Disentangling Interaction and Bias Effects in Opinion Dynamics of Large Language Models
Pith reviewed 2026-05-25 07:40 UTC · model grok-4.3
The pith
LLM opinion trajectories converge to shared attractors whose position depends on fine-tuning, once interaction is separated from three biases via Bayesian modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
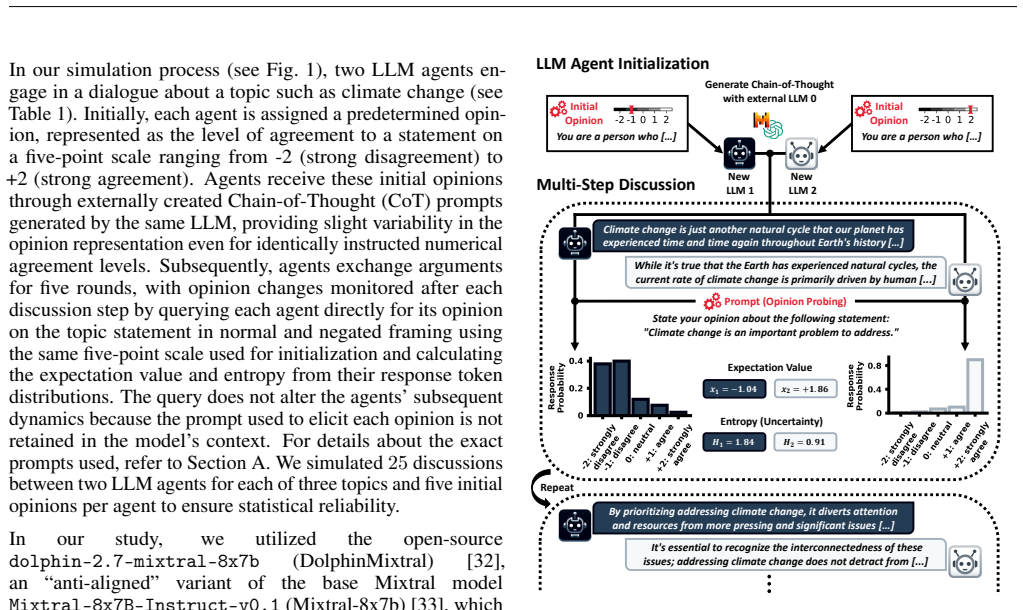
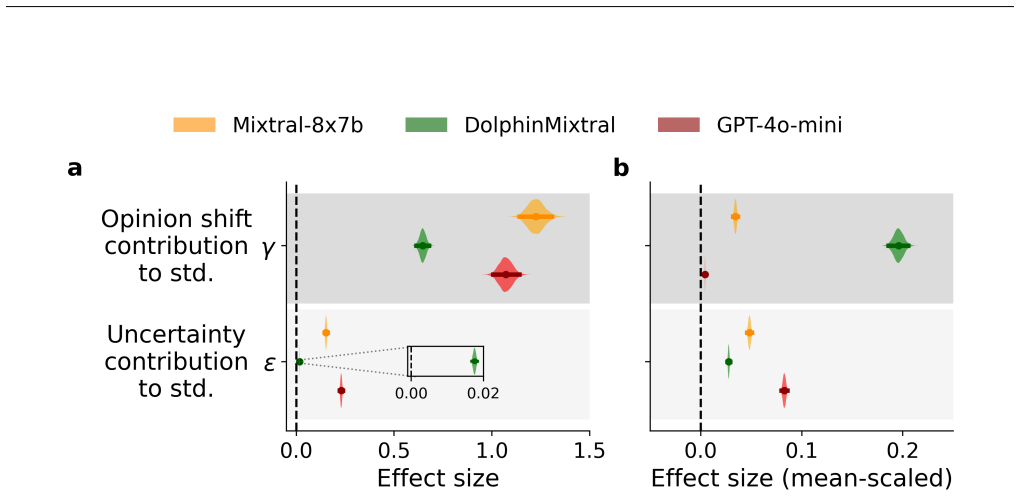
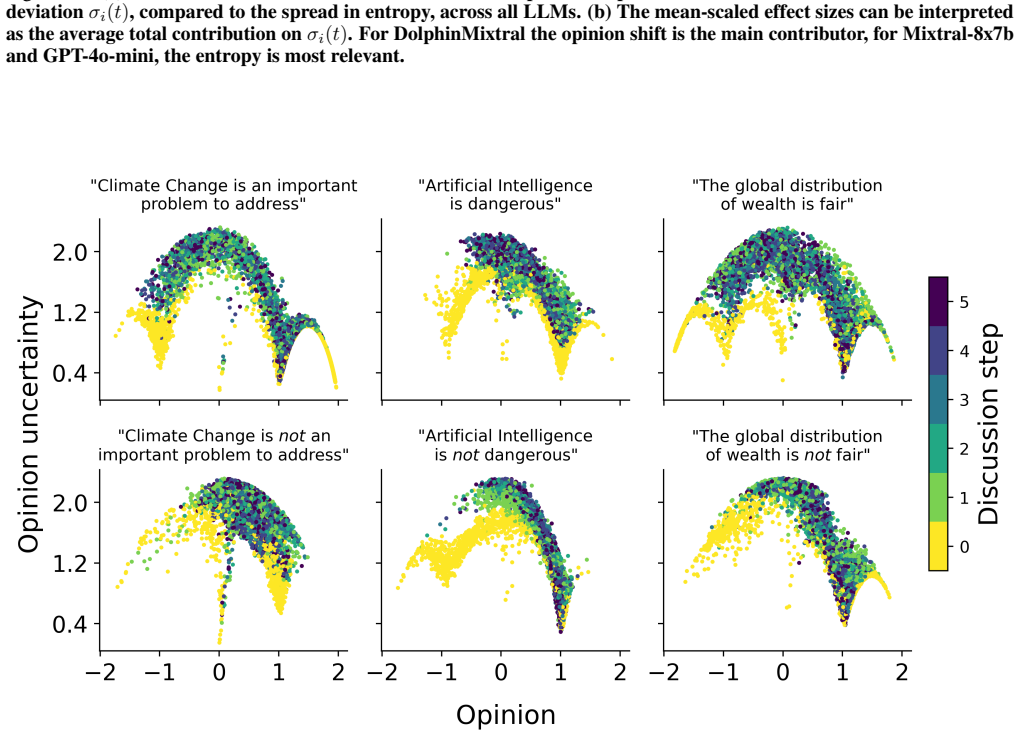
We develop a Bayesian framework to disentangle and quantify three biases in LLM opinion dynamics: topic bias toward the model's default stance, agreement bias favoring agreement irrespective of content, and anchoring bias toward the initiating stance. When applied to multi-step dialogues on climate, justice, and preference questions, opinion trajectories converge quickly to a shared attractor, with the effects of interaction and biases both decaying over time. The relative strength of the biases varies across different LLMs. Fine-tuning an LLM on sets of strongly opinionated statements shifts the location of this attractor accordingly.
What carries the argument
A Bayesian framework that models opinion updates as the sum of interaction effects and three named biases (topic, agreement, anchoring), allowing quantification of each contribution.
If this is right
- Opinion trajectories in LLM multi-turn dialogues converge rapidly to a common position.
- The contributions of both genuine interaction and the three biases decay as the dialogue progresses.
- Bias magnitudes differ systematically between different large language models.
- Fine-tuning on opinionated data, including misinformation, moves the final attractor position.
Where Pith is reading between the lines
- If the framework holds, then simulations of human societies using LLMs will inherit model-specific attractors unless fine-tuning is controlled.
- The decay of interaction effects suggests that long dialogues may be dominated by model priors rather than exchanged information.
- Applying the same decomposition to human conversation data could test whether analogous biases operate in people.
Load-bearing premise
The Bayesian framework isolates genuine interaction effects from the three biases without leftover confounding from other LLM behaviors or prompt design choices.
What would settle it
A direct test would be to run the same dialogues with the framework's estimated parameters fixed and check whether the observed opinion sequences match the predicted distributions; mismatch would falsify the disentanglement.
