The Spheres Dataset: Multitrack Orchestral Recordings for Music Source Separation and Information Retrieval
Pith reviewed 2026-05-17 05:00 UTC · model grok-4.3
The pith
The Spheres dataset supplies multitrack orchestral recordings with isolated stems and room impulse responses for classical music source separation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
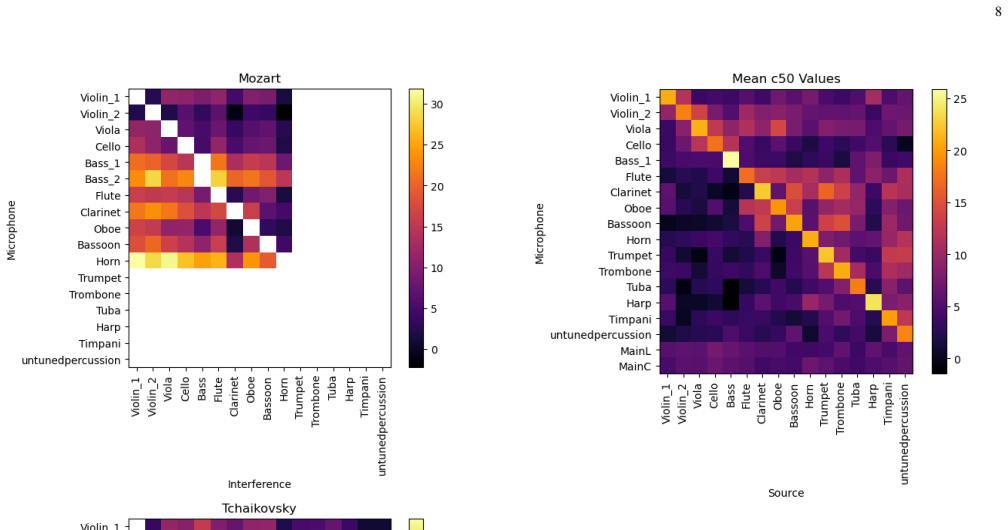
The Spheres dataset consists of over one hour of multitrack recordings of Tchaikovsky's Romeo and Juliet and Mozart's Symphony No. 40 performed by the Colibrì Ensemble, together with chromatic scales and solo excerpts for each instrument, captured via a 23-microphone array that yields realistic stereo mixes with controlled bleeding and isolated stems for supervised training of source separation models, along with estimated room impulse responses for acoustic characterization of the space.
What carries the argument
The 23-microphone array of close spot, main, and ambient microphones that produces both isolated instrument stems and realistic mixes with controlled bleeding.
If this is right
- Isolated stems enable supervised training of models that separate orchestral instrument families.
- Controlled bleeding in the mixes allows direct evaluation of microphone debleeding methods.
- Room impulse responses support studies of dereverberation and immersive audio rendering.
- Baseline results with X-UMX models establish initial benchmarks while exposing challenges in dense orchestral textures.
Where Pith is reading between the lines
- Models trained here could serve as a starting point for separation in live concert settings if studio and hall acoustics prove similar.
- Adding recordings from additional ensembles and venues would be a direct way to test and improve generalization.
- The multi-microphone layout may also aid research on instrument localization within the same recordings.
Load-bearing premise
Recordings from one ensemble in one studio with this fixed microphone setup produce data that generalizes to other orchestras, halls, and recording conditions.
What would settle it
Source separation models trained solely on this dataset would show markedly lower performance when tested on orchestral recordings made in different halls or with different ensembles.
