QSTRBench: a New Benchmark to Evaluate the Ability of Language Models to Reason with Qualitative Spatial and Temporal Calculi
Pith reviewed 2026-05-20 11:14 UTC · model grok-4.3
The pith
Current language models exceed random guessing on qualitative spatial and temporal reasoning but cannot solve all problems consistently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
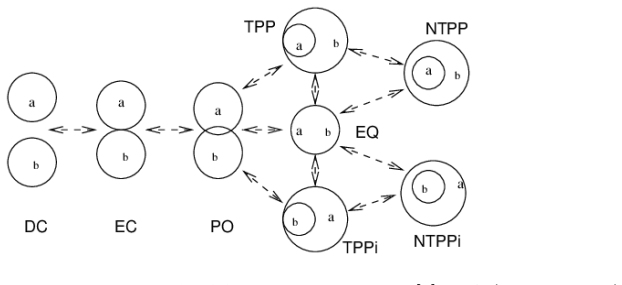
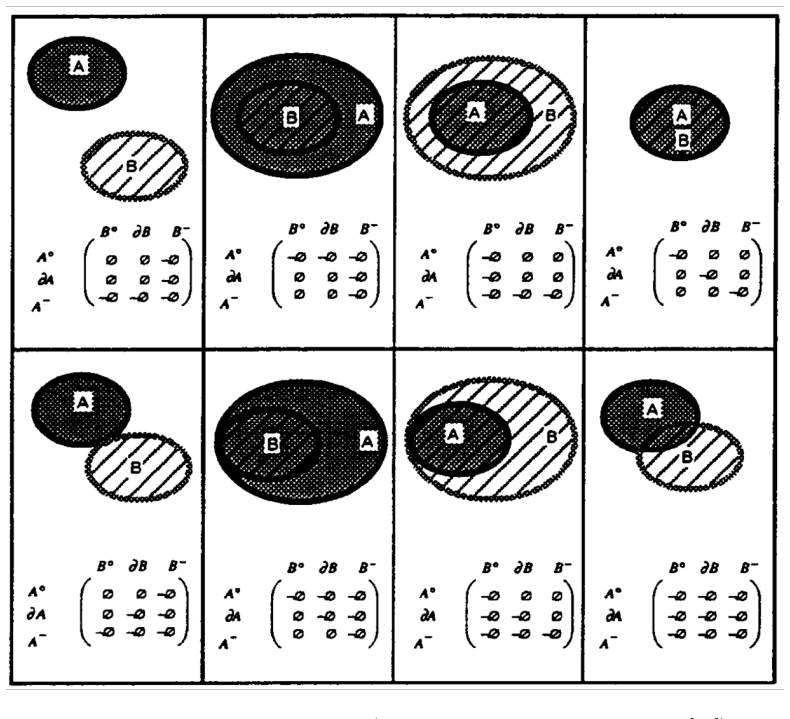
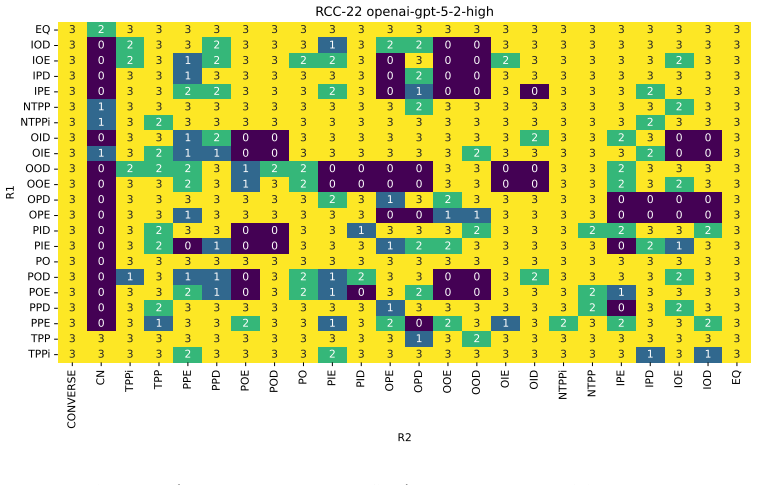
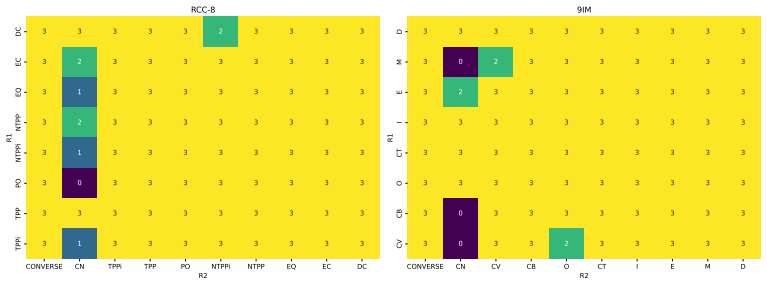
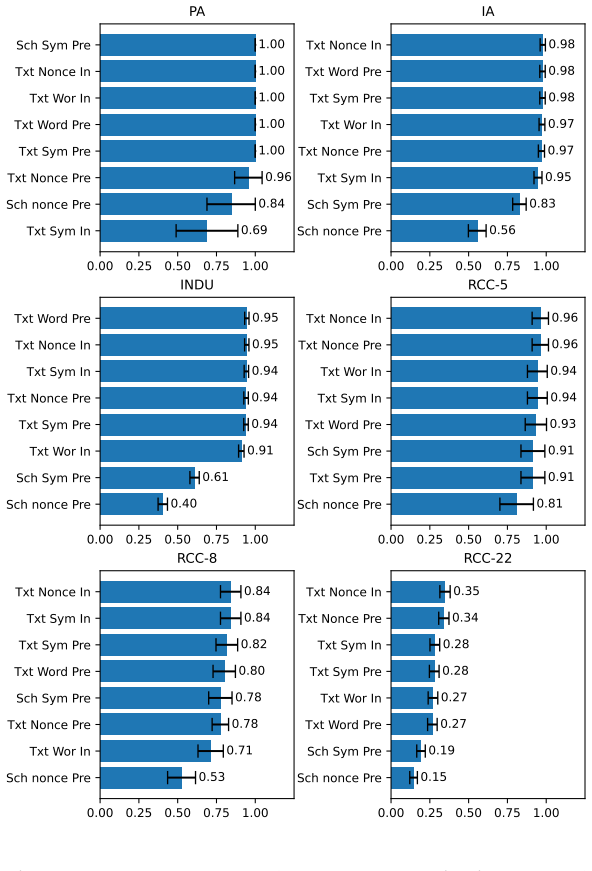
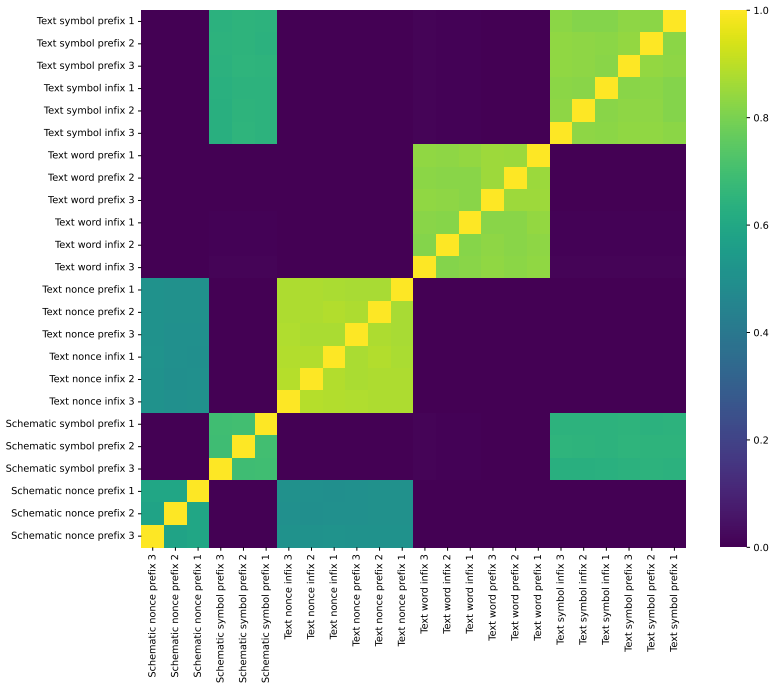
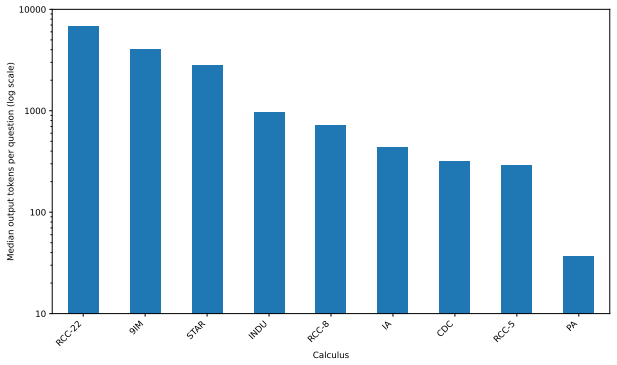
The paper establishes QSTRBench as a comprehensive evaluation tool for LLMs on QSTR tasks involving compositional reasoning via composition tables, converse relations, and conceptual neighbourhoods across multiple calculi including PA, Allen's Interval Algebra, INDU, RCC-5, RCC-8, RCC-22, and others. It reports that all tested contemporary frontier models perform above random guessing levels but fail to answer every question correctly, with performance differing markedly by calculus type—easiest for PA and hardest for RCC-22. The work also introduces the RCC-22 conceptual neighbourhood for the first time and provides an extended version of the benchmark that varies question formats such as 1
What carries the argument
QSTRBench, the benchmark consisting of questions on composition, converse, and conceptual neighbourhood reasoning for qualitative spatial and temporal calculi.
