DecompSR: A dataset for decomposed analyses of compositional multihop spatial reasoning
Pith reviewed 2026-05-18 01:15 UTC · model grok-4.3
The pith
DecompSR lets researchers independently vary four dimensions of compositionality to show LLMs struggle with productive and systematic generalisation in spatial reasoning tasks while remaining more robust to linguistic changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
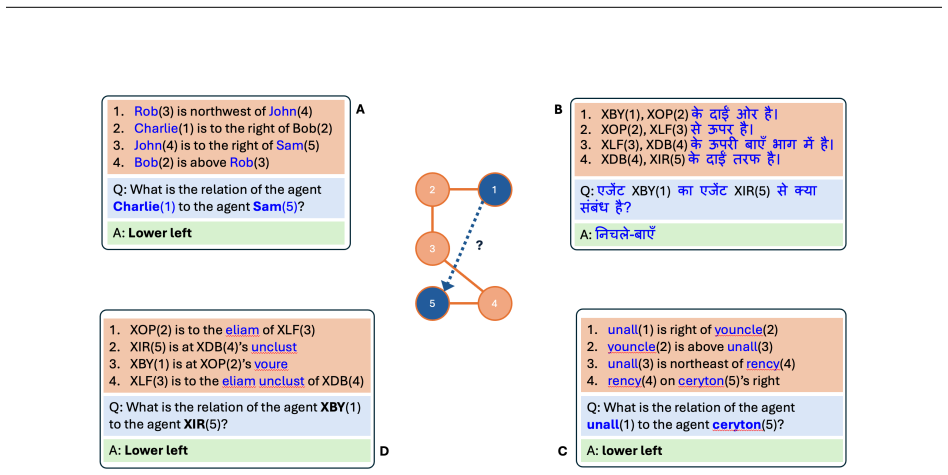
DecompSR is a procedurally generated and symbolically verified benchmark that decomposes spatial reasoning into four independently controllable compositionality dimensions: productivity via increased reasoning depth, substitutivity via entity and linguistic variation, overgeneralisation via input order and distractors, and systematicity via novel linguistic elements. Benchmarking across LLMs reveals that models struggle with productive and systematic generalisation in spatial reasoning tasks while remaining more robust to linguistic variation.
What carries the argument
The DecompSR procedural generation framework, which produces multihop spatial reasoning questions while independently varying productivity, substitutivity, overgeneralisation, and systematicity and verifies correctness with a symbolic solver.
If this is right
- LLM accuracy will decline as the number of spatial reasoning steps increases.
- LLMs will show large performance drops when questions contain novel linguistic elements not seen in training.
- LLMs will remain comparatively stable when only entity names or surface phrasing change.
- Specific distractors or reversed input orders will trigger overgeneralisation errors in current models.
Where Pith is reading between the lines
- The same independent-control approach could be applied to temporal or causal reasoning benchmarks to test whether the same productivity and systematicity weaknesses appear outside spatial domains.
- Targeted fine-tuning on high-productivity or high-systematicity slices of DecompSR could be used to strengthen the dimensions where models currently fail.
- If the four dimensions prove not to be fully independent in practice, the dataset would still serve as a diagnostic for correlated failure modes in existing LLMs.
Load-bearing premise
The procedural generation rules and symbolic solver correctly capture and verify independent control over the four compositionality dimensions without introducing unintended correlations or biases in the resulting questions.
What would settle it
An LLM that achieves and maintains high accuracy on the highest-productivity and highest-systematicity subsets of DecompSR, while still performing well on the base cases, would falsify the reported pattern of struggles with those two forms of generalisation.
Figures






read the original abstract
We introduce DecompSR, decomposed spatial reasoning, a large benchmark dataset (over 5m datapoints) and generation framework designed to analyse compositional spatial reasoning ability. The generation of DecompSR allows users to independently vary several aspects of compositionality, namely: productivity (reasoning depth), substitutivity (entity and linguistic variability), overgeneralisation (input order, distractors) and systematicity (novel linguistic elements). DecompSR is built procedurally in a manner which makes it is correct by construction, which is independently verified using a symbolic solver to guarantee the correctness of the dataset. DecompSR is comprehensively benchmarked across a host of Large Language Models (LLMs) where we show that LLMs struggle with productive and systematic generalisation in spatial reasoning tasks whereas they are more robust to linguistic variation. DecompSR provides a provably correct and rigorous benchmarking dataset with a novel ability to independently vary the degrees of several key aspects of compositionality, allowing for robust and fine-grained probing of the compositional reasoning abilities of LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DecompSR, a large-scale dataset exceeding 5 million datapoints for analyzing compositional multihop spatial reasoning. The accompanying generation framework permits independent variation of four compositionality aspects: productivity via reasoning depth, substitutivity through entity and linguistic variability, overgeneralisation using input order and distractors, and systematicity with novel linguistic elements. The dataset is generated procedurally to be correct by construction, with verification via a symbolic solver. Empirical benchmarking on LLMs indicates difficulties with productive and systematic generalisation, contrasted with greater robustness to linguistic variation.
