From Per-Image Low-Rank to Encoding Mismatch: Rethinking Feature Distillation in Vision Transformers
Pith reviewed 2026-05-17 20:19 UTC · model grok-4.3
The pith
An encoding mismatch from per-image low-rank features and rotating dataset subspaces blocks feature-map distillation for compressing Vision Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sample-wise SVD shows each image is highly compressible, yet dataset-level PCA reveals the teacher as a union of low-rank subspaces with substantial rotation across inputs. Token-level spectral energy patterns further show tokens distribute energy broadly across channel modes even inside low-rank subspaces. The combined effect is an encoding mismatch that prevents a compressed student from matching the teacher under standard feature-map distillation. Two lightweight remedies, Lift (retaining a wider projector at inference) and WideLast (widening only the final student block), eliminate the mismatch and raise DeiT-Tiny accuracy from 74.86 percent to 77.53 percent or 78.23 percent when distil
What carries the argument
encoding mismatch: the joint phenomenon of per-image low-rank compressibility, dataset-level subspace rotations, and broad token spectral energy patterns that together produce a channel-bandwidth mismatch for feature-map distillation.
If this is right
- Feature-map distillation regains effectiveness for ViT compression once the encoding mismatch is removed.
- Lift keeps a lightweight wider projector at test time while WideLast expands only the student's last block.
- The same fixes also improve students trained from scratch without any distillation.
- The mismatch accounts for why distillation works between equal-sized models but fails under compression.
Where Pith is reading between the lines
- Architectures that already widen their final layers may suffer less from the same mismatch when used as students.
- The subspace-rotation view suggests that input-dependent or conditional projectors could be explored beyond the two minimal fixes.
- Similar per-image versus dataset-level rank discrepancies might appear in other modalities or tasks where feature alignment is attempted.
Load-bearing premise
The per-image low-rank structure, dataset subspace rotations, and token spectral energy patterns are the main causal drivers of distillation failure rather than optimization or capacity limits.
What would settle it
Train a standard narrow student whose final projector is forced to match the teacher's observed subspace rotations and spectral energy distribution on the same data; if accuracy gains disappear without Lift or WideLast, the mismatch explanation is supported.