If this is right
- Models can handle simpler calculi like PA better than complex ones like RCC-22.
- No current model achieves consistent correctness across all question types and calculi.
- Variations in question presentation affect how the benchmark tests reasoning.
- Open release of the benchmark enables community-wide assessment of LLM capabilities.
Where Pith is reading between the lines
- LLMs may be using statistical associations from training data rather than performing genuine logical reasoning on these calculi.
- Extending the benchmark to include visual or multimodal inputs could reveal whether spatial reasoning improves with additional modalities.
- The difficulty ordering of calculi might guide the development of specialized training data for improving model performance on harder cases.
Load-bearing premise
The benchmark questions test genuine qualitative reasoning rather than being answerable through patterns learned from training data or prompt engineering tricks.
What would settle it
A language model that correctly answers every question in the benchmark across all calculi and presentation variations would falsify the claim that no current models can consistently solve them.
Figures









read the original abstract
We introduce an extensive qualitative spatial and temporal reasoning (QSTR) benchmark for evaluating large language models (LLMs). We pose questions concerning compositional reasoning (using composition tables, CT), converse relations, and conceptual neighbourhoods (CN) for QSTR calculi, Point Algebra (PA), Allen's Interval Algebra, Interval and Duration (INDU), Region Connection Calculus (RCC-5, RCC-8, and RCC-22), the nine intersection model, cardinal direction calculus, and STAR. The RCC-22 CN is published here for the first time. An extended benchmark systematically varies question presentation including prefix/infix, words/symbols/nonce terms and schematic descriptions for selected calculi. We report results for contemporary frontier models. All models tested perform better than guessing but none can consistently answer all questions correctly. Performance varies sharply by calculus, with PA being the most straightforward, and RCC-22 the most difficult. We release the benchmark, and our results under an open licence to facilitate further assessment of qualitative spatio/temporal reasoning in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QSTRBench, an open benchmark for assessing LLMs on qualitative spatial and temporal reasoning tasks. It covers compositional reasoning via composition tables, converse relations, and conceptual neighborhoods across calculi including PA, Allen's Interval Algebra, INDU, RCC-5/8/22, the nine-intersection model, cardinal directions, and STAR (with the RCC-22 CN published for the first time). Questions are systematically varied by format (prefix/infix, words/symbols/nonce terms, schematic descriptions). Results for frontier models show above-chance performance that is never perfect and varies sharply by calculus (PA easiest, RCC-22 hardest). The full question set and results are released.
