Meta-learning Structure-Preserving Dynamics
Pith reviewed 2026-05-18 22:08 UTC · model grok-4.3
The pith
Modulation-based meta-learning lets Hamiltonian dynamics models adapt to new parameters in few shots while keeping conservation laws intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating a range of modulation strategies, including newly proposed variants, into a Hamiltonian learning framework without requiring explicit system parameterization, modulation-based meta-learning enables accurate few-shot adaptation and robust generalization across parameter space without compromising the conservation of key invariants responsible for the dynamics.
What carries the argument
Modulation techniques applied within a Hamiltonian neural network framework, which adjust the model to new configurations while enforcing conservation properties without direct parameterization of the system.
If this is right
- Accurate few-shot adaptation occurs for parameter values outside the original training distribution.
- Generalization remains robust across the full parameter space of the benchmark problems.
- Key invariants such as energy are preserved in the predictions of the adapted models.
- Both existing and newly proposed modulation variants succeed when embedded in the Hamiltonian setup.
Where Pith is reading between the lines
- The same modulation idea could be tested on structure-preserving models that include dissipation rather than strict conservation.
- Applications in control or robotics might benefit if the approach scales to systems with real sensor noise.
- Further work could check whether the method reduces total training cost when many similar systems must be modeled sequentially.
Load-bearing premise
Modulation strategies can be integrated into the Hamiltonian learning framework without explicit system parameterization while still enforcing conservation laws on unseen parameter values.
What would settle it
A benchmark experiment in which the few-shot adapted model produces trajectories that violate a conserved quantity such as total energy by more than numerical tolerance on a new parameter value would falsify the claim.
Figures










read the original abstract
Structure-preserving approaches to dynamics discovery have demonstrated great potential for modeling physical systems due to their use of strong inductive biases, which enforce key features such as conservation laws and dissipative behavior. However, these models are typically trained on a per-configuration basis, requiring explicit knowledge of system parameters and costly retraining when these parameters vary. While meta-learning provides a potential remedy, optimization-based approaches can suffer from limited generalizability. Motivated by recent advances in modulation-based learning aimed at mitigating these drawbacks, we systematically investigate the use of modulation techniques in learning conservative dynamical systems. We study a range of existing modulation strategies alongside newly proposed variants, integrating them into a Hamiltonian learning framework without requiring an explicit system parameterization. Through extensive experiments on benchmark problems, we demonstrate that modulation-based meta-learning enables accurate few-shot adaptation, achieving robust generalization across parameter space without compromising the conservation of key invariants responsible for the dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes integrating a range of modulation strategies (existing and newly proposed variants) into a Hamiltonian neural network framework for meta-learning structure-preserving dynamical systems. The central claim is that this enables accurate few-shot adaptation to new system parameters without requiring explicit parameterization or per-configuration retraining, while preserving conservation of key invariants such as energy, as demonstrated through experiments on benchmark problems.
Significance. If the results hold, the work could meaningfully advance physics-informed meta-learning by showing how modulation can decouple adaptation from explicit system knowledge while retaining the strong inductive biases of Hamiltonian models. The systematic comparison of modulation variants and the emphasis on invariant preservation across parameter space are strengths that could influence downstream applications in simulation and control.
major comments (2)
- [§4.3] §4.3, the modulated Hamiltonian construction: the claim that modulation enforces conservation on unseen parameters without explicit parameterization is load-bearing, yet the derivation does not explicitly show that the symplectic gradient remains divergence-free after modulation for out-of-distribution φ; a short proof or numerical check of dH/dt = 0 on held-out trajectories would strengthen this.
- [Table 2] Table 2, few-shot adaptation rows: the reported conservation error for the proposed modulation variant is 1.2e-4, but the comparison to standard HNN fine-tuning lacks an ablation on whether the meta-initialization itself (rather than modulation) drives the improvement; this affects the generalization-across-parameter-space claim.
minor comments (2)
- [Figure 3] Figure 3 caption: the color coding for different modulation strategies is not fully explained in the legend, making it difficult to match curves to the methods listed in §3.2.
- [§5.2] §5.2: the benchmark problems are described at a high level; adding a short table of system dimensions, integration time steps, and data-split ratios would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and will update the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§4.3] §4.3, the modulated Hamiltonian construction: the claim that modulation enforces conservation on unseen parameters without explicit parameterization is load-bearing, yet the derivation does not explicitly show that the symplectic gradient remains divergence-free after modulation for out-of-distribution φ; a short proof or numerical check of dH/dt = 0 on held-out trajectories would strengthen this.
Authors: We agree that an explicit verification of the conservation property for out-of-distribution parameters would strengthen the manuscript. In the revised version, we will add a short derivation demonstrating that the modulated Hamiltonian retains the required symplectic structure (i.e., the gradient remains divergence-free), and we will include numerical checks reporting dH/dt ≈ 0 on held-out trajectories for unseen φ values. revision: yes
-
Referee: [Table 2] Table 2, few-shot adaptation rows: the reported conservation error for the proposed modulation variant is 1.2e-4, but the comparison to standard HNN fine-tuning lacks an ablation on whether the meta-initialization itself (rather than modulation) drives the improvement; this affects the generalization-across-parameter-space claim.
