Differentially Private and Federated Structure Learning in Bayesian Networks
Pith reviewed 2026-05-17 02:44 UTC · model grok-4.3
The pith
A federated method learns linear Gaussian Bayesian network structures with differential privacy by restricting each participant to updating only a few relevant edges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
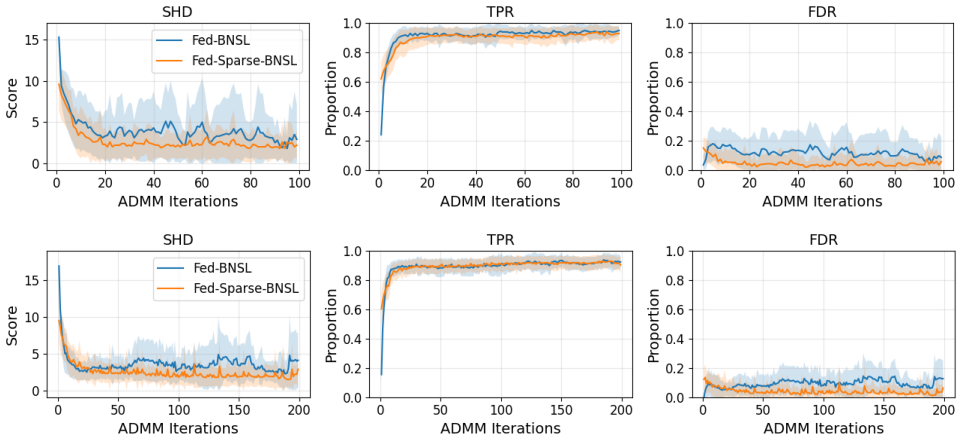
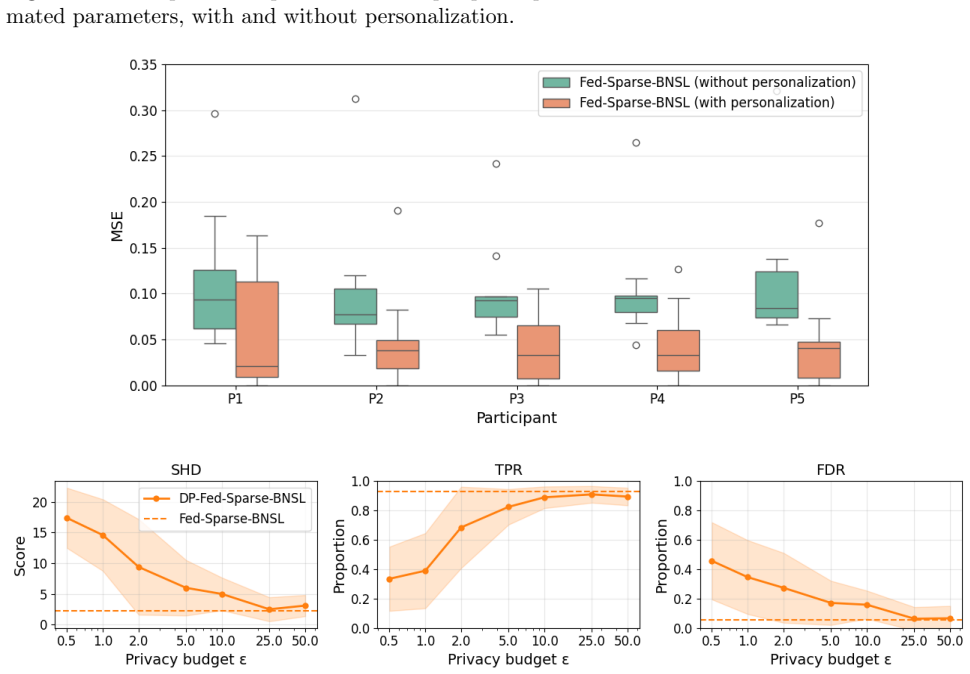
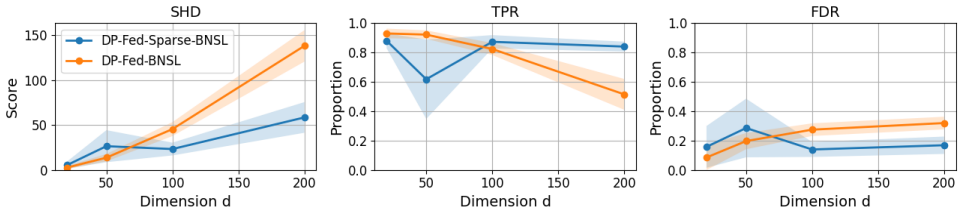
Fed-Sparse-BNSL performs federated structure learning for linear Gaussian Bayesian networks by having each participant apply differential privacy to a sparse set of greedy edge updates rather than transmitting full local statistics. Careful restriction of the updates to a few relevant edges per round preserves model identifiability, allowing accurate recovery of the global network structure without participants sharing their full datasets or incurring communication costs that grow with dimensionality.
