FASE: FPGA-Assisted Syscall Emulation for Rapid End-to-End Processor Performance Validation
Pith reviewed 2026-05-22 12:59 UTC · model grok-4.3
The pith
FASE lets complex benchmarks run directly on early processor designs via FPGA syscall emulation without full SoC or OS integration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
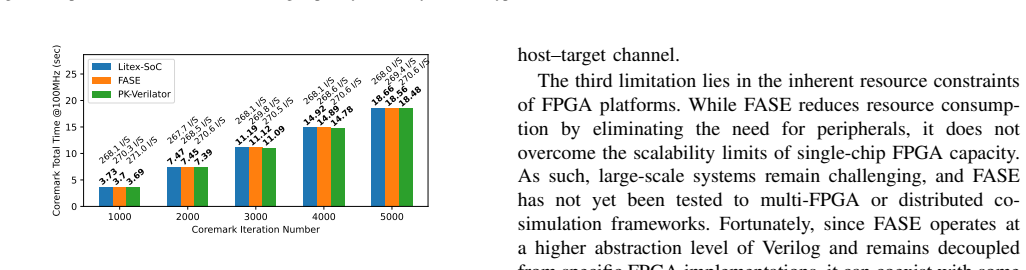
FASE is the first FPGA adaptation of syscall emulation that exposes only a minimal CPU interface, uses a Host-Target Protocol to reduce cross-device traffic, and delegates Linux-style calls to a host runtime, allowing complex multi-thread benchmarks to execute on the processor design alone for early-stage validation with measured accuracy above 96 percent single-thread and 91.5 percent multi-thread relative to complete SoC results.
What carries the argument
The Host-Target Protocol together with a minimal CPU interface that delegates syscalls to a remote host runtime while preserving timing fidelity on the FPGA.
If this is right
- Design teams can obtain end-to-end performance data on multi-thread code before RTL is integrated into a full SoC.
- Iteration cycles for domain-specific processors shrink because validation no longer waits for OS porting or peripheral bring-up.
- FPGA prototypes become usable for accurate benchmarking of complex workloads that previously required software simulation or late-stage hardware.
- Open release of the framework components allows reuse across other RISC-V or similar processor designs on Xilinx FPGAs.
Where Pith is reading between the lines
- The same minimal-interface pattern could be applied to other FPGA emulation flows that currently require full peripheral models.
- Accuracy might improve further for specific AI workloads by adding workload-aware traffic shaping inside the Host-Target Protocol.
- Combining FASE with existing RTL simulators could create a hybrid early-validation pipeline that switches between software and FPGA runs without rewriting benchmarks.
Load-bearing premise
The minimal CPU interface and Host-Target Protocol reproduce the timing and behavior of a full SoC closely enough that performance numbers for general workloads remain unbiased.
What would settle it
Measure the same OpenMP benchmarks on both FASE and a complete SoC implementation of the same Rocket core and check whether the reported performance error stays below 8.5 percent for the multi-thread workloads.
Figures















read the original abstract
The rapid advancement of AI workloads and domain-specific architectures has led to increasingly diverse processor microarchitectures, whose design exploration requires fast and accurate performance validation. However, traditional workflows defer validation process until RTL design and SoC integration are complete, significantly prolonging development and iteration cycle. In this work, we present FASE framework, FPGA-Assisted Syscall Emulation, the first work for adapt syscall emulation on FPGA platforms, enabling complex multi-thread benchmarks to directly run on the processor design without integrating SoC or target OS for early-stage performance validation. FASE introduces three key innovations to address three critical challenges for adapting FPGA-based syscall emulation: (1) only a minimal CPU interface is exposed, with other hardware components untouched, addressing the lack of a unified hardware interface in FPGA systems; (2) a Host-Target Protocol (HTP) is proposed to minimize cross-device data traffic, mitigating the low-bandwidth and high-latency communication between FPGA and host; and (3) a host-side runtime is proposed to remotely handle Linux-style system calls, addressing the challenge of cross-device syscall delegation. Experiments ware conducted on Xilinx FPGA with open-sourced RISC-V SMP processor Rocket. With single-thread CoreMark, FASE introduces less than 1% performance error and achieves over 2000x higher efficiency compared to Proxy Kernel due to FPGA acceleration. With complex OpenMP benchmarks, FASE demonstrates over 96% performance validation accuracy for most single-thread workloads and over 91.5% for most multi-thread workloads compared to full SoC validation, significantly reducing development complexity and time-to-feedback. All components of FASE framework are released as open-source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FASE, an FPGA-Assisted Syscall Emulation framework that enables complex multi-thread benchmarks to run directly on a processor design (e.g., Rocket RISC-V SMP) without full SoC integration or target OS, for early performance validation. It proposes three innovations: a minimal CPU interface exposing only necessary hardware, the Host-Target Protocol (HTP) to reduce cross-device traffic over low-bandwidth FPGA-host links, and a host-side runtime to handle Linux-style syscalls remotely. Experiments on Xilinx FPGA report <1% error and >2000x efficiency vs. Proxy Kernel for single-thread CoreMark, plus >96% accuracy for most single-thread and >91.5% for most multi-thread OpenMP workloads vs. full SoC baseline, with all components released open-source.
