LayerScope: Predictive Cross-Layer Scheduling for Efficient Multi-Batch MoE Inference on Legacy Servers
Pith reviewed 2026-05-18 12:34 UTC · model grok-4.3
The pith
PreScope uses a learnable layer-aware predictor and cross-layer scheduling to deliver 141% higher throughput for MoE models on commodity servers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PreScope is a prediction-driven expert scheduling system that addresses inaccurate activation prediction, PCIe bandwidth competition, and cross-device scheduling complexity through three components: the Learnable Layer-Aware Predictor (LLaPor) that captures layer-specific expert activation patterns, Prefetch-Aware Cross-Layer Scheduling (PreSched) that generates globally optimal plans, and Asynchronous I/O Optimizer (AsyncIO) that decouples I/O from computation, yielding 141% higher throughput and 74.6% lower latency than state-of-the-art solutions.
What carries the argument
The Learnable Layer-Aware Predictor (LLaPor) that captures layer-specific expert activation patterns to drive prefetch and scheduling decisions.
If this is right
- Large MoE models become practical to serve on servers that lack high-capacity GPU memory by moving most weights to CPU and moving only needed experts over PCIe.
- Globally optimal prefetch plans across layers reduce the total data movement cost compared with per-layer greedy decisions.
- Decoupling I/O from computation through asynchronous operations removes waiting bubbles and raises overall GPU utilization during inference.
Where Pith is reading between the lines
- The same prediction-plus-prefetch pattern could be tested on other memory-bound transformer variants that use conditional computation.
- On hardware with faster interconnects the relative benefit of accurate prediction might shrink, which could be checked by repeating the measurements on newer servers.
- Activation patterns may shift after continued fine-tuning, so periodic retraining of the predictor would likely be needed to maintain the reported gains.
Load-bearing premise
