Mammo-FM: Breast-specific foundational model for Integrated Mammographic Diagnosis, Prognosis, and Reporting
Pith reviewed 2026-05-17 03:17 UTC · model grok-4.3
The pith
A breast-specific foundation model outperforms larger generalist models on diagnosis, prognosis, and reporting while using one-third the parameters
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
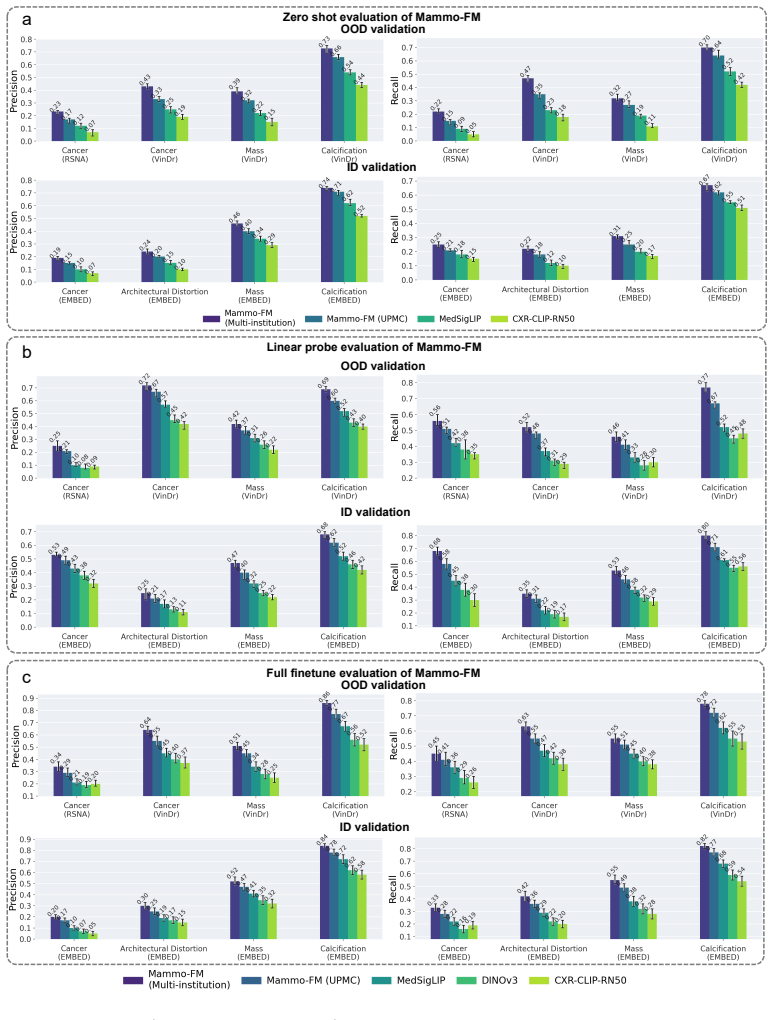
Mammo-FM is introduced as the first mammography-specific foundation model, pretrained on 140,677 patients and 821,326 mammograms from four U.S. institutions. It provides a single framework for cancer diagnosis, pathology localization, structured report generation, and cancer risk prognosis by aligning images with text for improved interpretability. The model operates on native-resolution mammograms and uses only one-third the parameters of state-of-the-art generalist foundation models while consistently outperforming them on multiple benchmarks.
What carries the argument
The image-text aligned foundation model pretrained on native-resolution mammograms that unifies diagnosis, localization, reporting, and prognosis in one representation.
If this is right
- The image-text alignment allows clinicians to audit model decisions through linked visual and textual explanations.
- A single smaller model can replace separate tools for diagnosis, risk assessment, and report writing in breast imaging workflows.
- Operating at native image resolution preserves fine details that downsampled generalist models might lose.
- Performance gains on out-of-distribution tests indicate the model handles data from different institutions better than broader alternatives.
Where Pith is reading between the lines
- Domain-specific pretraining could prove more efficient than scaling up general models for other specialized medical imaging tasks such as chest X-rays or MRIs.
- The results point to the value of multi-institution datasets for building medical AI that generalizes across equipment and patient populations.
- If the efficiency advantage holds, clinical deployment of advanced mammography AI could require less specialized hardware than current general models.
Load-bearing premise
The multi-institutional dataset of 140,677 patients is representative of real-world mammogram variations and free of biases or data leakage that could affect generalization.
What would settle it
Testing Mammo-FM on mammograms from a hospital or region outside the four training institutions and checking whether it still outperforms generalist models on the same tasks.