Significance. If the benchmark design holds, the work is significant for the AI reasoning community: it supplies a reproducible, open testbed that directly targets a core capability gap in current LLMs. The systematic inclusion of nonce-term and format variations, together with the release of the complete question set, provides concrete protection against training-data leakage and statistical shortcuts. The observed performance gradient across calculi aligns with the differing sizes and complexities of their composition tables and relation sets, offering a falsifiable baseline for future model improvements.
major comments (1)
- [§3] §3 (Benchmark Construction): the claim that the nonce-term and format variations isolate genuine qualitative reasoning would be strengthened by an explicit ablation showing that accuracy differences persist when controlling for surface-form familiarity; without this, the central interpretation that models are tested on reasoning rather than pattern matching remains partially open.
minor comments (3)
- [Table 1] Table 1 and §4.2: the exact scoring rubric (exact match vs. partial credit for converse or neighborhood questions) should be stated in a single, numbered paragraph so that future replications can match the reported numbers without ambiguity.
- [§5] §5 (Results): the paper reports that all models exceed chance but none reach ceiling; adding per-calculus chance baselines (derived from the size of the relation set) as an additional column would make the “above guessing” claim immediately verifiable from the table.
- [Abstract] The abstract states that the RCC-22 CN is published here for the first time; a short appendix or footnote giving the explicit neighborhood table would be useful for readers who wish to verify the new contribution without consulting external sources.
Simulated Author's Rebuttal
We thank the referee for their constructive review, positive assessment of the benchmark's significance, and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): the claim that the nonce-term and format variations isolate genuine qualitative reasoning would be strengthened by an explicit ablation showing that accuracy differences persist when controlling for surface-form familiarity; without this, the central interpretation that models are tested on reasoning rather than pattern matching remains partially open.
Authors: We appreciate this suggestion and agree that an explicit ablation would provide additional support for interpreting the results as evidence of qualitative reasoning. The current design already incorporates nonce terms, format variations, and schematic descriptions precisely to reduce reliance on surface-form familiarity and training-data leakage, and the sharp performance gradient across calculi (e.g., PA versus RCC-22) is consistent with differences in relation-set size and composition-table complexity rather than lexical familiarity alone. Nevertheless, to strengthen the central claim, we will add a targeted ablation in the revised manuscript that directly compares accuracy on familiar-term versus nonce-term versions of the same underlying questions while holding format and reasoning task fixed. This analysis will be performed on the released question set and reported in §3 and the results section. revision: yes
Circularity Check
No significant circularity identified
full rationale
This is an empirical benchmark paper that introduces QSTRBench and reports LLM performance on questions derived from established qualitative spatial/temporal calculi (PA, Allen's IA, RCC variants, etc.). No mathematical derivations, self-referential predictions, or fitted inputs called predictions appear in the work. Results are direct empirical measurements against the released question set and standard composition tables; systematic variations in presentation (prefix/infix, words/symbols, nonce terms) are used to target statistical shortcuts rather than relying on any internal self-definition or self-citation chain. The central claims remain externally verifiable against the calculi definitions and the open benchmark release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard definitions, composition tables, and conceptual neighbourhoods for QSTR calculi including RCC-8, Allen's Interval Algebra, and Point Algebra as established in prior literature.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We pose questions concerning compositional reasoning (using composition tables, CT), converse relations, and conceptual neighbourhoods (CN) for QSTR calculi, Point Algebra (PA), Allen’s Interval Algebra, ... RCC-22 CN is published here for the first time.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
All models tested perform better than guessing but none can consistently answer all questions correctly. Performance varies sharply by calculus, with PA being the most straightforward, and RCC-22 the most difficult.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. G. Cohn, J. Renz, Qualitative spatial representation and reason- ing, in: F. v. Harmelen, V. Lifschitz, B. Porter (Eds.), Handbook of Knowledge Representation, 1, Elsevier, 2007, pp. 551–596
work page 2007
-
[2]
J. Chen, A. G. Cohn, D. Liu, S. Wang, J. Ouyang, Q. Yu, A survey of qualitative spatial representations, The Knowledge Engineering Review 30 (2015) 106–136
work page 2015
-
[3]
A. G. Cohn, S. M. Hazarika, Qualitative spatial representation and reasoning: An overview, Fundamenta Informaticae 46 (2001) 1–29. 32https://github.com/RobBlackwell/QSTRBench accessed May 2026. 45
work page 2001
-
[4]
A Survey of Qualitative Spatial and Temporal Calculi -- Algebraic and Computational Properties
F. Dylla, J. H. Lee, T. Mossakowski, T. Schneider, A. V. Delden, J. V. D. Ven, D. Wolter, A survey of qualitative spatial and temporal calculi: Algebraic and computational properties, ACM Comput. Surv. 50 (2017). URL: https://doi.org/10.1145/3038927 . doi: 10.1145/3038927 , available at https://arxiv.org/pdf/1606.00133
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3038927 2017
-
[5]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, in: Pro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers), Association for Computa- tional Linguistics...
