KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Controls
Pith reviewed 2026-05-18 05:30 UTC · model grok-4.3
The pith
KORE injects new knowledge into multimodal models by structuring facts for adaptation and projecting adapters into the null space of prior activation covariances for retention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KORE is a synergistic method of knowledge-oriented augmentations and constraints. It automatically converts individual knowledge items into structured and comprehensive knowledge to ensure accurate adaptation. It stores previous knowledge in the covariance matrix of LMM linear-layer activations and initializes the adapter by projecting original weights into the matrix's null space, thereby defining a fine-tuning direction that minimizes interference with previous knowledge.
What carries the argument
The retention mechanism that encodes prior knowledge in the covariance matrix of linear-layer activations and initializes adapters via null-space projection of the original weights.
If this is right
- New knowledge items are learned more accurately because they are first expanded into structured, comprehensive forms rather than presented as isolated statements.
- Interference with existing knowledge is reduced because the adapter's initial direction is confined to the null space of the covariance matrix derived from prior activations.
- The same two-part procedure applies across different model sizes and architectures, as shown on 7B and 13B LLaVA variants and on Qwen2.5-VL-7B.
- Catastrophic forgetting is mitigated without requiring storage of raw previous data, since only the covariance matrix is retained.
Where Pith is reading between the lines
- The null-space projection could be recomputed periodically as more new knowledge is added, turning the method into an incremental continual-learning loop.
- The structured-knowledge conversion step might generalize to other modalities or to pure language models if the same automatic expansion process is applied.
- If the covariance matrix proves too coarse for certain layers, replacing it with a low-rank or attention-based summary could further reduce interference while keeping memory cost low.
Load-bearing premise
The covariance matrix of linear-layer activations on previous knowledge fully captures the directions that must be protected, and projecting the adapter initialization into its null space will not impair learning of genuinely new knowledge.
What would settle it
A controlled test in which the null-space projection is applied to an adapter and the model is then measured on both retention of old facts and acquisition of new facts; if new-knowledge accuracy drops below the non-projected baseline while retention improves only marginally, the claim would be falsified.
Figures












read the original abstract
Large Multimodal Models encode extensive factual knowledge in their pre-trained weights. However, its knowledge remains static and limited, unable to keep pace with real-world developments, which hinders continuous knowledge acquisition. Effective knowledge injection thus becomes critical, involving two goals: knowledge adaptation (injecting new knowledge) and knowledge retention (preserving old knowledge). Existing methods often struggle to learn new knowledge and suffer from catastrophic forgetting. To address this, we propose KORE, a synergistic method of KnOwledge-oRientEd augmentations and constraints for injecting new knowledge into large multimodal models while preserving old knowledge. Unlike general text or image data augmentation, KORE automatically converts individual knowledge items into structured and comprehensive knowledge to ensure that the model accurately learns new knowledge, enabling accurate adaptation. Meanwhile, KORE stores previous knowledge in the covariance matrix of LMM's linear layer activations and initializes the adapter by projecting the original weights into the matrix's null space, defining a fine-tuning direction that minimizes interference with previous knowledge, enabling powerful retention. Extensive experiments on various LMMs, including LLaVA-v1.5-7B, LLaVA-v1.5-13B, and Qwen2.5-VL-7B, show that KORE achieves superior new knowledge injection performance and effectively mitigates catastrophic forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KORE, a method for knowledge injection into large multimodal models that combines knowledge-oriented augmentations—automatically converting individual knowledge items into structured, comprehensive forms to improve adaptation—with a retention mechanism that computes the covariance matrix of linear-layer activations on previous knowledge and initializes adapters by projecting original weights into its null space to reduce interference. Experiments on LLaVA-v1.5-7B, LLaVA-v1.5-13B, and Qwen2.5-VL-7B are reported to show superior new-knowledge injection accuracy and effective mitigation of catastrophic forgetting relative to prior approaches.
