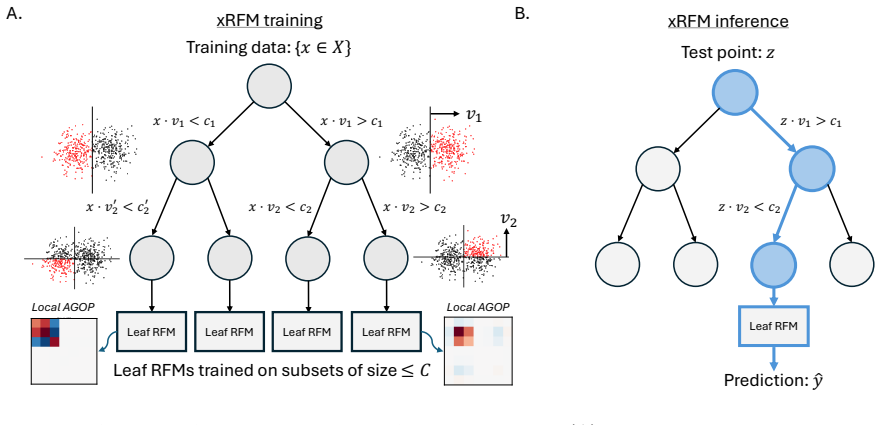
xRFM integrates feature learning kernel machines into a tree framework so the model both respects local data geometry and trains at unlimited scale; this produces the best results among 31 compared methods on 100 regression datasets, competitive results on 200 classification datasets while beating GBDTs, and direct interpretability through the Average Gradient Outer Product.
What carries the argument
The xRFM algorithm that fuses feature learning kernel machines with a tree structure and extracts interpretability from the Average Gradient Outer Product.
If this is right
- xRFM scales training to arbitrarily large tabular datasets without accuracy loss.
- Native interpretability is available through the Average Gradient Outer Product on every prediction.
- The same model handles both regression and classification tasks competitively.
- Performance exceeds or matches GBDTs and recent neural tabular models across hundreds of real-world datasets.
Where Pith is reading between the lines
- Similar kernel-plus-tree hybrids could be explored for structured data outside the tabular setting.
- The approach suggests that pure neural or pure tree methods may not be necessary for high-accuracy tabular work.
- Built-in gradient-based interpretability may prove useful in scientific or regulatory settings that require feature explanations.
- Further scaling experiments on datasets larger than those tested could confirm the unlimited-data claim.
Load-bearing premise
Combining kernel feature learning with trees will keep predictive accuracy high without introducing hidden costs in speed or reliability across the tested data regimes.
What would settle it
A fresh collection of tabular regression datasets on which xRFM records lower accuracy than the leading GBDT or TabPFN variant would falsify the performance claims.
Figures








read the original abstract
Inference from tabular data, collections of continuous and categorical variables organized into matrices, is a foundation for modern technology and science. Yet, in contrast to the explosive changes in the rest of AI, the best practice for these predictive tasks has been relatively unchanged and is still primarily based on variations of Gradient Boosted Decision Trees (GBDTs). Very recently, there has been renewed interest in developing state-of-the-art methods for tabular data based on recent developments in neural networks and feature learning methods. In this work, we introduce xRFM, an algorithm that combines feature learning kernel machines with a tree structure to both adapt to the local structure of the data and scale to essentially unlimited amounts of training data. We show that compared to $31$ other methods, including recently introduced tabular foundation models (TabPFNv2) and GBDTs, xRFM achieves best performance across $100$ regression datasets and is competitive to the best methods across $200$ classification datasets outperforming GBDTs. Additionally, xRFM provides interpretability natively through the Average Gradient Outer Product.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces xRFM, an algorithm that integrates feature learning kernel machines with a tree structure to adapt to local data structure while scaling to large training sets. It reports that xRFM achieves the best performance across 100 regression datasets and is competitive with the best methods across 200 classification datasets when compared to 31 baselines including TabPFNv2 and GBDTs, while providing native interpretability through the Average Gradient Outer Product.
Significance. If the empirical claims hold under controlled experimental conditions, xRFM would constitute a meaningful contribution to tabular modeling by offering a scalable, interpretable alternative to GBDTs and recent neural foundation models. The native interpretability mechanism via Average Gradient Outer Product is a potentially valuable feature if rigorously validated.
major comments (1)
- [Section 4 and Section 5] Section 4 (Experimental Setup) and Section 5 (Results): The central performance claim—that xRFM outperforms or matches 31 methods including TabPFNv2 and GBDTs on 100 regression and 200 classification datasets—is load-bearing. The manuscript does not specify the hyperparameter tuning protocol, search budget, or whether equivalent effort was applied to all baselines (e.g., whether defaults or limited tuning were used for some GBDT variants or TabPFNv2). Without this information, the ranking cannot be confidently attributed to the method rather than experimental procedure.
minor comments (2)
- [Abstract] The abstract states that xRFM scales to 'essentially unlimited amounts of training data,' but the main text would benefit from explicit scaling curves or memory/time measurements on progressively larger datasets to support this claim.
