ArchMap: Arch-Flattening and Knowledge-Guided Vision Language Model for Tooth Counting and Structured Dental Understanding
Pith reviewed 2026-05-17 21:11 UTC · model grok-4.3
The pith
Arch flattening plus a dental knowledge base lets vision-language models count teeth and detect conditions in raw 3D intraoral scans without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
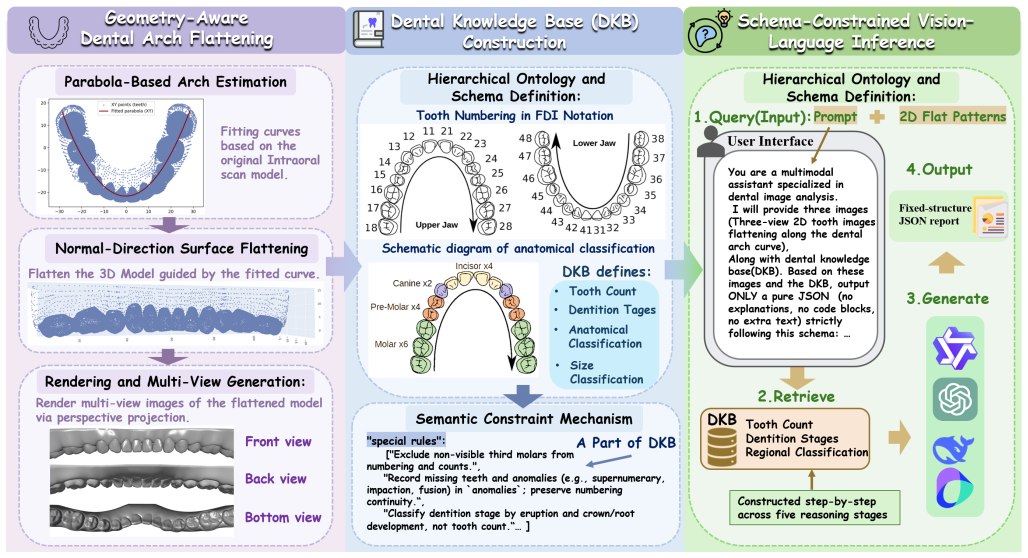
ArchMap shows that a geometry-aware arch-flattening step produces continuity-preserving multi-view projections from pose-varying and incomplete intraoral meshes, while a Dental Knowledge Base encoding hierarchical tooth ontology, dentition policies, and clinical semantics constrains the reasoning space, enabling accurate structured dental understanding without task-specific training or fine-tuning.
What carries the argument
The geometry-aware arch-flattening module that standardizes raw 3D meshes into spatially aligned, continuity-preserving multi-view projections, paired with the Dental Knowledge Base that supplies ontology and clinical constraints to limit semantic drift during vision-language model reasoning.
If this is right
- Tooth counting and anatomical partitioning reach higher accuracy on pre- and post-orthodontic cases than supervised or prompted baselines.
- Identification of conditions such as crowding, missing teeth, prosthetics, and caries shows reduced semantic drift.
- Performance remains stable even when input meshes are sparse or contain scanning artifacts.
- A fully training-free pipeline can generalize across devices better than modality-specific trained systems.
Where Pith is reading between the lines
- The same flattening-plus-ontology pattern could be tested on other 3D medical meshes where pose and incompleteness are common problems.
- Clinics might adopt the method faster because it removes the need to collect and label thousands of new training examples for each scanner type.
- Extending the knowledge base with additional rules for rare anomalies could further widen the range of conditions the system handles without retraining.
Load-bearing premise
The flattening step must turn imperfect meshes into projections that keep every important anatomical detail and meaning intact, while the knowledge base must supply enough rules to stop the model from making reasoning mistakes.
What would settle it
On a held-out collection of intraoral scans that include heavy pose variation or large missing regions, if ArchMap produces more tooth-count errors or clinical misidentifications than a retrained supervised pipeline, the claim that flattening plus knowledge guidance suffices would not hold.