The Learnable Layer-Aware Predictor can capture layer-specific expert activation patterns with enough accuracy that the resulting prefetch and scheduling decisions produce net gains rather than added overhead.
What would settle it
Run the same multi-batch MoE workload with the LLaPor predictor replaced by random or static expert selection and measure whether the reported throughput and latency gains disappear.
Figures
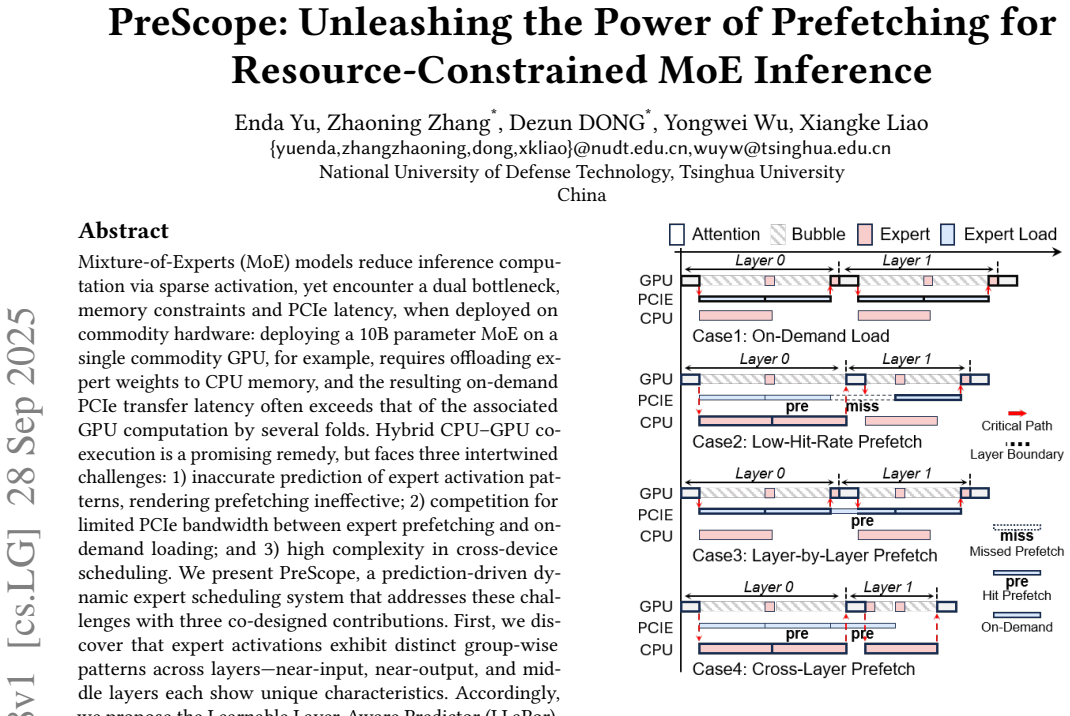








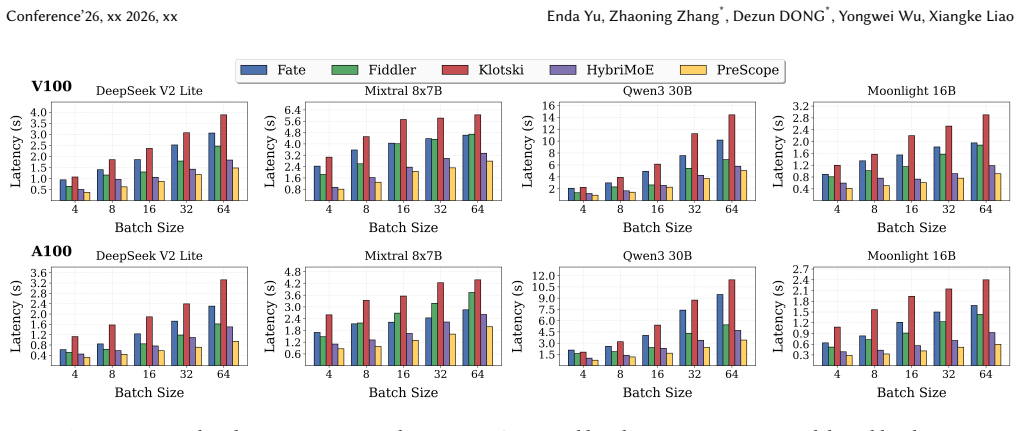

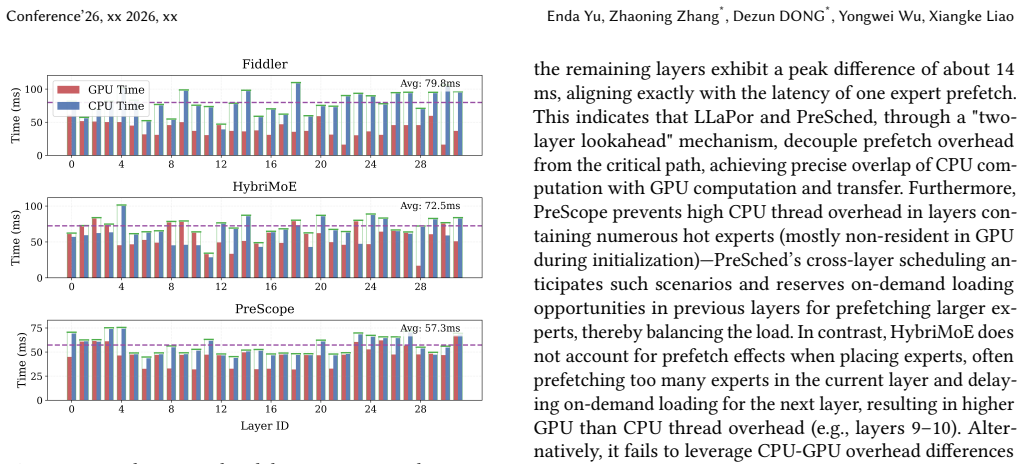
read the original abstract
Mixture-of-Experts (MoE) models face memory and PCIe latency bottlenecks when deployed on commodity hardware. Offloading expert weights to CPU memory results in PCIe transfer latency that exceeds GPU computation by several folds. We present PreScope, a prediction-driven expert scheduling system that addresses three key challenges: inaccurate activation prediction, PCIe bandwidth competition, and cross-device scheduling complexity. Our solution includes: 1) Learnable Layer-Aware Predictor (LLaPor) that captures layer-specific expert activation patterns; 2) Prefetch-Aware Cross-Layer Scheduling (PreSched) that generates globally optimal plans balancing prefetching costs and loading overhead; 3) Asynchronous I/O Optimizer (AsyncIO) that decouples I/O from computation, eliminating waiting bubbles. PreScope achieves 141% higher throughput and 74.6% lower latency than state-of-the-art solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PreScope (titled LayerScope), a prediction-driven scheduling system for Mixture-of-Experts inference on legacy servers. It offloads expert weights to CPU memory and mitigates PCIe latency via three components: the Learnable Layer-Aware Predictor (LLaPor) for layer-specific activation forecasting, Prefetch-Aware Cross-Layer Scheduling (PreSched) for globally optimal prefetch plans, and Asynchronous I/O Optimizer (AsyncIO) to eliminate I/O-compute bubbles. The central claim is a 141% throughput increase and 74.6% latency reduction versus state-of-the-art baselines.
