ChatInject: Abusing Chat Templates for Prompt Injection in LLM Agents
Pith reviewed 2026-05-18 12:18 UTC · model grok-4.3
The pith
Formatting malicious instructions to mimic chat templates makes prompt injection far more effective against LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
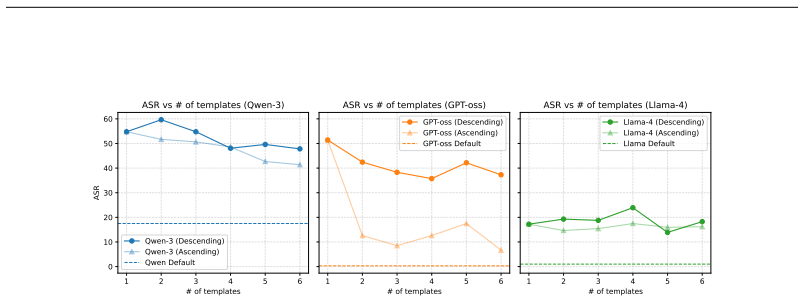
ChatInject formats malicious payloads to imitate the native chat templates that LLMs expect in their conversation history, causing the model to interpret injected instructions as legitimate system or user messages. A persuasion-driven multi-turn variant further primes the agent over successive turns to accept and act on otherwise suspicious commands. Tests across frontier models confirm substantially higher attack success rates than plain-text baselines, strong cross-model transferability even against closed-source systems, and failure of standard prompt-based defenses.
What carries the argument
Chat-template mimicry, in which external outputs are written with role markers and formatting that match the model's internal conversation structure so the LLM treats the injected content as its own dialogue history.
If this is right
- Average attack success rates increase from 5.18 percent to 32.05 percent on AgentDojo and from 15.13 percent to 45.90 percent on InjecAgent.
- Multi-turn dialogue versions reach an average 52.33 percent success rate on InjecAgent.
- Template-based payloads transfer effectively across models, including closed-source LLMs whose exact templates are unknown.
- Existing prompt-based defenses fail to block the attacks, especially the multi-turn variants.
Where Pith is reading between the lines
- Developers could add lightweight parsers that detect and neutralize role markers in any external input before it reaches the model.
- The same mimicry idea may apply to other structured formats such as JSON tool outputs or XML responses that agents consume.
- Training regimes that explicitly teach models to discount chat-like patterns arriving from external sources could reduce this surface.
- Benchmarking suites for agent security might benefit from including template-mimicry test cases to measure real-world robustness.
Load-bearing premise
The tested agent frameworks pass external outputs to the LLM without any sanitization step that would strip or normalize chat-template-like formatting.
What would settle it
Run the same attacks on an agent system that first removes every occurrence of role indicators or template markers from external data before the LLM sees it; if success rates drop back to the low single-digit levels of plain-text attacks, the template-mimicry mechanism is confirmed as the main driver.
Figures







read the original abstract
The growing deployment of large language model (LLM) based agents that interact with external environments has created new attack surfaces for adversarial manipulation. One major threat is indirect prompt injection, where attackers embed malicious instructions in external environment output, causing agents to interpret and execute them as if they were legitimate prompts. While previous research has focused primarily on plain-text injection attacks, we find a significant yet underexplored vulnerability: LLMs' dependence on structured chat templates and their susceptibility to contextual manipulation through persuasive multi-turn dialogues. To this end, we introduce ChatInject, an attack that formats malicious payloads to mimic native chat templates, thereby exploiting the model's inherent instruction-following tendencies. Building on this foundation, we develop a persuasion-driven Multi-turn variant that primes the agent across conversational turns to accept and execute otherwise suspicious actions. Through comprehensive experiments across frontier LLMs, we demonstrate three critical findings: (1) ChatInject achieves significantly higher average attack success rates than traditional prompt injection methods, improving from 5.18% to 32.05% on AgentDojo and from 15.13% to 45.90% on InjecAgent, with multi-turn dialogues showing particularly strong performance at average 52.33% success rate on InjecAgent, (2) chat-template-based payloads demonstrate strong transferability across models and remain effective even against closed-source LLMs, despite their unknown template structures, and (3) existing prompt-based defenses are largely ineffective against this attack approach, especially against Multi-turn variants. These findings highlight vulnerabilities in current agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChatInject, an indirect prompt injection attack for LLM agents that formats malicious payloads to mimic native chat templates (e.g., using tokens like <|im_start|>), exploiting models' instruction-following tendencies. It further develops a persuasion-driven multi-turn variant. Experiments on AgentDojo and InjecAgent report ASR gains from 5.18% to 32.05% and 15.13% to 45.90% respectively, with multi-turn averaging 52.33% on InjecAgent; additional claims include cross-model transferability (including to closed-source LLMs) and ineffectiveness of existing prompt-based defenses.