- [6]
-
[7]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. Chatterji, A. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. Gille- spie, K. ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
T. Kwa, B. West, J. Becker, A. Deng, K. Garcia, M. Hasin, S. Jawhar, M. Kinniment, N. Rush, S. V. Arx, R. Bloom, T. Broadley, H. Du, B. Goodrich, N. Jurkovic, L. H. Miles, S. Nix, T. Lin, N. Parikh, D. Rein, L. J. K. Sato, H. Wijk, D. M. Ziegler, E. Barnes, L. Chan, Measuring Ai ability to complete long tasks, 2025. URL: https://arxiv.org/ab s/2503.14499....
-
[9]
A. G. Cohn, B. Bennett, J. Gooday, N. M. Gotts, Qualitative spa- tial representation and reasoning with the region connection calculus, Geoinformatica 1 (1997) 275–316
work page 1997
-
[10]
Freksa, Temporal reasoning based on semi-intervals, Artificial intel- ligence 54 (1992) 199–227
C. Freksa, Temporal reasoning based on semi-intervals, Artificial intel- ligence 54 (1992) 199–227
work page 1992
-
[11]
D. Randell, A. G. Cohn, Modelling topological and metrical properties in physical processes, in: Proceedings of the First International Conference on Principles of Knowledge Representation and Reasoning, 1989, pp. 357–368
work page 1989
- [12]
- [13]
-
[14]
E.-O. Gardelakos, V. Kyriakopoulos, D.-A. Pantazi, O.-M. Kapopoulos, M. Tsourma, M. Koubarakis, Can large reasoning models reason about spatial relations?, in: Proceedings of the 8th ACM SIGSPATIAL In- ternational Workshop on AI for Geographic Knowledge Discovery, 2025, pp. 81–91
work page 2025
-
[15]
P. Bellodi, P. Casavecchia, A. Paparella, G. Sciavicco, I. E. Stan, As- sessing the (in) ability of LLMs to reason in interval temporal logic, in: 32nd International Symposium on Temporal Representation and Rea- soning (TIME 2025), Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 2025, pp. 4–1. 47
work page 2025
- [16]
-
[17]
O. Topsakal, E. Colby, H. Jackson, Evaluating the performance of large language models (LLMs) through grid-based game competitions: An extensible benchmark and leaderboard on the path to artificial general intelligence (AGI), The Journal of Cognitive Systems 9 (2025) 8–19
work page 2025
- [18]
-
[19]
X. Fu, Y. Hu, B. Li, Y. Feng, H. Wang, X. Lin, D. Roth, N. A. Smith, W.-C. Ma, R. Krishna, Blink: Multimodal large language models can see but not perceive, in: European Conference on Computer Vision, Springer, 2024, pp. 148–166
work page 2024
-
[20]
H. Yin, Z. Lin, X. Liu, B. Sun, K. Li, Do multimodal language models really understand direction? a benchmark for compass direction reason- ing, in: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2025, pp. 1–5
work page 2025
-
[21]
A. G. Cohn, R. E. Blackwell, Evaluating the ability of large language models to reason about cardinal directions, revisited, 2025. URL: https: //arxiv.org/abs/2507.12059 . arXiv:2507.12059, accepted at the 38th International Workshop on Qualitative Reasoning (QR 2025), co- located with IJCAI
-
[22]
S. Xie, S.-L. Hsu, Q. Zhang, Y. Gao, C. Shahabi, I. Sabek, Evaluating intrinsic geospatial topological reasoning in LLMs, in: Proceedings of the 1st ACM SIGSPATIAL International Workshop on Generative and Agentic AI for Multi-Modality Space-Time Intelligence, 2025, pp. 43–48
work page 2025
- [23]
-
[24]
F. Li, D. C. Hogg, A. G. Cohn, Advancing spatial reasoning in large language models: An in-depth evaluation and enhancement using the 48 stepgame benchmark, Proceedings of the AAAI Conference on Artificial Intelligence 38 (2024) 18500–18507. URL: https://ojs.aaai.org/ind ex.php/AAAI/article/view/29811 . doi: 10.1609/aaai.v38i17.2981 1