Figures










read the original abstract
This paper introduces The Spheres dataset, multitrack orchestral recordings designed to advance machine learning research in music source separation and related MIR tasks within the classical music domain. The dataset is composed of over one hour recordings of musical pieces performed by the Colibr\`i Ensemble at The Spheres recording studio, capturing two canonical works - Tchaikovsky's Romeo and Juliet and Mozart's Symphony No. 40 - along with chromatic scales and solo excerpts for each instrument. The recording setup employed 23 microphones, including close spot, main, and ambient microphones, enabling the creation of realistic stereo mixes with controlled bleeding and providing isolated stems for supervised training of source separation models. In addition, room impulse responses were estimated for each instrument position, offering valuable acoustic characterization of the recording space. We present the dataset structure, acoustic analysis, and baseline evaluations using X-UMX based models for orchestral family separation and microphone debleeding. Results highlight both the potential and the challenges of source separation in complex orchestral scenarios, underscoring the dataset's value for benchmarking and for exploring new approaches to separation, localization, dereverberation, and immersive rendering of classical music.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces The Spheres dataset, consisting of over one hour of multitrack orchestral recordings of Tchaikovsky's Romeo and Juliet and Mozart's Symphony No. 40 performed by the Colibrì Ensemble at The Spheres studio. It uses a 23-microphone setup (close spot, main, and ambient) to capture isolated stems with controlled bleeding for realistic mixes, along with chromatic scales, solo excerpts, and estimated room impulse responses for each instrument position. The manuscript describes the dataset structure, provides acoustic analysis, and reports baseline evaluations using X-UMX models for orchestral family separation and microphone debleeding.
Significance. If released with complete documentation and access, this dataset would address an important gap in publicly available multitrack resources for classical orchestral music, enabling supervised training of source separation models in a domain where such data is scarce. The inclusion of RIRs and controlled bleeding setups supports additional research on acoustic characterization, dereverberation, localization, and immersive rendering. The baseline results usefully illustrate both the applicability and the remaining challenges of separation in dense orchestral textures.
major comments (1)
- [Recording setup] Recording setup section: the description of how isolated stems are derived from the 23-microphone multitrack and the precise post-processing steps used to create controlled bleeding should be expanded with quantitative details (e.g., bleed levels, microphone distances) so that users can replicate the acoustic conditions for new experiments.
minor comments (2)
- [Abstract] Abstract: adding one or two concrete quantitative results (e.g., SDR or SI-SDR values from the X-UMX baselines) would better substantiate the stated 'potential and challenges'.
- [Dataset structure] Dataset structure: explicitly state total duration per work, sampling rate, bit depth, and file formats for all stems and RIRs to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive recommendation. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Recording setup] Recording setup section: the description of how isolated stems are derived from the 23-microphone multitrack and the precise post-processing steps used to create controlled bleeding should be expanded with quantitative details (e.g., bleed levels, microphone distances) so that users can replicate the acoustic conditions for new experiments.
Authors: We agree with the referee that expanding the Recording Setup section with quantitative details will improve the utility and reproducibility of the dataset. In the revised version of the manuscript, we will include specific microphone distances (e.g., spot mics at 0.5-1m from instruments), measured bleed levels in dB between adjacent stems, and a step-by-step description of the post-processing pipeline used to create the controlled bleeding mixes. These details are available from our recording session logs and will be presented in a new table or subsection for clarity. revision: yes
Circularity Check
No significant circularity in dataset release paper
full rationale
The paper is a data collection and release contribution describing recordings of two orchestral works with a 23-microphone setup, isolated stems, and room impulse responses, plus baseline evaluations on existing X-UMX models. No equations, derivations, or fitted parameters are presented that reduce any reported result to quantities defined or fitted from the same data by construction. The central claims rest on the concrete recording protocol and external model baselines rather than self-referential steps, self-citations as load-bearing premises, or ansatzes smuggled through prior work. This matches the expected honest non-finding for a resource paper whose value is the new data itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard acoustic measurement techniques can produce usable room impulse responses from the chosen microphone positions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The dataset is composed of over one hour recordings... 23 microphones... room impulse responses were estimated... baseline evaluations using X-UMX based models for orchestral family separation and microphone debleeding.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B
Z. Rafii, A. Liutkus, F.-R. St ¨oter, S. I. Mimilakis, and R. Bittner, “MUSDB18-HQ - an uncompressed version of musdb18,” Dec. 2019. [Online]. Available: https://doi.org/10.5281/zenodo.3338373
-
[2]
Music demixing challenge 2021,
Y . Mitsufuji, G. Fabbro, S. Uhlich, F.-R. St ¨oter, A. D ´efossez, M. Kim, W. Choi, C.-Y . Yu, and K.-W. Cheuk, “Music demixing challenge 2021,” Frontiers in Signal Processing, vol. 1, p. 808395, 2022
work page 2021
-
[3]
The sound demixing challenge 2023 – music demixing track,
G. Fabbro, S. Uhlich, C.-H. Lai, W. Choi, M. Mart ´ınez-Ram´ırez, W. Liao, I. Gadelha, G. Ramos, E. Hsu, H. Rodrigues, F.-R. St ¨oter, A. D ´efossez, Y . Luo, J. Yu, D. Chakraborty, S. Mohanty, R. Solovyev, A. Stempkovskiy, T. Habruseva, N. Goswami, T. Harada, M. Kim, J. Hyung Lee, Y . Dong, X. Zhang, J. Liu, and Y . Mitsufuji, “The sound demixing challen...
