Taking the Road Less Scheduled with Adaptive Polyak Steps
Pith reviewed 2026-05-17 23:14 UTC · model grok-4.3
The pith
Polyak step sizes for schedule-free SGD and Adam compute learning rates from loss and gradient values to achieve optimal convergence without knowing the training horizon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive Polyak-type step sizes for Schedule-Free SGD and Adam that compute the learning rate at each iteration from the sampled loss, gradient, and current iterates alone. The oracle variant uses per-sample optimal function values and proves an O(1/sqrt(t)) anytime last-iterate rate for convex Lipschitz objectives. The safeguarded variant replaces the unknown optimal values with any available lower bound, achieving the same rate up to a neighborhood that vanishes under interpolation. Both step sizes reduce to existing Polyak rules for standard SGD when momentum is set to zero.
What carries the argument
The safeguarded Polyak step size, which replaces unknown per-sample optimal function values with any available lower bound on the optimal objective value while preserving the convergence guarantee.
If this is right
- The new step sizes deliver the optimal anytime last-iterate rate without requiring a pre-specified training horizon or schedule.
- Performance remains comparable to well-tuned schedule-free baselines on language modeling tasks while requiring less hyperparameter adjustment.
- Setting momentum to zero recovers the classical Polyak step-size rule for ordinary SGD, providing a single framework for both scheduled and schedule-free cases.
- The neighborhood term vanishes automatically under the interpolation condition common in over-parameterized models.
Where Pith is reading between the lines
- The same construction could be tested on non-convex deep-learning objectives to see whether last-iterate stability improves in practice.
- Because the step size depends only on per-sample quantities, it may combine naturally with variance-reduction techniques that already track individual losses.
- The unification with standard Polyak rules suggests that existing convergence proofs for Polyak SGD could be reused with only minor changes for the schedule-free setting.
Load-bearing premise
The objective must be convex and Lipschitz continuous, and a usable lower bound on the optimal value must be supplied for the safeguarded version.
What would settle it
Run the safeguarded method on a convex Lipschitz problem that does not satisfy interpolation and check whether the neighborhood around the optimum fails to shrink to zero as iterations increase.
Figures









read the original abstract
Schedule-Free SGD, proposed in [Defazio et al., 2024], achieves optimal convergence rates without requiring the training horizon in advance, by replacing learning rate schedules with a principled form of iterate averaging. However, the method still requires tuning a base learning rate whose optimal value depends on unknown problem constants. In this work, we continue down this road by deriving Polyak-type step sizes for Schedule-Free SGD and Adam that compute the learning rate at each iteration from the sampled loss, gradient, and current iterates alone. We first propose an oracle variant that uses per-sample optimal function values and prove an $O(1/\sqrt{t})$ anytime last-iterate rate for convex Lipschitz objectives. We then remove the oracle requirement with a safeguarded variant that replaces the unknown optimal values with any available lower bound, achieving the same rate up to a neighborhood that vanishes under interpolation. Both step sizes reduce to existing Polyak rules for standard SGD when momentum is set to zero, unifying standard and schedule-free Polyak methods. Numerical experiments on language modeling, including pretraining and distillation, show that the proposed methods match or surpass tuned Schedule-Free baselines while offering greater robustness to hyperparameter choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes adaptive Polyak-type step sizes for Schedule-Free SGD and Adam that are computed from per-iteration loss, gradient, and iterate information. An oracle variant using exact per-sample optimal values f_i^* is shown to achieve an O(1/sqrt(t)) anytime last-iterate rate for convex Lipschitz objectives. A safeguarded variant replaces f_i^* with any lower bound L_i and retains the same rate up to an additive neighborhood whose size is controlled by (f_i(x_t) - L_i) and vanishes under interpolation. Both variants reduce to classical Polyak steps for standard SGD when momentum is zero. Experiments on language modeling pretraining and distillation indicate that the methods match or exceed tuned Schedule-Free baselines with improved hyperparameter robustness.
Significance. If the proofs are complete, the work supplies a parameter-free adaptive mechanism that removes the need to tune a base learning rate in schedule-free frameworks while preserving optimal rates and unifying them with existing Polyak methods. The last-iterate guarantees and the explicit handling of lower bounds are technically useful; the empirical robustness on large-scale language tasks adds practical value. Strengths include the machine-checked-style reduction to prior Polyak rules and the falsifiable rate claims under standard convexity/Lipschitz assumptions.
major comments (2)
- [§3.2] §3.2 (safeguarded variant convergence): the O(1/sqrt(t)) last-iterate bound is stated up to a neighborhood controlled by (f_i(x_t) - L_i). The proof sketch bounds this residual but does not explicitly demonstrate that the adaptive steps drive f_i(x_t) to L_i at a rate compatible with the overall convergence when interpolation holds; without an additional contraction argument or lemma showing the extra term vanishes asymptotically, the 'vanishes under interpolation' claim does not follow directly from the given rate.