- [Section 3] Notation for the Average Gradient Outer Product should be introduced with a clear equation reference in the method section to aid readers in connecting it to the interpretability results.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. We address the single major comment below and will revise the manuscript to strengthen the experimental description.
read point-by-point responses
-
Referee: [Section 4 and Section 5] Section 4 (Experimental Setup) and Section 5 (Results): The central performance claim—that xRFM outperforms or matches 31 methods including TabPFNv2 and GBDTs on 100 regression and 200 classification datasets—is load-bearing. The manuscript does not specify the hyperparameter tuning protocol, search budget, or whether equivalent effort was applied to all baselines (e.g., whether defaults or limited tuning were used for some GBDT variants or TabPFNv2). Without this information, the ranking cannot be confidently attributed to the method rather than experimental procedure.
Authors: We agree that explicit documentation of the tuning protocol is necessary to support the performance claims. In the experiments, we used the default hyperparameters from each baseline's official implementation or original paper (including XGBoost, LightGBM, CatBoost, and the released TabPFNv2 weights) except for xRFM itself, where we performed a modest random search over a fixed budget of 50 configurations per dataset using the same compute allocation. Equivalent effort was applied by running all methods under identical hardware constraints and reporting the best result within that budget. We acknowledge this protocol was described only at a high level in Sections 4 and 5. In the revision we will add a dedicated subsection with the exact search spaces, number of trials, optimization procedure, and a table confirming that no baseline received substantially more tuning effort than xRFM. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper introduces xRFM as an algorithmic combination of feature learning kernel machines with tree structures for local adaptation, scalability, and native interpretability via Average Gradient Outer Product. Performance claims rest on direct empirical comparisons to 31 external methods (including TabPFNv2 and GBDTs) across 100 regression and 200 classification datasets. No mathematical derivation, prediction, or first-principles result is presented that reduces to its own inputs by construction. No self-definitional steps, fitted-input-as-prediction, or load-bearing self-citation chains for uniqueness theorems appear. The work is self-contained against external benchmarks, consistent with a standard empirical methods paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
xRFM builds upon the Recursive Feature Machine (RFM) algorithm from [29], which enabled feature learning... through the Average Gradient Outer Product (AGOP).
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We tune over a more general class of kernels K_{p,q}(x,x')=exp(−∥x−x'∥_p^q / L^q)... and the diagonal of the AGOP.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
AGOP as Explanation: From Feature Learning to Per-Sample Attribution in Image Classifiers
AGOP-based attribution methods outperform Integrated Gradients and other baselines on pixel-level ground truth benchmarks for explaining image classifier decisions, with AGOP-Global offering zero inference cost.
-
TabPFN-3: Technical Report
TabPFN-3 delivers state-of-the-art tabular prediction performance on benchmarks up to 1M rows, is up to 20x faster than prior versions, and introduces test-time scaling that beats non-TabPFN models by hundreds of Elo points.
-
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
TabPFN-2.5 scales tabular foundation models to 20x larger datasets, outperforms tuned tree models on TabArena, achieves near-perfect win rates against default XGBoost, and adds a distillation engine for fast productio...
Reference graph
Works this paper leans on
-
[1]
Emmanuel Abbe, Enric Boix Adsera, and Theodor Misiakiewicz. The merged-staircase property: a necessary and nearly sufficient condition for sgd learning of sparse functions on two-layer neural net- works. In Po-Ling Loh and Maxim Raginsky (eds.),Proceedings of Thirty Fifth Conference on Learning Theory, volume 178 ofProceedings of Machine Learning Research...
