We Still Don't Understand High-Dimensional Bayesian Optimization
Pith reviewed 2026-05-17 03:21 UTC · model grok-4.3
The pith
Simple linear models match state-of-the-art performance in high-dimensional Bayesian optimization after a geometric fix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
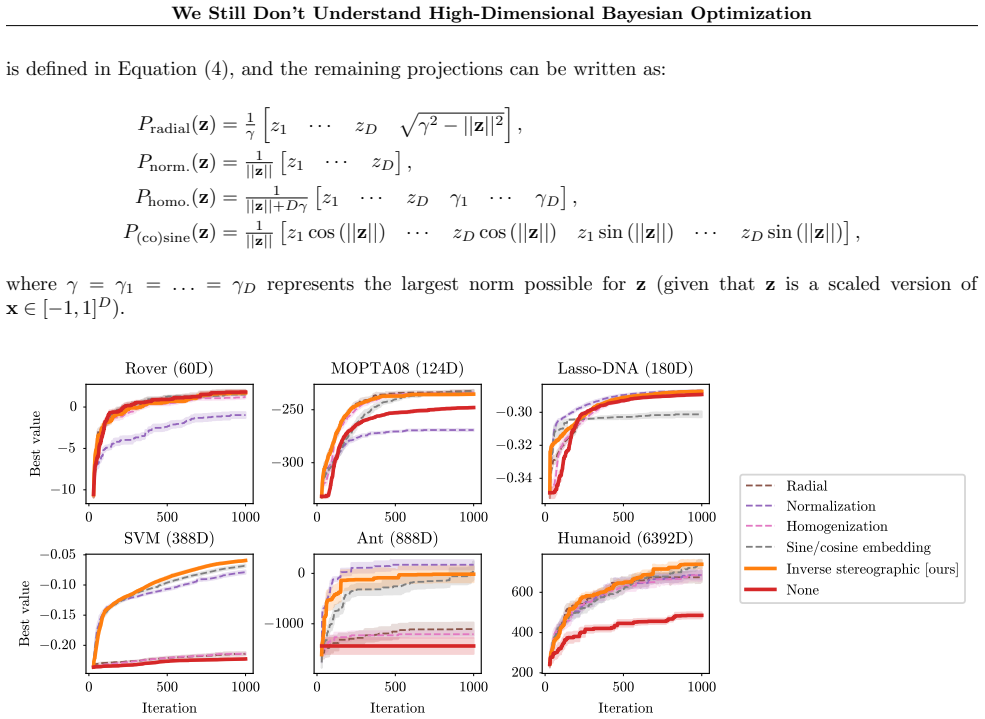
Existing high-dimensional Bayesian optimization methods aim to overcome the curse of dimensionality by carefully encoding structural assumptions, from locality to sparsity to smoothness, into the optimization procedure. Surprisingly, these approaches are outperformed by arguably the simplest method imaginable: Bayesian linear regression. After applying a geometric transformation to avoid boundary-seeking behavior, Gaussian processes with linear kernels match state-of-the-art performance on tasks with 60- to 6,000-dimensional search spaces. Linear models offer numerous advantages over their non-parametric counterparts: they afford closed-form sampling and their computation scales linearly, a
What carries the argument
Geometric transformation applied to Gaussian processes with linear kernels to avoid boundary-seeking behavior
Load-bearing premise
The selected benchmark tasks and the molecular optimization problem represent the high-dimensional regimes where complex structural assumptions were previously considered necessary, and the transformation does not systematically favor linear models.
What would settle it
A new high-dimensional optimization benchmark in which linear-kernel Gaussian processes with the geometric transformation fall short of methods that encode locality or sparsity would falsify the performance-matching claim.