Figures











read the original abstract
Large Language Models are increasingly used to simulate human opinion dynamics, yet the effect of genuine interaction is often obscured by systematic biases. We develop a Bayesian framework to disentangle and quantify three such biases: (i) A topic bias toward the LLM's default stance; (ii) an agreement bias favoring agreement to the prompted statement irrespective of the question; and (iii) an anchoring bias toward the initiating agent's stance. We apply this framework to various LLMs that performed multi-step dialogues on 12 different questions from climate change and societal justice to music preferences. We find that opinion trajectories tend to quickly converge to a shared attractor, with the influence of both interaction and biases decaying over time, and with the impact of biases differing between LLMs. In addition, we show that fine-tuning an LLM on different sets of strongly opinionated statements (including misinformation) shifts the opinion attractor correspondingly. By exposing stark differences between LLMs and providing quantitative tools for comparing interaction and bias contributions to opinion shifts in LLM agent discussions, our approach highlights both promises and pitfalls of using LLMs as proxies for human behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a Bayesian framework to separate genuine interaction effects from three biases (topic bias toward default stance, agreement bias favoring prompted statements, and anchoring bias toward the initiating agent) in multi-turn LLM dialogues. It applies the model to several LLMs across 12 questions on climate change, societal justice, and music preferences, reporting rapid convergence to shared opinion attractors with decaying interaction and bias influences over time, LLM-specific differences in bias strength, and shifts in the attractor after fine-tuning on opinionated (including misinformation) statements.
Significance. If the separation of interaction from the three biases proves robust, the work supplies a quantitative tool for auditing LLM agent simulations of opinion dynamics and for comparing model behaviors, which is relevant for both social simulation studies and responsible deployment of LLMs as proxies for human discussion.
major comments (2)
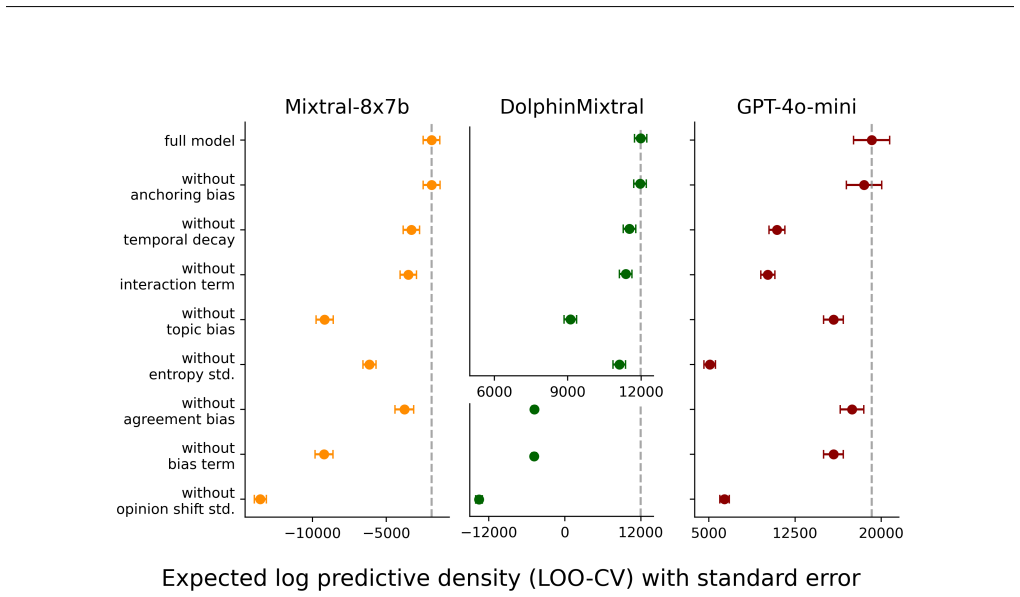
- [§3] §3 (Bayesian model): the identifiability of the interaction term from the three additive bias shifts rests on the assumption that higher-order LLM effects (e.g., sycophancy modulated by context length or framing) are absent from the likelihood; no parameter-recovery experiment on synthetic trajectories generated from known ground-truth parameters is reported, leaving open the possibility that recovered interaction strengths are biased by unmodeled confounding.
- [Application section] Application section (following §3): the claim that fine-tuning on different opinionated statement sets shifts the attractor correspondingly requires explicit controls showing that the shift is not an artifact of prompt length, token distribution, or other training-side changes; the manuscript supplies no such ablation or comparison of fine-tuning protocols.
minor comments (2)
- The abstract states that the framework 'was applied' but supplies no equations, prior specifications, or likelihood form; these details should appear in the main text with at least one worked numerical example.