Significance. If the central empirical claims hold, FASE could meaningfully shorten processor design iteration cycles for diverse microarchitectures by providing rapid end-to-end feedback before RTL/SoC completion. The open-source release of the full framework is a clear strength that supports reproducibility. The use of physical FPGA hardware against a full-SoC baseline, rather than simulation-only comparisons, adds concrete grounding to the accuracy numbers.
major comments (2)
- [Evaluation] The central claim that a minimal CPU interface plus HTP faithfully reproduces full-SoC timing rests on aggregate accuracy figures (>91.5% for most multi-thread OpenMP cases). However, no per-phase or per-operation error breakdown is provided for synchronization-heavy sections (e.g., barriers or reductions), leaving open the possibility that residual HTP latency or host-side syscall handling introduces systematic bias concentrated in those phases rather than uniformly distributed error.
- [Abstract and Evaluation] Workload selection, measurement methodology (including how performance counters are collected across FPGA-host boundaries), and any statistical significance testing are not detailed. This makes it difficult to assess whether the reported accuracy numbers could be sensitive to post-hoc choices or specific to the evaluated CoreMark/OpenMP set.
minor comments (2)
- [Abstract] Typo in abstract: 'Experiments ware conducted' should read 'were conducted'.
- [Host-Target Protocol] The description of HTP would benefit from a timing diagram or pseudocode showing the exact message sequence for a typical syscall to clarify how serialization and host handling affect effective memory access patterns.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We have carefully considered the points raised regarding the evaluation and have made revisions to provide additional details and analysis as described below.
read point-by-point responses
-
Referee: [Evaluation] The central claim that a minimal CPU interface plus HTP faithfully reproduces full-SoC timing rests on aggregate accuracy figures (>91.5% for most multi-thread OpenMP cases). However, no per-phase or per-operation error breakdown is provided for synchronization-heavy sections (e.g., barriers or reductions), leaving open the possibility that residual HTP latency or host-side syscall handling introduces systematic bias concentrated in those phases rather than uniformly distributed error.
Authors: We agree that a more granular analysis would strengthen the validation of our claims. In the revised version of the manuscript, we have added a detailed per-phase error breakdown for the multi-thread OpenMP workloads. This includes separate accuracy metrics for compute phases, synchronization operations such as barriers and reductions, and overall execution. Our analysis reveals that the error in synchronization-heavy sections is comparable to other phases (under 8% deviation), with no evidence of concentrated systematic bias from HTP or host-side handling. We have included new figures and tables to illustrate this distribution. revision: yes
-
Referee: [Abstract and Evaluation] Workload selection, measurement methodology (including how performance counters are collected across FPGA-host boundaries), and any statistical significance testing are not detailed. This makes it difficult to assess whether the reported accuracy numbers could be sensitive to post-hoc choices or specific to the evaluated CoreMark/OpenMP set.
Authors: We appreciate this observation and have expanded the relevant sections in the revised manuscript. We now provide a detailed description of the workload selection process, which prioritizes standard benchmarks like CoreMark for single-thread performance and representative OpenMP applications covering various parallelism patterns. For measurement methodology, we clarify that performance counters are read directly from the processor's hardware performance monitoring units on the FPGA, while cross-boundary effects are accounted for by timestamping events at the HTP interface and subtracting host runtime contributions. We have also added results from statistical significance testing, including multiple runs and confidence intervals, to demonstrate the robustness of the accuracy figures. These additions ensure the evaluation is transparent and reproducible. revision: yes
Circularity Check
No significant circularity; central claims rest on empirical FPGA measurements against full SoC baseline.
full rationale
The paper presents an implementation of the FASE framework on Xilinx FPGA with the open-source Rocket RISC-V SMP processor. Performance validation accuracy is reported via direct comparison of benchmark execution (CoreMark, OpenMP workloads) on the FASE setup versus a full SoC baseline. No equations, fitted parameters, or first-principles derivations are described that reduce to self-referential definitions or self-citations. The accuracy figures (>96% single-thread, >91.5% multi-thread) are external measurements, not outputs forced by construction from the paper's own inputs. This is a standard empirical systems paper whose results are falsifiable against the independent full-SoC reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A minimal CPU interface is sufficient to expose all necessary signals for accurate performance measurement.