-
[25]
Z. Shi, Q. Zhang, A. Lipani, StepGame: A new benchmark for robust multi-hop spatial reasoning in texts, in: Proc. AAAI, volume 36, 2022, pp. 11321–11329
work page 2022
-
[26]
DecompSR: A dataset for decomposed analyses of compositional multihop spatial reasoning
L. McPheat, N. Kaur, R. Blackwell, A. Russo, A. G. Cohn, P. Mad- hyastha, DecompSR: A dataset for decomposed analyses of composi- tional multihop spatial reasoning, 2025. URL: https://arxiv.org/ab s/2511.02627. arXiv:2511.02627
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
R. Mirzaee, H. Rajaby Faghihi, Q. Ning, P. Kordjamshidi, SPARTQA: A textual question answering benchmark for spatial reasoning, in: Proc. NAACL, 2021, pp. 4582–4598
work page 2021
-
[28]
Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks
J. Weston, A. Bordes, S. Chopra, A. M. Rush, B. Van Merriënboer, A. Joulin, T. Mikolov, Towards AI-complete question answering: A set of prerequisite toy tasks, arXiv preprint arXiv:1502.05698 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [29]
-
[30]
A. Isli, A. G. Cohn, A new approach to cyclic ordering of 2d orientations using ternary relation algebras, Artificial Intelligence 122 (2000) 137–
work page 2000
-
[31]
A vailable at https://www.sciencedirect.com/science/articl e/pii/S0004370200000448/pdf?md5=555f1a9e6f8a6567d9f08f607b 7dc7a2&pid=1-s2.0-S0004370200000448-main.pdf
-
[32]
C. Freksa, Using orientation information for qualitative spatial rea- soning, in: Theories and Methods of Spatio-Temporal Reasoning in Geographic Space: International Conference GIS-From Space to Terri- tory: Theories and Methods of Spatio-Temporal Reasoning Pisa, Italy, September 21–23, 1992 Proceedings, Springer, 2005, pp. 162–178. A vail- able at https...
work page 1992
-
[33]
Z. Gantner, M. Westphal, S. Wölfl, Gqr - a fast reasoner for binary qualitative constraint calculi, in: AAAI Workshop on Spatial and Tem- poral Reasoning, AAAI Chicago (IL), 2008, p. 6. A vailable at https: //cdn.aaai.org/Workshops/2008/WS-08-11/WS08-11-004.pdf
work page 2008
-
[34]
D. Wolter, SparQ – A Spatial Reasoning Toolbox., in: AAAI Spring Symposium: Benchmarking of Qualitative Spatial and Temporal Rea- soning Systems, 2009, p. 53. A vailable at https://cdn.aaai.org/Sym posia/Spring/2009/SS-09-02/SS09-02-012.pdf
work page 2009
-
[35]
M. J. Egenhofer, D. M. Mark, J. Herring, The 9-intersection: Formal- ism and its use for natural-language spatial predicates (94-1), Technical Report 94-1, National Center for Geographic Information and Analysis,
-
[36]
URL: https://escholarship.org/content/qt5nj6647c/qt5n j6647c.pdf
-
[37]
A. U. Frank, Qualitative spatial reasoning: Cardinal directions as an example, International Journal of Geographical Information Science 10 (1996) 269–290. A vailable at https://www.frank.gerastree.at/Pub licationList/resources/docs/docsH/ijgis-frank.pdf
work page 1996
-
[38]
J. Renz, D. Mitra, et al., Qualitative direction calculi with arbitrary granularity, in: PRICAI, volume 3157, 2004, pp. 65–74
work page 2004
-
[39]
A. G. Cohn, R. E. Blackwell, Evaluating the Ability of Large Language Models to Reason About Cardinal Directions, in: B. Adams, A. L. Griffin, S. Scheider, G. McKenzie (Eds.), 16th International Conference on Spatial Information Theory (COSIT 2024), volume 315 of Leibniz International Proceedings in Informatics (LIPIcs) , Schloss Dagstuhl – Leibniz-Zentrum ...