work page 2023
-
[4]
Musical source separation: An introduction,
E. Cano, D. FitzGerald, A. Liutkus, M. D. Plumbley, and F.-R. St ¨oter, “Musical source separation: An introduction,”IEEE Signal Processing Magazine, vol. 36, no. 1, pp. 31–40, 2019
work page 2019
-
[5]
M. Vinyes, “MTG MASS database. [Online].” http://www.mtg.upf.edu/static/mass/resources, 2008
work page 2008
-
[6]
Medleydb 2.0: New data and a system for sustainable data collection,
R. M. Bittner, J. Wilkins, H. Yip, and J. P. Bello, “Medleydb 2.0: New data and a system for sustainable data collection,”ISMIR Late Breaking and Demo Papers, vol. 36, 2016
work page 2016
-
[7]
E. Manilow, G. Wichern, P. Seetharaman, and J. Le Roux, “Cutting music source separation some Slakh: A dataset to study the impact of training data quality and quantity,” inProc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2019
work page 2019
-
[8]
Piano concerto dataset (pcd): A multitrack dataset of piano concertos,
Y . ¨Ozer, S. J. Schw ¨ar, V . Arifi-M ¨uller, J. Lawrence, E. Sen, and M. M ¨uller, “Piano concerto dataset (pcd): A multitrack dataset of piano concertos,”Transactions of the International Society for Music Information Retrieval, vol. 6, no. 1, pp. 75–88, 2023
work page 2023
-
[9]
Music source separation in the waveform domain
A. D ´efossez, N. Usunier, L. Bottou, and F. Bach, “Music source separation in the waveform domain,”arXiv preprint arXiv:1911.13254, 2019
-
[10]
Spleeter: a fast and efficient music source separation tool with pre-trained models,
R. Hennequin, A. Khlif, F. V oituret, and M. Moussallam, “Spleeter: a fast and efficient music source separation tool with pre-trained models,” Journal of Open Source Software, vol. 5, no. 50, p. 2154, 2020
work page 2020
-
[11]
Hybrid spectrogram and waveform source separation,
A. D ´efossez, “Hybrid spectrogram and waveform source separation,” in Proceedings of the ISMIR 2021 Workshop on Music Source Separation, 2021
work page 2021
-
[12]
Hybrid transformers for music source separation,
S. Rouard, F. Massa, and A. D ´efossez, “Hybrid transformers for music source separation,” inICASSP 2023 - 2023 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
work page 2023
-
[13]
Music source separation with band-split rnn,
Y . Luo and J. Yu, “Music source separation with band-split rnn,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1893–1901, 2023
work page 1901
-
[14]
Scnet: Sparse compression network for music source separation,
W. Tong, J. Zhu, J. Chen, S. Kang, T. Jiang, Y . Li, Z. Wu, and H. Meng, “Scnet: Sparse compression network for music source separation,” in ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 1276–1280
work page 2024
-
[15]
Music source sepa- ration with band-split rope transformer,
W.-T. Lu, J.-C. Wang, Q. Kong, and Y .-N. Hung, “Music source sepa- ration with band-split rope transformer,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 481–485
work page 2024
-
[16]
Monaural score-informed source separation for classical music using convolutional neural networks,
M. Miron, J. Janer, and E. G ´omez, “Monaural score-informed source separation for classical music using convolutional neural networks,” in Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR), 2017, pp. 55–62
work page 2017
-
[17]
Conditioned source separa- tion for musical instrument performances,
O. Slizovskaia, G. Haro, and E. G ´omez, “Conditioned source separa- tion for musical instrument performances,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 2083–2095, 2021
work page 2083
-
[18]
Source separation of piano concertos using musically motivated augmentation techniques,
Y . ¨Ozer and M. M ¨uller, “Source separation of piano concertos using musically motivated augmentation techniques,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1214–1225, 2024
work page 2024
-
[19]
Synthsod: Developing an heteroge- neous dataset for orchestra music source separation,