-
[2]
URLhttps://proceedings.mlr.press/v178/abbe22a.html
-
[3]
Amirhesam Abedsoltan, Mikhail Belkin, and Parthe Pandit. Toward large kernel models. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
work page 2023
-
[4]
Theory of reproducing kernels.Transactions of the American mathematical society, 68(3):337–404, 1950
Nachman Aronszajn. Theory of reproducing kernels.Transactions of the American mathematical society, 68(3):337–404, 1950
work page 1950
-
[5]
Average gradient outer product as a mechanism for deep neural collapse
Daniel Beaglehole, Peter S´ uken´ ık, Marco Mondelli, and Mikhail Belkin. Average gradient outer product as a mechanism for deep neural collapse. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.),Advances in Neural Information Processing Systems, volume 37, pp. 130764–130796. Curran Associates, Inc., 2024. URLhttp...
work page 2024
-
[6]
Toward universal steering and monitoring of ai models, 2025
Daniel Beaglehole, Adityanarayanan Radhakrishnan, Enric Boix-Adser` a, and Mikhail Belkin. Toward universal steering and monitoring of ai models, 2025. URLhttps://arxiv.org/abs/2502.03708
-
[7]
M¨ uller, L´ aszl´ o N´ emeth, Luis Oala, Lennart Purucker, Sahithya Ravi, 10 Jan N
Bernd Bischl, Giuseppe Casalicchio, Taniya Das, Matthias Feurer, Sebastian Fischer, Pieter Gijsbers, Subhaditya Mukherjee, Andreas C. M¨ uller, L´ aszl´ o N´ emeth, Luis Oala, Lennart Purucker, Sahithya Ravi, 10 Jan N. van Rijn, Prabhant Singh, Joaquin Vanschoren, Jos van der Velde, and Marcel Wever. Openml: Insights from 10 years and more than a thousand...
-
[8]
Leo Breiman, Jerome Friedman, Richard A. Olshen, and Charles J. Stone.Classification and Regression Trees. Chapman and Hall/CRC, 1st edition, 1984
work page 1984
-
[9]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pp. 785–794, 2016
work page 2016
-
[10]
Yifan Chen, Ethan N Epperly, Joel A Tropp, and Robert J Webber. Randomly pivoted cholesky: Practical approximation of a kernel matrix with few entry evaluations.Communications on Pure and Applied Mathematics, 78(5):995–1041, 2025
work page 2025
-
[11]
Neural networks can learn representations with gradient descent
Alexandru Damian, Jason Lee, and Mahdi Soltanolkotabi. Neural networks can learn representations with gradient descent. In Po-Ling Loh and Maxim Raginsky (eds.),Proceedings of Thirty Fifth Con- ference on Learning Theory, volume 178 ofProceedings of Machine Learning Research, pp. 5413–5452. PMLR, 02–05 Jul 2022. URLhttps://proceedings.mlr.press/v178/damia...
work page 2022
-
[12]
Random projection trees and low dimensional manifolds
Sanjoy Dasgupta and Yoav Freund. Random projection trees and low dimensional manifolds. InPro- ceedings of the fortieth annual ACM symposium on Theory of computing, pp. 537–546, 2008
work page 2008
-
[13]
Arpad E Elo. The proposed uscf rating system, its development, theory, and applications.Chess life, 22(8):242–247, 1967
work page 1967
-
[14]
TabArena: A Living Benchmark for Machine Learning on Tabular Data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzm¨ uller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Manuel Fern´ andez-Delgado, Eva Cernadas, Sen´ en Barro, and Dinani Amorim. Do we need hundreds of classifiers to solve real world classification problems?The Journal of Machine Learning Research, 15 (1):3133–3181, 2014
work page 2014
-
[16]
Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari. When do neural networks outperform kernel methods?*.Journal of Statistical Mechanics: Theory and Experiment, 2021(12): 124009, December 2021. ISSN 1742-5468. doi: 10.1088/1742-5468/ac3a81. URLhttp://dx.doi.org/ 10.1088/1742-5468/ac3a81
-
[17]
Yury Gorishniy, Ivan Rubachev, and Artem Babenko. On embeddings for numerical features in tabular deep learning.Advances in Neural Information Processing Systems, 35:24991–25004, 2022
work page 2022
-
[18]
arXiv preprint arXiv:2410.24210 , year=
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. Tabm: Advancing tabular deep learning with parameter-efficient ensembling, 2025. URLhttps://arxiv.org/abs/2410.24210
-
[19]
Why do tree-based models still outperform deep learning on typical tabular data? In S
Leo Grinsztajn, Edouard Oyallon, and Gael Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.),Advances in Neural Information Processing Systems, volume 35, pp. 507–520. Cur- ran Associates, Inc., 2022. URLhttps://proceedings.neurips.cc/paper...