What carries the argument
Fed-Sparse-BNSL, which applies differential privacy to greedy updates that select and modify only a few relevant edges per participant.
If this is right
- Communication cost stays low even as the number of variables grows because only a bounded number of edges are exchanged per participant.
- Differential privacy can be added without destroying the ability to identify the correct network dependencies.
- The method yields structures whose utility approaches that of non-private methods on both synthetic and real data.
- Privacy budget is used efficiently by concentrating noise on the selected sparse updates rather than on all possible edges.
Where Pith is reading between the lines
- The sparse-update idea could transfer to structure learning for other graphical models where full edge sets are costly to communicate.
- Institutions holding sensitive data might use similar techniques to build joint models without pooling raw records.
- Varying the number of edges updated per round offers a tunable knob for trading privacy strength against estimation accuracy.
- The approach might extend to discrete or mixed-variable Bayesian networks if the identifiability arguments are adapted accordingly.
Load-bearing premise
That restricting updates to a few relevant edges and adding differential privacy noise still permits accurate recovery of the true linear Gaussian Bayesian network structure without systematic bias or loss of identifiability.
What would settle it
A dataset where the non-private baseline recovers the correct edges but the private federated version consistently selects a substantially different edge set or fails to identify the true parents of key variables.
Figures
read the original abstract
Learning the structure of a Bayesian network from decentralized data poses two major challenges: (i) ensuring rigorous privacy guarantees for participants, and (ii) avoiding communication costs that scale poorly with dimensionality. In this work, we introduce Fed-Sparse-BNSL, a novel federated method for learning linear Gaussian Bayesian network structures that addresses both challenges. By combining differential privacy with greedy updates that target only a few relevant edges per participant, Fed-Sparse-BNSL efficiently uses the privacy budget while keeping communication costs low. Our careful algorithmic design preserves model identifiability and enables accurate structure estimation. Experiments on synthetic and real datasets demonstrate that Fed-Sparse-BNSL achieves utility close to non-private baselines while offering substantially stronger privacy and communication efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Fed-Sparse-BNSL, a federated algorithm for structure learning of linear Gaussian Bayesian networks. It integrates differential privacy with per-participant greedy updates restricted to a small number of candidate edges to control communication cost and privacy budget. The central claims are that the algorithmic design preserves model identifiability and that experiments on synthetic and real datasets show utility close to non-private baselines while providing stronger privacy and efficiency.
Significance. If the identifiability claim and near-baseline utility hold, the work would be a useful contribution to privacy-preserving federated graphical model learning, especially for high-dimensional settings where full communication is prohibitive. The sparse-update strategy combined with DP is a pragmatic design choice that could enable deployment in domains with decentralized sensitive data.
major comments (2)
- [Algorithmic Design / Theoretical Analysis] The assertion that 'careful algorithmic design preserves model identifiability' is load-bearing for the central claim yet lacks an explicit bound relating DP noise scale (Gaussian or Laplace), score sensitivity, and minimum edge strength. In linear-Gaussian score-based learning, BIC or marginal-likelihood differences between true and spurious parents can be small; without a derived condition ensuring that the calibrated noise does not flip the argmax ordering in the greedy step, consistent recovery of the true DAG is not guaranteed.