Significance. If the performance numbers are shown to be robust and the predictive component is isolated as the source of gains, the work could meaningfully improve practical MoE deployment on commodity hardware by reducing PCIe pressure without requiring high-end interconnects.
major comments (2)
- [Evaluation] Evaluation section: the reported 141% throughput and 74.6% latency gains are presented only as end-to-end results; no ablation replaces LLaPor predictions with static or oracle-free scheduling while retaining PreSched and AsyncIO. Without this comparison it is impossible to confirm that the learned layer-specific forecasts, rather than AsyncIO alone, produce the claimed net PCIe savings after misprediction overhead.
- [Abstract] Abstract and results: large performance deltas are stated without describing the experimental setup (models, batch sizes, hardware, baseline implementations, or error bars), preventing assessment of whether the data support the headline claims.
minor comments (2)
- Resolve the naming inconsistency between the title (LayerScope) and the system name used throughout the text (PreScope).
- Add explicit references to any released code, models, or datasets to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These have helped us identify areas where the manuscript can be strengthened, particularly in evaluation rigor and experimental clarity. We provide point-by-point responses below and have made revisions to address the concerns.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 141% throughput and 74.6% latency gains are presented only as end-to-end results; no ablation replaces LLaPor predictions with static or oracle-free scheduling while retaining PreSched and AsyncIO. Without this comparison it is impossible to confirm that the learned layer-specific forecasts, rather than AsyncIO alone, produce the claimed net PCIe savings after misprediction overhead.
Authors: We agree that an ablation isolating the contribution of LLaPor is essential to substantiate that the gains arise from the layer-aware predictions rather than AsyncIO in isolation. In the revised manuscript we have added a dedicated ablation subsection in the Evaluation section. This compares the full PreScope system against a variant that substitutes LLaPor with a static (historical-average) scheduler while retaining PreSched and AsyncIO. The new results confirm that the predictive component delivers additional PCIe savings after misprediction overhead is accounted for, thereby strengthening the causal link between LLaPor and the reported end-to-end improvements. revision: yes
-
Referee: [Abstract] Abstract and results: large performance deltas are stated without describing the experimental setup (models, batch sizes, hardware, baseline implementations, or error bars), preventing assessment of whether the data support the headline claims.
Authors: We acknowledge the need for greater transparency in the abstract and results presentation. We have revised the abstract to concisely describe the evaluated models, batch-size range, legacy-server hardware configuration, baseline systems, and the reporting of error bars. Corresponding details and error-bar annotations have also been added to the results section and figures. These changes allow readers to directly assess the support for the headline performance numbers. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces PreScope as a system combining LLaPor for layer-specific expert activation prediction, PreSched for cross-layer prefetch scheduling, and AsyncIO for asynchronous I/O optimization, with performance claims (141% throughput, 74.6% latency improvement) presented as outcomes of empirical evaluation on MoE models. No equations, self-citations, or derivations are exhibited in the provided text that reduce any prediction, uniqueness claim, or result to a fitted input or prior self-referential definition by construction. The central claims rest on measured end-to-end gains rather than tautological redefinitions or load-bearing self-citations, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Efficient Mixture-of-Experts LLM Inference with Apple Silicon NPUs
NPUMoE accelerates MoE LLM inference on Apple Silicon NPUs via offline-calibrated static expert tiers, grouped execution, and load-aware graph residency, delivering 1.32x-5.55x lower latency and 1.81x-7.37x better ene...