Significance. If the four compositionality dimensions can be controlled independently without introducing confounding correlations, this dataset represents a valuable advancement for the field. It enables precise probing of where LLMs fail in compositional spatial reasoning. The large scale, procedural correctness, and symbolic verification are notable strengths that support reproducible and rigorous evaluation. This could inform future model development by highlighting specific generalisation challenges.
major comments (2)
- [Generation Framework] The central claim that LLMs struggle specifically with productive and systematic generalisation (while being robust to linguistic variation) depends on the four dimensions being varied independently. The procedural generation rules and symbolic solver guarantee answer correctness but do not automatically ensure lack of correlations (e.g., between reasoning depth and distractor frequency or entity substitution patterns). Please add quantitative checks, such as correlation analysis or parameter ablation tables, in the generation framework section to confirm independence.
- [Benchmarking Experiments] The benchmarking results attribute performance drops to particular dimensions, but without explicit cross-dimension comparisons or controls for unintended biases in question construction, the attribution remains vulnerable to confounds. Include tables or figures showing performance as a function of each isolated dimension with statistical tests.
minor comments (2)
- [Abstract] The abstract mentions 'over 5m datapoints'; reporting the precise total count or a breakdown by dimension would improve precision.
- [Methods] Clarify the exact operational definitions and example questions for each of the four compositionality dimensions in the main text to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and positive feedback, which highlights the potential value of DecompSR for probing compositional spatial reasoning. We address each major comment below and will incorporate revisions to strengthen the manuscript's rigor regarding dimension independence and benchmarking controls.
read point-by-point responses
-
Referee: [Generation Framework] The central claim that LLMs struggle specifically with productive and systematic generalisation (while being robust to linguistic variation) depends on the four dimensions being varied independently. The procedural generation rules and symbolic solver guarantee answer correctness but do not automatically ensure lack of correlations (e.g., between reasoning depth and distractor frequency or entity substitution patterns). Please add quantitative checks, such as correlation analysis or parameter ablation tables, in the generation framework section to confirm independence.
Authors: We agree that empirical verification of independence is important to substantiate our claims about isolated effects of each dimension. In the revised manuscript, we will add a new subsection to the Generation Framework detailing quantitative checks. This will include pairwise Pearson correlation analyses across the control parameters (e.g., reasoning depth with distractor frequency, entity substitution rate with linguistic novelty) computed over large samples of generated instances. We will also include parameter ablation tables showing performance or distribution statistics when varying one dimension while holding others fixed. These additions will demonstrate that confounding correlations are minimal and that the dimensions can be controlled independently. revision: yes
-
Referee: [Benchmarking Experiments] The benchmarking results attribute performance drops to particular dimensions, but without explicit cross-dimension comparisons or controls for unintended biases in question construction, the attribution remains vulnerable to confounds. Include tables or figures showing performance as a function of each isolated dimension with statistical tests.
Authors: We acknowledge that stronger statistical controls would improve the robustness of our performance attributions. In the revised Benchmarking Experiments section, we will add tables and figures displaying accuracy (and other metrics) as a function of each isolated dimension, with other dimensions held at fixed baseline values. These will be accompanied by statistical tests including one-way ANOVA and post-hoc Tukey HSD tests to evaluate significance of differences across levels of each dimension. We will also include cross-dimension interaction plots and regression models to quantify any residual confounds or interactions. revision: yes
Circularity Check
No circularity: empirical dataset construction and benchmarking
full rationale
The paper presents a procedurally generated dataset (DecompSR) whose correctness is asserted by construction and independently verified via a symbolic solver, followed by direct empirical benchmarking of LLMs on controlled variations of productivity, substitutivity, overgeneralisation, and systematicity. No mathematical derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. The reported LLM performance patterns are observational outcomes from running models on the generated data rather than results that reduce to the generation rules by construction. The four compositionality dimensions are controlled via explicit procedural rules whose independence is an empirical claim open to external verification, not a self-definitional loop. This is a standard dataset-plus-benchmark paper with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Procedural generation rules produce questions whose ground-truth answers are correctly determined by a symbolic solver.
Reference graph
Works this paper leans on
-
[1]
Systematic Generalization: What Is Required and Can It Be Learned?