Figures











read the original abstract
Existing high-dimensional Bayesian optimization (BO) methods aim to overcome the curse of dimensionality by carefully encoding structural assumptions, from locality to sparsity to smoothness, into the optimization procedure. Surprisingly, we demonstrate that these approaches are outperformed by arguably the simplest method imaginable: Bayesian linear regression. After applying a geometric transformation to avoid boundary-seeking behavior, Gaussian processes with linear kernels match state-of-the-art performance on tasks with 60- to 6,000-dimensional search spaces. Linear models offer numerous advantages over their non-parametric counterparts: they afford closed-form sampling and their computation scales linearly with data, a fact we exploit on molecular optimization tasks with >20,000 observations. Coupled with empirical analyses, our results suggest the need to depart from past intuitions about BO methods in high-dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that high-dimensional Bayesian optimization methods relying on structural assumptions (locality, sparsity, smoothness) are outperformed by the simplest alternative: Bayesian linear regression. After a geometric transformation to mitigate boundary-seeking behavior, Gaussian processes with linear kernels match state-of-the-art performance on benchmark tasks with 60–6,000-dimensional search spaces. The authors further demonstrate computational advantages of linear models, including closed-form sampling and linear scaling with data size, on a molecular optimization task involving >20,000 observations, and argue that these results challenge prevailing intuitions about the necessity of complex models in high-dimensional BO.
Significance. If the central empirical claim holds under fair and reproducible comparisons, the work would be significant for the Bayesian optimization community. It provides a direct counterexample to the assumption that high-dimensional problems inherently require sophisticated structural encodings, potentially simplifying algorithm design and enabling better scalability. The emphasis on linear scaling and closed-form properties is a concrete practical strength for large-scale applications such as molecular design. The results could prompt re-examination of why simple linear models succeed in regimes previously thought to demand non-parametric complexity.
major comments (2)
- [Abstract and Section 4] Abstract and Section 4 (Experimental Setup): The central claim that linear-kernel GPs match SOTA after the geometric transformation is load-bearing on the transformation being a neutral preprocessing step available to every baseline. The manuscript does not explicitly state whether the same geometric mapping was applied uniformly to locality-, sparsity-, and smoothness-based competitors. If the transformation interacts favorably only with the closed-form properties of the linear model, the results demonstrate the value of the preprocessing rather than the sufficiency of linear kernels without complex assumptions.
- [Section 5] Section 5 (Results on Molecular Optimization): The reported linear scaling with >20,000 observations is a key advantage, but the manuscript should include an ablation or timing comparison against at least one non-linear high-dimensional baseline under identical data regimes to substantiate that the scaling benefit is not offset by poorer sample efficiency.
minor comments (2)
- [Figure 2] Figure 2 and associated caption: axis labels and legend entries should explicitly indicate whether the geometric transformation was used for each plotted method.
- [Abstract] The abstract states 'match state-of-the-art performance' but the main text should report exact quantitative gaps (e.g., mean and standard deviation over repeated runs) rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major point below with clarifications and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and Section 4] Abstract and Section 4 (Experimental Setup): The central claim that linear-kernel GPs match SOTA after the geometric transformation is load-bearing on the transformation being a neutral preprocessing step available to every baseline. The manuscript does not explicitly state whether the same geometric mapping was applied uniformly to locality-, sparsity-, and smoothness-based competitors. If the transformation interacts favorably only with the closed-form properties of the linear model, the results demonstrate the value of the preprocessing rather than the sufficiency of linear kernels without complex assumptions.
Authors: We appreciate this observation on ensuring fair comparisons. The geometric transformation is a general preprocessing step intended to mitigate boundary-seeking behavior and is applicable to any method. In the reported experiments, it was applied uniformly across all baselines, including those based on locality, sparsity, and smoothness assumptions. We will revise Section 4 to explicitly state this uniform application and describe the implementation details for non-linear methods to remove any ambiguity. revision: yes
-
Referee: [Section 5] Section 5 (Results on Molecular Optimization): The reported linear scaling with >20,000 observations is a key advantage, but the manuscript should include an ablation or timing comparison against at least one non-linear high-dimensional baseline under identical data regimes to substantiate that the scaling benefit is not offset by poorer sample efficiency.
