2
Agents reach only 62.5% on real terminal tasks
TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
Benchmark drawn from 80k recordings shows weak overlap with curated tests
 full image
full image
abstract click to expand
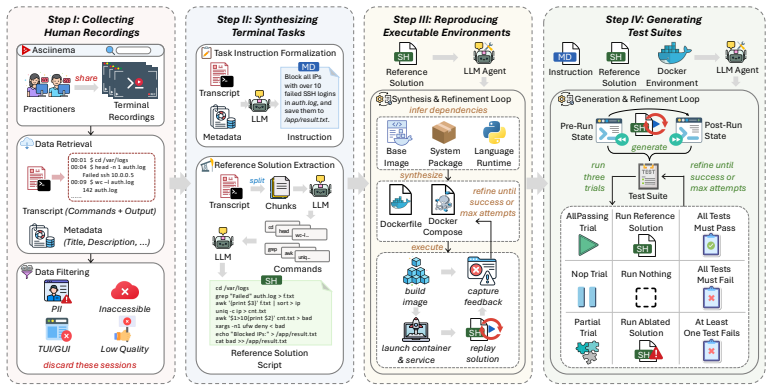
We introduce TerminalWorld, a scalable data engine that automatically reverse-engineers high-fidelity evaluation tasks from "in-the-wild" terminal recordings. Processing 80,870 terminal recordings, the engine yields a full benchmark of 1,530 validated tasks, spanning 18 real-world categories, ranging from short everyday operations to workflows exceeding 50 steps, and covering 1,280 unique commands. From these, we curate a Verified subset of 200 representative, manually reviewed tasks. Comprehensive benchmarking on TerminalWorld-Verified across eight frontier models and six agents reveals that current systems still struggle with authentic terminal workflows, achieving a maximum pass rate of only 62.5%. Moreover, TerminalWorld captures real-world terminal capabilities distinct from existing expert-curated benchmarks (e.g., Terminal-Bench), with only a weak correlation to their scores (Pearson r=0.20). The automated engine makes TerminalWorld authentic and scalable by construction, enabling it to evaluate agents in real-world terminal environments as developer practices evolve. Data and code are available at https://github.com/EuniAI/TerminalWorld.