J. Garcia-Martinez, D. Diaz-Guerra, A. Politis, T. Virtanen, J. J. Carabias-Orti, and P. Vera-Candeas, “Synthsod: Developing an heteroge- neous dataset for orchestra music source separation,”IEEE Open Journal of Signal Processing, vol. 6, pp. 129–137, 2025
work page 2025
-
[20]
J. Fritsch, “The trios dataset,” Jul. 2022. [Online]. Available: https://doi.org/10.5281/zenodo.6797837
-
[21]
Soundprism: an online system for score- informed source separation of music audio,
Z. Duan and B. Pardo, “Soundprism: an online system for score- informed source separation of music audio,”IEEE Journal of Selected Topics in Signal Process., vol. 5, no. 6, pp. 1205–1215, 2011
work page 2011
-
[22]
B. Li, X. Liu, K. Dinesh, Z. Duan, and G. Sharma, “Creating a multitrack classical music performance dataset for multimodal music analysis: Challenges, insights, and applications,”IEEE Transactions on Multimedia, vol. 21, no. 2, pp. 522–535, 2019
work page 2019
-
[23]
Anechoic recording system for symphony orchestra,
J. P ¨atynen, V . Pulkki, and T. Lokki, “Anechoic recording system for symphony orchestra,”Acta Acustica united with Acustica, vol. 94, pp. 856–865, 11 2008
work page 2008
-
[24]
Kollektion: Operation beethoven. beethovens 4. sinfonie in einzelstimmen!
U. Kaiser, I. Mestemacher, and M. Vieregg, “Kollektion: Operation beethoven. beethovens 4. sinfonie in einzelstimmen!”[Online]. Available: https://openmusic.academy/docs/4HAB9wcKyiXNGNsmkEFRXD/operation- beethoven-kooperation-der-open-music-academy-mit-der-hofkapelle- muenchen, 2023
work page 2023
-
[25]
Mixing-specific data augmentation techniques for improved blind vio- lin/piano source separation,
C.-Y . Chiu, W.-Y . Hsiao, Y .-C. Yeh, Y .-H. Yang, and A. W.-Y . Su, “Mixing-specific data augmentation techniques for improved blind vio- lin/piano source separation,” in2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP). IEEE, 2020, pp. 1–6
work page 2020
-
[26]
A study of audio mixing methods for piano transcription in violin-piano ensembles,
H. Kim, J. Park, T. Kwon, D. Jeong, and J. Nam, “A study of audio mixing methods for piano transcription in violin-piano ensembles,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
work page 2023
-
[27]
Generating data to train convolutional neural networks for classical music source separation,
M. Miron, J. Janer Mestres, and E. G ´omez Guti ´errez, “Generating data to train convolutional neural networks for classical music source separation,” inProceedings of the 14th Sound and Music Computing Conference, 2017, pp. p. 227–33
work page 2017
-
[28]
E. Tunturi, D. Diaz-Guerra, A. Politis, and T. Virtanen, “Score-informed music source separation: Improving synthetic-to- real generalization in classical music,” 2025. [Online]. Available: https://arxiv.org/abs/2503.07352
-
[29]
Hierarchical musical instru- ment separation,
E. Manilow, G. Wichern, and J. L. Roux, “Hierarchical musical instru- ment separation,” inProceedings of the 21st International Conference on Music Information Retrieval, ISMIR 2020, 2020, pp. 376–383. 13
work page 2020
-
[30]
Leveraging syn- thetic data for improving chamber ensemble separation,
S. Sarkar, L. Thorpe, E. Benetos, and M. Sandler, “Leveraging syn- thetic data for improving chamber ensemble separation,” in2023 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2023, pp. 1–5
work page 2023
-
[31]
All for one and one for all: Improving music separation by bridging networks,
R. Sawata, S. Uhlich, S. Takahashi, and Y . Mitsufuji, “All for one and one for all: Improving music separation by bridging networks,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 51–55
work page 2021
-
[32]
G. Roa Dabike, T. J. Cox, A. J. Miller, B. M. Fazenda, S. Graetzer, R. R. V os, M. A. Akeroyd, J. Firth, W. M. Whitmer, S. Bannister, A. Greasley, and J. P. Barker, “The cadenza woodwind dataset: Synthesised quartets for music information retrieval and machine learning,”Data in Brief, vol. 57, p. 111199, 2024. [Online]. Available: https://www.sciencedirec...