Figures


















read the original abstract
Breast cancer is one of the leading causes of death among women worldwide. We introduce Mammo-FM, the first foundation model specifically for mammography, pretrained on the largest and most diverse dataset to date - 140,677 patients (821,326 mammograms) across four U.S. institutions. Mammo-FM provides a unified foundation for core clinical tasks in breast imaging, including cancer diagnosis, pathology localization, structured report generation, and cancer risk prognosis within a single framework. Its alignment between images and text enables both visual and textual interpretability, improving transparency and clinical auditability, which are essential for real-world adoption. We rigorously evaluate Mammo-FM across diagnosis, prognosis, and report-generation tasks in in- and out-of-distribution datasets. Despite operating on native-resolution mammograms and using only one-third of the parameters of state-of-the-art generalist FMs, Mammo-FM consistently outperforms them across multiple public and private benchmarks. These results highlight the efficiency and value of domain-specific foundation models designed around the full spectrum of tasks within a clinical domain and emphasize the importance of rigorous, domain-aligned evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Mammo-FM, a breast-specific foundation model pretrained on the largest reported mammography dataset to date (140,677 patients / 821,326 images across four U.S. institutions). It presents a single image-text aligned model that jointly supports cancer diagnosis, pathology localization, structured report generation, and cancer risk prognosis. The central empirical claim is that Mammo-FM, operating at native resolution with only one-third the parameters of leading generalist foundation models, consistently outperforms those baselines on both public and private in- and out-of-distribution benchmarks.
Significance. If the performance advantages survive rigorous controls for data leakage and identical fine-tuning protocols, the work would usefully demonstrate that domain-specific pretraining can deliver efficiency and multi-task coverage advantages in medical imaging. The scale of the multi-institutional pretraining corpus and the explicit integration of visual and textual outputs for interpretability are concrete strengths that would be of interest to both the computer-vision and clinical-breast-imaging communities.
major comments (2)
- [§4 and §3.2] §4 (Experiments) and §3.2 (Dataset Construction): the manuscript does not describe patient-level deduplication, temporal splits, or institution-level separation between the 140,677-patient pretraining corpus and the private test cohorts. Because the headline claim of consistent outperformance on out-of-distribution data rests on the assumption that these test sets are truly unseen, the absence of these controls is load-bearing for the generalization argument.
- [Results tables] Results tables (e.g., Tables 2–4): no statistical significance tests, confidence intervals, or ablation studies isolating the contribution of domain-specific pretraining versus native-resolution input or fine-tuning protocol are reported. Without these, it is impossible to verify that the reported gains are attributable to the model rather than evaluation asymmetry.
minor comments (2)
- [Abstract and §3.1] The exact parameter count comparison to the cited generalist models should be presented in a dedicated table rather than stated only in the abstract.
- [Figures 3–5] Figure captions for localization and report-generation examples would benefit from explicit annotation of ground-truth versus model output to aid clinical interpretability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments identify important areas where additional methodological transparency and statistical rigor will strengthen the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4 and §3.2] §4 (Experiments) and §3.2 (Dataset Construction): the manuscript does not describe patient-level deduplication, temporal splits, or institution-level separation between the 140,677-patient pretraining corpus and the private test cohorts. Because the headline claim of consistent outperformance on out-of-distribution data rests on the assumption that these test sets are truly unseen, the absence of these controls is load-bearing for the generalization argument.
Authors: We agree that explicit documentation of these controls is essential for supporting the out-of-distribution claims. Patient-level deduplication was performed using unique patient identifiers across all institutions, and the private test cohorts were drawn from held-out institutions and later acquisition periods not represented in the pretraining corpus. We will revise §3.2 to provide a clear description of the deduplication process, the institution-level separation, and any temporal considerations used to ensure no patient or image overlap between pretraining and evaluation sets. revision: yes
-
Referee: [Results tables] Results tables (e.g., Tables 2–4): no statistical significance tests, confidence intervals, or ablation studies isolating the contribution of domain-specific pretraining versus native-resolution input or fine-tuning protocol are reported. Without these, it is impossible to verify that the reported gains are attributable to the model rather than evaluation asymmetry.