- [Experiments] The experimental claim of 'utility close to non-private baselines' is not yet supported by evidence that the chosen privacy parameters keep noise below typical score gaps on the evaluated datasets. If the noise variance required for the stated ε,δ exceeds the separation between correct and incorrect edges, the reported performance may be confined to favorable regimes and does not substantiate the general utility guarantee.
minor comments (2)
- [Abstract] The abstract states 'substantially stronger privacy' without quoting the concrete (ε,δ) values or the privacy budget allocation across rounds; adding these numbers would improve clarity.
- [Methods] Notation for the local score function and the sensitivity bound used in the DP mechanism should be introduced earlier and used consistently when describing the noisy update step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and outline the revisions we intend to make to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Algorithmic Design / Theoretical Analysis] The assertion that 'careful algorithmic design preserves model identifiability' is load-bearing for the central claim yet lacks an explicit bound relating DP noise scale (Gaussian or Laplace), score sensitivity, and minimum edge strength. In linear-Gaussian score-based learning, BIC or marginal-likelihood differences between true and spurious parents can be small; without a derived condition ensuring that the calibrated noise does not flip the argmax ordering in the greedy step, consistent recovery of the true DAG is not guaranteed.
Authors: We acknowledge that the current manuscript does not supply an explicit theoretical bound relating the DP noise scale to score sensitivity and minimum edge strength. Our identifiability claim rests on the observation that restricting each participant to a small set of candidate edges substantially reduces the sensitivity of the local score computations, thereby limiting the impact of the calibrated Gaussian noise on the greedy argmax step. We agree that a more formal condition would be valuable. In the revision we will expand the theoretical analysis section with a discussion of score sensitivity for linear-Gaussian models, explain how the sparse-update restriction helps preserve ordering under the added noise, and state the additional assumptions (e.g., minimum edge strength and data distribution) that would be needed for a worst-case guarantee. We will not claim a complete proof if one is not derived. revision: partial
-
Referee: [Experiments] The experimental claim of 'utility close to non-private baselines' is not yet supported by evidence that the chosen privacy parameters keep noise below typical score gaps on the evaluated datasets. If the noise variance required for the stated ε,δ exceeds the separation between correct and incorrect edges, the reported performance may be confined to favorable regimes and does not substantiate the general utility guarantee.
Authors: We appreciate this observation. To substantiate the utility claim, the revised experimental section will include a direct comparison, for each dataset and privacy parameter setting, of the noise variance induced by the chosen (ε, δ) against the observed score gaps (BIC or marginal-likelihood differences) between correct and incorrect parent sets. This analysis will be presented alongside the existing performance tables so that readers can verify that the noise remains below the typical separation in the evaluated regimes. revision: yes
Circularity Check
No circularity: method combines standard DP mechanisms with greedy sparse updates without reducing outputs to inputs by construction
full rationale
The provided abstract and description introduce Fed-Sparse-BNSL as a combination of differential privacy noise with per-participant greedy edge updates on a linear Gaussian BN. No equations appear that define the recovered structure or identifiability in terms of the noisy scores themselves, nor is any target quantity fitted to a subset and then re-predicted. Claims of preserved identifiability are presented as consequences of the algorithmic restrictions rather than smuggled in via self-citation or ansatz. The derivation therefore remains independent of its own outputs and relies on external properties of DP and score-based search.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The data-generating process follows a linear Gaussian Bayesian network.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Fed-Sparse-BNSL, a novel federated method for learning linear Gaussian Bayesian network structures... combining differential privacy with greedy updates that target only a few relevant edges per participant
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The permute-and-flip mechanism is identical to report-noisy-max with exponential noise
Amin, K., Dick, T., Kulesza, A., Medina, A. M., and Vassilvitskii, S. (2019). Differentially private covariance estimation. In Wallach, H. M., Larochelle, H., Beygelzimer, A., d’Alch´ e-Buc, F., Fox, E. B., and Garnett, R., editors,Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIP...