Figures
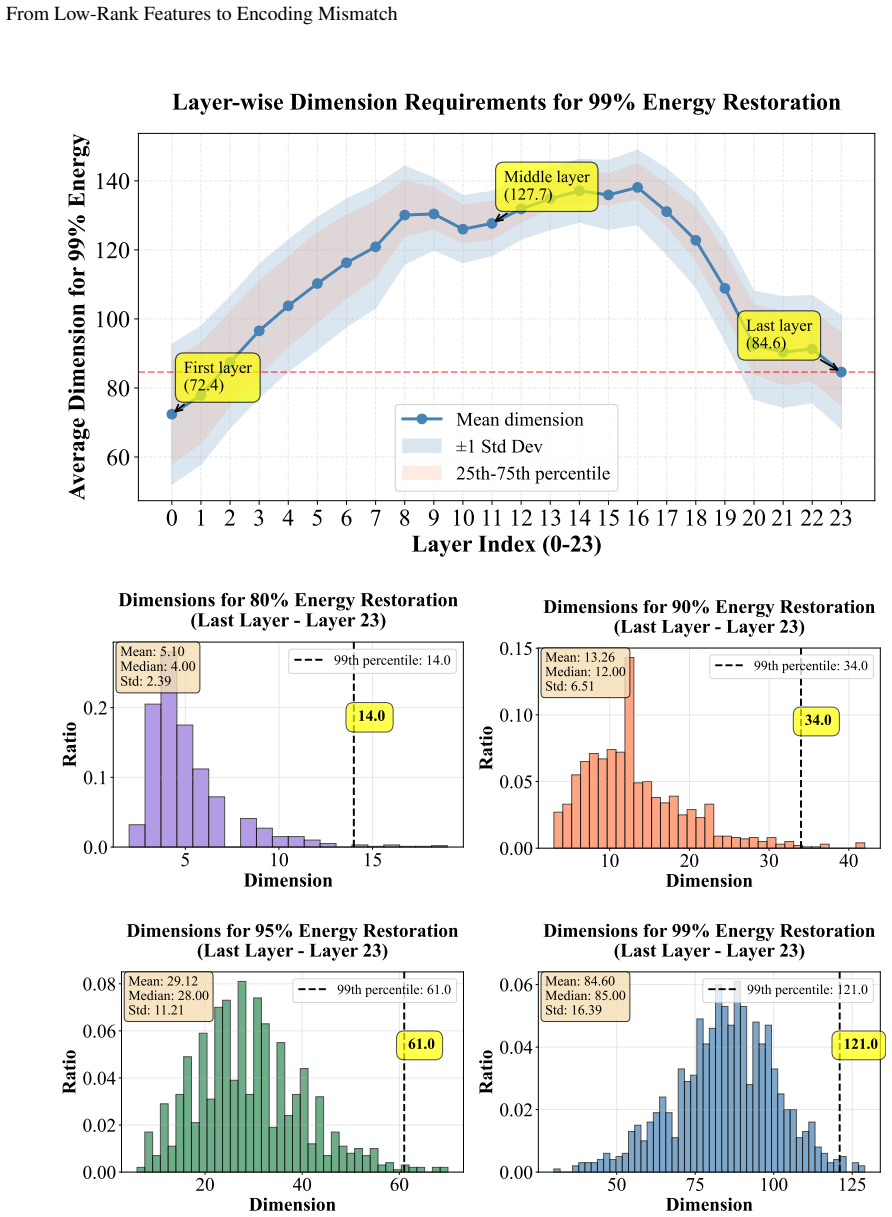
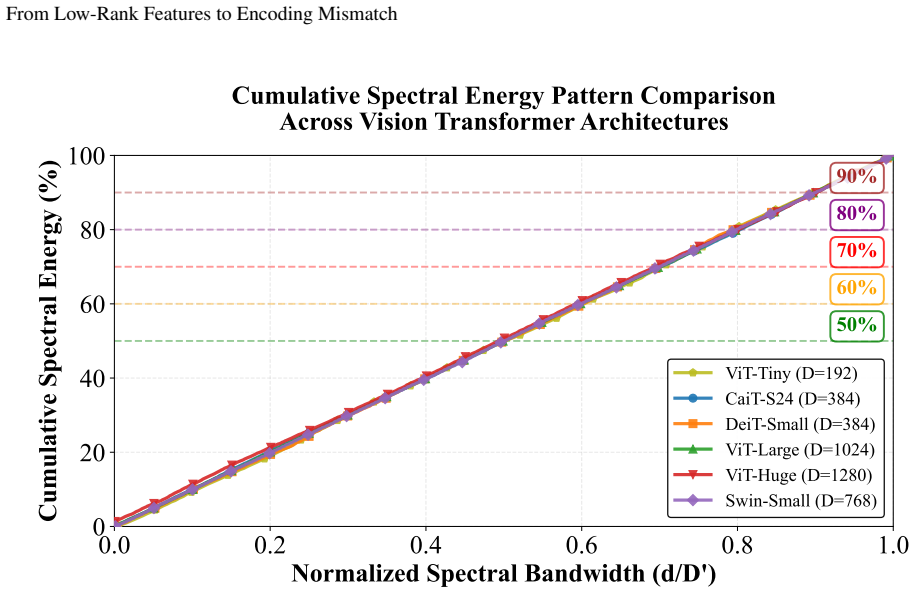






read the original abstract
Feature-map knowledge distillation (KD) transfers internal representations well between comparably sized Vision Transformers (ViTs), but it often fails in compression. We revisit this failure and uncover a paradox. Sample-wise SVD shows that each image is highly compressible, which seems to suggest that a narrow student with a linear projector should match the teacher "in principle". However, a dataset-level view contradicts this intuition: PCA shows that the teacher is a union of low-rank subspaces with significant subspace rotation across inputs. We further introduce token-level Spectral Energy Patterns (SEP) and find an architecture-invariant encoding law: tokens spread energy broadly across channel modes even when they live in low-rank subspace, creating a bandwidth mismatch. We refer to this combined phenomenon as an encoding mismatch. We propose two minimal remedies, Lift or WideLast: (i) Lift retains a lightweight lifting projector at inference to provide wider channel, or (ii) WideLast widens only the student's last block, enabling an input-dependent expansion. On ImageNet-1K, these fixes revive feature KD for ViT compression, improving DeiT-Tiny distilled from CaiT-S24 from 74.86% to 77.53%/78.23% top-1 accuracy, and they also strengthen students trained without distillation. Our analyses clarify when and why feature-map KD fails and then how to fix it. Code and raw data are provided in the supplementary materials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that feature-map knowledge distillation fails for ViT compression due to an 'encoding mismatch': per-image SVD shows low-rank structure (suggesting narrow students should suffice), but dataset-level PCA reveals subspace rotations across inputs, and token-level Spectral Energy Patterns (SEP) show broad energy distribution across channel modes despite low-rank subspaces. This mismatch explains KD underperformance. Two minimal fixes are proposed—Lift (retaining a lightweight projector at inference for wider channels) and WideLast (widening only the final student block for input-dependent expansion). On ImageNet-1K, these revive KD, e.g., improving DeiT-Tiny distilled from CaiT-S24 from 74.86% to 77.53%/78.23% top-1 accuracy, with gains also for non-distilled students. Code and raw data are released.