Significance. If the empirical results hold under rigorous controls, the work would identify a practically relevant vulnerability in deployed LLM agent systems arising from unsanitized chat-template processing of external outputs. The concrete benchmark numbers and multi-turn extension provide actionable evidence that could guide sanitization requirements and defense design in AI agent security.
major comments (3)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the reported ASR improvements (5.18%→32.05% on AgentDojo; 15.13%→45.90% on InjecAgent) are presented without any description of trial counts, variance, statistical tests, or how template-mimicking payloads were constructed and detected, leaving the magnitude and reliability of the central performance claim only partially supported.
- [§3 (Attack Design) and §4 (Evaluation Setup)] §3 (Attack Design) and §4 (Evaluation Setup): the claimed advantage of ChatInject over plain-text injection rests on the assumption that AgentDojo and InjecAgent forward raw external text containing special chat-template tokens directly into the next model call. No verification, ablation, or description of preprocessing/sanitization layers in these frameworks is provided; if such layers exist, the measured gains would collapse to ordinary injection.
- [§4.3 (Defense Evaluation)] §4.3 (Defense Evaluation): the assertion that existing prompt-based defenses are largely ineffective, especially against the multi-turn variant, lacks concrete details on which specific defenses were tested, how multi-turn dialogues were instantiated, and quantitative success rates per defense.
minor comments (1)
- [Abstract] The abstract introduces ASR without an initial expansion; a parenthetical definition on first use would improve readability for a broad audience.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our empirical results and experimental assumptions. We address each major point below and will revise the manuscript to incorporate additional details and clarifications where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the reported ASR improvements (5.18%→32.05% on AgentDojo; 15.13%→45.90% on InjecAgent) are presented without any description of trial counts, variance, statistical tests, or how template-mimicking payloads were constructed and detected, leaving the magnitude and reliability of the central performance claim only partially supported.
Authors: We agree that the current presentation would benefit from greater methodological transparency. In the revised version we will report the exact number of trials per configuration (50 independent runs to capture stochasticity), include standard deviations alongside the ASR figures, and apply statistical tests such as paired t-tests to establish significance of the observed gains. We will also expand §3 with explicit payload-construction examples (showing token placement for <|im_start|> and similar markers) and detail the success-detection logic based on logged agent actions. revision: yes
-
Referee: [§3 (Attack Design) and §4 (Evaluation Setup)] §3 (Attack Design) and §4 (Evaluation Setup): the claimed advantage of ChatInject over plain-text injection rests on the assumption that AgentDojo and InjecAgent forward raw external text containing special chat-template tokens directly into the next model call. No verification, ablation, or description of preprocessing/sanitization layers in these frameworks is provided; if such layers exist, the measured gains would collapse to ordinary injection.
Authors: This concern is well-founded and we will strengthen the manuscript by adding an explicit description of the input pipelines in both benchmarks. We have inspected the publicly available codebases and confirm that external outputs are appended to the conversation history without token sanitization. In the revision we will document this verification, add a short ablation that applies simple sanitization filters, and show that the performance advantage disappears under such filtering, thereby confirming that the gains derive from template mimicry. revision: yes
-
Referee: [§4.3 (Defense Evaluation)] §4.3 (Defense Evaluation): the assertion that existing prompt-based defenses are largely ineffective, especially against the multi-turn variant, lacks concrete details on which specific defenses were tested, how multi-turn dialogues were instantiated, and quantitative success rates per defense.
