MCP-Flow: Facilitating LLM Agents to Master Real-World, Diverse and Scaling MCP Tools
Pith reviewed 2026-05-18 03:14 UTC · model grok-4.3
The pith
An automated web-agent pipeline discovers MCP servers at scale to generate training data that improves LLM tool use and agent performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
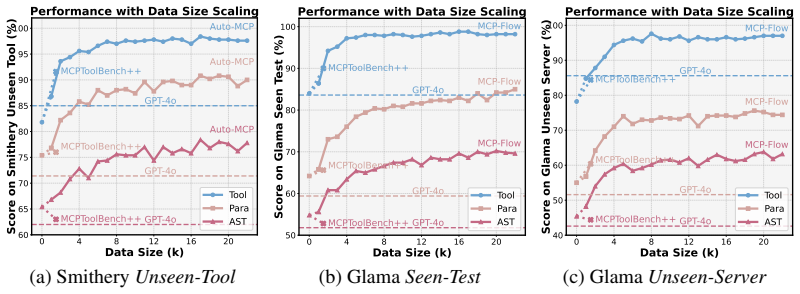
MCP-Flow is an automated web-agent-driven pipeline for large-scale server discovery, data synthesis, and model training. It collects and filters data from 1166 servers and 11536 tools to produce 68733 high-quality instruction-function call pairs and 6439 trajectories. This scale and diversity drive superior MCP tool selection, function-call generation, and enhanced agentic task performance.
What carries the argument
MCP-Flow, the automated web-agent-driven pipeline that performs server discovery, data synthesis, and model training at scale.
If this is right
- LLM agents achieve higher accuracy when choosing the correct MCP tool for a given instruction.
- Models produce more correct function calls during tool interactions.
- Agentic workflows that chain multiple tools show measurable gains in task completion.
- Training data can continue to grow automatically as new MCP servers appear.
Where Pith is reading between the lines
- The same automated collection method could be adapted to other tool or API ecosystems that lack large curated datasets.
- Greater exposure to diverse tools during training may improve generalization to entirely new MCP servers not seen in the data.
- Lowering the cost of dataset creation could let more research groups experiment with capable tool-using agents.
Load-bearing premise
The automated web-agent discovery and filtering steps produce high-quality, unbiased data that represents how MCP tools are actually used in practice.
What would settle it
Train separate LLMs on the MCP-Flow dataset versus prior small curated sets, then evaluate both on a fresh collection of real MCP servers and tasks; equal or worse performance on the larger dataset would falsify the claim of superiority.
Figures















read the original abstract
Large Language Models (LLMs) increasingly rely on external tools to perform complex, realistic tasks, yet their ability to utilize the rapidly expanding Model Contextual Protocol (MCP) ecosystem remains limited. Existing MCP research covers few servers, depends on costly manual curation, and lacks training support, hindering progress toward real-world deployment. To overcome these limitations, we introduce MCP-Flow, an automated web-agent-driven pipeline for large-scale server discovery, data synthesis, and model training. MCP-Flow collects and filters data from 1166 servers and 11536 tools, producing 68733 high-quality instruction-function call pairs and 6439 trajectories, far exceeding prior work in scale and diversity. Extensive experiments demonstrate MCP-Flow's effectiveness in driving superior MCP tool selection, function-call generation, and enhanced agentic task performance. MCP-Flow thus provides a scalable foundation for advancing LLM agents' proficiency in real-world MCP environments. MCP-Flow is publicly available at https://github.com/wwh0411/MCP-Flow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MCP-Flow, an automated web-agent-driven pipeline for large-scale MCP server discovery, data synthesis, and model training. It reports collecting data from 1166 servers and 11536 tools to produce 68733 high-quality instruction-function call pairs and 6439 trajectories, claiming this scale and diversity far exceeds prior work, with experiments demonstrating improved MCP tool selection, function-call generation, and agentic task performance.
Significance. If the central claims hold, the work offers a scalable, automated alternative to manual curation for training LLM agents on real-world MCP tools, addressing a clear gap in the field. The public release of code and data at the provided GitHub link is a concrete strength that supports reproducibility and further research.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The claims of superior performance in tool selection, function-call generation, and agentic tasks rest on experiments whose details are not visible, including specific baselines, statistical significance tests, error bars, or exact comparison protocols. This directly affects the soundness of the effectiveness claim.
- [Data Synthesis and Filtering] Data Synthesis and Filtering section: The assertion that the automated web-agent-driven process yields 'high-quality' pairs and trajectories lacks reported quality metrics (e.g., precision/recall of the filter), human validation, or bias audits. This assumption is load-bearing for the generalization and lack-of-selection-bias claims.
minor comments (1)
- [Abstract] The abstract states the data 'far exceeds prior work' without citing the specific prior datasets or providing quantitative scale comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the clarity and rigor of our claims regarding experimental details and data quality. We address each major comment below and have prepared revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The claims of superior performance in tool selection, function-call generation, and agentic tasks rest on experiments whose details are not visible, including specific baselines, statistical significance tests, error bars, or exact comparison protocols. This directly affects the soundness of the effectiveness claim.