Significance. If the analyses establish causality and the remedies are shown to target the mismatch rather than add capacity, the work clarifies a key limitation in feature KD for ViT compression and provides simple, practical architectural adjustments. Credit is due for releasing code and raw data, enabling reproducibility. The application of SVD/PCA/SEP to diagnose KD behavior is a clear contribution, though the central claim hinges on linking the observations directly to the proposed fixes.
major comments (1)
- [Experiments section] Experiments section (ImageNet-1K results and Table reporting 74.86% → 77.53%/78.23% gains): the manuscript does not report subspace rotation angles or SEP bandwidth metrics for the Lift/WideLast students on the same teacher-student pairs before and after modification. Without this, the accuracy improvements cannot be unambiguously attributed to resolution of the encoding mismatch rather than increased effective capacity, weakening the causal claim for the remedies.
minor comments (2)
- [Abstract] Abstract: the introduction of 'Spectral Energy Patterns (SEP)' and 'encoding mismatch' would benefit from a one-sentence definition to aid readers before the detailed sections.
- Notation: ensure consistent use of 'channel modes' versus 'feature dimensions' when describing SEP across sections to avoid minor ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript to incorporate the requested analysis.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (ImageNet-1K results and Table reporting 74.86% → 77.53%/78.23% gains): the manuscript does not report subspace rotation angles or SEP bandwidth metrics for the Lift/WideLast students on the same teacher-student pairs before and after modification. Without this, the accuracy improvements cannot be unambiguously attributed to resolution of the encoding mismatch rather than increased effective capacity, weakening the causal claim for the remedies.
Authors: We agree that the manuscript currently does not report subspace rotation angles or SEP bandwidth metrics for the Lift and WideLast variants. To strengthen the causal attribution of the accuracy gains to resolution of the encoding mismatch (rather than capacity increase alone), we will compute and add these metrics for the modified students on the same teacher-student pairs in the revised manuscript, enabling direct before-and-after comparison. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central claims rest on empirical observations obtained by applying standard linear-algebra operations (sample-wise SVD, dataset-level PCA, and token-level spectral energy patterns) to extracted feature maps. These observations are then used to motivate the architectural remedies Lift and WideLast, whose effects are measured on held-out ImageNet-1K validation data. No equation or derivation reduces by construction to a fitted parameter, self-citation, or renamed input; the analysis remains externally falsifiable and does not rely on load-bearing self-references.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Singular value decomposition and principal component analysis can be used to characterize rank and subspace structure of feature maps
- domain assumption Feature-map knowledge distillation transfers internal representations between teacher and student Vision Transformers
invented entities (2)
-
encoding mismatch
no independent evidence
-
Spectral Energy Patterns (SEP)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Attention Transfer Is Not Universally Effective for Vision Transformers
Attention transfer from ViT teachers succeeds for only 7 of 11 families and fails for the rest because of architectural mismatch between teacher and student.
