Dual-level Modality Debiasing Learning for Unsupervised Visible-Infrared Person Re-Identification
Pith reviewed 2026-05-17 02:24 UTC · model grok-4.3
The pith
Dual-level debiasing at model and optimization stages removes modality bias in unsupervised visible-infrared person re-identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
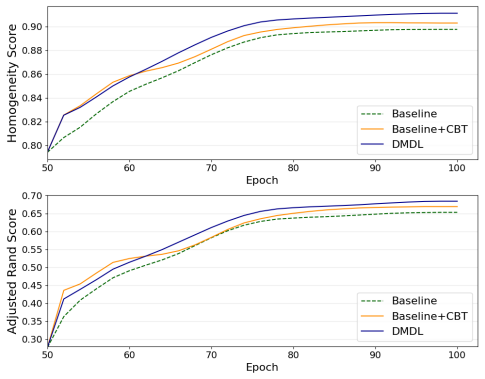
The authors establish that a two-level intervention—replacing likelihood-based modeling with causal modeling inside the Causality-inspired Adjustment Intervention module and applying Collaborative Bias-free Training across data, labels, and features—interrupts modality bias propagation, produces low-biased representations, and yields modality-invariant features together with a more generalized model.
What carries the argument
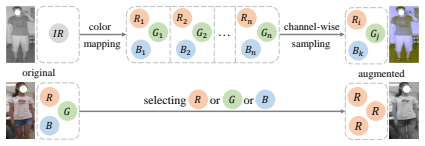
The Dual-level Modality Debiasing Learning framework, whose load-bearing components are the Causality-inspired Adjustment Intervention module that substitutes causal modeling for likelihood modeling and the Collaborative Bias-free Training strategy that coordinates modality-specific augmentation with label refinement and feature alignment.
If this is right
- Modality-specific cues learned during single-modality training no longer propagate into cross-modality stages.
- Identity discrimination improves because representations become less contaminated by modality artifacts.
- The resulting model shows stronger generalization across visible and infrared images on existing benchmark datasets.
Where Pith is reading between the lines
- The same two-level structure could be tested on other unsupervised multi-modal retrieval tasks such as visible-thermal or RGB-depth matching.
- Integrating the causal intervention with existing pseudo-label refinement methods might further stabilize training without extra supervision.
- Running the framework on datasets with extreme lighting variation would reveal whether the learned invariance holds under realistic surveillance conditions.
Load-bearing premise
Replacing likelihood-based modeling with causal modeling inside the adjustment module actually stops modality-induced spurious patterns from entering the learned representations.
What would settle it
A test that extracts and compares modality-specific cues from features produced by the trained model versus a standard baseline would falsify the claim if the cues remain equally strong after the dual-level debiasing steps.
Figures







read the original abstract
Two-stage learning pipeline has achieved promising results in unsupervised visible-infrared person re-identification (USL-VI-ReID). It first performs single-modality learning and then operates cross-modality learning to tackle the modality discrepancy. Although promising, this pipeline inevitably introduces modality bias: modality-specific cues learned in the single-modality training naturally propagate into the following cross-modality learning, impairing identity discrimination and generalization. To address this issue, we propose a Dual-level Modality Debiasing Learning (DMDL) framework that implements debiasing at both the model and optimization levels. At the model level, we propose a Causality-inspired Adjustment Intervention (CAI) module that replaces likelihood-based modeling with causal modeling, preventing modality-induced spurious patterns from being introduced, leading to a low-biased model. At the optimization level, a Collaborative Bias-free Training (CBT) strategy is introduced to interrupt the propagation of modality bias across data, labels, and features by integrating modality-specific augmentation, label refinement, and feature alignment. Extensive experiments on benchmark datasets demonstrate that DMDL could enable modality-invariant feature learning and a more generalized model. The code is available at https://github.com/priester3/DMDL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that two-stage pipelines for unsupervised visible-infrared person re-identification (USL-VI-ReID) introduce modality bias that propagates from single-modality pretraining into cross-modality learning, impairing identity discrimination. It proposes the Dual-level Modality Debiasing Learning (DMDL) framework to address this via a Causality-inspired Adjustment Intervention (CAI) module at the model level, which replaces likelihood-based modeling with causal modeling to avoid introducing modality-induced spurious patterns, and a Collaborative Bias-free Training (CBT) strategy at the optimization level that combines modality-specific augmentation, label refinement, and feature alignment to interrupt bias propagation across data, labels, and features. Extensive experiments on benchmark datasets are reported to show that DMDL enables modality-invariant feature learning and improved generalization; code is released.