Reference graph
Works this paper leans on
-
[1]
Anonymous. 2024. ShareGPT-V3-unfiltered-cleaned-split. Electronic dataset.https://huggingface.co/datasets/learnanything/sharegpt_v3_ unfiltered_cleaned_split
work page 2024
-
[2]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, et al . 2024. Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. In ACM ASPLOS. 929–947
work page 2024
-
[3]
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xiaoxuan Liu, Ying Sheng, Joseph E Gonzalez, Matei Zaharia, and Ion Stoica. 2025. Moe- lightning: High-throughput moe inference on memory-constrained gpus. InACM ASPLOS. 715–730
work page 2025
-
[4]
Hongtao Chen, Weiyu Xie, Boxin Zhang, Jingqi Tang, Jiahao Wang, Jianwei Dong, Shaoyuan Chen, Ziwei Yuan, Chen Lin, Chengyu Qiu, Yuening Zhu, Qingliang Ou, Jiaqi Liao, Xianglin Chen, Zhiyuan Ai, Yongwei Wu, and Mingxing Zhang. 2025. KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models. In ACM SOSP. 10–26
work page 2025
- [5]
- [6]
-
[7]
Hongchao Du, Shangyu Wu, Arina Kharlamova, Nan Guan, and Chun Jason Xue. 2025. FlexInfer: Breaking Memory Constraint via Flexible and Efficient Offloading for On-Device LLM Inference. In EuroMLSys. 56–65
work page 2025
-
[8]
Zhixu Du, Shiyu Li, Yuhao Wu, Xiangyu Jiang, Jingwei Sun, Qilin Zheng, Yongkai Wu, Ang Li, Hai Li, and Yiran Chen. 2024. Sida: Sparsity-inspired data-aware serving for efficient and scalable large mixture-of-experts models.MLSys6 (2024), 224–238
work page 2024
- [9]
- [10]
-
[11]
Zhiyuan Fang, Yuegui Huang, Zicong Hong, Yufeng Lyu, Wuhui Chen, Yue Yu, Fan Yu, and Zibin Zheng. 2025. Klotski: Efficient Mixture- of-Expert Inference via Expert-Aware Multi-Batch Pipeline. InACM ASPLOS. 574–588
work page 2025
-
[12]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch trans- formers: Scaling to trillion parameter models with simple and efficient sparsity.JMLR23, 120 (2022), 1–39
work page 2022
- [13]
- [14]
-
[15]
Vima Gupta, Kartik Sinha, Ada Gavrilovska, and Anand Padmanabha Iyer. 2024. Lynx: Enabling Efficient MoE Inference through Dynamic Batch-Aware Expert Selection. arXiv:2411.08982
work page internal anchor Pith review arXiv 2024
- [16]
-
[17]
Huanqi Hu, Bowen Xiao, Shixuan Sun, Jianian Yin, Zhexi Zhang, Xi- ang Luo, Chengquan Jiang, Weiqi Xu, Xiaoying Jia, Xin Liu, et al
-
[18]
LiquidGEMM: Hardware-Efficient W4A8 GEMM Kernel for High-Performance LLM Serving. arXiv:2509.01229
-
[19]
Haiyang Huang, Newsha Ardalani, Anna Sun, Liu Ke, Shruti Bhosale, Hsien-Hsin Lee, Carole-Jean Wu, and Benjamin Lee. 2024. Toward efficient inference for mixture of experts.NIPS37 (2024), 84033–84059
work page 2024
-
[20]
Ranggi Hwang, Jianyu Wei, Shijie Cao, Changho Hwang, Xiaohu Tang, Ting Cao, and Mao Yang. 2024. Pre-gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference. InIEEE ISCA. 1018–1031
work page 2024
-
[21]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al . 2024. Mixtral of experts. arXiv:2401.04088
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Zewen Jin, Shengnan Wang, Jiaan Zhu, Hongrui Zhan, Youhui Bai, Lin Zhang, Zhenyu Ming, and Cheng Li. 2025. BigMac: A Communication- Efficient Mixture-of-Experts Model Structure for Fast Training and Inference. InAAAI. 17689–17698
work page 2025
-
[23]
Keisuke Kamahori, Tian Tang, Yile Gu, Kan Zhu, and Baris Kasikci
-
[24]
Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture- of-Experts Models. InICLR. 56099–56115
-
[25]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[26]
Efficient memory management for large language model serving with pagedattention. InACM SOSP. 611–626
-
[27]
Xinlu Lai. 2024. The DPO Dataset for Chinese and English with emoji. https://huggingface.co/datasets/shareAI/DPO-zh-en-emoji
work page 2024
-
[28]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: Efficient generative inference of large language models with dynamic{KV}cache management. InOSDI. 155–172
work page 2024
-
[29]
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. 2023. Accelerating distributed MoE training and inference with lina. In USENIX ATC 23. 945–959
work page 2023
-
[30]
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. 2024. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv:2405.04434
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning.NIPS36 (2023), 34892–34916
work page 2023
-
[32]
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, et al. 2025. Muon is Scalable for LLM Training. arXiv:2502.16982