Reference graph
Works this paper leans on
-
[1]
Going deeper with image transformers
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 32–42, October 2021
work page 2021
-
[2]
Distilling the knowledge in a neural network, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network, 2015
work page 2015
-
[3]
Tejalal Choudhary, Vipul Mishra, Anurag Goswami, and Jagannathan Sarangapani. A comprehensive survey on model compression and acceleration.Artificial Intelligence Review, 53:5113–5155, 2020. 11 From Low-Rank Features to Encoding Mismatch
work page 2020
-
[4]
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. A survey on model compression for large language models.Transactions of the Association for Computational Linguistics, 12:1556–1577, 2024
work page 2024
-
[5]
Qianhan Feng, Wenshuo Li, Tong Lin, and Xinghao Chen. Align-kd: Distilling cross-modal alignment knowledge for mobile vision-language large model enhancement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4178–4188, June 2025
work page 2025
-
[6]
Backpropagation applied to handwritten zip code recognition.Neural computation, 1(4):541– 551, 1989
Yann LeCun, Bernhard Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne Hubbard, and Lawrence D Jackel. Backpropagation applied to handwritten zip code recognition.Neural computation, 1(4):541– 551, 1989
work page 1989
-
[7]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
work page 2012
-
[8]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[9]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA, 2017. Curran Associates Inc
work page 2017
-
[10]
Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, 2020
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, 2020
work page 2020
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[12]
Logit standardization in knowledge distillation
Shangquan Sun, Wenqi Ren, Jingzhi Li, Rui Wang, and Xiaochun Cao. Logit standardization in knowledge distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15731–15740, 2024
work page 2024
-
[13]
Fitnets: Hints for thin deep nets, 2015
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets, 2015
work page 2015
-
[14]
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning
Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4133–4141, 2017
work page 2017
-
[15]
Sergey Zagoruyko and Nikos Komodakis. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. InInternational Conference on Learning Representations, 2017
work page 2017
-
[16]
A comprehensive overhaul of feature distillation
Byeongho Heo, Jeesoo Kim, Sangdoo Yun, Hyojin Park, Nojun Kwak, and Jin Young Choi. A comprehensive overhaul of feature distillation. InProceedings of the IEEE/CVF international conference on computer vision, pages 1921–1930, 2019
work page 1921
-
[17]
Distilling knowledge via knowledge review
Pengguang Chen, Shu Liu, Hengshuang Zhao, and Jiaya Jia. Distilling knowledge via knowledge review. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5008–5017, June 2021
work page 2021
-
[18]
Mingi Ji, Byeongho Heo, and Sungrae Park. Show, attend and distill: Knowledge distillation via attention-based feature matching.Proceedings of the AAAI Conference on Artificial Intelligence, 35(9):7945–7952, May 2021
work page 2021
-
[19]
Frequency attention for knowledge distillation
Cuong Pham, Van-Anh Nguyen, Trung Le, Dinh Phung, Gustavo Carneiro, and Thanh-Toan Do. Frequency attention for knowledge distillation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2277–2286, 2024
work page 2024
-
[20]
Tinybert: Distilling bert for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. InFindings of the association for computational linguistics: EMNLP 2020, pages 4163–4174, 2020
work page 2020
-
[21]
Relational knowledge distillation
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. Relational knowledge distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3967–3976, 2019
work page 2019
-
[22]
Decoupled knowledge distillation
Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11953–11962, 2022
work page 2022
-
[23]
Zhendong Yang, Ailing Zeng, Zhe Li, Tianke Zhang, Chun Yuan, and Yu Li. From knowledge distillation to self-knowledge distillation: A unified approach with normalized loss and customized soft labels. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17185–17194, 2023. 12 From Low-Rank Features to Encoding Mismatch
work page 2023
-
[24]
DetKDS: Knowledge distillation search for object detectors
Lujun Li, Yufan Bao, Peijie Dong, Chuanguang Yang, Anggeng Li, Wenhan Luo, Qifeng Liu, Wei Xue, and Yike Guo. DetKDS: Knowledge distillation search for object detectors. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[25]
The role of masking for efficient supervised knowledge distillation of vision transformers
Seungwoo Son, Jegwang Ryu, Namhoon Lee, and Jaeho Lee. The role of masking for efficient supervised knowledge distillation of vision transformers. InEuropean Conference on Computer Vision, pages 379–396. Springer, 2025
