StreamingTalker: Audio-driven 3D Facial Animation with Autoregressive Diffusion Model
Pith reviewed 2026-05-21 19:25 UTC · model grok-4.3
The pith
An autoregressive diffusion model generates 3D facial animations from streaming audio by conditioning each new frame on a short history of prior motions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
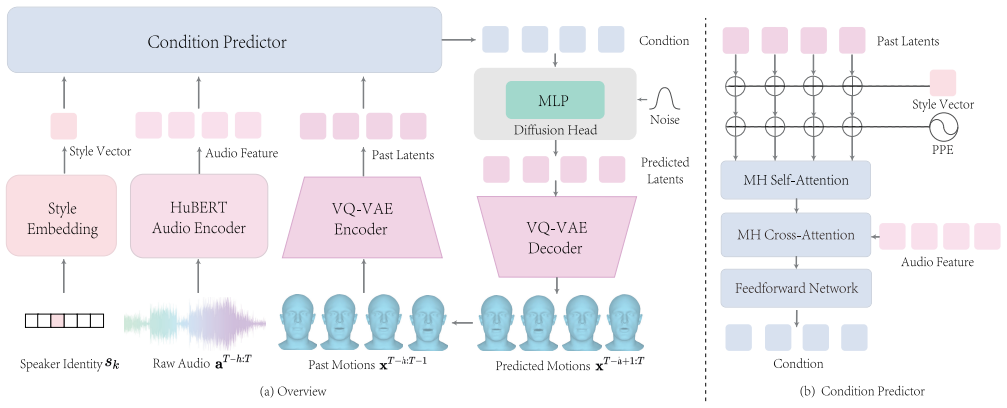
The central claim is that an autoregressive diffusion model can produce high-quality, audio-synchronized 3D facial motion sequences by iteratively denoising each new frame while conditioning the process on both the current audio segment and a limited set of past motion frames, thereby supporting continuous streaming generation with latency independent of total audio length.
What carries the argument
The dynamic conditioning step that combines incoming audio with a small fixed window of historical motion frames to steer the diffusion denoising process for sequential frame-by-frame generation.
If this is right
- Animation can be produced with constant low latency for audio of any duration.
- The same trained model handles both short and long inputs without retraining or padding tricks.
- Real-time interactive use becomes practical, as shown by the implemented demo.
- Quality remains comparable to full-sequence diffusion while removing the length restriction.
Where Pith is reading between the lines
- The same streaming conditioning pattern could be tested on related tasks such as audio-driven body gesture generation.
- On-device deployment for mobile avatars becomes more feasible because computation per frame stays bounded.
- Error accumulation might still appear in very long sessions, suggesting periodic full-context resets as a practical safeguard.
Load-bearing premise
That a short window of past motion frames supplies enough context to keep long-term motion coherent and prevent gradual drift or error buildup across extended audio.
What would settle it
A continuous multi-minute audio clip in which the generated facial motions begin to lose synchronization with the speech or develop visible unnatural drift after the first minute would show the limited-history conditioning is insufficient.
Figures





read the original abstract
This paper focuses on the task of speech-driven 3D facial animation, which aims to generate realistic and synchronized facial motions driven by speech inputs. Recent methods have employed audio-conditioned diffusion models for 3D facial animation, achieving impressive results in generating expressive and natural animations. However, these methods process the whole audio sequences in a single pass, which poses two major challenges: they tend to perform poorly when handling audio sequences that exceed the training horizon and will suffer from significant latency when processing long audio inputs. To address these limitations, we propose a novel autoregressive diffusion model that processes input audio in a streaming manner. This design ensures flexibility with varying audio lengths and achieves low latency independent of audio duration. Specifically, we select a limited number of past frames as historical motion context and combine them with the audio input to create a dynamic condition. This condition guides the diffusion process to iteratively generate facial motion frames, enabling real-time synthesis with high-quality results. Additionally, we implemented a real-time interactive demo, highlighting the effectiveness and efficiency of our approach. We will release the code at https://zju3dv.github.io/StreamingTalker/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StreamingTalker, a novel autoregressive diffusion model for audio-driven 3D facial animation. It processes input audio in a streaming manner by selecting a limited number of past frames as historical motion context, combining them with the current audio to form a dynamic condition that guides the diffusion process to iteratively generate the next facial motion frame. This design aims to overcome the limitations of prior batch-processing diffusion methods, which struggle with audio sequences longer than the training horizon and incur high latency on long inputs, thereby enabling real-time synthesis with low latency independent of audio duration. The authors also present a real-time interactive demo and commit to releasing the code.