Significance. If the causal adjustment mechanism in CAI demonstrably removes modality-specific spurious correlations (rather than acting as generic regularization), the dual-level debiasing approach would represent a meaningful advance for cross-modal ReID by directly targeting bias propagation in two-stage pipelines. The combination of model-level causal intervention and optimization-level collaborative training, together with public code, would support reproducibility and could influence subsequent work on modality-invariant representations.
major comments (1)
- [CAI module] CAI module description: the central claim that replacing likelihood-based modeling with causal modeling prevents modality-induced spurious patterns from being introduced into representations requires an explicit causal graph, a defined intervention operator (e.g., do-calculus adjustment on the modality variable as confounder), or a proof that the adjustment targets modality-specific cues rather than performing standard feature reweighting or attention. Without this, it is unclear whether CAI achieves the stated causal debiasing; this is load-bearing because the CBT stage operates on CAI outputs and any residual modality cue would propagate into label refinement and alignment.
minor comments (2)
- [Abstract] The abstract states that extensive experiments support the claims yet provides no quantitative results, ablation details, or error analysis; adding at least the top-line mAP/Rank-1 numbers on the primary benchmarks would allow readers to assess the magnitude of improvement immediately.
- [Method sections] Ensure that all equations and algorithmic steps in the CAI and CBT sections use consistent notation and explicitly define any new symbols or operators introduced for the causal adjustment and bias-free training components.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The major comment raises an important point about clarifying the causal mechanism in the CAI module, which we address below. We believe incorporating the requested details will improve the rigor of the presentation.
read point-by-point responses
-
Referee: [CAI module] CAI module description: the central claim that replacing likelihood-based modeling with causal modeling prevents modality-induced spurious patterns from being introduced into representations requires an explicit causal graph, a defined intervention operator (e.g., do-calculus adjustment on the modality variable as confounder), or a proof that the adjustment targets modality-specific cues rather than performing standard feature reweighting or attention. Without this, it is unclear whether CAI achieves the stated causal debiasing; this is load-bearing because the CBT stage operates on CAI outputs and any residual modality cue would propagate into label refinement and alignment.
Authors: We agree that an explicit causal graph and formal intervention details would strengthen the exposition of the CAI module. In the revised manuscript we will add a dedicated figure depicting the causal graph in which modality serves as a confounder between the observed features and the identity label. We will also provide the mathematical formulation of the adjustment operator using do-calculus to intervene on the modality variable, together with a short derivation showing that the resulting representation removes modality-specific spurious correlations while preserving identity-discriminative information. This formulation distinguishes the operation from generic attention or reweighting by explicitly blocking the back-door path from modality to the prediction. Because the CBT stage is applied to the outputs of this adjusted representation, the added details will also clarify why residual modality cues are not expected to propagate into label refinement and feature alignment. revision: yes
Circularity Check
No significant circularity in DMDL derivation chain
full rationale
The paper introduces a two-stage pipeline critique and proposes DMDL with distinct CAI (causality-inspired adjustment) and CBT (collaborative bias-free training) components at model and optimization levels. No self-definitional constructs appear where outputs are defined in terms of inputs by construction. No fitted parameters from data subsets are relabeled as predictions. The central claims rest on novel module designs rather than load-bearing self-citations or imported uniqueness theorems. The abstract and description present the replacement of likelihood modeling with causal modeling and the integration of augmentation/refinement/alignment as independent contributions without reduction to prior fitted quantities or ansatz smuggling. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modality-specific cues learned in single-modality training propagate into cross-modality learning and impair identity discrimination.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CAI implements the computation of P(Y|do(X)) by backdoor adjustment... P(Y|do(X))=Σ_c P(Y|X,C=c)·P(C=c)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