- Figure captions and table legends should explicitly state the number of dialogue turns, number of independent runs per LLM-question pair, and the precise definition of the 'attractor' (e.g., fixed point of the posterior mean trajectory).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of model identifiability and experimental controls that we address point by point below. We are prepared to incorporate additional validation and ablation experiments in a revised manuscript.
read point-by-point responses
-
Referee: §3 (Bayesian model): the identifiability of the interaction term from the three additive bias shifts rests on the assumption that higher-order LLM effects (e.g., sycophancy modulated by context length or framing) are absent from the likelihood; no parameter-recovery experiment on synthetic trajectories generated from known ground-truth parameters is reported, leaving open the possibility that recovered interaction strengths are biased by unmodeled confounding.
Authors: We agree that identifiability of the interaction coefficient rests on the modeling assumption that higher-order effects are negligible relative to the three explicit bias terms. While the additive structure is motivated by the experimental design (fixed prompt templates and controlled dialogue length), we acknowledge that a parameter-recovery study on synthetic trajectories would provide direct evidence of recoverability. We will add such an experiment in the revision, generating trajectories from the fitted model with known ground-truth parameters and demonstrating accurate recovery of the interaction term. revision: yes
-
Referee: Application section (following §3): the claim that fine-tuning on different opinionated statement sets shifts the attractor correspondingly requires explicit controls showing that the shift is not an artifact of prompt length, token distribution, or other training-side changes; the manuscript supplies no such ablation or comparison of fine-tuning protocols.
Authors: The referee correctly notes that the reported attractor shifts after fine-tuning lack explicit controls for training-side confounds such as prompt length or token statistics. In the revised manuscript we will include (i) an ablation comparing fine-tuning on opinionated statements against length- and token-matched neutral corpora and (ii) a comparison of two distinct fine-tuning protocols (LoRA vs. full fine-tuning) to isolate the effect of the opinion content itself. revision: yes
Circularity Check
No circularity in derivation; framework presented without reducible equations
full rationale
The abstract and skeptic summary describe a Bayesian framework for disentangling biases from interaction but supply no equations, parameterizations, or self-citations. No load-bearing steps are quoted that reduce a prediction to a fit by construction, import uniqueness from authors, or smuggle an ansatz. The central claim of separability therefore cannot be shown to collapse to its inputs from the given text; the derivation is treated as self-contained pending explicit model details.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
TeraGram: A Structured Longitudinal Dataset of the Telegram Messenger
A large-scale longitudinal dataset of public Telegram content is introduced to enable studies of engagement patterns and network evolution without algorithmic curation.
-
Conformity Generates Collective Misalignment in AI Agents Societies
Populations of individually aligned AI agents reach stable misaligned states through conformity, with small adversarial agents able to trigger irreversible tipping points.
Reference graph
Works this paper leans on
-
[1]
James WA Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, et al. Testing theory of mind in large language models and humans.Nature Human Behaviour, 8(7):1285–1295, 2024
work page 2024
-
[2]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
On the conversational persuasiveness of gpt-4.Nature Human Behaviour, 2025
Francesco Salvi, Manoel Horta Ribeiro, Riccardo Gallotti, and Robert West. On the conversational persuasiveness of gpt-4.Nature Human Behaviour, 2025