Significance. If the empirical claims hold, the work would offer a practical advance for real-time speech-driven animation in applications such as virtual avatars and interactive media by providing length-independent latency and flexibility. The autoregressive streaming formulation with historical context is a direct response to a recognized bottleneck in diffusion-based animation pipelines. However, the absence of any reported quantitative results, ablation studies, error metrics, or baseline comparisons in the manuscript text makes it impossible to gauge whether the design actually delivers measurable improvements in quality or coherence.
major comments (2)
- [Abstract] Abstract: the central claim that the autoregressive diffusion model 'enables real-time synthesis with high-quality results' is unsupported by any quantitative evidence, ablation studies, error metrics, or comparisons with prior work. This is load-bearing for the contribution because the soundness of the streaming design rests on demonstrating that the limited historical context suffices for coherent generation.
- [Abstract] Abstract (and implied Method): the autoregressive conditioning on a limited number of past motion frames is presented without any described mechanism (e.g., scheduled sampling, auxiliary consistency loss, or periodic global conditioning) to counteract error accumulation or drift over sequences much longer than the training window. This directly affects the weakest assumption that short-window historical context will maintain long-term coherence.
minor comments (2)
- [Abstract] The abstract mentions implementation of a real-time interactive demo but provides no details on the demo's technical specifications, hardware requirements, or measured latency, which would help readers assess practicality.
- [Abstract] The promised code release link is given but no supplementary material or pseudocode for the dynamic conditioning procedure is included in the text, hindering immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative validation and explicit mechanisms for long-term coherence. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the autoregressive diffusion model 'enables real-time synthesis with high-quality results' is unsupported by any quantitative evidence, ablation studies, error metrics, or comparisons with prior work. This is load-bearing for the contribution because the soundness of the streaming design rests on demonstrating that the limited historical context suffices for coherent generation.
Authors: We acknowledge that the current manuscript text focuses on the method description and qualitative demonstration via the interactive demo, without including numerical metrics or baseline comparisons. This is a valid observation. In the revised version, we will add quantitative evaluations including vertex-wise error metrics, lip synchronization scores (e.g., LSE-D and LSE-C), ablation studies varying the historical frame count, and direct comparisons against prior batch diffusion methods on standard benchmarks. These additions will directly support the claim that limited historical context suffices for coherent, high-quality streaming synthesis. revision: yes
-
Referee: [Abstract] Abstract (and implied Method): the autoregressive conditioning on a limited number of past motion frames is presented without any described mechanism (e.g., scheduled sampling, auxiliary consistency loss, or periodic global conditioning) to counteract error accumulation or drift over sequences much longer than the training window. This directly affects the weakest assumption that short-window historical context will maintain long-term coherence.
Authors: The method relies on conditioning each diffusion step on a sliding window of recent motion frames plus current audio, which in practice limits drift by emphasizing local temporal consistency. However, the manuscript does not explicitly describe auxiliary techniques such as consistency losses or periodic global resets. We agree this should be clarified. In revision, we will expand the method section to include a scheduled sampling strategy during training and an auxiliary temporal consistency loss to further stabilize long sequences, along with analysis showing that the chosen window size maintains coherence beyond the training horizon. revision: yes
Circularity Check
No circularity: novel streaming diffusion design is self-contained
full rationale
The paper proposes an autoregressive diffusion model that conditions on a sliding window of past motion frames plus current audio to enable streaming generation. No equations, derivations, or fitted parameters are presented that reduce the claimed real-time coherence or quality to quantities obtained by construction from the same training data or prior self-citations. The central contribution is an architectural choice addressing latency and sequence-length limitations of prior non-streaming diffusion methods, remaining independent of the circularity patterns listed in the guidelines.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of historical motion frames
axioms (1)
- domain assumption A limited number of past motion frames supply sufficient context to maintain animation coherence across long audio streams
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we select a limited number of past frames as historical motion context and combine them with the audio input to create a dynamic condition... AR condition predictor... Diffusion Head
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fixed history length strategy, selecting the start frame and take the next h frames... h ranging from 60 to 120 frames
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ho, J.; Jain, A.; and Abbeel, P
Generative adversarial networks.Communications of the ACM, 63(11): 139–144. Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising diffusion probabilistic models.Advances in neural information pro- cessing systems, 33: 6840–6851. Hsu, W.-N.; Bolte, B.; Tsai, Y .-H. H.; Lakhotia, K.; Salakhutdinov, R.; and Mohamed, A. 2021. Hubert: Self- supervised speech repres...
work page 2020
-
[2]
Auto-Encoding Variational Bayes
Audio-driven facial animation by joint end-to-end learning of pose and emotion.ACM Transactions on Graph- ics (ToG), 36(4): 1–12. Kingma, D. P. 2013. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114. Kurose, J.; and Ross, K. 2017.Computer Networking: A Top-Down Approach. Pearson. Li, T.; Bolkart, T.; Black, M. J.; Li, H.; and Romero, J. 2017...
work page internal anchor Pith review Pith/arXiv arXiv 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.