Significance. If the empirical results and the underlying assumptions prove robust, KORE would offer a concrete control mechanism for balancing adaptation and retention during knowledge updates in LMMs, a capability with clear practical value for maintaining up-to-date factual knowledge in deployed multimodal systems.
major comments (1)
- [Abstract and retention mechanism section] Abstract and retention mechanism section: The central retention claim rests on the covariance matrix of activations (computed from previous knowledge) defining a null space into which adapter weights are projected. This construction is asserted to protect old knowledge while leaving sufficient capacity for new knowledge learned via the augmentations. However, the manuscript provides no analysis of the rank or dimensionality of the estimated null space, no verification that the finite-sample covariance captures all directions relevant to retention, and no targeted experiments examining cases where new knowledge directions overlap with the protected subspace. Without such evidence, the reported joint improvement in injection performance and forgetting mitigation cannot be confidently attributed to the projection rather than to other factors.
minor comments (2)
- [Abstract] The abstract states that KORE achieves 'superior' performance but supplies no numerical results, baselines, or error statistics, which reduces the immediate informativeness of the summary.
- Clarify the precise layers and data subsets used to construct the covariance matrix, as well as the rank of the resulting null space, in the method description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has helped clarify the presentation of our retention mechanism. We address the major comment below and have incorporated revisions to strengthen the supporting analysis.
read point-by-point responses
-
Referee: Abstract and retention mechanism section: The central retention claim rests on the covariance matrix of activations (computed from previous knowledge) defining a null space into which adapter weights are projected. This construction is asserted to protect old knowledge while leaving sufficient capacity for new knowledge learned via the augmentations. However, the manuscript provides no analysis of the rank or dimensionality of the estimated null space, no verification that the finite-sample covariance captures all directions relevant to retention, and no targeted experiments examining cases where new knowledge directions overlap with the protected subspace. Without such evidence, the reported joint improvement in injection performance and forgetting mitigation cannot be confidently attributed to the projection rather than to other factors.