Authors: We appreciate the referee's concern for experimental transparency. The Experiments section (Section 4) specifies the baselines (including GPT-4o, Claude-3.5-Sonnet, and prior MCP tool-use methods), evaluation protocols, and datasets used for tool selection, function calling, and agentic tasks. However, we acknowledge that error bars, statistical significance tests, and fully explicit comparison protocols were not uniformly reported across all tables and figures. In the revised manuscript, we have added standard deviation error bars over multiple runs, Wilcoxon signed-rank tests with p-values, and a dedicated paragraph clarifying the exact evaluation protocols. These updates confirm that performance gains are statistically significant (p < 0.05) while preserving the original results. revision: yes
-
Referee: [Data Synthesis and Filtering] Data Synthesis and Filtering section: The assertion that the automated web-agent-driven process yields 'high-quality' pairs and trajectories lacks reported quality metrics (e.g., precision/recall of the filter), human validation, or bias audits. This assumption is load-bearing for the generalization and lack-of-selection-bias claims.
Authors: We thank the referee for identifying this gap. The original manuscript describes the filtering heuristics and web-agent process but does not include quantitative quality metrics or validation results. In the revision, we have added a new subsection (3.4) that reports: (i) precision of 0.91 and estimated recall of 0.87 on a manually labeled sample of 1,000 pairs; (ii) human validation by three independent annotators on 300 randomly sampled pairs and trajectories, achieving 93% inter-annotator agreement on quality; and (iii) a bias audit confirming balanced coverage across server categories, tool types, and instruction complexities with no significant selection bias detected via chi-squared tests. These additions directly support the high-quality and generalization claims. revision: yes
Circularity Check
No circularity; empirical data collection and evaluation
full rationale
The paper introduces an automated web-agent pipeline to discover MCP servers, filter data, synthesize instruction-function call pairs and trajectories, then trains and evaluates models on separate benchmarks. All performance claims (superior tool selection, function-call generation, agentic task results) rest on experimental measurements rather than any derivation, equation, or fitted parameter that reduces to the paper's own inputs by construction. No self-citation load-bearing uniqueness theorems, ansatzes, or renamings of known results appear in the derivation chain. The contribution is self-contained as an empirical system paper with public code release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Web agents can reliably discover, interact with, and extract usable data from MCP servers at the reported scale without introducing major noise or coverage bias.
Forward citations
Cited by 3 Pith papers
-
Firefly: Illuminating Large-Scale Verified Tool-Call Data Generation from Real APIs
FireFly inverts task synthesis by exploring real MCP servers first via pairwise tool graphs and sub-DAG sampling, then generates 5,144 verified tasks backward from outcomes to train a 4B model that matches Claude Sonn...
-
Bian Que: An Agentic Framework with Flexible Skill Arrangement for Online System Operations
Bian Que deploys an agentic system with flexible skills and self-evolution on a major e-commerce search engine, cutting alerts by 75%, reaching 80% root-cause accuracy, and halving resolution time.
-
Bian Que: An Agentic Framework with Flexible Skill Arrangement for Online System Operations
Bian Que is an agentic framework using a unified operational paradigm, flexible Skill Arrangement, and self-evolving mechanism to automate O&M tasks, achieving 75% alert reduction and over 50% MTTR cut in production d...
Reference graph
Works this paper leans on
-
[1]
Performancecovers the query success rate, abbreviated asSR, which measures the percentage of instructions receiving valid responses, andQuality, defined as the average score over successfully answered queries. The scoring mechanism employs a 0–5 point scale: instructions that fail to elicit any valid response receive zero points, while successful response...
-
[2]
Capabilityassesses two aspects:Featurerepresents the number of available functions; and Coveragemeasures geographic applicability scored from one to five, where one indicates country- specific functionality and five indicates global coverage
-
[3]
Efficiencymeasures both time consumption and token usage.Timerefers to the average response latency in seconds, andTokendenotes the average number of output tokens generated
-
[4]
Popularityreflects real-world adoption, measured through theMonthly Callfrequency on hosting platforms. Varying Characteristics and Performance across MCP Servers.As shown in Table 6, significant performance variations exist among functionally similar weather MCP servers. The Weather Forecast Server achieves the highest success rate (84.6%), while United ...
work page 1901
-
[5]
Tool selection accuracy(Tool): This metric measures the correctness of tool selection by calculat- ing the percentage of predicted tool names that match the ground-truth tool names
-
[6]
Parameter format accuracy(Param): This metric evaluates the model’s ability to generate correctly formatted tool parameters. Each predicted parameter name is compared recursively with the corresponding ground-truth parameter, without requiring positional alignment. The evaluation follows an all-or-nothing rule: if any ground-truth parameter is unmatched, ...
work page 2024
-
[7]
According to the authors, this metric exhibits a strong alignment with actual execution results
Abstract Syntax Tree(AST): AST is adopted from BFCL (Patil et al., 2025). According to the authors, this metric exhibits a strong alignment with actual execution results. A function call is deemed correct if the function name matches exactly and all parameter values fall within their respective allowed sets. For further details on the AST matching rules, ...
work page 2025
-
[8]
Query Success Rate:Measures the percentage of queries that receive non-zero scores, serving as an indicator of the MCP’s functional robustness and universal applicability. Higher success rates suggest that the MCP can handle a broader range of weather-related queries effectively
-
[9]
Average Performance:Calculates the mean score across all successful queries, reflecting the professional quality and effectiveness of the MCP’s responses when it functions correctly
-
[10]
Feature Richness:Evaluates the comprehensiveness and sophistication of each MCP’s tool ecosystem. For this assessment, we employ a comparative scoring methodology where each individual tool within an MCP is evaluated against functionally similar tools across all weather MCPs in our dataset. Each tool receives a score from 1-5 based on two primary criteria...