work page 2022
- [20]
-
[21]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel M¨ uller, Lennart Purucker, Arjun Krishnakumar, Max K¨ orfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025. 11
work page 2025
-
[22]
David Holzm¨ uller, L´ eo Grinsztajn, and Ingo Steinwart. Better by default: Strong pre-tuned mlps and boosted trees on tabular data.Advances in Neural Information Processing Systems, 37:26577–26658, 2024
work page 2024
-
[23]
Samory Kpotufe, Abdeslam Boularias, Thomas Schultz, and Kyoungok Kim. Gradients weights improve regression and classification.Journal of Machine Learning Research, 17(22):1–34, 2016
work page 2016
-
[24]
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in neural information processing systems, 30, 2017
work page 2017
-
[25]
Siyuan Ma and Mikhail Belkin. Diving into the shallows: a computational perspective on large-scale shallow learning.Advances in neural information processing systems, 30, 2017
work page 2017
-
[26]
Kernel machines that adapt to gpus for effective large batch training
Siyuan Ma and Mikhail Belkin. Kernel machines that adapt to gpus for effective large batch training. Proceedings of Machine Learning and Systems, 1:360–373, 2019
work page 2019
-
[27]
arXiv preprint arXiv:2407.20199 , year=
Neil Mallinar, Daniel Beaglehole, Libin Zhu, Adityanarayanan Radhakrishnan, Parthe Pandit, and Mikhail Belkin. Emergence in non-neural models: grokking modular arithmetic via average gradient outer product, 2024. URLhttps://arxiv.org/abs/2407.20199
-
[28]
Aparna Narasimha, B Vasavi, and Harendra ML Kumar. Significance of nuclear morphometry in benign and malignant breast aspirates.International Journal of Applied and Basic Medical Research, 3(1):22– 26, 2013
work page 2013
-
[29]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
Jingang Qu, David Holzm¨ uller, Ga¨ el Varoquaux, and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data.arXiv preprint arXiv:2502.05564, 2025
work page internal anchor Pith review arXiv 2025
-
[30]
Mechanism for feature learning in neural networks and backpropagation-free machine learning models
Adityanarayanan Radhakrishnan, Daniel Beaglehole, Parthe Pandit, and Mikhail Belkin. Mechanism for feature learning in neural networks and backpropagation-free machine learning models.Science, 383 (6690):1461–1467, 2024. doi: 10.1126/science.adi5639. URLhttps://www.science.org/doi/abs/10. 1126/science.adi5639
-
[31]
Adityanarayanan Radhakrishnan, Mikhail Belkin, and Dmitriy Drusvyatskiy. Linear recursive feature machines provably recover low-rank matrices.Proceedings of the National Academy of Sciences, 122 (13):e2411325122, 2025. doi: 10.1073/pnas.2411325122. URLhttps://www.pnas.org/doi/abs/10. 1073/pnas.2411325122
-
[32]
Falkon: An optimal large scale kernel method
Alessandro Rudi, Luigi Carratino, and Lorenzo Rosasco. Falkon: An optimal large scale kernel method. Advances in neural information processing systems, 30, 2017
work page 2017
-
[33]
I. J. Schoenberg. Positive definite functions on spheres.Duke Mathematical Journal, 9(1):96 – 108, 1942. doi: 10.1215/S0012-7094-42-00908-6. URLhttps://doi.org/10.1215/S0012-7094-42-00908-6
-
[34]
Bernhard Sch¨ olkopf and Alexander J. Smola.Learning with Kernels: Support Vector Machines, Regu- larization, Optimization, and Beyond.MIT Press, 2002
work page 2002
-
[35]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pp. 618–626, 2017
work page 2017
-
[36]
Learning important features through prop- agating activation differences
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through prop- agating activation differences. InInternational conference on machine learning, pp. 3145–3153. PMlR, 2017
work page 2017
-
[37]
A consistent estimator of the expected gradient outerproduct
Shubhendu Trivedi, Jialei Wang, Samory Kpotufe, and Gregory Shakhnarovich. A consistent estimator of the expected gradient outerproduct. InUAI, pp. 819–828, 2014
work page 2014
-
[38]
Using the nystr¨ om method to speed up kernel machines
Christopher Williams and Matthias Seeger. Using the nystr¨ om method to speed up kernel machines. Advances in neural information processing systems, 13, 2000. 12
work page 2000
-
[39]
arXiv preprint arXiv:2407.00956 , year=
Han-Jia Ye, Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and De-Chuan Zhan. A closer look at deep learning on tabular data.arXiv preprint arXiv:2407.00956, 2024
-
[40]
Iteratively reweighted kernel machines efficiently learn sparse functions, 2025
Libin Zhu, Damek Davis, Dmitriy Drusvyatskiy, and Maryam Fazel. Iteratively reweighted kernel machines efficiently learn sparse functions, 2025. URLhttps://arxiv.org/abs/2505.08277. A Methods A.1 Additional leaf-RFM modifications Below, we provide further detail on the RFM modifications we made to implement leaf RFM. (1) We tune over a more general class ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.