Authors: We agree that the original manuscript would benefit from explicit analysis of the null-space properties. In the revised version we have added a dedicated subsection (now Section 4.3) that reports the rank and effective dimensionality of the covariance matrices computed on the previous-knowledge activation sets for each model and dataset. These matrices are consistently low-rank relative to the hidden dimension, confirming substantial null-space capacity remains available. For finite-sample coverage we include an empirical verification: we measure the fraction of variance explained by the top principal components and show that the retained directions align with performance on held-out old-knowledge queries. To directly address potential overlap, we added a controlled experiment that injects new knowledge items sharing semantic features with retained facts; results indicate that the null-space projection continues to reduce forgetting relative to unprojected adapters and prior baselines. These additions support attributing the observed gains to the projection step. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes KORE with two components: knowledge-oriented augmentations that convert individual items into structured knowledge for adaptation, and a retention mechanism that computes a covariance matrix from linear-layer activations on previous knowledge then projects adapter initialization into its null space. Neither component reduces by construction to the target new-knowledge data or to self-citations; the covariance is built from prior activations independent of the injection targets, and the reported gains on LLaVA-v1.5 and Qwen2.5-VL models are presented as empirical outcomes rather than algebraic identities or fitted-parameter renamings. The central claims therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Covariance matrix of linear-layer activations on previous knowledge captures all directions that must remain unchanged during new-knowledge fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
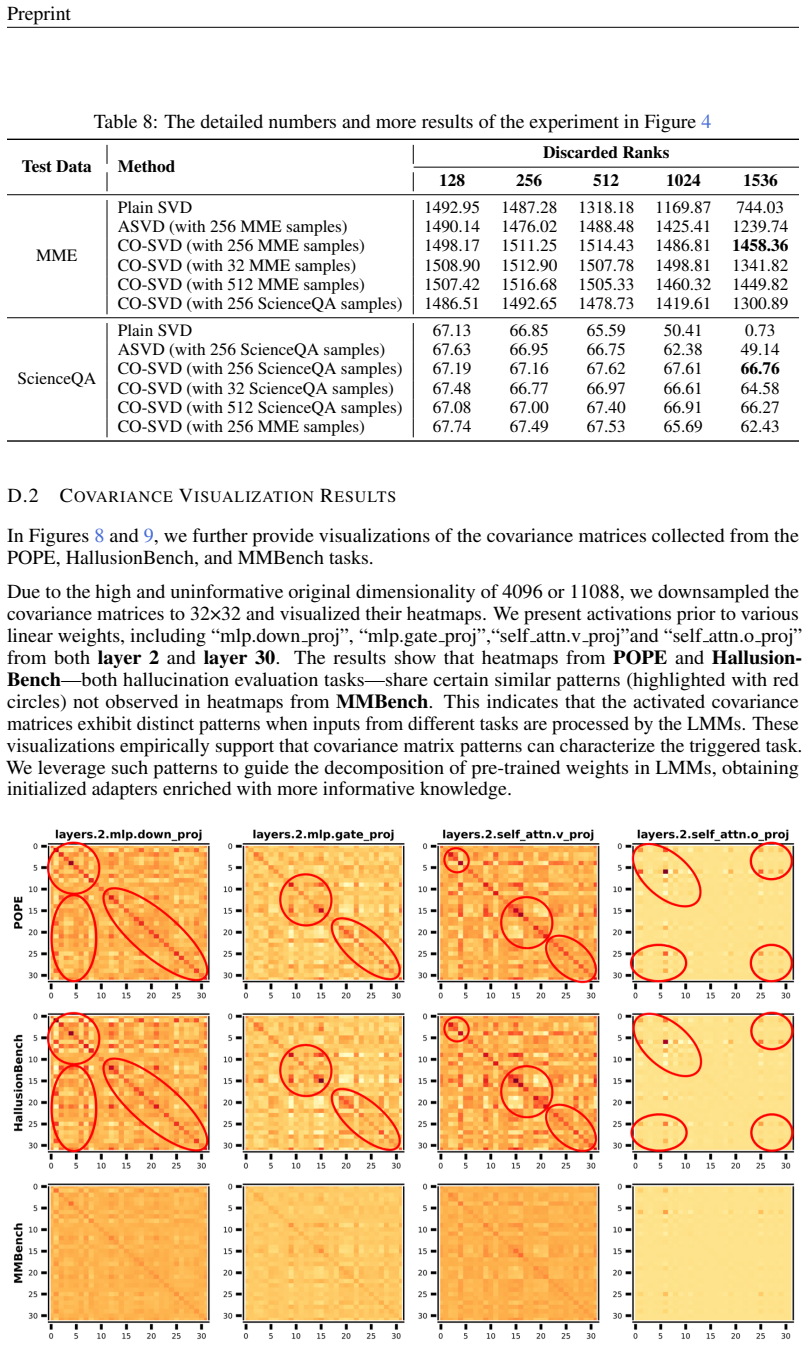
KORE stores previous knowledge in the covariance matrix C of LMM’s linear layer activations and initializes the adapter by projecting the original weights into the matrix’s null space
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We apply SVD to C=XX^T … null space … AC=0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
DecomPose: Disentangling Cross-Category Optimization Contention for Category-Level 6D Object Pose Estimation
DecomPose introduces difficulty-aware gradient decoupling and asymmetric branching to reduce cross-category optimization contention in category-level 6D pose estimation, reporting better results on REAL275, CAMERA25, ...
Reference graph
Works this paper leans on
-
[1]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
17 Arslan Chaudhry, Naeemullah Khan, Puneet Dokania, and Philip Torr. Continual learning in low-rank orthogonal subspaces.Advances in Neural Information Processing Systems, 33:9900–9911, 2020. 3 Jinpeng Chen, Runmin Cong, Yuzhi Zhao, Hongzheng Yang, Guangneng Hu, Horace Ho-Shing Ip, and Sam Kwong. SEFE: Superficial and essential forgetting eliminator for ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
LoRA: Low-rank adaptation of large language models
2 Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. 2, 3, 17 Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, and Philip S Yu. A survey on knowledge graphs: Representation, ac...