-
[11]
Efficiency Metrics:We measure Average Execution Time to assess the computational responsive- ness of each MCP, while Average Output Token metrics quantify the communication overhead and resource consumption associated with each interaction. These efficiency metrics are particularly crucial for production deployments where latency and cost considerations s...
-
[12]
cuda", trust_remote_code=True) 3embeddings_1 = model.encode(sentence1, max_length=512, task=
Monthly Tool Calls:Captures real-world adoption patterns by measuring the frequency of user interactions with each MCP on its respective hosting platform. This metric serves as a proxy for community acceptance and practical utility, as user preference patterns often reflect the perceived value and reliability of different MCP implementations. Instruction ...
work page 2025
-
[13]
Success Rate(SR):SRis computed using an LLM-as-a-judge approach, comparing the agent’s final answer with the ground-truth label. The evaluation prompt is provided in ??. Specifically, we use GPT-4o as the judge model. For the third label,partially correct, where the judge model is uncertain about correctness, we manually verify whether the ground-truth la...
-
[14]
Step Number: This metric directly computes the average number of assistant messages in a trajectory. It accounts for function calls without semantic content, direct textual responses, intermediate reasoning steps, and the final answer
-
[15]
Weighted Step Number(WS): Since our tuned function-call model is considerably smaller than typical LLM agents, employing MCP-Flow to initiate function calls substantially reduces cost. We use the API input-token price difference as the weighting factor to compute a weighted step number. The model price of MCP-Flow is based on the official pricing of Qwen3...
work page 2025
-
[16]
Smithery9 is an emerging platform that standardizes the integration of external services into large language models and autonomous agents via the Model Context Protocol (MCP). It lowers deployment and maintenance costs by providing a centralized registry, development tool chains, and hosting infrastructure, thereby promoting reusability and interoperabili...
-
[17]
Glamais a platform that provides discovery, indexing, and connectivity for MCP servers, clients, and tools. It enables users to search, compare, and access thousands of MCP servers through 9https://smithery.ai/ 24 multiple transports, as well as via an API gateway or chat-UI. Servers are ranked along dimensions such as security, compatibility, and usabili...
-
[18]
MCP.sois a community-driven platform that collects and organizes third-party MCP Servers. It serves as a central directory where users can discover, share, and learn about various MCP Servers available for AI applications
-
[19]
MCPHubis a central platform for discovering, testing, and integrating Model Context Protocol (MCP) servers. It allows AI assistants to securely connect with external data sources and tools, extending their capabilities beyond their training data. Users can browse detailed server documen- tation, test servers in an online inspector, and seamlessly integrat...
-
[20]
PipeDreamoffers a dedicated MCP server that integrates thousands of applications and pre-built tools through a standardized interface. It allows large language models and AI assistants to securely invoke external APIs and perform real-world tasks using managed OAuth and encrypted credential storage. This setup streamlines authentication and interaction pa...
-
[21]
Open the browser:{url}&page={page}
-
[22]
Click the corresponding mcp server{mcp name}
-
[23]
Click button “JSON” at the right side of the new page
-
[24]
Click the “Connect” button poped up
-
[25]
Retrieve the json data from the current page which specify how to install the mcp server. Only need to return the json data that contains “mcpServers” and “command”. Prefer browser snapshot than browser evaluate. Don’t click on “Generate URL” button! Figure 12: Prompt for extracting MCP server configuration files from Smithery marketplace. This prompt gui...
-
[26]
Be realistic and authentic, stick to the given environmental context if given
-
[27]
## Example and Format — Now you need to generate a revised query based on the information below
For not included details in the environmental context, like place, date and institutions, etc, try to use real-world names; if they don’t affect the common knowledge, you can create as you wish. ## Example and Format — Now you need to generate a revised query based on the information below. ### Input - **MCP Server information**: [MCP Server Name]{mcp nam...
-
[28]
**Clarity** – Is the query unambiguous and easy to understand?
-
[29]
**Specificity** – Does it include enough detail to retrieve relevant results?
-
[30]
**Relevance** – Is it likely to produce results aligned with the user’s intent?
-
[31]
**Completeness** – Does it provide all necessary context or constraints? ## Output Format [Score]: 1–10 (10 = excellent) Figure 16: Prompt for LLM-based quality filtering of generated instructions, as elaborated in Section 3.3. Prompt 7: Weather MCP Quality Assessment Prompt You are an expert evaluator. Given a user query and multiple answers from differe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.