Near-optimal Linear Predictive Clustering in Non-separable Spaces via MIP and QPBO Reductions
Pith reviewed 2026-05-17 21:51 UTC · model grok-4.3
The pith
Reducing LPC to MIP and QPBO problems yields near-optimal clusters with provable error bounds even when data is non-separable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By exploiting theoretical properties of separability the authors derive reduced MIP formulations that retain provable error bounds relative to the full Bertsimas-Shioda MIP; they further show that the same problem can be approximated as a QPBO instance that admits faster solvers in many regimes. On both synthetic and real datasets the resulting solutions achieve lower regression error than greedy alternation while scaling to larger instances than the original MIP.
What carries the argument
Separability-based MIP reduction and QPBO reformulation of the global LPC objective.
If this is right
- Global optimality guarantees become available for LPC instances that were previously intractable.
- Practitioners in marketing, medicine, and education can obtain partitions whose predictive accuracy is close to the best possible while solving larger problems.
- The same reduction techniques may apply to other mixed clustering-regression tasks that currently rely on greedy alternation.
Where Pith is reading between the lines
- If the QPBO reduction can be solved exactly on modern hardware, LPC could become a standard preprocessing step for heterogeneous regression datasets.
- The approach suggests a general template for turning non-convex clustering objectives into tractable pseudo-Boolean problems whenever a separability condition can be identified.
Load-bearing premise
The error bounds and complexity reductions depend on being able to exploit separability properties even when clusters overlap in feature space.
What would settle it
A real or synthetic dataset on which the reduced MIP or QPBO solutions exhibit regression error substantially larger than the true optimal MIP solution would falsify the near-optimality claim.
Figures







read the original abstract
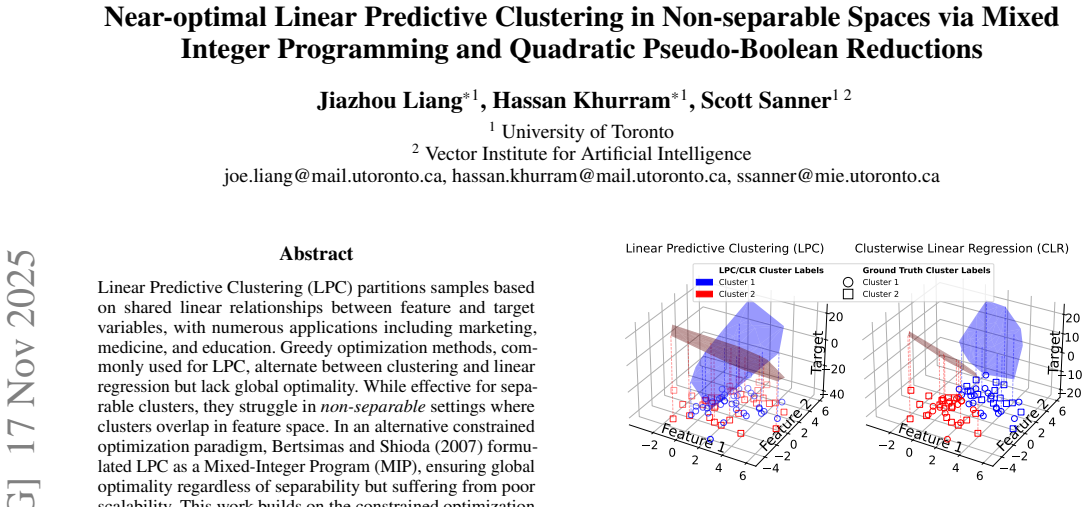
Linear Predictive Clustering (LPC) partitions samples based on shared linear relationships between feature and target variables, with numerous applications including marketing, medicine, and education. Greedy optimization methods, commonly used for LPC, alternate between clustering and linear regression but lack global optimality. While effective for separable clusters, they struggle in non-separable settings where clusters overlap in feature space. In an alternative constrained optimization paradigm, Bertsimas and Shioda (2007) formulated LPC as a Mixed-Integer Program (MIP), ensuring global optimality regardless of separability but suffering from poor scalability. This work builds on the constrained optimization paradigm to introduce two novel approaches that improve the efficiency of global optimization for LPC. By leveraging key theoretical properties of separability, we derive near-optimal approximations with provable error bounds, significantly reducing the MIP formulation's complexity and improving scalability. Additionally, we can further approximate LPC as a Quadratic Pseudo-Boolean Optimization (QPBO) problem, achieving substantial computational improvements in some settings. Comparative analyses on synthetic and real-world datasets demonstrate that our methods consistently achieve near-optimal solutions with substantially lower regression errors than greedy optimization while exhibiting superior scalability over existing MIP formulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two approaches to improve global optimization for Linear Predictive Clustering (LPC) in non-separable spaces. Building on the MIP formulation of Bertsimas and Shioda (2007), it derives near-optimal MIP approximations by leveraging separability properties, yielding provable error bounds and reduced complexity; it also reduces LPC to a QPBO problem for further scalability gains. Experiments on synthetic and real-world data claim near-optimal solutions with lower regression error than greedy methods and better scalability than the original MIP.