Dzmitry Bahdanau, Shikhar Murty, Michael Noukhovitch, Thien Huu Nguyen, Harm de Vries, and Aaron Courville. Systematic generalization: what is required and can it be learned? arXiv preprint arXiv:1811.12889,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source llms
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondřej Dušek. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source llms. arXiv preprint arXiv:2402.03927 ,
-
[3]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott M Lundberg, et al. Sparks of artificial general intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Spatialrgpt: Grounded spatial reasoning in vision language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision language models. arXiv preprint arXiv:2406.01584 ,
-
[5]
On the Measure of Intelligence
François Chollet. On the Measure of Intelligence. (arXiv:1911.01547), November
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[6]
Transformers as soft reasoners over language
Peter Clark, Oyvind Tafjord, and Kyle Richardson. Transformers as soft reasoners over language. arXiv preprint arXiv:2002.05867 ,
-
[7]
doi: 10.1016/j.cognition.2023.105690
ISSN 00100277. doi: 10.1016/j.cognition.2023.105690. Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, et al. Faith and fate: Limits of transformers on compositionality. Advances in Neural Information Processing Systems , 36:70293–70332,
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding. arXiv, (arXiv:2009.03300), January 2021a. doi: 10.48550/arXiv.2009.03300. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring M...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2009
-
[10]
Evaluating step-by-step reasoning traces: A survey
Jinu Lee and Julia Hockenmaier. Evaluating step-by-step reasoning traces: A survey. arXiv preprint arXiv:2502.12289,
-
[11]
Unsupervised compositional concepts discovery with text-to-image generative models
Nan Liu, Yilun Du, Shuang Li, Joshua B Tenenbaum, and Antonio Torralba. Unsupervised compositional concepts discovery with text-to-image generative models. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 2085–2095,
work page 2085
-
[12]
Deepseek-r1 thoughtology: Let’s< think> about llm reasoning
12 Sara Vera Marjanović, Arkil Patel, Vaibhav Adlakha, Milad Aghajohari, Parishad BehnamGhader, Mehar Bhatia, Aditi Khandelwal, Austin Kraft, Benno Krojer, Xing Han Lù, et al. Deepseek-r1 thoughtology: Let’s< think> about llm reasoning. arXiv preprint arXiv:2504.07128 ,
-
[13]
Thomas McCoy, Sewon Min, and Tal Linzen
R. Thomas McCoy, Sewon Min, and Tal Linzen. Embers of autoregression: Understanding large language models through the problem they are trained to solve. arXiv preprint arXiv:2309.13918 ,
-
[14]
Inadequacies of large language model benchmarks in the era of generative artificial intelligence
Timothy R McIntosh, Teo Susnjak, Nalin Arachchilage, Tong Liu, Paul Watters, and Malka N Halgamuge. Inadequacies of large language model benchmarks in the era of generative artificial intelligence. arXiv preprint arXiv:2402.09880 ,
-
[15]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Direct evaluation of chain-of-thought in multi-hop reasoning with knowledge graphs
Minh-Vuong Nguyen, Linhao Luo, Fatemeh Shiri, Dinh Phung, Yuan-Fang Li, Thuy-Trang Vu, and Gholam- reza Haffari. Direct evaluation of chain-of-thought in multi-hop reasoning with knowledge graphs. arXiv preprint arXiv:2402.11199 ,
-
[17]
Pervasive label errors in test sets destabilize machine learning benchmarks
Curtis G Northcutt, Anish Athalye, and Jonas Mueller. Pervasive label errors in test sets destabilize machine learning benchmarks. arXiv preprint arXiv:2103.14749 ,
-
[18]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark. arXiv preprint arXiv:2310.18018 ,
-
[20]
Clutrr: A diagnostic benchmark for inductive reasoning from text
Koustuv Sinha, Shagun Sodhani, Jin Dong, Joelle Pineau, and William L Hamilton. Clutrr: A diagnostic benchmark for inductive reasoning from text. arXiv preprint arXiv:1908.06177 ,
-
[21]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answer- ing challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Zhuoyan Xu, Zhenmei Shi, and Yingyu Liang. Do large language models have compositional ability? an investigation into limitations and scalability. arXiv preprint arXiv:2407.15720 ,
-
[24]
A LLM prompts A.1 5-shot default prompt 1 {{" id": "{ line['ID ']}" , 2 " messages ": [ 3 {{" role ": "user "," content ":" Given a story about spatial relations among objects , answer the relation between two queried objects . Possible relations are: above , below , left , right , upper -left , upper -right , lower -left , and lower -right. If a sentence...
work page 2024
-
[25]
where we have sufficient data we compute the prediction interval across multiple experimental repeats ( Blackwell et al. , 2024). All LLM experiments were conducted using the Golem software
work page 2024
-
[26]
Also, if a model has typically been defined as LRM, but we ran it in the standard mode (without reasoning), we will categorize the model as LLM. We conducted further analysis of the types of errors made by the models. For k = 1 , we observed that most models tended to produce incorrect answers on the same set of questions, indicating a high degree of over...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.