Authors: We agree that an explicit timing comparison would further substantiate the practical advantages. While sample efficiency is already compared on the benchmark tasks in Sections 4 and earlier, Section 5 emphasizes computational scaling on large datasets where cubic-scaling methods become infeasible. We will add a timing ablation against one representative non-linear high-dimensional baseline on a subsampled version of the molecular dataset to directly address this concern. revision: yes
Circularity Check
Empirical demonstration with no load-bearing derivation
full rationale
The paper advances an empirical claim that Bayesian linear regression (Gaussian processes with linear kernels) plus a geometric transformation matches state-of-the-art high-dimensional BO performance on 60- to 6000-dimensional tasks. This rests on direct benchmark comparisons and scaling observations rather than any first-principles derivation, fitted-parameter prediction, or self-citation chain that reduces the result to its own inputs by construction. No equations or uniqueness theorems are invoked that would create self-definitional or fitted-input circularity; the central result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of Gaussian process regression and Bayesian optimization remain valid when the kernel is restricted to linear form in high dimensions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
After applying a geometric transformation to avoid boundary-seeking behavior, Gaussian processes with linear kernels match state-of-the-art performance on tasks with 60- to 6,000-dimensional search spaces.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ament, S., Daulton, S., Eriksson, D., Balandat, M., and Bakshy, E. (2023). Unexpected improvements to expected improvement for B ayesian optimization. Advances in Neural Information Processing Systems
work page 2023
-
[2]
Balandat, M., Karrer, B., Jiang, D., Daulton, S., Letham, B., Wilson, A. G., and Bakshy, E. (2020). B o T orch: A framework for efficient M onte- C arlo B ayesian optimization. Advances in neural information processing systems
work page 2020
-
[3]
Brown, N., Fiscato, M., Segler, M. H., and Vaucher, A. C. (2019). GuacaMol : benchmarking models for de novo molecular design. Journal of chemical information and modeling
work page 2019
-
[4]
Bull, A. D. (2011). Convergence rates of efficient global optimization algorithms. Journal of Machine Learning Research
work page 2011
-
[5]
Eriksson, D. and Jankowiak, M. (2021). High-dimensional B ayesian optimization with sparse axis-aligned subspaces. In Uncertainty in Artificial Intelligence
work page 2021
-
[6]
Eriksson, D., Pearce, M., Gardner, J., Turner, R. D., and Poloczek, M. (2019). Scalable global optimization via local Bayesian optimization. In Advances in Neural Information Processing Systems
work page 2019
-
[7]
Fan, Z., Wang, W., Ng, S. H., and Hu, Q. (2024). Minimizing ucb: a better local search strategy in local B ayesian optimization. Advances in Neural Information Processing Systems
work page 2024
-
[8]
Frazier, P. I. (2018). B ayesian optimization. In Recent advances in optimization and modeling of contemporary problems . Informs
work page 2018
-
[9]
Gardner, J., Guo, C., Weinberger, K., Garnett, R., and Grosse, R. (2017). Discovering and exploiting additive structure for B ayesian optimization. In Artificial Intelligence and Statistics
work page 2017
-
[10]
Gardner, J., Pleiss, G., Weinberger, K. Q., Bindel, D., and Wilson, A. G. (2018). GPyTorch : Blackbox matrix-matrix G aussian process inference with GPU acceleration. Advances in Neural Information Processing Systems , 31
work page 2018
-
[11]
Garnett, R. (2023). B ayesian optimization . Cambridge University Press
work page 2023
-
[12]
Genton, M. G. (2001). Classes of kernels for machine learning: a statistics perspective. Journal of Machine Learning Research , 2(Dec):299--312
work page 2001
-
[13]
Han, E., Arora, I., and Scarlett, J. (2021). High-dimensional B ayesian optimization via tree-structured additive models. In Proceedings of the AAAI Conference on Artificial Intelligence
work page 2021
- [14]
-
[15]
Hensman, J., Fusi, N., and Lawrence, N. D. (2013). G aussian processes for big data. In Uncertainty in Artificial Intelligence