-
[3]
5, 6, 16 Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InThe Twelfth International Conference on Learning Representations, 2024. 6, 17 Tongxu Luo, Jiahe Lei, Fangyu Lei, Weihao ...
-
[4]
Evowiki: Evaluating llms on evolving knowledge
2 Wei Tang, Yixin Cao, Yang Deng, Jiahao Ying, Bo Wang, Yizhe Yang, Yuyue Zhao, Qi Zhang, Xuanjing Huang, Yu-Gang Jiang, and Yong Liao. Evowiki: Evaluating llms on evolving knowledge. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), 2025. 3 13 Preprint Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing R...
work page 2025
-
[5]
Orthogonal subspace learning for language model continual learning
5 Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. Orthogonal subspace learning for language model continual learning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 10658–10671, 2023. 3, 6, 17 Yujun Wang, Aniri, Jinhe Bi, Soeren Pirk, and Yunpu Ma. Ascd: Attention-steera...
-
[6]
MME(Fu et al., 2023) provides a holistic evaluation of LMMs’ perception and cognition across 14 tasks. Its key feature is the use of carefully crafted instruction-answer pairs, which facilitates a straightforward assessment without the need for specialized prompt engineering
work page 2023
-
[7]
MMBench(Liu et al., 2024c) is a cross-lingual benchmark for comprehensively evaluating LMMs. It features over 3,000 bilingual multiple-choice questions spanning 20 skill dimensions, from visual recognition to abstract reasoning
-
[8]
SEEDBench2 Plus(Li et al., 2024) benchmarks LMMs on interpreting text-rich visuals (e.g., charts, web layouts). It uses 2,300 multiple-choice questions to test reasoning capabilities where integrating textual and visual information is essential
work page 2024
-
[9]
OCRVQA(Mishra et al., 2019) is a benchmark for evaluating a model’s ability to answer questions by reading text within images. It focuses on tasks where textual information is essential, requiring tight integration of visual perception and OCR
work page 2019
-
[10]
ScienceQA(Lu et al., 2022) evaluates scientific reasoning through a large-scale multimodal benchmark; it features curriculum-based questions with diagrams and provides lectures and explanations for each question to encourage complex reasoning
work page 2022
-
[11]
MMMU(Yue et al., 2024) evaluates LMMs on college-level, multimodal questions requiring expert knowledge. The benchmark includes 11,500 questions from six disciplines, utilizing 30 image formats to test complex, subject-specific reasoning
work page 2024
-
[12]
MIA-Bench(Qian et al., 2024) is a targeted benchmark that measures how precisely LMMs can follow complex and multi-layered instructions. It consists of 400 distinct image-prompt combinations engineered to test a model’s ability to comply with detailed and nuanced directives
work page 2024
-
[13]
MMDU(Liu et al., 2025) evaluates LMMs in multi-image, multi-turn conversational scenarios. It specifically assesses a model’s capacity for contextual understanding, temporal reasoning, and maintaining coherence throughout extended interactions. 16 Preprint
work page 2025
-
[14]
MathVista(Lu et al., 2024) benchmarks the mathematical reasoning of foundation models in visual contexts. It aggregates 6,141 problems from 31 datasets, requiring detailed visual analysis and compositional logic for solution
work page 2024
-
[15]
MathVision(Wang et al., 2025a) provides a challenging dataset of 3,040 visually-presented problems from math competitions. Categorized into 16 mathematical areas and five difficulty tiers, it offers a structured evaluation of advanced reasoning in LMMs
-
[16]
HallusionBench(Guan et al., 2024) diagnoses hallucination and illusion in LMMs’ visual interpretations. It employs 346 images and 1,129 structured questions to quantitatively analyze the causes of inaccurate or inconsistent model responses
work page 2024
-
[17]
POPE(Li et al., 2023) evaluates object hallucination in LMMs—the tendency to describe non- existent objects. It uses a polling-based questioning strategy to reliably measure this tendency. B.3 EVALUATIONPROTOCOL To evaluate performance on open-domain question answering tasks, two key metrics are employed: Cover Exact Match (CEM)andF1-Score (F1). TheCEMmet...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.