replaces likelihood-based modeling with causal modeling, preventing modality-induced spurious patterns
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Ye, W. Ruan, B. Du, M. Z. Shou, Channel augmented joint learning for visible- infrared recognition, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13567–13576
work page 2021
-
[2]
K. Ren, L. Zhang, Implicit discriminative knowledge learning for visible-infrared person re-identification, in: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 393–402. 29
work page 2024
-
[3]
B. Yang, M. Ye, J. Chen, Z. Wu, Augmented dual-contrastive aggregation learn- ing for unsupervised visible-infrared person re-identification, in: Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 2843–2851
work page 2022
-
[4]
Z. Wu, M. Ye, Unsupervised visible-infrared person re-identification via progres- sive graph matching and alternate learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9548–9558
work page 2023
- [5]
-
[6]
J. Shi, X. Yin, Y . Zhang, Y . Xie, Y . Qu, et al., Learning commonality, divergence and variety for unsupervised visible-infrared person re-identification, Advances in Neural Information Processing Systems 37 (2024) 99715–99734
work page 2024
-
[7]
X. Teng, L. Lan, D. Chen, K. Xu, N. Yin, Relieving universal label noise for un- supervised visible-infrared person re-identification by inferring from neighbors, in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 39, 2025, pp. 7356–7364
work page 2025
-
[8]
Z. Dai, G. Wang, W. Yuan, S. Zhu, P. Tan, Cluster contrast for unsupervised person re-identification, in: Proceedings of the Asian Conference on Computer Vision, 2022, pp. 1142–1160
work page 2022
- [9]
-
[10]
L. He, D. Cheng, N. Wang, X. Gao, Exploring homogeneous and heterogeneous consistent label associations for unsupervised visible-infrared person reid, Inter- national Journal of Computer Vision (2024) 1–20. 30
work page 2024
-
[11]
M. Ye, Z. Wu, B. Du, Dual-level matching with outlier filtering for unsupervised visible-infrared person re-identification, IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
work page 2025
-
[12]
B. Yang, J. Chen, M. Ye, Towards grand unified representation learning for unsupervised visible-infrared person re-identification, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 11069– 11079
work page 2023
-
[13]
Z. Pang, C. Wang, L. Zhao, Y . Liu, G. Sharma, Cross-modality hierarchical clus- tering and refinement for unsupervised visible-infrared person re-identification, IEEE Transactions on Circuits and Systems for Video Technology (2023)
work page 2023
-
[14]
B. Yang, J. Chen, M. Ye, Shallow-deep collaborative learning for unsupervised visible-infrared person re-identification, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2024, pp. 16870–16879
work page 2024
- [15]
-
[16]
T. Kim, S. Shin, Y . Yu, H. G. Kim, Y . M. Ro, Causal mode multiplexer: A novel framework for unbiased multispectral pedestrian detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26784–26793
work page 2024
-
[17]
X. Li, Y . Lu, B. Liu, Y . Liu, G. Yin, Q. Chu, J. Huang, F. Zhu, R. Zhao, N. Yu, Counterfactual intervention feature transfer for visible-infrared person re- identification, in: European Conference on Computer Vision, Springer, 2022, pp. 381–398
work page 2022
- [18]
-
[19]
Z. Yang, M. Lin, X. Zhong, Y . Wu, Z. Wang, Good is bad: Causality inspired cloth-debiasing for cloth-changing person re-identification, in: Proceedings of 31 the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1472–1481
work page 2023
- [20]
-
[21]
X.-C. Li, X. Xia, F. Zhu, T. Liu, X.-Y . Zhang, C.-L. Liu, Dynamics-aware loss for learning with label noise, Pattern Recognition 144 (2023) 109835
work page 2023
-
[22]
J. Han, P. Luo, X. Wang, Deep self-learning from noisy labels, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5138– 5147
work page 2019
- [23]
- [24]
-
[25]
Q. He, Z. Wang, Z. Zheng, H. Hu, Spatial and temporal dual-attention for unsu- pervised person re-identification, IEEE Transactions on Intelligent Transportation Systems 25 (2) (2023) 1953–1965
work page 2023
-
[26]
Y . Cho, W. J. Kim, S. Hong, S.-E. Yoon, Part-based pseudo label refinement for unsupervised person re-identification, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2022, pp. 7308–7318
work page 2022
-
[27]
J. Shi, Y . Zhang, X. Yin, Y . Xie, Z. Zhang, J. Fan, Z. Shi, Y . Qu, Dual pseudo- labels interactive self-training for semi-supervised visible-infrared person re- identification, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 11218–11228. 32