Authors: We acknowledge the value of isolating the contribution of modulation from the meta-initialization. In the revision, we will add an ablation comparing the proposed modulated approach against a meta-initialized HNN that undergoes standard fine-tuning without modulation on the few-shot data. This will clarify the source of the observed improvements and better support the generalization claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes integrating existing and new modulation strategies into a Hamiltonian learning framework for meta-learning conservative dynamical systems, with claims of few-shot adaptation and invariant preservation supported by benchmark experiments. No load-bearing steps reduce by construction to inputs, self-citations, or fitted parameters renamed as predictions. The abstract and available text present an empirical study without self-definitional loops or uniqueness theorems imported from prior author work. The derivation remains self-contained against external benchmarks and does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We study a range of existing modulation strategies alongside newly proposed variants, integrating them into a Hamiltonian learning framework without requiring an explicit system parameterization... preserving the conservation of key invariants responsible for the dynamics.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the degeneracy conditions... LLL(x) ∂S/∂x = 0, and MMM(x) ∂E/∂x = 0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Metriplector: From Field Theory to Neural Architecture
Metriplector treats neural computation as coupled metriplectic field dynamics whose stress-energy tensor readout achieves competitive results on vision, control, Sudoku, language modeling, and pathfinding with small p...
Reference graph
Works this paper leans on
-
[1]
Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, and Shirley Ho. Lagrangian neural networks. In ICLR 2020 Workshop,
work page 2020
-
[2]
Port-Hamiltonian neural networks for learning explicit time-dependent dynamical systems
Shaan Desai, Marios Mattheakis, David Sondak, Pavlos Protopapas, and Stephen Roberts. Port-Hamiltonian neural networks for learning explicit time-dependent dynamical systems. arXiv preprint arXiv:2107.08024,
-
[3]
doi:https://doi.org/10.1016/0167-2789(86)90209-5
ISSN 0167-2789. doi:https://doi.org/10.1016/0167-2789(86)90209-5. URL https://www. sciencedirect.com/science/article/pii/0167278986902095. PJ Morrison. Thoughts on brackets and dissipation: Old and new. In Journal of Physics: Conference Series, volume 169, page 012006. IOP Publishing,
-
[4]
On First-Order Meta-Learning Algorithms
Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi:10.1016/j.neunet.2024.106162
ISSN 0893-6080. doi:10.1016/j.neunet.2024.106162. URL https://doi.org/10.1016/j.neunet.2024.106162. Tomoharu Iwata and Yusuke Tanaka. Symplectic neural Gaussian processes for meta-learning Hamiltonian dynamics. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 4210–4218,
-
[6]
doi:10.1007/BF01446807. Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 32,
-
[7]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
and the latent full-weight modulation Kirchmeyer et al. [2022].2 The latent shift modulation technique can be defined as the mapping: h 7→ σ W (ℓ)h + b(ℓ) + s(ℓ,k) , where s(k) = ∪L ℓ=1s(ℓ,k) = fhyper(z(k); ϕ). The latent full weight modulation can be similarly defined as: h 7→ σ (W (ℓ) + ∆W (ℓ,k))h + b(ℓ) + s(ℓ,k) , where (∆W (k), s(k)) = ∪L ℓ=1∆W (ℓ,k),...
work page 2022
-
[9]
Contracting the second and the fourth dimensions gives the MMM matrix, MMM(x) = ζαβ,µν ∂E ∂xβ ∂E ∂xν . C.2 Modification for this work We apply three key assumptions following practices in the literature Zhang et al. [2022], Lee et al
work page 2022
-
[10]
to make the problem more tractable. Similar to HNNs, we assume the GENERIC model forms under consideration are governed by the canonical Poisson matrix, that is, LLL = " 0 III N 0 −III N 0 0 0 0 0 # , where N denotes the degrees of freedom in the system and IN is the identify matrix of size N. This is equivalent to assuming that the reversible dynamics in...
work page 2020
-
[11]
The total energy is then given by E(q, p, S1, S2) = H(q, p) + E1 + E2 = p2 2m + E1 + E2
This shows that the energy is highly nonlinear with respect to the position and the entropy. The total energy is then given by E(q, p, S1, S2) = H(q, p) + E1 + E2 = p2 2m + E1 + E2. The state variables are x = [q, p, S1, S2]T and the dynamics in the GENERIC form can be expressed in terms of the matrices: LLL = 0 1 0 0 −1 0 0 0 0 0 0 0 0 0 0 0 , ...