Authors: We concur that statistical significance testing and confidence intervals are necessary to substantiate the performance differences. We will recompute and report p-values and 95% confidence intervals for all key metrics in Tables 2–4. In addition, we will add an ablation study in §4 that isolates the contribution of domain-specific pretraining from the effects of native-resolution input and fine-tuning protocol, using controlled comparisons on the same evaluation sets. revision: yes
Circularity Check
No significant circularity in empirical evaluation chain
full rationale
The paper describes pretraining a domain-specific foundation model on a large multi-institutional dataset of 140,677 patients followed by empirical evaluation on diagnosis, prognosis, localization, and report-generation tasks using in- and out-of-distribution benchmarks. All central claims rest on comparative performance numbers against external generalist models rather than any closed mathematical derivation, fitted parameter renamed as prediction, or self-referential definition. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the abstract or described methodology; the reported outperformance is presented as an observable result of the training and evaluation protocol, not a quantity forced by the paper's own equations. The setup is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Pretraining hyperparameters and architecture choices
axioms (1)
- domain assumption The multi-institutional dataset of 140,677 patients supplies adequate diversity and quality for robust pretraining and out-of-distribution generalization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mammo-FM uses dual encoders—an EfficientNet-B5 image encoder and a ModernBERT text encoder... multiview contrastive loss aligns both modalities within a shared embedding space.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Despite operating on native-resolution mammograms and using only one-third of the parameters of state-of-the-art generalist FMs, Mammo-FM consistently outperforms them.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
there is a suspicious mass in the lower inner right breast at anterior depth
-
[2]
there is a suspicious mass in the lower inner right breast at mid depth
-
[3]
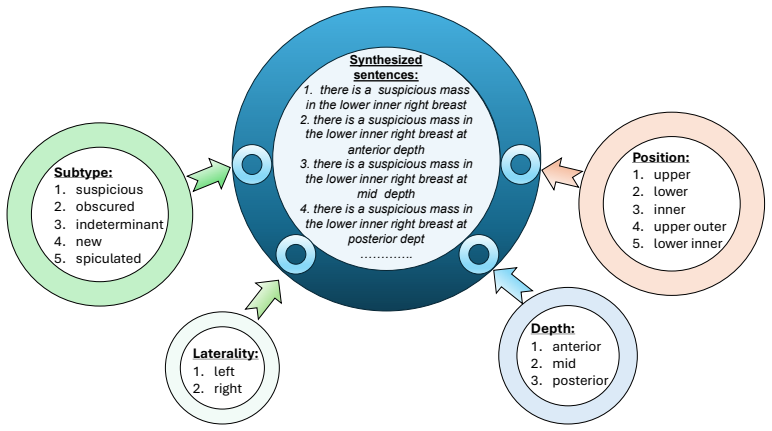
there is a suspicious mass in the lower inner right breast at posterior dept …………. Subtype: 1.suspicious 2.obscured 3.indeterminant 4.new 5.spiculated Position: 1.upper 2.lower 3.inner 4.upper outer 5.lower inner Laterality: 1.left 2.right Depth: 1.anterior 2.mid 3.posterior Figure 6. Example of report-like sentence generation for the attributemasslabeled...
work page 2017
-
[4]
Please provide the radiology report for the following 2D screening mammogram <image>
achieves strong predictive accuracy by aggregating multi-view mammographic representa- tions through a transformer, but its latent features remain opaque and lack clinical interpretability. AsymMIRAI Donnelly et al. [2024] advances this direction by introducing an interpretable frame- work based on bilateral dissimilarity between left–right breast represe...
work page 2024
-
[6]
Also, the question-answer must be derived from the given radiology report only, nothing else
All questions and answers must be visually driven, meaning that someone would need to look at the actual mammogram images to confirm the answer. Also, the question-answer must be derived from the given radiology report only, nothing else
-
[8]
All questions should relate to what can be observed or concluded from the mammogram images
Do not include random or irrelevant questions with respect to the report. All questions should relate to what can be observed or concluded from the mammogram images
-
[9]
Provide detailed answers when answering complex questions
Also include complex questions that are relevant to the report accompanied by the 2D mammogram images only. Provide detailed answers when answering complex questions. For example, give detailed examples or reasoning steps to make the content more convincing and well-organized
-
[10]
You can include questions about BI-RADS only if BI-RADS assessment is mentioned in the report explicitly. If BI-RADS is not mentioned in the report, do not include questions on the overall BI-RADS assessment. You can include as many question and answer couples as you find appropriate
-
[11]
If there is any finding (mass/calcification/asymmetry etc.) mentioned, you must generate 3 questions: (1) what is the finding? (2) the corresponding laterality (left/right/bilateral), and (3) the corresponding view (CC or MLO) if mentioned. If there is no mention of views (CC/MLO), don’t generate questions on views. Table 5.Prompt used for generating conv...
work page 2010
-
[13]
Minimal vascular calcification is seen
Probability: 0.3311 (33.1%) "Minimal vascular calcification is seen. " [2] Probability: 0.2674 (26.7%) "A few other scattered coarse benign-appearing calcifications are seen in the left breast. " [3] Probability: 0.2093 (20.9%) "Findings: There are scattered fine punctate and coarsely grouped calcifications in the right breast consistent with benign findi...
work page 2093
-
[14]
Probability: 0.4671 (46.7%) "There is a mass in the central right breast with surrounding calcifications, for which additional imaging with spot compression and magnification views are recommended. " [2] Probability: 0.3527 (35.3%) "The patient will be contacted by our department to schedule an appointment for a diagnostic mammogram with spot compression ...