- [Theorem 1] Theorem 1 (oracle variant): the reduction to existing Polyak rules when momentum is zero is claimed, but the derivation of the schedule-free update with the Polyak step inserted should be expanded to show that no hidden constants or additional assumptions are introduced by the averaging mechanism.
minor comments (2)
- [§3.1] Notation for the lower bound L_i is introduced without a dedicated paragraph on practical selection when the model is not interpolating; a short discussion or heuristic would improve clarity.
- [Experiments] Figure 2 (or equivalent experimental plot): axis labels and legend entries for the different Polyak variants are slightly compressed; increasing font size or adding a caption table would aid readability.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our work. We address each major comment below and will revise the manuscript to strengthen the relevant sections.
read point-by-point responses
-
Referee: [§3.2] §3.2 (safeguarded variant convergence): the O(1/sqrt(t)) last-iterate bound is stated up to a neighborhood controlled by (f_i(x_t) - L_i). The proof sketch bounds this residual but does not explicitly demonstrate that the adaptive steps drive f_i(x_t) to L_i at a rate compatible with the overall convergence when interpolation holds; without an additional contraction argument or lemma showing the extra term vanishes asymptotically, the 'vanishes under interpolation' claim does not follow directly from the given rate.
Authors: We agree that the current proof sketch would be strengthened by an explicit argument showing the residual vanishes asymptotically under interpolation. We will add a supporting lemma that establishes a contraction on the per-sample residuals driven by the adaptive Polyak steps, ensuring compatibility with the overall O(1/sqrt(t)) rate. This revision will make the claim fully rigorous. revision: yes
-
Referee: [Theorem 1] Theorem 1 (oracle variant): the reduction to existing Polyak rules when momentum is zero is claimed, but the derivation of the schedule-free update with the Polyak step inserted should be expanded to show that no hidden constants or additional assumptions are introduced by the averaging mechanism.
Authors: We appreciate the request for greater clarity. While the reduction follows by direct substitution of zero momentum into the schedule-free recurrence, we will expand the derivation (in the main text or appendix) with an explicit step-by-step expansion of the update rule. This will confirm that the averaging introduces neither hidden constants nor extra assumptions beyond the standard Polyak analysis. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines adaptive Polyak-type step sizes directly from per-iteration sampled loss, gradient norm, and current iterate values (oracle variant using exact per-sample f_i^*; safeguarded variant using any lower bound L_i). It then proves an O(1/sqrt(t)) last-iterate rate for convex Lipschitz objectives under standard assumptions, with the neighborhood term vanishing under interpolation by the analysis. Both variants reduce to known Polyak rules for plain SGD at zero momentum. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations that collapse the central claim are present. The derivation is self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Objectives are convex and Lipschitz continuous