work page 2017
-
[12]
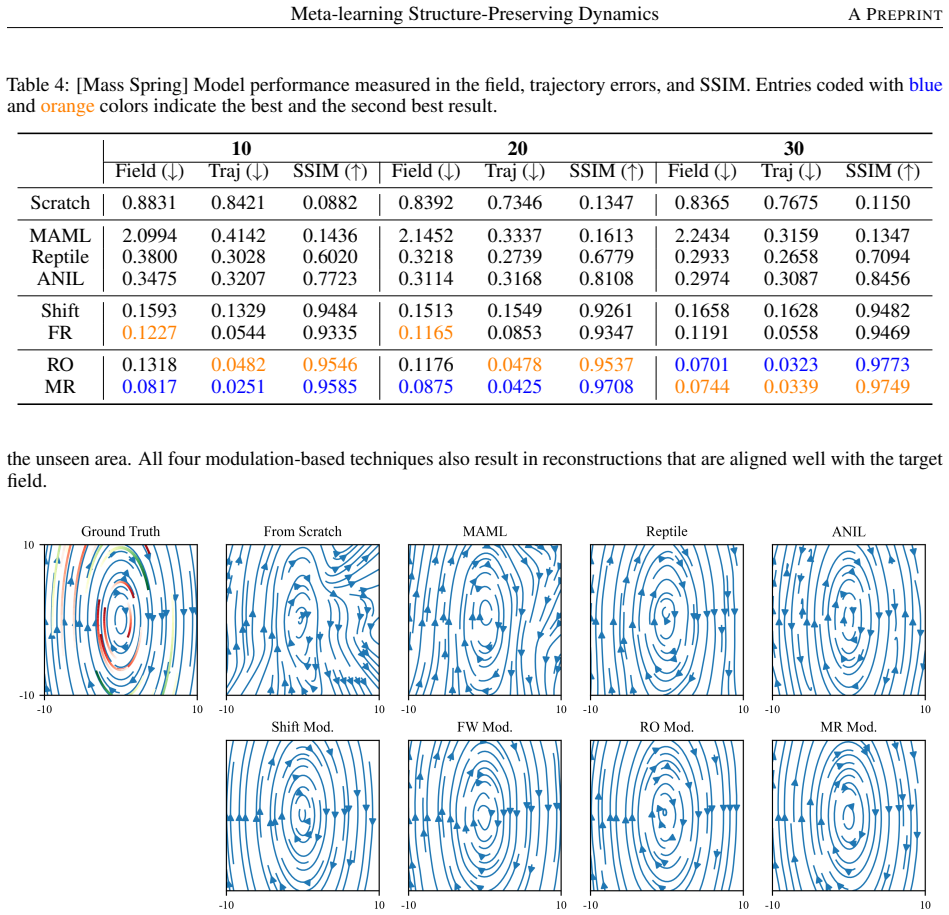
The optimization-based methods demonstrate improved performance compared to learning the vector field from scratch. This demonstrates the power of meta-learning; given only the trajectories depicted in the red color, training from scratch struggles to capture the unseen areas of the vector field (even with structure-preserving modeling), while the meta-le...
work page 1991
-
[13]
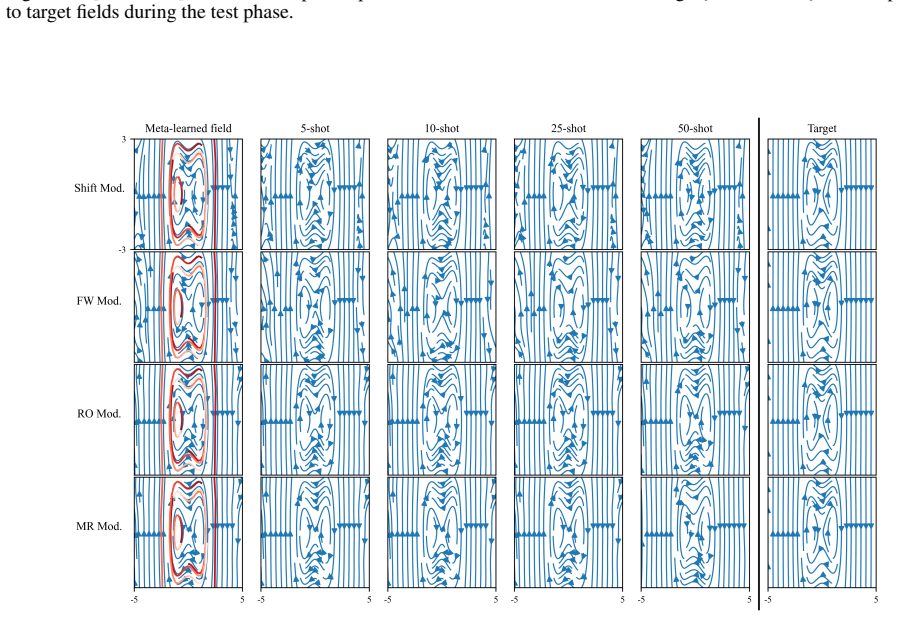
The top panels show the target velocity field with S = 1 and the learned vector fields by using four modulation methods. The bottom panels show the target energy function and the learned energy functions by using the modulation methods. The proposed RO 21 Meta-learning Structure-Preserving Dynamics A PREPRINT and MR methods again present improved approxim...
work page 2056
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.