work page 2024
-
[33]
Tchaikovsky, Romeo and Juliet, Leonard Bernstein, New York Philharmonic
Lennyforever. Tchaikovsky, Romeo and Juliet, Leonard Bernstein, New York Philharmonic. [Online]. Available: https://www.youtube.com/watch?v=BSbzyTNVB1Q
- [34]
-
[35]
Advancements in impulse response measurements by sine sweeps,
farina angelo, “Advancements in impulse response measurements by sine sweeps,”journal of the audio engineering society, no. 7121, may 2007
work page 2007
-
[36]
Acoustics – measurement of room acoustic parameters – part 1: Performance spaces,
I. 3382-1:2009, “Acoustics – measurement of room acoustic parameters – part 1: Performance spaces,” International Organization for Standard- ization, Geneva, Switzerland, Standard ISO 3382-1:2009, 2009
work page 2009
-
[37]
Why does music source separation benefit from cacophony?
C.-B. Jeon, G. Wichern, F. G. Germain, and J. Le Roux, “Why does music source separation benefit from cacophony?” in2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW). IEEE, 2024, pp. 873–877
work page 2024
-
[38]
Open-unmix-a reference implementation for music source separation,
F.-R. St ¨oter, S. Uhlich, A. Liutkus, and Y . Mitsufuji, “Open-unmix-a reference implementation for music source separation,”Journal of Open Source Software, vol. 4, no. 41, p. 1667, 2019
work page 2019
-
[39]
Asteroid: the PyTorch-based audio source separation toolkit for researchers,
M. Pariente, S. Cornell, J. Cosentino, S. Sivasankaran, E. Tzinis, J. Heitkaemper, M. Olvera, F.-R. St ¨oter, M. Hu, J. M. Mart ´ın-Do˜nas, D. Ditter, A. Frank, A. Deleforge, and E. Vincent, “Asteroid: the PyTorch-based audio source separation toolkit for researchers,” inIn- terspeech 2020, Shanghai, China, 2020
work page 2020
-
[40]
F.-R. St ¨oter and A. Liutkus, “museval 0.3.0,” Aug. 2019. [Online]. Available: https://doi.org/10.5281/zenodo.3376621
-
[41]
J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “Sdr–half-baked or well done?” inICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626–630
work page 2019
-
[42]
Performance measurement in blind audio source separation,
E. Vincent, R. Gribonval, and C. F ´evotte, “Performance measurement in blind audio source separation,”IEEE transactions on audio, speech, and language processing, vol. 14, no. 4, pp. 1462–1469, 2006
work page 2006
-
[43]
Using an exponential sine sweep to measure 3d printed vocal tract resonances,
B. Delvaux and D. M. Howard, “Using an exponential sine sweep to measure 3d printed vocal tract resonances,” inThe 21st International COngress on Sound and Vibration, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:55646202
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.