work page 2023
-
[28]
J. Shi, X. Yin, Y . Chen, Y . Zhang, Z. Zhang, Y . Xie, Y . Qu, Multi-memory match- ing for unsupervised visible-infrared person re-identification, in: European Con- ference on Computer Vision, Springer, 2024, pp. 456–474
work page 2024
-
[29]
In Defense of the Triplet Loss for Person Re-Identification
A. Hermans, L. Beyer, B. Leibe, In defense of the triplet loss for person re- identification, arXiv preprint arXiv:1703.07737 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [30]
-
[31]
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, Y . Ben- gio, Show, attend and tell: Neural image caption generation with visual attention, in: International conference on machine learning, PMLR, 2015, pp. 2048–2057
work page 2015
-
[32]
C. Jambigi, R. Rawal, A. Chakraborty, Mmd-reid: A simple but effective solution for visible-thermal person reid, arXiv preprint arXiv:2111.05059 (2021)
- [33]
-
[34]
D. T. Nguyen, H. G. Hong, K. W. Kim, K. R. Park, Person recognition system based on a combination of body images from visible light and thermal cameras, Sensors 17 (3) (2017) 605
work page 2017
- [35]
-
[36]
M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, S. C. Hoi, Deep learning for person re-identification: A survey and outlook, IEEE transactions on pattern analysis and machine intelligence 44 (6) (2021) 2872–2893. 33
work page 2021
-
[37]
X. Wang, R. Girshick, A. Gupta, K. He, Non-local neural networks, in: Proceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7794–7803
work page 2018
-
[38]
F. Radenovi ´c, G. Tolias, O. Chum, Fine-tuning cnn image retrieval with no human annotation, IEEE transactions on pattern analysis and machine intelligence 41 (7) (2018) 1655–1668
work page 2018
-
[39]
C. Chen, M. Ye, M. Qi, J. Wu, J. Jiang, C.-W. Lin, Structure-aware positional transformer for visible-infrared person re-identification, IEEE Transactions on Image Processing 31 (2022) 2352–2364
work page 2022
- [40]
-
[41]
H. Yu, X. Cheng, W. Peng, W. Liu, G. Zhao, Modality unifying network for visible-infrared person re-identification, in: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision, 2023, pp. 11185–11195
work page 2023
-
[42]
J. Shi, X. Yin, D. Zhang, Z. Zhang, Y . Xie, Y . Qu, Two-stage knowledge dis- tillation for visible-infrared person re-identification, Pattern Recognition (2025) 111850
work page 2025
-
[43]
J. Wang, Z. Zhang, M. Chen, Y . Zhang, C. Wang, B. Sheng, Y . Qu, Y . Xie, Op- timal transport for label-efficient visible-infrared person re-identification, in: Eu- ropean Conference on Computer Vision, Springer, 2022, pp. 93–109
work page 2022
-
[44]
X. Zhu, L. Dong, X. Chen, X. Zhang, F. Qi, X.-Y . Jing, Confidence guided semi-supervised cross-modality person re-identification, Pattern Recognition 165 (2025) 111669
work page 2025
-
[45]
Y . Yang, W. Hu, H. Hu, Progressive cross-modal association learning for unsuper- vised visible-infrared person re-identification, IEEE Transactions on Information Forensics and Security (2025). 34
work page 2025
-
[46]
Y . Li, Y . Sun, Y . Qin, D. Peng, X. Peng, P. Hu, Robust dual- ity learning for unsupervised visible-infrared person re-identification, IEEE Transactions on Information Forensics and Security 20 (2025) 1937–1948. doi:10.1109/TIFS.2025.3536613
- [47]
-
[48]
H. Park, S. Lee, J. Lee, B. Ham, Learning by aligning: Visible-infrared per- son re-identification using cross-modal correspondences, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12046–12055
work page 2021
-
[49]
M. Yang, Z. Huang, P. Hu, T. Li, J. Lv, X. Peng, Learning with twin noisy labels for visible-infrared person re-identification, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 14308–14317
work page 2022
-
[50]
Y . Feng, F. Chen, G. Sun, F. Wu, Y . Ji, T. Liu, S. Liu, X.-Y . Jing, J. Luo, Learning multi-granularity representation with transformer for visible-infrared person re- identification, Pattern Recognition 164 (2025) 111510
work page 2025
-
[51]
Z. Pang, L. Zhao, Y . Liu, G. Sharma, C. Wang, Inter-modality similarity learning for unsupervised multi-modality person re-identification, IEEE Transactions on Circuits and Systems for Video Technology 34 (10) (2024) 10411–10423
work page 2024
-
[52]
L. van der Maaten, G. Hinton, Visualizing data using t-sne. journal of machine learning research 9, Nov (2008) (2008)
work page 2008
-
[53]
D. Cournapeau, G. members, scikit-learn, https://scikit-learn.org/stable/index.html(2007)
work page 2007
-
[54]
M. Ester, H.-P. Kriegel, J. Sander, X. Xu, et al., A density-based algorithm for discovering clusters in large spatial databases with noise, in: kdd, V ol. 96, 1996, pp. 226–231. 35
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.