Figures

read the original abstract
A structured understanding of intraoral 3D scans is essential for digital orthodontics. However, existing deep-learning approaches rely heavily on modality-specific training, large annotated datasets, and controlled scanning conditions, which limit generalization across devices and hinder deployment in real clinical workflows. Moreover, raw intraoral meshes exhibit substantial variation in arch pose, incomplete geometry caused by occlusion or tooth contact, and a lack of texture cues, making unified semantic interpretation highly challenging. To address these limitations, we propose ArchMap, a training-free and knowledge-guided framework for robust structured dental understanding. ArchMap first introduces a geometry-aware arch-flattening module that standardizes raw 3D meshes into spatially aligned, continuity-preserving multi-view projections. We then construct a Dental Knowledge Base (DKB) encoding hierarchical tooth ontology, dentition-stage policies, and clinical semantics to constrain the symbolic reasoning space. We validate ArchMap on 1060 pre-/post-orthodontic cases, demonstrating robust performance in tooth counting, anatomical partitioning, dentition-stage classification, and the identification of clinical conditions such as crowding, missing teeth, prosthetics, and caries. Compared with supervised pipelines and prompted VLM baselines, ArchMap achieves higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions. As a fully training-free system, ArchMap demonstrates that combining geometric normalization with ontology-guided multimodal reasoning offers a practical and scalable solution for the structured analysis of 3D intraoral scans in modern digital orthodontics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ArchMap, a training-free and knowledge-guided framework for structured dental understanding from intraoral 3D scans. It introduces a geometry-aware arch-flattening module to standardize raw meshes into spatially aligned, continuity-preserving multi-view projections, constructs a Dental Knowledge Base (DKB) encoding hierarchical tooth ontology, dentition-stage policies, and clinical semantics, and uses these to constrain VLM reasoning. The framework is validated on 1060 pre-/post-orthodontic cases for tooth counting, anatomical partitioning, dentition-stage classification, and identification of conditions such as crowding, missing teeth, prosthetics, and caries, with claims of higher accuracy, reduced semantic drift, and superior stability compared to supervised pipelines and prompted VLM baselines.
Significance. If the central claims hold with supporting quantitative evidence, the work could be significant for digital orthodontics by demonstrating a practical, training-free alternative that reduces reliance on large annotated datasets and improves generalization across devices and artifact-prone conditions. The combination of geometric normalization with ontology-guided multimodal reasoning is a notable strength, as is the explicit focus on stability under sparse or incomplete geometry. These elements address real deployment barriers in clinical workflows.
major comments (2)
- [Abstract] Abstract: The claim of superior performance on 1060 cases versus baselines is stated without any quantitative metrics, error analysis, exclusion criteria, or implementation details. This absence leaves major gaps in verifying support for the central claims of higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions.
- [Arch-flattening module] Arch-flattening module (method description): The geometry-aware arch-flattening is presented as converting raw intraoral meshes with pose variation, occlusion, and incomplete geometry into continuity-preserving multi-view projections without loss of critical anatomical or semantic information, yet no explicit metrics (e.g., pre/post-flattening tooth centroid error, segmentation IoU under synthetic incompleteness, or landmark retention rate) are reported to quantify preservation under the exact challenging conditions cited. This quantification is load-bearing for attributing downstream VLM + DKB gains to the flattening step.
minor comments (2)
- [Figures] Figure captions for the multi-view projections should explicitly note any assumptions about mesh completeness or pose standardization to aid reader interpretation.
- [Dental Knowledge Base] The hierarchical structure of the Dental Knowledge Base would benefit from a concise table or diagram summarizing the ontology levels and policy rules for easier reference.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, proposing specific revisions to improve clarity and support for the central claims. All proposed changes will be incorporated in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of superior performance on 1060 cases versus baselines is stated without any quantitative metrics, error analysis, exclusion criteria, or implementation details. This absence leaves major gaps in verifying support for the central claims of higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports these in Section 4 (Experiments), including tooth counting accuracy of 97.8% on the 1060 cases (vs. 89.4% for the strongest VLM baseline), a 12% reduction in semantic drift measured by ontology violation rate, and stability results showing <3% accuracy drop on scans with >25% missing geometry. Exclusion criteria (scans with extreme motion artifacts or <50% arch coverage) and implementation details (VLM prompt templates, DKB construction) appear in Sections 3.2 and 4.1. We will revise the abstract to incorporate concise metrics and a brief reference to the evaluation protocol. revision: yes
-
Referee: [Arch-flattening module] Arch-flattening module (method description): The geometry-aware arch-flattening is presented as converting raw intraoral meshes with pose variation, occlusion, and incomplete geometry into continuity-preserving multi-view projections without loss of critical anatomical or semantic information, yet no explicit metrics (e.g., pre/post-flattening tooth centroid error, segmentation IoU under synthetic incompleteness, or landmark retention rate) are reported to quantify preservation under the exact challenging conditions cited. This quantification is load-bearing for attributing downstream VLM + DKB gains to the flattening step.