work page 2025
-
[4]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
work page 2025
-
[5]
Yuxiao Lu, Alberto Aleta, Chenguang Du, Lei Shi, and Yamir Moreno. Llms and generative agent-based models for complex systems research.Physics of Life Reviews, 51:283–293, 2024. doi:10.1016/j.plrev.2024.10.013
-
[6]
Generative agents: Interactive simulacra of human behav- ior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behav- ior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[7]
Yun-Shiuan Chuang, Agam Goyal, Nikunj Harlalka, Sid- dharth Suresh, Robert Hawkins, Sijia Yang, Dhavan 10 Shah, Junjie Hu, and Timothy T. Rogers. Simulating opinion dynamics with networks of llm-based agents. arXiv preprint arXiv:2311.09618, 2023. URL https: //arxiv.org/abs/2311.09618
-
[8]
The persuasive power of large language models
Simon Martin Breum, Daniel Vædele Egdal, Victor Gram Mortensen, Anders Giovanni Møller, and Luca Maria Aiello. The persuasive power of large language models. InProceedings of the International AAAI Conference on Web and Social Media, volume 18, pages 152–163, 2024
work page 2024
-
[9]
Large language model agents can coordinate beyond human scale.arXiv preprint arXiv:2409.02822, 2024
Giordano De Marzo, Claudio Castellano, and David Gar- cia. Large language model agents can coordinate beyond human scale.arXiv preprint arXiv:2409.02822, 2024
-
[10]
Gregor Betz. Natural-language multi-agent simulations of argumentative opinion dynamics.arXiv preprint arXiv:2104.06737, 2021
-
[11]
Social opinions prediction utilizes fusing dynamics equation with llm-based agents
Junchi Yao, Hongjie Zhang, Jie Ou, Dingyi Zuo, Zheng Yang, and Zhicheng Dong. Social opinions prediction utilizes fusing dynamics equation with llm-based agents. Scientific Reports, 15(1):15472, 2025
work page 2025
-
[12]
Erica Cau, Valentina Pansanella, Dino Pedreschi, and Giulio Rossetti. Language-driven opinion dynamics in agent-based simulations with llms.arXiv preprint arXiv:2502.19098, 2025
-
[13]
Andreas Flache, Michael Mäs, Thomas Feliciani, Edmund Chattoe-Brown, Guillaume Deffuant, Sylvie Huet, and Jan Lorenz. Models of social influence: Towards the next frontiers.Jasss-The journal of artificial societies and social simulation, 20(4):2, 2017
work page 2017
-
[14]
Coupled infec- tious disease and behavior dynamics
Andreas Reitenbach, Fabio Sartori, Sven Banisch, Anas- tasia Golovin, André Calero Valdez, Mirjam Kretzschmar, Viola Priesemann, and Michael Maes. Coupled infec- tious disease and behavior dynamics. a review of model assumptions.Reports on Progress in Physics, 2024
work page 2024
-
[15]
Mixing beliefs among interacting agents.Advances in Complex Systems, 3(1-4):87–98,
Guillaume Deffuant, David Neau, Frédéric Amblard, and Gérard Weisbuch. Mixing beliefs among interacting agents.Advances in Complex Systems, 3(1-4):87–98,
-
[16]
doi:10.1142/S0219525900000078
-
[17]
Rainer Hegselmann and Ulrich Krause. Opinion dynamics and bounded confidence: Models, analysis, and simula- tion.Journal of Artificial Societies and Social Simulation, 5(3), 2002. URL http://jasss.soc.surrey.ac.uk /5/3/2.html
work page 2002
-
[18]
Corrado Monti, Luca Maria Aiello, Gianmarco De Fran- cisci Morales, and Francesco Bonchi. The language of opinion change on social media under the lens of commu- nicative action.Scientific Reports, 12(1):17920, 2022
work page 2022
-
[19]
A survey on nonstrategic models of opinion dynamics.Games, 11 (4):65, 2020
Michel Grabisch and Agnieszka Rusinowska. A survey on nonstrategic models of opinion dynamics.Games, 11 (4):65, 2020
work page 2020
-
[20]
Chen Gao, Xiaochong Lan, Nian Li, Yuan Yuan, Jing- tao Ding, Zhilun Zhou, Fengli Xu, and Yong Li. Large language models empowered agent-based modeling and simulation: A survey and perspectives.Humanities and Social Sciences Communications, 11(1):1259, 2024. doi:10.1057/s41599-024-03611-3. URL https://www. nature.com/articles/s41599-024-03611-3
-
[21]
Jiawei Li, Yang Gao, Yizhe Yang, Yu Bai, Xiaofeng Zhou, Yinghao Li, Huashan Sun, Yuhang Liu, Xingpeng Si, Yuhao Ye, et al. Fundamental capabilities and applications of large language models: A survey.ACM Computing Surveys, 2025