-
[2]
Geiping, J., Bauermeister, H., Dr¨ oge, H., and Moeller, M. (2020). Inverting gradients - how easy is it to break privacy in federated learning? InNeurIPS. Hastie, T., Tibshirani, R., and Wainwright, M. (2015).Statistical Learning with Sparsity: The Lasso and Generalizations. Chapman & Hall/CRC. Huth, M., Arruda, J., Gusinow, R., Contento, L., Tacconelli,...
-
[3]
Wang, L., Pang, Q., and Song, D. (2020). Towards practical differentially private causal graph dis- covery. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H., editors,Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 5516–5526. Curran Associates, Inc. Wang, Y. (2018). Revisiting differentially private linear ...
work page 2020
-
[4]
The (i, j)-th partial derivative ofℓis∇ i,jℓ(B;x i). Gradient sensitivity.For neighboring datasetsX, X ′ differing in a single sample at indexk, we have ∆ = sup X,X ′ ∥∇i,jL(B;X)− ∇ i,jL(B;X ′)∥2 = 1 n ∇i,jℓ(B;x k)− ∇ i,jℓ(B;x ′ k) ≤ 2Li,j n , whereL i,j is the coordinate-wise Lipschitz constant ofℓ. Sensitivity of the coordinate selection score.The non-p...
work page 2018
-
[5]
This additive noise term is sampled, for each variable, from a standard normal distributionN(0,1)
In this model, the value of each variable is determined by a linear combination of its parents’ value (as defined by the weighted adjacency matrix), plus an independent Gaussian noise term. This additive noise term is sampled, for each variable, from a standard normal distributionN(0,1). This implies a uniform noise variance of 1 across all vari- ables, a...
work page 2013
-
[6]
This approach helps to ensure robustness of the chosen hyperparameters against specific dataset realizations in high dimensions. Final evaluation.Once the optimal hyperparameters were determined for a given scenario using the procedure above, the final results (mean and standard deviation) reported in Section 6 were ob- tained by running each algorithm on...
work page 2018
-
[7]
For this analysis, a broader set of hyperparameters, includingλ andγ, were re-tuned for each dimension. For DP-Fed-BNSL,bis the sensitivity bound used for the 23 Gaussian mechanism applied to privatize the covariance matrices, as described by Wang (2018). The grid search ranges for this study are given in Table
work page 2018
-
[8]
Table 7: Optimal hyperparameters for each method and dimension, with privacy budgetε= 10, in the private dimensionality robustness study (Figure 4). Dimension DP-Fed-Sparse-BNSL DP-Fed-BNSL C T K λ γ b T λ 20 10 100 30 0.1 0.5 7 300 0.01 50 5 50 50 0.1 1 10 300 0.1 100 30 100 50 0.1 1 20 300 0.01 200 30 100 100 0.1 1 10 300 0.01 F.2 Real Data In contrast ...
work page 2018
-
[9]
•For DP-Fed-BNSL:b= 4, T= 100, λ= 0.1 and threshold= 0.1. G Implementation and Computing Resources All experiments were conducted on CPUs, either on a personal computer or using a commodity cluster. The implementation relies on several open-source components. Parts of the code were adapted from the open-source implementation of Ng and Zhang (2022) (availa...
work page 2022
-
[10]
Regarding licenses, the reused code for NOTEARS-ADMM (Ng and Zhang,
was obtained through the Causal Discovery Toolbox (CDT) Python package (Kalainathan and Goudet, 2019). Regarding licenses, the reused code for NOTEARS-ADMM (Ng and Zhang,
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.