work page 2013
-
[16]
M., Requeima, J., Pyzer-Knapp, E
Hern \'a ndez-Lobato, J. M., Requeima, J., Pyzer-Knapp, E. O., and Aspuru-Guzik, A. (2017). Parallel and distributed T hompson sampling for large-scale accelerated exploration of chemical space. In International conference on machine learning . PMLR
work page 2017
-
[17]
Hilbert, D. and Cohn-Vossen, S. (2021). Geometry and the Imagination , volume 87. American Mathematical Soc
work page 2021
-
[18]
Hvarfner, C., Hellsten, E. O., and Nardi, L. (2024). Vanilla B ayesian optimization performs great in high dimensions. In Proceedings of the 41st International Conference on Machine Learning
work page 2024
-
[19]
R., Schonlau, M., and Welch, W
Jones, D. R., Schonlau, M., and Welch, W. J. (1998). Efficient global optimization of expensive black-box functions. Journal of Global optimization
work page 1998
-
[20]
Kandasamy, K., Schneider, J., and P \'o czos, B. (2015). High dimensional B ayesian optimisation and bandits via additive models. In International conference on machine learning
work page 2015
-
[21]
Kirschner, J., Mutny, M., Hiller, N., Ischebeck, R., and Krause, A. (2019). Adaptive and safe B ayesian optimization in high dimensions via one-dimensional subspaces. In International Conference on Machine Learning
work page 2019
-
[22]
Letham, B., Calandra, R., Rai, A., and Bakshy, E. (2020). Re-examining linear embeddings for high-dimensional B ayesian optimization. Advances in neural information processing systems
work page 2020
-
[23]
Li, C., Gupta, S., Rana, S., Nguyen, V., Venkatesh, S., and Shilton, A. (2017). High dimensional B ayesian optimization using dropout. In Proceedings of the 26th International Joint Conference on Artificial Intelligence
work page 2017
-
[24]
J., Bradshaw, J., and Gardner, J
Maus, N., Jones, H., Moore, J., Kusner, M. J., Bradshaw, J., and Gardner, J. (2022). Local latent space B ayesian optimization over structured inputs. Advances in neural information processing systems
work page 2022
-
[25]
Maus, N., Kim, K., Pleiss, G., Eriksson, D., Cunningham, J. P., and Gardner, J. R. (2024). Approximation-aware B ayesian optimization. Advances in Neural Information Processing Systems
work page 2024
-
[26]
Mo c kus, J. (1974). On B ayesian methods for seeking the extremum. In IFIP Technical Conference on Optimization Techniques
work page 1974
-
[27]
Moriconi, R., Deisenroth, M. P., and Sesh Kumar, K. (2020). High-dimensional B ayesian optimization using low-dimensional feature spaces. Machine Learning
work page 2020
-
[28]
Moss, H. B., Ober, S. W., and Picheny, V. (2023). Inducing point allocation for sparse G aussian processes in high-throughput B ayesian optimisation. In Artificial Intelligence and Statistics
work page 2023
-
[29]
M \"u ller, S., von Rohr, A., and Trimpe, S. (2021). Local policy search with B ayesian optimization. Advances in Neural Information Processing Systems
work page 2021
-
[30]
Mutny, M. and Krause, A. (2018). Efficient high dimensional B ayesian optimization with additivity and quadrature F ourier features. Advances in Neural Information Processing Systems , 31
work page 2018
-
[31]
Nardi, L., Gramfort, A., Salmon, J., and Sehic, K. (2022). Lassobench: A high-dimensional hyperparameter optimization benchmark suite for lasso. In 1st International Conference on Automated Machine Learning (AutoML)
work page 2022
-
[32]
Nayebi, A., Munteanu, A., and Poloczek, M. (2019). A framework for B ayesian optimization in embedded subspaces. In International Conference on Machine Learning
work page 2019
-
[33]
Nguyen, Q., Wu, K., Gardner, J., and Garnett, R. (2022). Local B ayesian optimization via maximizing probability of descent. Advances in neural information processing systems
work page 2022
-
[34]
Oh, C., Gavves, E., and Welling, M. (2018). BOCK : B ayesian optimization with cylindrical kernels. In International conference on machine learning
work page 2018
-
[35]
Papenmeier, L., Cheng, N., Becker, S., and Nardi, L. (2025a). Exploring exploration in B ayesian optimization. In Forty-First Conference on Uncertainty in Artificial Intelligence
-
[36]