work page 2025
-
[22]
Surendrabikram Thapa, Shuvam Shiwakoti, Sid- dhant Bikram Shah, Surabhi Adhikari, Hariram Veeramani, Mehwish Nasim, and Usman Naseem. Large language models (llm) in computational social science: Prospects, current state, and challenges.Social Network Analysis and Mining, 15(1):1–30, 2025
work page 2025
-
[23]
Vanessa Cheung, Maximilian Maier, and Falk Lieder. Large language models show amplified cognitive biases in moral decision-making.Proceedings of the National Academy of Sciences, 122(25):e2412015122, 2025
work page 2025
-
[24]
Generative language models exhibit social identity biases
Tiancheng Hu, Yara Kyrychenko, Steve Rathje, Nigel Collier, Sander van der Linden, and Jon Roozenbeek. Generative language models exhibit social identity biases. Nature Computational Science, 5(1):65–75, 2025
work page 2025
-
[25]
Systematic biases in llm simulations of debates
Amir Taubenfeld, Yaniv Dover, Roi Reichart, and Ariel Goldstein. Systematic biases in llm simulations of debates. arXiv preprint arXiv:2402.04049, 2024
-
[26]
Lindia Tjuatja, Valerie Chen, Tongshuang Wu, Ameet Talwalkwar, and Graham Neubig. Do llms exhibit human- like response biases? a case study in survey design.Trans- actions of the Association for Computational Linguistics, 12:1011–1026, 2024
work page 2024
-
[27]
Jeremy K Nguyen. Human bias in ai models? anchoring effects and mitigation strategies in large language mod- els.Journal of Behavioral and Experimental Finance, 43: 100971, 2024
work page 2024
-
[28]
Lucas Molleman, Alan N Tump, Andrea Gradassi, Stefan Herzog, Bertrand Jayles, Ralf HJM Kurvers, and Wouter van den Bos. Strategies for integrating disparate social information.Proceedings of the Royal Society B, 287 (1939):20202413, 2020
work page 1939
-
[29]
Bayesian learning in social networks.Games and economic behavior, 45(2): 329–346, 2003
Douglas Gale and Shachar Kariv. Bayesian learning in social networks.Games and economic behavior, 45(2): 329–346, 2003
work page 2003
-
[30]
Bayesian decision making in human collectives with binary choices.PLoS One, 10(4):e0121332, 2015
Víctor M Eguíluz, Naoki Masuda, and Juan Fernández- Gracia. Bayesian decision making in human collectives with binary choices.PLoS One, 10(4):e0121332, 2015
work page 2015
-
[31]
How to grow a mind: Statistics, structure, and abstraction.science, 331(6022):1279–1285, 2011
Joshua B Tenenbaum, Charles Kemp, Thomas L Griffiths, and Noah D Goodman. How to grow a mind: Statistics, structure, and abstraction.science, 331(6022):1279–1285, 2011
work page 2011
-
[32]
Maher, Caoimhe O’Reilly, and Michael Quayle
Dino Carpentras, Paul J. Maher, Caoimhe O’Reilly, and Michael Quayle. Deriving an opinion dynamics model from experimental data.Journal of Artificial Societies and Social Simulation, 25(4), 2022. ISSN 1460-7425. doi:10.18564/jasss.4947. URL http://dx.doi.org/1 0.18564/jasss.4947
-
[33]
Dolphin-2.7-mixtral-8x7b [model card]
Cognitive Computations. Dolphin-2.7-mixtral-8x7b [model card]. https://huggingface.co/cognitive computations/dolphin-2.7-mixtral-8x7b , 2024. Accessed: 2025-06-26. 11
work page 2024
-
[34]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o sys- tem card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Mistral AI. Mixtral of experts. https://mistral. ai/news/mixtral- of- experts , 2023. Accessed 2025-07-12
work page 2023
-
[37]
Gpt -4o mini: advancing cost -efficient intelli- gence
OpenAI. Gpt -4o mini: advancing cost -efficient intelli- gence. https://openai.com/de-DE/index/gpt-4 o-mini-advancing-cost-efficient-intellige nce/, 2024. Accessed 2025-07-12
work page 2024
-
[38]
Yun-Shiuan Chuang, Siddharth Suresh, Nikunj Harlalka, Agam Goyal, Robert Hawkins, Sijia Yang, Dhavan Shah, Junjie Hu, and Timothy T Rogers. The wisdom of partisan crowds: Comparing collective intelligence in humans and llm-based agents.arXiv preprint arXiv:2311.09665, 2023
-
[39]
Schneider, ¸ Süheda Yıldırım, Jasper Benke, and Viola Priesemann
Sebastian Bernd Mohr, Andreas C. Schneider, ¸ Süheda Yıldırım, Jasper Benke, and Viola Priesemann. Telegram graph data of COVID-19 related channels, 2023. URL https://doi.org/10.25625/H5JUZG