-
[40]
J. F. Allen, Maintaining knowledge about temporal intervals, Com- munications of the ACM 26 (1983) 832–843. A vailable at https: //dl.acm.org/doi/pdf/10.1145/182.358434
-
[41]
D. Randell, Z. Cui, A. G. Cohn, A spatial logic based on regions and connection, in: 3rd International Conference on Knowledge Represen- tation and Reasoning, 1992, volume 92, 1992, pp. 165–176. 50
work page 1992
-
[42]
M. B. Vilain, H. A. Kautz, Constraint propagation algorithms for tem- poral reasoning., in: AAAI, volume 86, 1986, pp. 377–382. A vailable at https://cdn.aaai.org/AAAI/1986/AAAI86-063.pdf
work page 1986
-
[43]
B. Bennett, Spatial reasoning with propositional logics, in: Principles of Knowledge Representation and Reasoning, Elsevier, 1994, pp. 51–62. A vailable at https://citeseerx.ist.psu.edu/document?repid=rep 1&type=pdf&doi=4c45519c2db0dac5ceaa76e1b53b1ca3c0bfce00
work page 1994
-
[44]
P. Jonsson, T. Drakengren, A complete classification of tractability in RCC-5, Journal of Artificial Intelligence Research 6 (1997) 211–221. A vailable at https://www.jair.org/index.php/jair/article/down load/10187/24187/
work page 1997
- [45]
-
[46]
Z. Cui, A. G. Cohn, D. A. Randell, Qualitative and topological relation- ships in spatial databases, in: D. Abel, B. Chin Ooi (Eds.), Advances in Spatial Databases, Springer Berlin Heidelberg, Berlin, Heidelberg, 1993, pp. 296–315
work page 1993
-
[47]
A. K. Pujari, G. Vijaya Kumari, A. Sattar, INDU: An interval & du- ration network, in: Australasian Joint Conference on Artificial Intelli- gence, Springer, 1999, pp. 291–303. A vailable at https://citeseerx. ist.psu.edu/document?repid=rep1&type=pdf&doi=11328a3099706 0552f8971c599bde8ea6d581d21
work page 1999
-
[48]
C. Schlieder, Reasoning about ordering, in: International conference on spatial information theory, Springer, 1995, pp. 341–349
work page 1995
- [49]
-
[50]
G. F. Ligozat, Qualitative triangulation for spatial reasoning, in: Eu- ropean Conference on Spatial Information Theory, Springer, 1993, pp. 51 54–68. A vailable at https://link.springer.com/chapter/10.1007/ 3-540-57207-4_5
work page 1993
- [51]
-
[52]
E. Clementini, P. Di Felice, D. Hernández, Qualitative representation of positional information, Artificial intelligence 95 (1997) 317–356. A vail- able at https://www.sciencedirect.com/science/article/pii/S0 004370297000465/pdf?md5=be67a5e4a7057f94a25879a9f7c5b076&p id=1-s2.0-S0004370297000465-main.pdf&_valck=1
work page 1997
-
[53]
D. Hernández, E. Clementini, P. Di Felice, Qualitative distances, in: Spatial Information Theory A Theoretical Basis for GIS: International Conference COSIT’95 Semmering, Austria, September 21–23, 1995 Pro- ceedings 2, Springer, 1995, pp. 45–57
work page 1995
-
[54]
R. Moratz, Extending binary qualitative direction calculi with a gran- ular distance concept: Hidden feature attachment, arXiv preprint arXiv:1012.5960 (2010)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[55]
H. W. Guesgen, Spatial reasoning based on Allen’s temporal logic, ICSI (1989)
work page 1989
-
[56]
P. Balbiani, J.-F. Condotta, L. F. Del Cerro, Tractability results in the block algebra, Journal of Logic and Computation 12 (2002) 885–909. A vailable at https://academic.oup.com/logcom/article-pdf/12/ 5/885/3852916/120885.pdf
work page 2002
-
[57]
Köhler, The occlusion calculus, in: Cognitive vision workshop, Cite- seer, 2002, pp
C. Köhler, The occlusion calculus, in: Cognitive vision workshop, Cite- seer, 2002, pp. 420–450. A vailable at https://citeseerx.ist.psu.ed u/document?repid=rep1&type=pdf&doi=21f52b4007e25b30267b532 d22a74995ba8dcc48