Authors: The referee correctly identifies that direct quantitative metrics for information preservation in the arch-flattening module are not provided. The current manuscript demonstrates the module's effect indirectly via end-to-end gains and qualitative examples in Figure 3. We will add a dedicated paragraph in Section 3.1 with a geometric argument for topology preservation (mesh connectivity and geodesic distances are maintained by construction) plus illustrative centroid displacement statistics computed on a 50-case subset. However, full synthetic incompleteness IoU or landmark retention experiments were not performed in the original study; we will include a limitations note acknowledging this and commit to such analysis in future work. revision: partial
Circularity Check
No circularity: independent geometric and knowledge modules with external validation
full rationale
The paper describes a training-free pipeline consisting of a geometry-aware arch-flattening module that produces multi-view projections from raw meshes and a separately constructed Dental Knowledge Base that supplies hierarchical ontology and clinical constraints. These components are introduced as distinct engineering contributions whose outputs feed a VLM; the reported metrics (accuracy on tooth counting, partitioning, stage classification, and clinical condition detection) are obtained by direct comparison against supervised baselines and prompted VLM variants on an external set of 1060 cases. No equation, parameter fit, or central claim is shown to be definitionally equivalent to its own input, and no load-bearing premise reduces to a self-citation whose content is itself unverified. The derivation chain therefore remains self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Raw intraoral meshes exhibit substantial variation in arch pose, incomplete geometry caused by occlusion or tooth contact, and a lack of texture cues that can be mitigated by geometric normalization.
invented entities (2)
-
Arch-flattening module
no independent evidence
-
Dental Knowledge Base (DKB)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. Liu, J. Hao, H. Lin, W. Pan, J. Yang, Y . Feng, G. Wang, J. Li, Z. Jin, Z. Zhaoet al., “Deep learning-enabled 3d multimodal fusion of cone- beam ct and intraoral mesh scans for clinically applicable tooth-bone reconstruction,”Patterns, vol. 4, no. 9, 2023
work page 2023
-
[2]
Deep learning-based tooth segmentation methods in medical imaging: A review,
X. Chen, N. Ma, T. Xu, and C. Xu, “Deep learning-based tooth segmentation methods in medical imaging: A review,”Proceedings of the Institution of Mechanical Engineers, Part H: Journal of Engineering in Medicine, vol. 238, no. 2, pp. 115–131, 2024
work page 2024
-
[3]
A. M. Alassiry, “Clinical aspects of digital three-dimensional intraoral scanning in orthodontics–a systematic review,”The Saudi Dental Jour- nal, vol. 35, no. 5, pp. 437–442, 2023
work page 2023
-
[4]
T.-H. Wu, C. Lian, S. Lee, M. Pastewait, C. Piers, J. Liu, F. Wang, L. Wang, C.-Y . Chiu, W. Wanget al., “Two-stage mesh deep learning for automated tooth segmentation and landmark localization on 3d intraoral scans,”IEEE transactions on medical imaging, vol. 41, no. 11, pp. 3158– 3166, 2022
work page 2022
-
[5]
Mask-mcnet: tooth instance segmentation in 3d point clouds of intra-oral scans,
F. G. Zanjani, A. Pourtaherian, S. Zinger, D. A. Moin, F. Claessen, T. Cherici, S. Parinussa, and P. H. de With, “Mask-mcnet: tooth instance segmentation in 3d point clouds of intra-oral scans,”Neurocomputing, vol. 453, pp. 286–298, 2021
work page 2021
-
[6]
J. Im, J.-Y . Kim, H.-S. Yu, K.-J. Lee, S.-H. Choi, J.-H. Kim, H.-K. Ahn, and J.-Y . Cha, “Accuracy and efficiency of automatic tooth segmentation in digital dental models using deep learning,”Scientific reports, vol. 12, no. 1, p. 9429, 2022