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
Zhiwen Mo, Lei Wang, Jianyu Wei, Zhichen Zeng, Shijie Cao, Lingxiao Ma, Naifeng Jing, Ting Cao, Jilong Xue, Fan Yang, et al . 2025. LUT Tensor Core: A Software-Hardware Co-Design for LUT-Based Low-Bit LLM Inference. InISCA. 514–528
work page 2025
-
[35]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al . 2024. GPT-4 Technical Report. arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Xiurui Pan, Endian Li, Qiao Li, Shengwen Liang, Yizhou Shan, Ke Zhou, Yingwei Luo, Xiaolin Wang, and Jie Zhang. 2025. InstAttention: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference. InIEEE HPCA. 1510–1525
work page 2025
-
[37]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yux- iong He. 2022. Deepspeed-moe: Advancing mixture-of-experts infer- ence and training to power next-generation ai scale. InICML. 18332– 18346
work page 2022
-
[38]
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. 2021. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. InACM SC. 1–14
work page 2021
-
[39]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ra- mani, and Tri Dao. 2024. Flashattention-3: Fast and accurate attention Conference’26, xx 2026, xx Enda Yu, Zhaoning Zhang *, Dezun DONG*, Yongwei Wu, Xiangke Liao with asynchrony and low-precision.NIPS37 (2024), 68658–68685
work page 2024
-
[40]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang
-
[41]
Flexgen: High-throughput generative inference of large language models with a single gpu. InICML. 31094–31116
- [42]
-
[43]
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. 2024. PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU. In ACM SOSP. 590–606
work page 2024
-
[44]
Ruslan Svirschevski, Avner May, Zhuoming Chen, Beidi Chen, Zhihao Jia, and Max Ryabinin. 2024. Specexec: Massively parallel speculative decoding for interactive llm inference on consumer devices.NIPS37 (2024), 16342–16368
work page 2024
- [45]
- [46]
-
[47]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Yiding Wang, Kai Chen, Haisheng Tan, and Kun Guo. 2023. Tabi: An efficient multi-level inference system for large language models. In EuroSys. 233–248
work page 2023
-
[49]
Yuanxin Wei, Jiangsu Du, Jiazhi Jiang, Xiao Shi, Xianwei Zhang, Dan Huang, Nong Xiao, and Yutong Lu. 2024. APTMoE: Affinity-Aware Pipeline Tuning for MoE Models on Bandwidth-Constrained GPU Nodes. InIEEE SC. 1–14
work page 2024
-
[50]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al . 2019. Huggingface’s transformers: State-of-the-art natural language processing. arXiv:1910.03771
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[51]
Daliang Xu, Wangsong Yin, Hao Zhang, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, and Xuanzhe Liu. 2025. EdgeLLM: Fast On-Device LLM Inference With Speculative Decoding.IEEE TMC24, 4 (2025), 3256–3273
work page 2025
- [52]
-
[53]
Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchun- shu Zhou, and Yang You. 2024. OpenMoE: an early effort on open mixture-of-experts language models. InICML. 55625–55655
work page 2024
- [54]
-
[55]
Jinghan Yao, Quentin Anthony, Aamir Shafi, Hari Subramoni, and Dhabaleswar K DK Panda. 2024. Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference. InIEEE IPDPS. 915–925
work page 2024
- [56]
-
[57]
Libo Zhang, Zhaoning Zhang, Baizhou Xu, Songzhu Mei, and Dong- sheng Li. 2025. Dovetail: A cpu/gpu heterogeneous speculative decod- ing for llm inference. InEMNLP. 1–13
work page 2025
-
[58]
Yujie Zhang, Shivam Aggarwal, and Tulika Mitra. 2025. DAOP: Data- Aware Offloading and Predictive Pre-Calculation for Efficient MoE Inference. InIEEE DATE. 1–7
work page 2025
-
[59]
Xuanlei Zhao, Bin Jia, Haotian Zhou, Ziming Liu, Shenggan Cheng, and Yang You. 2024. Hetegen: Efficient heterogeneous parallel inference for large language models on resource-constrained devices.MLSys6 (2024), 162–172
work page 2024
-
[60]
Shuzhang Zhong, Ling Liang, Yuan Wang, Runsheng Wang, Ru Huang, and Meng Li. 2024. AdapMoE: Adaptive sensitivity-based expert gating and management for efficient moe inference. InIEEE ICCAD. 1–9
work page 2024
-
[61]
Shuzhang Zhong, Yanfan Sun, Ling Liang, Runsheng Wang, Ru Huang, and Meng Li. 2025. HybriMoE: Hybrid CPU-GPU Scheduling and Cache Management for Efficient MoE Inference. InDAC. 1–7
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.