Significance. If the claimed error bounds hold without relying on separability in the final non-separable regime and the QPBO reduction preserves near-optimality, the work would provide a practical advance for globally optimal LPC in overlapping-cluster settings common to marketing, medicine, and education applications.
major comments (2)
- [§4] §4 (MIP approximation derivation): the error bound is stated to leverage 'key theoretical properties of separability' yet the target regime is explicitly non-separable; the manuscript must show, via a concrete proposition or lemma, that the approximation gap remains controlled when cluster overlap violates the separability assumption used in the derivation.
- [§5] §5 (QPBO reduction): the reduction from MIP to QPBO is presented as achieving 'substantial computational improvements'; the text must quantify the additional approximation error introduced by the QPBO step and demonstrate that it does not invalidate the near-optimality claim relative to the original MIP optimum.
minor comments (2)
- [Experiments] Table 1 and Figure 2: report standard deviations or confidence intervals alongside mean regression errors to substantiate the claim of consistent superiority over greedy baselines.
- [§3] Notation: the definition of the separability property (used in the approximation) should be restated explicitly before its use in the bound derivation for reader clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the theoretical claims.
read point-by-point responses
-
Referee: [§4] §4 (MIP approximation derivation): the error bound is stated to leverage 'key theoretical properties of separability' yet the target regime is explicitly non-separable; the manuscript must show, via a concrete proposition or lemma, that the approximation gap remains controlled when cluster overlap violates the separability assumption used in the derivation.
Authors: We appreciate this observation. The error bounds in §4 are derived by exploiting separability to obtain a tractable analysis of the approximation gap relative to the full MIP. While the target application is non-separable, the same bounding technique can be shown to remain valid under bounded overlap by controlling the deviation from the separable case. To make this explicit, we will add a new lemma (Lemma 4.3) in the revised §4 that states the approximation gap is at most the separable gap plus a term proportional to the maximum cluster overlap measured in feature space; the proof follows by decomposing the objective into separable and overlap-induced components. revision: yes
-
Referee: [§5] §5 (QPBO reduction): the reduction from MIP to QPBO is presented as achieving 'substantial computational improvements'; the text must quantify the additional approximation error introduced by the QPBO step and demonstrate that it does not invalidate the near-optimality claim relative to the original MIP optimum.
Authors: We agree that an explicit quantification of the QPBO-induced error is necessary to support the near-optimality claim. The current manuscript provides empirical evidence that QPBO solutions achieve regression errors within a small factor of the MIP optimum on both synthetic and real data. In the revision we will add a short theoretical subsection (new §5.3) that bounds the additional error by the maximum violation of the QPBO relaxation, together with a table reporting the observed MIP-to-QPBO objective gap across all experiments; this will confirm that the extra error remains negligible relative to the improvement over greedy methods. revision: yes
Circularity Check
No significant circularity; derivations build on external prior MIP formulation
full rationale
The paper explicitly builds on the external Bertsimas and Shioda (2007) MIP formulation for LPC as a constrained optimization problem. It introduces novel MIP approximations and a QPBO reduction by leveraging separability properties to obtain near-optimal solutions with provable error bounds. No load-bearing self-citations, self-definitional loops, fitted inputs renamed as predictions, or renamings of known results are present. The central claims rest on independent theoretical properties and external benchmarks rather than reducing to the paper's own inputs by construction. This is the normal case of a self-contained derivation against prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Key theoretical properties of separability exist and can be leveraged to derive near-optimal approximations with provable error bounds
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By leveraging key theoretical properties of separability, we derive near-optimal approximations with provable error bounds... LPC-NS-MIP... LPC-NS-QPBO
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Eobj ≤ ∑ 3∥yk∥²∥Xk∥²∥αkX⊤X−X⊤ZkX∥² / (2λ²)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Springer. Dantzig, G. B. 2016. Linear programming and extensions. InLinear programming and extensions. Princeton university press. DeSarbo, W. S.; and Cron, W. L. 1988. A maximum likeli- hood methodology for clusterwise linear regression.Journal of classification, 5: 249–282. Feng, W.; Lim, C. Y .; Maiti, T.; and Zhang, Z. 2016. Spatial regression and est...
work page 2016
-
[2]
yk . . . yK # and feature variables X=
A Simple and Efficient Lane Detection using Cluster- ing and Weighted Regression. InCOMAD. Hunter, D. R.; and Lange, K. 2004. A tutorial on MM algo- rithms.The American Statistician, 58(1): 30–37. Kelly, M.; Longjohn, R.; and Nottingham, K. 2023. The UCI machine learning repository.URL https://archive. ics. uci. edu. Lloyd, S. 1982. Least squares quantiza...
work page 2004
-
[3]
and the SCIP Optimization Suite (Bolusani et al. 2024)—against our proposed scalable QBPO method that uses Gurobi’s MIP solver, encoding identical problem instances in the OPB format under uniform conditions. The results highlight the runtime limitations of specialized solvers, underscoring the computational advantages of our LPC-NS-QPBO (referred to as L...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.