work page 2022
-
[7]
Transformer based 3d tooth segmentation via point cloud region partition,
Y . Wu, H. Yan, and K. Ding, “Transformer based 3d tooth segmentation via point cloud region partition,”Scientific Reports, vol. 14, no. 1, p. 28513, 2024
work page 2024
-
[8]
Automatic 3d tooth segmentation using convolutional neural networks in harmonic parameter space,
J. Zhang, C. Li, Q. Song, L. Gao, and Y .-K. Lai, “Automatic 3d tooth segmentation using convolutional neural networks in harmonic parameter space,”Graphical Models, vol. 109, p. 101071, 2020
work page 2020
-
[9]
W. Y . Kot, S. Y . Au Yeung, Y . Y . Leung, P. H. Leung, and W.-f. Yang, “Evolution of deep learning tooth segmentation from ct/cbct images: a systematic review and meta-analysis,”BMC Oral Health, vol. 25, no. 1, p. 800, 2025
work page 2025
-
[10]
L. Yang, Z. Zhu, Y . Li, J. Huang, X. Wang, H. Zheng, and J. Chen, “Clinica-oriented 3d visualization and quantitative analysis of gingival thickness using convolutional neural networks and cbct,”Frontiers in Dental Medicine, vol. 6, p. 1635155, 2025
work page 2025
-
[11]
Dentalsplat: Dental occlusion novel view synthesis from sparse intra-oral photographs,
Y . Miao, T. Wu, T. Chen, S. Li, J. Jiang, Y . Yang, A. Stefanidis, L. Yu, and J. Su, “Dentalsplat: Dental occlusion novel view synthesis from sparse intra-oral photographs,”arXiv preprint arXiv:2511.03099, 2025
-
[12]
R. Nambiar and R. Nanjundegowda, “A comprehensive review of ai and deep learning applications in dentistry: From image segmentation to treatment planning,”Journal of Robotics and Control (JRC), vol. 5, no. 6, pp. 1744–1752, 2024
work page 2024
-
[13]
Application of machine learning in dentistry: insights, prospects and challenges,
L. Wang, Y . Xu, W. Wang, and Y . Lu, “Application of machine learning in dentistry: insights, prospects and challenges,”Acta Odontologica Scandinavica, vol. 84, p. 43345, 2025
work page 2025
-
[14]
3d dental model segmentation with geometrical boundary preserving,
S. Xi, Z. Liu, J. Chang, H. Wu, X. Wang, and A. Hao, “3d dental model segmentation with geometrical boundary preserving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 10 476–10 485
work page 2025
-
[15]
Cross- center model adaptive tooth segmentation,
R. Chen, J. Yang, H. Xiong, R. Xu, Y . Feng, J. Wu, and Z. Liu, “Cross- center model adaptive tooth segmentation,”Medical Image Analysis, vol. 101, p. 103443, 2025
work page 2025
-
[17]
Q. Chen, J. Huang, H. S. Salehi, H. Zhu, L. Lian, X. Lai, and K. Wei, “Hierarchical cnn-based occlusal surface morphology analysis for clas- sifying posterior tooth type using augmented images from 3d dental surface models,”Computer methods and programs in biomedicine, vol. 208, p. 106295, 2021
work page 2021
-
[18]
Toward clinically applicable 3-dimensional tooth segmentation via deep learning,
J. Hao, W. Liao, Y . Zhang, J. Peng, Z. Zhao, Z. Chen, B. Zhou, Y . Feng, B. Fang, Z. Liuet al., “Toward clinically applicable 3-dimensional tooth segmentation via deep learning,”Journal of dental research, vol. 101, no. 3, pp. 304–311, 2022
work page 2022
-
[19]
High-precision 3d teeth reconstruction based on five-view intra-oral photos,
Y . Wang, X. Sun, J. Jia, Z. Jin, and Y . Ma, “High-precision 3d teeth reconstruction based on five-view intra-oral photos,”Displays, vol. 87, p. 102988, 2025
work page 2025
-
[20]
C. Lian, L. Wang, T.-H. Wu, F. Wang, P.-T. Yap, C.-C. Ko, and D. Shen, “Deep multi-scale mesh feature learning for automated labeling of raw dental surfaces from 3d intraoral scanners,”IEEE transactions on medical imaging, vol. 39, no. 7, pp. 2440–2450, 2020
work page 2020
-
[21]