work page 2025
-
[26]
DistiLLM: Towards streamlined distillation for large language models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. DistiLLM: Towards streamlined distillation for large language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[27]
DistiLLM-2: A contrastive approach boosts the distillation of LLMs
Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se-Young Yun. DistiLLM-2: A contrastive approach boosts the distillation of LLMs. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[28]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[29]
Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, et al. A survey on vision transformer.IEEE transactions on pattern analysis and machine intelligence, 45(1):87–110, 2022
work page 2022
-
[30]
Xiangtai Li, Henghui Ding, Haobo Yuan, Wenwei Zhang, Jiangmiao Pang, Guangliang Cheng, Kai Chen, Ziwei Liu, and Chen Change Loy. Transformer-based visual segmentation: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[31]
Vitkd: Feature-based knowledge distillation for vision transformers
Zhendong Yang, Zhe Li, Ailing Zeng, Zexian Li, Chun Yuan, and Yu Li. Vitkd: Feature-based knowledge distillation for vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 1379–1388, June 2024
work page 2024
-
[32]
Roy Miles and Krystian Mikolajczyk. Understanding the role of the projector in knowledge distillation.Proceed- ings of the AAAI Conference on Artificial Intelligence, 38(5):4233–4241, Mar. 2024
work page 2024
-
[33]
Vkd: Improving knowledge distillation using orthogonal projections
Roy Miles, Ismail Elezi, and Jiankang Deng. Vkd: Improving knowledge distillation using orthogonal projections. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15720–15730, 2024
work page 2024
-
[34]
Huiyuan Tian, Bonan Xu, Shijian Li, and Gang Pan. Spectralkd: A unified framework for interpreting and distilling vision transformers via spectral analysis, 2025
work page 2025
-
[35]
Distillation dynamics: Towards understanding feature-based distillation in vision transformers, 2025
Huiyuan Tian and Bonan Xu Shijian Li. Distillation dynamics: Towards understanding feature-based distillation in vision transformers, 2025
work page 2025
-
[36]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers & distillation through attention. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 10...
work page 2021
-
[37]
Minivit: Compressing vision transformers with weight multiplexing
Jinnian Zhang, Houwen Peng, Kan Wu, Mengchen Liu, Bin Xiao, Jianlong Fu, and Lu Yuan. Minivit: Compressing vision transformers with weight multiplexing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12145–12154, 2022
work page 2022
-
[38]
Learning efficient vision transformers via fine-grained manifold distillation
Zhiwei Hao, Jianyuan Guo, Ding Jia, Kai Han, Yehui Tang, Chao Zhang, Han Hu, and Yunhe Wang. Learning efficient vision transformers via fine-grained manifold distillation. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 9164–9175. Curran Associates, Inc., 2022
work page 2022
-
[39]
Scalekd: Strong vision transformers could be excellent teachers
Jiawei Fan, Chao Li, Xiaolong Liu, and Anbang Yao. Scalekd: Strong vision transformers could be excellent teachers. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 63290–63315. Curran Associates, Inc., 2024
work page 2024
-
[40]
Contrastive representation distillation
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representation distillation. InInternational Conference on Learning Representations, 2020
work page 2020
-
[41]
Tinyvit: Fast pretraining distillation for small vision transformers
Kan Wu, Jinnian Zhang, Houwen Peng, Mengchen Liu, Bin Xiao, Jianlong Fu, and Lu Yuan. Tinyvit: Fast pretraining distillation for small vision transformers. InEuropean conference on computer vision, pages 68–85. Springer, 2022. 13 From Low-Rank Features to Encoding Mismatch
work page 2022
-
[42]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In2007 15th European signal processing conference, pages 606–610. IEEE, 2007
work page 2007
- [43]
-
[44]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
- [45]
-
[46]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[47]
SGDR: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. InInternational Conference on Learning Representations, 2017
work page 2017
-
[48]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019. 14 From Low-Rank Features to Encoding Mismatch A Additional SVD Analysis A...
work page 2019
-
[49]
Earlier stages exhibit the same “rise-and-fall” pattern as depth increases within the hierarchy. These results show that global low-rank structure is not restricted to plain ViTs, but also appears in windowed/hierarchical transformers. ViT-Huge, ViT-Large, and ViT-Tiny. Figure 5–7 provide analogous SVD diagnostics for ViT-Huge (MAE pre-trained), ViT-Large...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.