-
[15]
Minimal vascular calcification is seen
Probability: 0.3311 (33.1%) "Minimal vascular calcification is seen. " [2] Probability: 0.2674 (26.7%) "A few other scattered coarse benign-appearing calcifications are seen in the left breast. " [3] Probability: 0.2093 (20.9%) "Findings: There are scattered fine punctate and coarsely grouped calcifications in the right breast consistent with benign findi...
work page 2093
-
[16]
Use the mammogram report strictly for context regarding findings and impressions. Do not reference the report verbatim or mention its specifics ( e.g., who read the exam, the software used, or the date)
-
[17]
Also, the question-answer pairs must be derived from the given radiology report only, nothing else
All questions and answers must be visually driven, meaning that someone would need to look at the actual mammogram images to confirm the answer. Also, the question-answer pairs must be derived from the given radiology report only, nothing else
-
[18]
Focus strictly on the core findings or impressions
-
[19]
All questions must relate to observable or inferable image features
Do not include random or irrelevant questions. All questions must relate to observable or inferable image features
-
[20]
Include BI-RADS-related questions only if the report explicitly mentions a BI-RADS assessment
-
[21]
If no views are mentioned, omit view-specific questions
If the report mentions any finding ( e.g., mass, calcification, asymmetry), you must generate 3 questions: (1) identify the finding, (2) specify the laterality (left/right/bilateral), and (3) indicate the view (CC or MLO) if mentioned. If no views are mentioned, omit view-specific questions
-
[22]
These three core questions must appear in each of the <free _response>, <description>, and <multiple _choice> sections. Final structure: <free_response> <q>Q1</q><a>A1</a> <q>Q2</q><a>A2</a> </free_response> <description> <q>Q1</q><a>A1</a> <q>Q2</q><a>A2</a> </description> <multiple_choice> <q>Q1 (a)...(d)</q><a>(b)</a> <q>Q2 (a)...(d)</q><a>(a)</a> </mu...
-
[23]
Focus strictly on 2D screening-mammography findings - tissue composition, masses, calcifications, asymmetries, distortions, overall BI-RADS category, etc
-
[24]
Use clear, radiology-style language; be concise and factual
-
[25]
If the user asks general breast-imaging knowledge (not about this exam), answer normally
-
[26]
Avoid unrelated topics and keep all responses clinically relevant
If the user greets you, respond politely. Avoid unrelated topics and keep all responses clinically relevant. Table 7.System prompt for Mammo-GRG (preliminary report generation)defining view-specific inputs, directive tokens, and clinical response guidelines for mammography-grounded report generation. System prompt to generate the final report from the pre...
-
[27]
Treat the PRELIMINARY REPORT as the base text. Preserve its clinically relevant content, density description, laterality, locations (e.g.,upper outer quadrant), and recommendations
-
[28]
You MUST include (carry forward) all non-contradicted statements from the preliminary report
-
[29]
RECONCILIATION RULES (VERY IMPORTANT):
Reconcile contradictions using the rules below. RECONCILIATION RULES (VERY IMPORTANT):
-
[30]
no X” statements for that category. - State laterality accurately: Left, Right, or “bilaterally
If structured findings are POSITIVE for a category (mass, suspicious calcification, asymmetry), you MUST reflect that positivity in the final report: - Remove or revise any preliminary “no X” statements for that category. - State laterality accurately: Left, Right, or “bilaterally” ONLY if both sides are positive
-
[31]
If structured findings are NEGATIVE and the preliminary report already says “no X,” keep that negative statement
-
[32]
Do NOT add “bilaterally” unless BOTH sides are positive. 4)BI-RADS POLICY (SCREENING):You must output BI-RADS in {0, 1, 2} ONLY. - If any structured finding is positive/indeterminate, assign BI-RADS 0. - If there are no findings, assign BI-RADS 1. - If only benign findings are present, assign BI-RADS 2. - If the preliminary BI-RADS is provided, keep it if...
- [33]
-
[34]
Use standard terminology (CC, MLO; laterality) and be concise and clinically appropriate
-
[35]
Preserve the overall style of the preliminary report while outputting ONLY the two sections. Table 8.Prompt used for the grounding stage of Mammo-GRG.This instruction reconciles structured findings from Mammo-FM with the preliminary generated report to produce a clinically consistent final screening mammography report containing onlyFindingsandImpressions...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.