B. Beser, T. Reis, M. N. Berber, E. Topaloglu, E. Gungor, M. C. Kılıc, S. Duman, ¨O. C ¸ elik, A. Kuran, and I. S. Bayrakdar, “Yolo- v5 based deep learning approach for tooth detection and segmentation on pediatric panoramic radiographs in mixed dentition,”BMC medical imaging, vol. 24, no. 1, p. 172, 2024
work page 2024
-
[22]
Fully automated deep learning approach to dental development assessment in panoramic radiographs,
S.-H. Ong, H. Kim, J.-S. Song, T. J. Shin, H.-K. Hyun, K.-T. Jang, and Y .-J. Kim, “Fully automated deep learning approach to dental development assessment in panoramic radiographs,”BMC Oral Health, vol. 24, no. 1, p. 426, 2024
work page 2024
-
[23]
A fully automated method for 3d individual tooth identification and segmentation in dental cbct,
T. J. Jang, K. C. Kim, H. C. Cho, and J. K. Seo, “A fully automated method for 3d individual tooth identification and segmentation in dental cbct,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 10, pp. 6562–6568, 2021
work page 2021
-
[24]
A fully automatic ai system for tooth and alveolar bone segmentation from cone-beam ct images,
Z. Cui, Y . Fang, L. Mei, B. Zhang, B. Yu, J. Liu, C. Jiang, Y . Sun, L. Ma, J. Huanget al., “A fully automatic ai system for tooth and alveolar bone segmentation from cone-beam ct images,”Nature communications, vol. 13, no. 1, p. 2096, 2022
work page 2096
-
[25]
When 3d partial points meets sam: Tooth point cloud segmentation with sparse labels,
Y . Liu, W. Li, C. Wang, H. Chen, and Y . Yuan, “When 3d partial points meets sam: Tooth point cloud segmentation with sparse labels,” in International Conference on Medical Image Computing and Computer- Assisted Intervention. Springer, 2024, pp. 778–788
work page 2024
-
[26]
Z. Meng, J. Hao, X. Dai, Y . Feng, J. Liu, B. Feng, H. Wu, X. Gai, H. Zhu, T. Huet al., “Dentvlm: A multimodal vision-language model for comprehensive dental diagnosis and enhanced clinical practice,”arXiv preprint arXiv:2509.23344, 2025
-
[27]
Prompting vision-language models for dental notation aware abnormal- ity detection,
C. Du, X. Chen, J. Wang, J. Wang, Z. Li, Z. Zhang, and Q. Lao, “Prompting vision-language models for dental notation aware abnormal- ity detection,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 687–697
work page 2024
-
[28]
Benchmarking of large language models for the dental admission test,
Y . Hou, J. Patel, L. Dai, E. Zhang, Y . Liu, Z. Zhan, P. Gangwani, and R. Zhang, “Benchmarking of large language models for the dental admission test,”Health Data Science, vol. 5, p. 0250, 2025
work page 2025
-
[29]
Adapting sam2 model from natural images for tooth segmentation in dental panoramic x-ray images,
Z. Li, W. Tang, S. Gao, Y . Wang, and S. Wang, “Adapting sam2 model from natural images for tooth segmentation in dental panoramic x-ray images,”Entropy, vol. 26, no. 12, p. 1059, 2024
work page 2024
-
[30]
J. Hao, Y . Fan, Y . Sun, K. Guo, L. Lin, J. Yang, Q. Y . H. Ai, L. M. Wong, H. Tang, and K. F. Hung, “Towards better dental ai: A multimodal benchmark and instruction dataset for panoramic x-ray analysis,”arXiv preprint arXiv:2509.09254, 2025
-
[31]
High-precision teeth reconstruction based on automatic multimodal fusion with cbct and ios,
Z. Ren, L. Ma, M. Xu, G. Wei, S. Zhuang, and Y . Zhou, “High-precision teeth reconstruction based on automatic multimodal fusion with cbct and ios,”Computer Aided Geometric Design, vol. 111, p. 102299, 2024
work page 2024
-
[32]
Structure-aware 3d tooth modeling via prompt-guided segmentation and multi-view projection,
C. Wang, Y . Cai, R. Fan, and F. Liu, “Structure-aware 3d tooth modeling via prompt-guided segmentation and multi-view projection,”Processes, vol. 13, no. 7, p. 1968, 2025
work page 1968
-
[33]
Integrating ontologies and large language models to implement retrieval augmented genera- tion,