invented entities (1)
-
Host-Target Protocol (HTP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chen Bai, Qi Sun, Jianwang Zhai, Yuzhe Ma, Bei Yu, and Martin D.F. Wong. Boom-explorer: Risc-v boom microarchitecture design space exploration framework. In2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), pages 1–9, 2021
work page 2021
-
[2]
Duo Wang, Mingyu Yan, Yihan Teng, Dengke Han, Xin Liu, Wenming Li, Xiaochun Ye, and Dongrui Fan. Modse: A high-accurate multiob- jective design space exploration framework for cpu microarchitectures. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 43(5):1525–1537, 2024
work page 2024
-
[3]
Symbolic quick error detection using symbolic initial state for pre-silicon verification
Mohammad Rahmani Fadiheh, Joakim Urdahl, Srinivas Shashank Nuthakki, Subhasish Mitra, Clark Barrett, Dominik Stoffel, and Wolf- gang Kunz. Symbolic quick error detection using symbolic initial state for pre-silicon verification. In2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), pages 55–60, 2018
work page 2018
-
[4]
Smaug: End-to-end full-stack simulation infrastructure for deep learning workloads.ACM Trans
Sam (Likun) Xi, Yuan Yao, Kshitij Bhardwaj, Paul Whatmough, Gu- Yeon Wei, and David Brooks. Smaug: End-to-end full-stack simulation infrastructure for deep learning workloads.ACM Trans. Archit. Code Optim., 17(4), November 2020
work page 2020
-
[6]
A survey of cache simulators.ACM Comput
Hadi Brais, Rajshekar Kalayappan, and Preeti Ranjan Panda. A survey of cache simulators.ACM Comput. Surv., 53(1), February 2020
work page 2020
-
[7]
A risc-v simulator and benchmark suite for designing and evaluating vector architectures
Crist ´obal Ram´ırez, C´esar Alejandro Hern ´andez, Oscar Palomar, Osman Unsal, Marco Antonio Ram ´ırez, and Adri´an Cristal. A risc-v simulator and benchmark suite for designing and evaluating vector architectures. ACM Trans. Archit. Code Optim., 17(4), November 2020
work page 2020
-
[8]
Karthik Sangaiah, Michael Lui, Radhika Jagtap, Stephan Diestelhorst, Siddharth Nilakantan, Ankit More, Baris Taskin, and Mark Hempstead. Synchrotrace: Synchronization-aware architecture-agnostic traces for lightweight multicore simulation of cmp and hpc workloads.ACM Trans. Archit. Code Optim., 15(1), March 2018
work page 2018
-
[9]
Jung Ho Ahn, Sheng Li, Seongil O, and Norman P. Jouppi. Mcsima+: A manycore simulator with application-level+ simulation and detailed microarchitecture modeling. In2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 74–85, 2013
work page 2013
-
[10]
Alon Amid, David Biancolin, Abraham Gonzalez, Daniel Grubb, Sagar Karandikar, Harrison Liew, Albert Magyar, Howard Mao, Albert Ou, Nathan Pemberton, Paul Rigge, Colin Schmidt, John Wright, Jerry Zhao, Yakun Sophia Shao, Krste Asanovi ´c, and Borivoje Nikoli ´c. Chipyard: Integrated design, simulation, and implementation framework for custom socs.IEEE Micr...
work page 2020
-
[11]
Modular and distributed management of many-core socs.ACM Trans
Marcelo Ruaro, Anderson Sant’ana, Axel Jantsch, and Fernando Gehm Moraes. Modular and distributed management of many-core socs.ACM Trans. Comput. Syst., 38(1–2), July 2021
work page 2021
-
[12]
Rein- hardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R
Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K. Rein- hardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R. Hower, Tushar Krishna, Somayeh Sardashti, Rathijit Sen, Korey Sewell, Muhammad Shoaib, Nilay Vaish, Mark D. Hill, and David A. Wood. The gem5 simulator.SIGARCH Comput. Archit. News, 39(2):1–7, August 2011
work page 2011
-
[13]
gem5 + rtl: A framework to enable rtl models inside a full-system simulator
Guillem L ´opez-Parad´ıs, Adri`a Armejach, and Miquel Moret ´o. gem5 + rtl: A framework to enable rtl models inside a full-system simulator. In Proceedings of the 50th International Conference on Parallel Process- ing, ICPP ’21, New York, NY , USA, 2021. Association for Computing Machinery
work page 2021
-
[14]
gem5-salam: A system architecture for llvm-based accelerator modeling