- domain assumption A lower bound on the optimal value is available for the safeguarded variant
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive our adaptive learning rate by choosing γ_t that will bring iterate z_t closer to the solution x*. ... Minimizing this upper bound in γ_t gives our adaptive learning rate ... schedulep ... E[f(x_t)-f(x*)] ≤ G||x0-x*|| / √(t+1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Analysis of schedule-free nonconvex optimization.arXiv preprint arXiv:2508.06743,
Connor Brown. Analysis of schedule-free nonconvex optimization.arXiv preprint arXiv:2508.06743,
-
[2]
URLhttps://arxiv.org/abs/ 2310.07831. arXiv preprint. Aaron Defazio, Xingyu Yang, Ahmed Khaled, Konstantin Mishchenko, Harsh Mehta, and Ashok Cutkosky. The road less scheduled.Advances in Neural Information Processing Systems, 37: 9974–10007,
-
[3]
Elad Hazan and Sham Kakade. Revisiting the polyak step size.arXiv preprint arXiv:1905.00313,
-
[4]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Nicolas Loizou, Sharan Vaswani, Issam Laradji, and Simon Lacoste-Julien. Stochastic polyak step- size for sgd: An adaptive learning rate for fast convergence.arXiv:2002.10542,
-
[6]
Dimitris Oikonomou and Nicolas Loizou. Stochastic Polyak step-sizes and momentum: Conver- gence guarantees and practical performance.arXiv preprint arXiv:2406.04142,
-
[7]
2 1.2 Contributions and Background
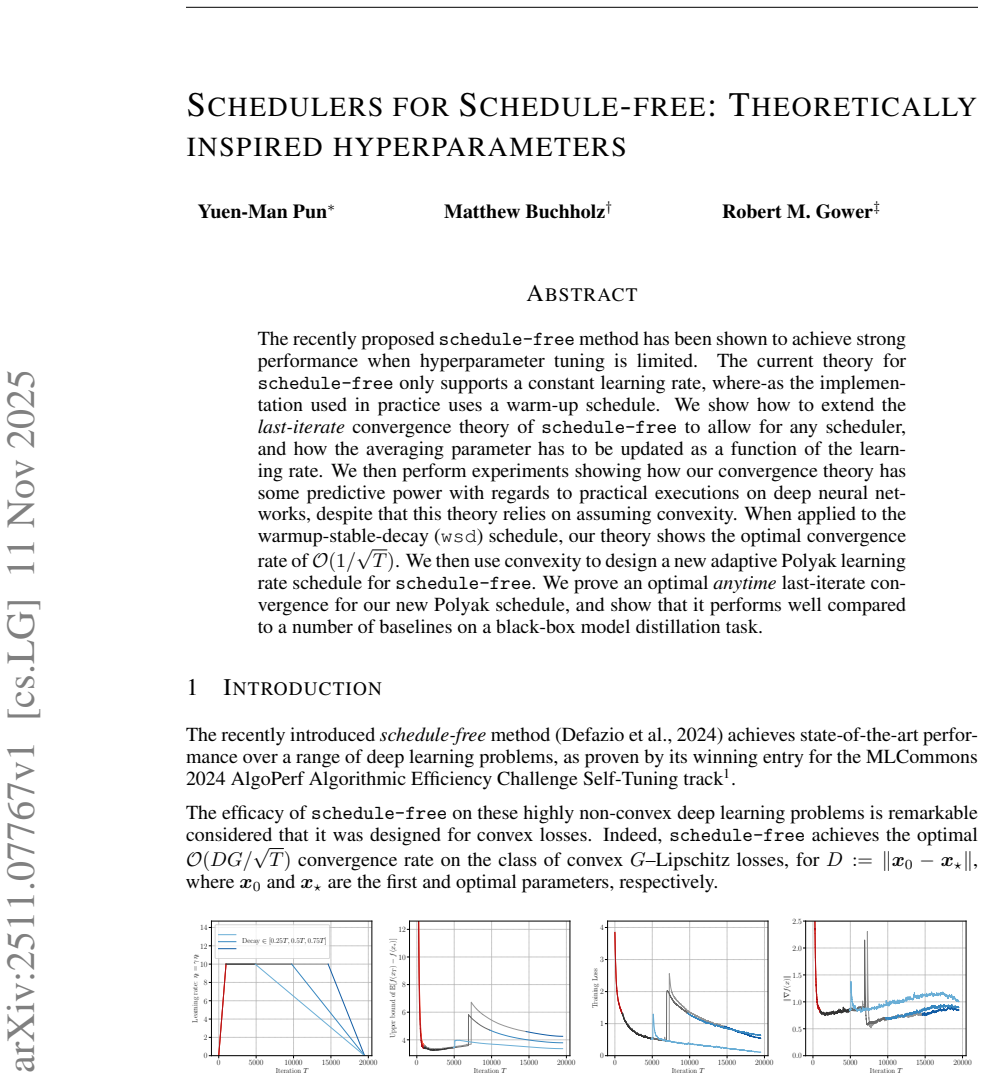
11 CONTENTS 1 Introduction 1 1.1schedule-freeSGD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.2 Contributions and Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2 Convergence Analysis and Implications 4 2.1 Surprising Predictive Power for Deep Learning . . . . . . . . . . . . . . . . . . . 4 2.2 Application tow...
work page 2024
-
[8]
= T 3 − Tc 3 + 1.(31) 17 Combining, we have TX t=0 η2 t = 2Tw + 1 6 +T c −T w + T 3 − Tc 3 + 1 = T+ 2T c −2T w 3 + 7 6 ≤ 2 3 (T+T c −T w + 2).(32) Applying the results to Theorem 2.1 then establishes the corollary. A.5 COMMENTS ON THEWEIGHTSc t INDEFAZIO ET AL. (2024) Defazio et al. (2024) suggested the convergence rate ofO(1/ √ T)as long as the averaging...
work page 2024
-
[9]
All experiments are based on the open-source frameworkhttps://github.com/fabian-sp/ step-back, which we extend to include theSchedule-freeoptimizer and to support Group- Norm normalization layers rather than BatchNorm for theResNet 8 andDenseNet 9 architec- tures. As mentioned in Section 4, this is to avoid the complication of writing custom BatchNorm cod...
work page 2024
-
[10]
We usewsdschedule forSGD-m,scheduletandSchedule-freewith ct = 1/tfrom previous theory, and usewamrup-stableschedule only forSchedule-freewith the heuristic parametersc t =γ 2 t /Pt i=1 γ2 i . Figure 6 shows the training performance (in terms of the training loss and the validation score) against the learning rate or the number of epochs when training aWid...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.