M. DeBellis, N. Dutta, J. Gino, and A. Balaji, “Integrating ontologies and large language models to implement retrieval augmented genera- tion,”Applied Ontology, vol. 19, no. 4, pp. 389–407, 2024
work page 2024
-
[34]
An ontology-based method for secondary use of electronic dental record data,
T. K. Schleyer, A. Ruttenberg, W. Duncan, M. Haendel, C. Torniai, A. Acharya, M. Song, T. P. Thyvalikakath, K. Liu, and P. Hernandez, “An ontology-based method for secondary use of electronic dental record data,”AMIA Summits on Translational Science Proceedings, vol. 2013, p. 234, 2013
work page 2013
-
[35]
A. Ayadi, K. Marzena, A. BLOCH-ZUPAN, C. Wemmertet al., “Ontology-guided prompting for reasoning in multimodal vision- language models: An application to rare dental disease,” inThe First Workshop on Multimodal Knowledge and Language Modeling
-
[36]
Development and comparative evaluation of a reinstructed gpt-4o model specialized in periodontology,
F. Fanelli, M. Saleh, P. Santamaria, K. Zhurakivska, L. Nibali, and G. Troiano, “Development and comparative evaluation of a reinstructed gpt-4o model specialized in periodontology,”Journal of Clinical Peri- odontology, vol. 52, no. 5, pp. 707–716, 2025
work page 2025
-
[37]
S. Wang, C. Lei, Y . Liang, J. Sun, X. Xie, Y . Wang, F. Zuo, Y . Bai, S. Li, and Y .-J. Liu, “A 3d dental model dataset with pre/post-orthodontic treatment for automatic tooth alignment [data set]. zenodo,” 2024
work page 2024
-
[38]
Ckd- tree: An improved kd-tree construction algorithm
Y . Narasimhulu, A. Suthar, R. Pasunuri, and C. V . Vadlamudi, “Ckd- tree: An improved kd-tree construction algorithm.” inISIC, 2021, pp. 211–218
work page 2021
-
[39]
Comparebench: A benchmark for visual comparison reasoning in vision-language models,
J. Cai, K. Yang, L. Fu, J. Ding, J. Li, H. Sun, D. Xing, J. Shen, and Z. Meng, “Comparebench: A benchmark for visual comparison reasoning in vision-language models,”arXiv preprint arXiv:2509.22737, 2025
-
[40]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Assessing and enhancing the reliability of chinese large language models in dental implantology,
G. Zhu, X. Zhang, and C. Chen, “Assessing and enhancing the reliability of chinese large language models in dental implantology,”BMC Oral Health, vol. 25, no. 1, p. 1242, 2025
work page 2025
-
[42]
Memorb: A plug-and-play verbal-reinforcement memory layer for e-commerce customer service,
Y . Huang, Y . Liu, R. Zhao, X. Zhong, X. Yue, and L. Jiang, “Memorb: A plug-and-play verbal-reinforcement memory layer for e-commerce customer service,”arXiv preprint arXiv:2509.18713, 2025. APPENDIX DENTALKNOWLEDGEBASE(DKB) Tooth Count (Deciduous vs Permanent) Deciduous dentition Deciduous dentition usually consists of 20 teeth, 10 in each arch. Each qu...
-
[43]
Therefore, no inference or completion of the opposite arch should be made
In all image analysis tasks, the provided image is known to contain either the upper or lower dentition only, not a full-mouth view. Therefore, no inference or completion of the opposite arch should be made
-
[44]
Theteeth_numberfield must strictly reflect the teeth actually visible in the image as the primary reference. Knowledge base information can be used for secondary validation only, and not for assumption-based estimation
-
[45]
If third molars (wisdom teeth) are not visible in the image, they must not be included in numbering or total tooth count
-
[46]
If teeth are missing due to extraction, congenital absence, or other causes, this must be recorded in theanomalies field, ensuring that numbering continuity is preserved
-
[47]
Dental Knowledge Base (DKB) used in our work
Dentition-stage classification should be based on eruption status, crown/root morphology, and developmental fea- tures, not merely tooth count. Dental Knowledge Base (DKB) used in our work
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.