work page 2002
-
[58]
N. Van de Weghe, B. Kuijpers, P. Bogaert, P. De Maeyer, A qualitative trajectory calculus and the composition of its relations, in: International Conference on GeoSpatial Sematics, Springer, 2005, pp. 60–76. 52
work page 2005
- [59]
-
[60]
M. Broxvall, P. Jonsson, Point algebras for temporal reasoning: Algo- rithms and complexity, Artificial Intelligence 149 (2003) 179–220
work page 2003
-
[61]
F. Dylla, An agent control perspective on qualitative spatial reasoning: Towards more intuitive spatial agent development. vol. 320, 2008
work page 2008
-
[62]
Crystal, The Cambridge encyclopedia of the English language, Cam- bridge university press, 2018
D. Crystal, The Cambridge encyclopedia of the English language, Cam- bridge university press, 2018
work page 2018
- [63]
-
[65]
L. Li, L. Sleem, G. Nichil, R. State, et al., Exploring the impact of tem- perature on large language models: Hot or cold?, Procedia Computer Science 264 (2025) 242–251
work page 2025
-
[66]
R. Burnell, W. Schellaert, J. Burden, T. D. Ullman, F. Martinez- Plumed, J. B. Tenenbaum, D. Rutar, L. G. Cheke, J. Sohl-Dickstein, M. Mitchell, D. Kiela, M. Shanahan, E. M. Voorhees, A. G. Cohn, J. Z. Leibo, J. Hernandez-Orallo, Rethink reporting of evaluation results in AI, Science 380 (2023) 136–138
work page 2023
- [67]
-
[68]
A. Cohn, J. Gooday, B. Bennett, A comparison of structures in spatial and temporal logics, in: Philosophy and the Cognitive Sciences, R. Casati, G. White (eds.), Holder-Pichler-Temp, 1994
work page 1994
-
[69]
G. É. Ligozat, Reasoning about cardinal directions, Journal of Visual Languages & Computing 9 (1998) 23–44. 53
work page 1998
- [70]
-
[71]
M. J. Egenhofer, J. Sharma, D. M. Mark, et al., A critical comparison of the 4-intersection and 9-intersection models for spatial relations: for- mal analysis, in: Autocarto-Conference, ASPRS American Society for Photogrametry, 1993, pp. 1–1
work page 1993
-
[72]
K. Leyton-Brown, Y. Shoham, Understanding understanding: A prag- matic framework motivated by large language models, arXiv preprint arXiv:2406.10937 (2024)
- [73]
-
[74]
Small Language Models are the Future of Agentic AI
URL: https://arxiv.org/abs/2506.02153. arXiv:2506.02153
work page internal anchor Pith review Pith/arXiv arXiv
- [75]
-
[76]
R. E. Blackwell, A. G. Cohn, RCC-8 as a benchmark for diagrammatic reasoning in multimodal foundation models, in: Proc. COSIT, 2026, to appear
work page 2026
-
[77]
F. Li, D. Hogg, A. Cohn, Reframing spatial reasoning evaluation in language models: A real-world simulation benchmark for qualitative reasoning, in: Proceedings of the Thirty-Third International Joint Con- ference on Artificial Intelligence, International Joint Conferences on Ar- tificial Intelligence, 2024, pp. 6342–6349
work page 2024
-
[78]
T. Drakengren, P. Jonsson, A complete classification of tractability in RCC-5, Journal of Artificial Intelligence Research 6 (1997) 211–221
work page 1997
-
[79]
J. Renz, B. Nebel, On the complexity of qualitative spatial reasoning: A maximal tractable fragment of the region connection calculus, Artificial Intelligence 108 (1999) 69–123
work page 1999
-
[80]
A. Galton, Qualitative spatial change, Oxford University Press, 2000. 54 Appendix A. Example prompts for RCC-8 Appendix A.1. Text symbol prefix You are a helpful assistant who answers questions about qualitative spa- tial and temporal calculi. The Region Connection Calculus (RCC-8) is a qualitative spatial calculus for representing and reasoning about spat...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.