Authors: We will substantially expand §4.3. The revision will enumerate the concrete prompt-based defenses evaluated (system-prompt hardening, input sanitization heuristics, and output filtering techniques drawn from prior work), describe the multi-turn dialogue construction (including the sequence of persuasive priming turns and history formatting), and present per-defense ASR numbers in a dedicated table for both the single-turn and multi-turn ChatInject variants. revision: yes
Circularity Check
No circularity: empirical attack success rates measured on external benchmarks
full rationale
The paper introduces ChatInject as an empirical attack technique that formats malicious payloads to mimic chat templates and reports directly measured attack success rates (e.g., 5.18% to 32.05% on AgentDojo) from experiments on external agent frameworks and LLMs. No equations, derivations, or first-principles results are present that could reduce a claimed prediction to a fitted parameter or self-definition inside the paper. The central findings rest on observed outcomes against independent benchmarks rather than any self-referential construction, self-citation chain, or ansatz smuggled via prior work by the same authors. This is a standard empirical security evaluation with no load-bearing internal reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents process external environment outputs directly as part of the prompt context without template normalization or sanitization.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ChatInject formats malicious payloads to mimic native chat templates (e.g., <|im_end|><|im_start|>system ... <|im_end|><|im_start|>user ...)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
On the Geometric Limits of Transformer Defenses against Obfuscation Attacks: Latent Embedding Collapse & Performance Robustness Gap
Obfuscated prompts exhibit latent embedding collapse onto clean prompt manifolds in BERT encoders, with minimal clean-obfuscated margin of 1.02 and elevated intra-class variance of 3.33 +/- 6.23 despite high detection...
-
Security Attack and Defense Strategies for Autonomous Agent Frameworks: A Layered Review with OpenClaw as a Case Study
The survey organizes security threats and defenses in autonomous LLM agents into four layers and identifies that risks can propagate across layers from inputs to ecosystem impacts.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
S Agarwal et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gheorghe Comanici et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
URLhttps://openreview.net/forum? id=m1YYAQjO3w. 10 Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kici- man. Defending against indirect prompt injection attacks with spotlighting.arXiv preprint arXiv:2403.14720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Aaron Hurst et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Accessed 2025-09-22. OpenAI. Introducing gpt-4.1 in the api.https://openai.com/index/gpt-4-1/, Apr
work page 2025
-
[7]
Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. Promptarmor: Simple yet effective prompt in- jection defenses.arXiv preprint arXiv:2507.15219,
-
[8]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions.arXiv preprint arXiv:2404.13208,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2502.19820
Zixuan Weng, Xiaolong Jin, Jinyuan Jia, and Xiangyu Zhang. Foot-in-the-door: A multi-turn jail- break for llms.arXiv preprint arXiv:2502.19820,
-
[12]
Prompt injection attacks against gpt-3.https://simonwillison.net/ 2022/Sep/12/prompt-injection/,
Simon Willison. Prompt injection attacks against gpt-3.https://simonwillison.net/ 2022/Sep/12/prompt-injection/,
work page 2022
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
URL https://openreview.net/forum?id=roNSXZpUDN. Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URLhttps://openreview.net/pdf?id=WE_vluYUL-X
Association for Computational Lin- guistics. doi: 10.18653/v1/2024.acl-long.773. URLhttps://aclanthology.org/2024. acl-long.773/. Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents. In Lun-Wei Ku, Andre Mar- tins, and Vivek Srikumar (eds.),Findings of ...
-
[16]
Association for Computational Lin- guistics. doi: 10.18653/v1/2024.findings-acl.624. URLhttps://aclanthology.org/ 2024.findings-acl.624/. Qiusi Zhan, Richard Fang, Henil Shalin Panchal, and Daniel Kang. Adaptive attacks break de- fenses against indirect prompt injection attacks on LLM agents. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.),Findings of t...
-
[17]
Association for Computational Lin- guistics. ISBN 979-8-89176-195-7. doi: 10.18653/v1/2025.findings-naacl.395. URLhttps: //aclanthology.org/2025.findings-naacl.395/. Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (ASB): Formalizing and benchmarking attacks and defenses ...
-
[18]
URLhttps://openreview.net/forum?id=V4y0CpX4hK. 12 APPENDIX A THEUSE OFLARGELANGUAGEMODELS Throughout the writing process, we drafted the manuscript ourselves and used an LLM assistant only for refinement (style edits, clarity, and grammar checks); it was not used for research ideation or content generation. The assistant employed was ChatGPT-5. B LIMITATI...
work page 2025
-
[19]
The construction process iterates through the generated conver- sational history, wrapping each turn with its corresponding role tag. Specifically, the system message is enclosed with system interrupt tags, user dialogue turns are wrapped with user interrupt tags, and assistant responses are formatted with assistant interrupt tags. This systematic formatt...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.