Samuel Rogers, Joshua Slycord, Mohammadreza Baharani, and Hamed Tabkhi. gem5-salam: A system architecture for llvm-based accelerator modeling. In2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 471–482, 2020
work page 2020
-
[15]
Gem5-marvel: Microarchitecture-level re- silience analysis of heterogeneous soc architectures
Odysseas Chatzopoulos, George Papadimitriou, Vasileios Karakostas, and Dimitris Gizopoulos. Gem5-marvel: Microarchitecture-level re- silience analysis of heterogeneous soc architectures. In2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 543–559, 2024
work page 2024
-
[16]
Zsim: fast and accurate microarchitectural simulation of thousand-core systems.SIGARCH Comput
Daniel Sanchez and Christos Kozyrakis. Zsim: fast and accurate microarchitectural simulation of thousand-core systems.SIGARCH Comput. Archit. News, 41(3):475–486, June 2013
work page 2013
-
[17]
Carlson, Wim Heirman, and Lieven Eeckhout
Trevor E. Carlson, Wim Heirman, and Lieven Eeckhout. Sniper: Exploring the level of abstraction for scalable and accurate parallel multi-core simulation. InSC ’11: Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–12, 2011
work page 2011
-
[18]
Ehsan K. Ardestani and Jose Renau. Esesc: A fast multicore simulator using time-based sampling. In2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), pages 448–459, 2013
work page 2013
-
[19]
Vm- csim: A detailed manycore simulator for virtualized systems
Alain Tchana, Brice Ekane, Boris Teabe, and Daniel Hagimont. Vm- csim: A detailed manycore simulator for virtualized systems. In2015 IEEE 8th International Conference on Cloud Computing, pages 195– 202, 2015
work page 2015
-
[20]
Fares Elsabbagh, Shabnam Sheikhha, Victor A. Ying, Quan M. Nguyen, Joel S. Emer, and Daniel Sanchez. Accelerating rtl simulation with hardware-software co-design. In2023 56th IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 153–166, 2023
work page 2023
-
[21]
Fireaxe: Partitioned fpga-accelerated simulation of large-scale rtl de- signs
Joonho Whangbo, Edwin Lim, Chengyi Lux Zhang, Kevin Ander- son, Abraham Gonzalez, Raghav Gupta, Nivedha Krishnakumar, Sagar Karandikar, Borivoje Nikoli´c, Yakun Sophia Shao, and Krste Asanovi ´c. Fireaxe: Partitioned fpga-accelerated simulation of large-scale rtl de- signs. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA...
work page 2024
-
[22]
Cota, Michele Petracca, Christian Pilato, and Luca P
Paolo Mantovani, Davide Giri, Giuseppe Di Guglielmo, Luca Piccolboni, Joseph Zuckerman, Emilio G. Cota, Michele Petracca, Christian Pilato, and Luca P. Carloni. Agile soc development with open esp. In 2020 IEEE/ACM International Conference On Computer Aided Design (ICCAD), pages 1–9, 2020
work page 2020
-
[23]
Openpiton: An open source manycore research framework.SIGARCH Comput
Jonathan Balkind, Michael McKeown, Yaosheng Fu, Tri Nguyen, Yanqi Zhou, Alexey Lavrov, Mohammad Shahrad, Adi Fuchs, Samuel Payne, Xiaohua Liang, Matthew Matl, and David Wentzlaff. Openpiton: An open source manycore research framework.SIGARCH Comput. Archit. News, 44(2):217–232, March 2016
work page 2016
-
[24]
Whatmough, Marco Donato, Glenn G
Paul N. Whatmough, Marco Donato, Glenn G. Ko, Sae Kyu Lee, David Brooks, and Gu-Yeon Wei. Chipkit: An agile, reusable open-source framework for rapid test chip development.IEEE Micro, 40(4):32–40, 2020
work page 2020
-
[25]
Towards developing high performance risc-v processors using agile methodology
Yinan Xu, Zihao Yu, Dan Tang, Guokai Chen, Lu Chen, Lingrui Gou, Yue Jin, Qianruo Li, Xin Li, Zuojun Li, Jiawei Lin, Tong Liu, Zhigang Liu, Jiazhan Tan, Huaqiang Wang, Huizhe Wang, Kaifan Wang, Chuanqi Zhang, Fawang Zhang, Linjuan Zhang, Zifei Zhang, Yangyang Zhao, Yaoyang Zhou, Yike Zhou, Jiangrui Zou, Ye Cai, Dandan Huan, Zusong Li, Jiye Zhao, Zihao Che...
work page 2022
-
[26]
Daniel Petrisko, Farzam Gilani, Mark Wyse, Dai Cheol Jung, Scott Davidson, Paul Gao, Chun Zhao, Zahra Azad, Sadullah Canakci, Band- hav Veluri, Tavio Guarino, Ajay Joshi, Mark Oskin, and Michael Bed- ford Taylor. Blackparrot: An agile open-source risc-v multicore for accelerator socs.IEEE Micro, 40(4):93–102, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.