-
[40]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Maarten Grootendorst. Bertopic: Neural topic model- ing with a class-based tf-idf procedure.arXiv preprint arXiv:2203.05794, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022
work page 2022
-
[42]
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
work page 1999
-
[43]
Interacting large language model agents
Adit Jain and Vikram Krishnamurthy. Interacting large language model agents. bayesian social learning based interpretable models.IEEE Access, 2025
work page 2025
-
[44]
Giordano De Marzo, Luciano Pietronero, and David Gar- cia. Emergence of scale-free networks in social inter- actions among large language models.arXiv preprint arXiv:2312.06619, 2023
-
[45]
Nicoló Fontana, Francesco Pierri, and Luca Maria Aiello. Nicer than humans: How do large language models be- have in the prisoner’s dilemma? InProceedings of the International AAAI Conference on Web and Social Media, volume 19, pages 522–535, 2025
work page 2025
-
[46]
Playing repeated games with large language models.Nature Human Be- haviour, pages 1–11, 2025
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. Playing repeated games with large language models.Nature Human Be- haviour, pages 1–11, 2025
work page 2025
-
[47]
Lei Wang, Jingsen Zhang, Hao Yang, Zhi-Yuan Chen, Jiakai Tang, Zeyu Zhang, Xu Chen, Yankai Lin, Hao Sun, Ruihua Song, et al. User behavior simulation with large language model-based agents.ACM Transactions on Information Systems, 43(2):1–37, 2025
work page 2025
-
[48]
Sebastian Michelmann, Manoj Kumar, Kenneth A Nor- man, and Mariya Toneva. Large language models can segment narrative events similarly to humans.Behavior Research Methods, 57(1):1–13, 2025
work page 2025
-
[49]
Xiaoliang Luo, Akilles Rechardt, Guangzhi Sun, Kevin K Nejad, Felipe Yáñez, Bati Yilmaz, Kangjoo Lee, Alexan- dra O Cohen, Valentina Borghesani, Anton Pashkov, et al. Large language models surpass human experts in predict- ing neuroscience results.Nature human behaviour, 9(2): 305–315, 2025
work page 2025
-
[50]
Reasoning with large language models, a survey, 2024
Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, and Thomas Back. Reasoning with large language models, a survey, 2024. URL https://arxiv. org/abs/2407.11511
-
[51]
Lewis R Goldberg. An alternative “description of person- ality”: The big-five factor structure. InPersonality and personality disorders, pages 34–47. Routledge, 2013
work page 2013
-
[52]
Lucio La Cava and Andrea Tagarelli. Open models, closed minds? on agents capabilities in mimicking human per- sonalities through open large language models. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 39(2), pages 1355–1363, 2025
work page 2025
-
[53]
Myra Cheng, Tiziano Piccardi, and Diyi Yang. Compost: Characterizing and evaluating caricature in llm simula- tions.arXiv preprint arXiv:2310.11501, 2023. URL https://arxiv.org/abs/2310.11501
-
[54]
Pymc: a modern, and compre- hensive probabilistic programming framework in python
Oriol Abril-Pla, Virgile Andreani, Colin Carroll, Larry Dong, Christopher J Fonnesbeck, Maxim Kochurov, Ravin Kumar, Junpeng Lao, Christian C Luhmann, Os- valdo A Martin, et al. Pymc: a modern, and compre- hensive probabilistic programming framework in python. PeerJ Computer Science, 9:e1516, 2023
work page 2023
-
[55]
Matthew D Hoffman, Andrew Gelman, et al. The no-u- turn sampler: adaptively setting path lengths in hamilto- nian monte carlo.J. Mach. Learn. Res., 15(1):1593–1623, 2014. Acknowledgments We thank Jonas Dehning and Abdullah Makkeh for their de- tailed feedback on an early draft of this work. We thank Jonas Dehning for support with the Bayesian inference. W...
work page 2014
-
[56]
Here, we used a weakly informative prior in the form of a uniform distribution U(−2,2) across this range. We enlarged the half-normal prior’s scale forγ to σ= 20 so that it reduces prior-data conflict while still providing weak regularisation. 15 Figure 8: Traces of the parameter inference for DolphinMixtral. Topic biases are color coded for the “climate ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.