Papenmeier, L., Nardi, L., and Poloczek, M. (2022). Increasing the scope as you learn: Adaptive B ayesian optimization in nested subspaces. Advances in Neural Information Processing Systems
work page 2022
-
[37]
Papenmeier, L., Nardi, L., and Poloczek, M. (2023). Bounce: Reliable high-dimensional B ayesian optimization for combinatorial and mixed spaces. Advances in Neural Information Processing Systems
work page 2023
-
[38]
Papenmeier, L., Poloczek, M., and Nardi, L. (2025b). Understanding high-dimensional B ayesian optimization. In Forty-Second International Conference on Machine Learning
-
[39]
Rashidi, B., Johnstonbaugh, K., and Gao, C. (2024). Cylindrical T hompson sampling for high-dimensional B ayesian optimization. In International Conference on Artificial Intelligence and Statistics
work page 2024
-
[40]
Rolland, P., Scarlett, J., Bogunovic, I., and Cevher, V. (2018). High-dimensional B ayesian optimization via additive models with overlapping groups. In International conference on artificial intelligence and statistics
work page 2018
-
[41]
Santoni, M. L., Raponi, E., Leone, R. D., and Doerr, C. (2024). Comparison of high-dimensional B ayesian optimization algorithms on BBOB . ACM Transactions on Evolutionary Learning
work page 2024
-
[42]
Schoenberg, I. (1942). Positive definite functions on spheres. Duke Mathematical Journal
work page 1942
-
[43]
Schoenberg, I. J. (1938). Metric spaces and completely monotone functions. Annals of Mathematics , 39(4):811--841
work page 1938
-
[44]
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., and De Freitas, N. (2015). Taking the human out of the loop: A review of B ayesian optimization. Proceedings of the IEEE
work page 2015
-
[45]
Song, L., Xue, K., Huang, X., and Qian, C. (2022). Monte C arlo tree search based variable selection for high dimensional B ayesian optimization. Advances in Neural Information Processing Systems
work page 2022
-
[46]
Srinivas, N., Krause, A., Kakade, S. M., and Seeger, M. (2010). G aussian process optimization in the bandit setting: No regret and experimental design. In International Conference on Machine Learning
work page 2010
-
[47]
Thompson, W. R. (1933). On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika
work page 1933
-
[48]
Vakili, S., Moss, H., Artemev, A., Dutordoir, V., and Picheny, V. (2021). Scalable thompson sampling using sparse gaussian process models. Advances in neural information processing systems , 34:5631--5643
work page 2021
-
[49]
Vershynin, R. (2025). High-dimensional probability: An introduction with applications in data science . Cambridge University Press, second edition
work page 2025
-
[50]
Wan, X., Nguyen, V., Ha, H., Ru, B., Lu, C., and Osborne, M. A. (2021). Think global and act local: B ayesian optimisation over high-dimensional categorical and mixed search spaces. In International Conference on Machine Learning
work page 2021
-
[51]
Wang, L., Fonseca, R., and Tian, Y. (2020). Learning search space partition for black-box optimization using M onte C arlo tree search. Advances in Neural Information Processing Systems
work page 2020
-
[52]
Wang, Z., Gehring, C., Kohli, P., and Jegelka, S. (2018). Batched large-scale B ayesian optimization in high-dimensional spaces. In Artificial Intelligence and Statistics
work page 2018
-
[53]
Wang, Z., Hutter, F., Zoghi, M., Matheson, D., and De Feitas, N. (2016). B ayesian optimization in a billion dimensions via random embeddings. Journal of Artificial Intelligence Research
work page 2016
-
[54]
Williams, C. K. and Rasmussen, C. E. (2006). G aussian processes for machine learning . MIT press
work page 2006
-
[55]
Wu, K., Kim, K., Garnett, R., and Gardner, J. (2023). The behavior and convergence of local B ayesian optimization. Advances in neural information processing systems , 36:73497--73523
work page 2023
-
[56]
Xu, Z., Wang, H., Phillips, J. M., and Zhe, S. (2025). Standard G aussian process is all you need for high-dimensional B ayesian optimization. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[57]
Ziomek, J. K. and Ammar, H. B. (2023). Are random decompositions all we need in high dimensional B ayesian optimisation? In International Conference on Machine Learning
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.