LEDDS: Portable LBM-DEM simulations on GPUs
Pith reviewed 2026-05-17 00:51 UTC · model grok-4.3
The pith
LBM-DEM simulations achieve hand-tuned CUDA performance using only portable parallel primitives on GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
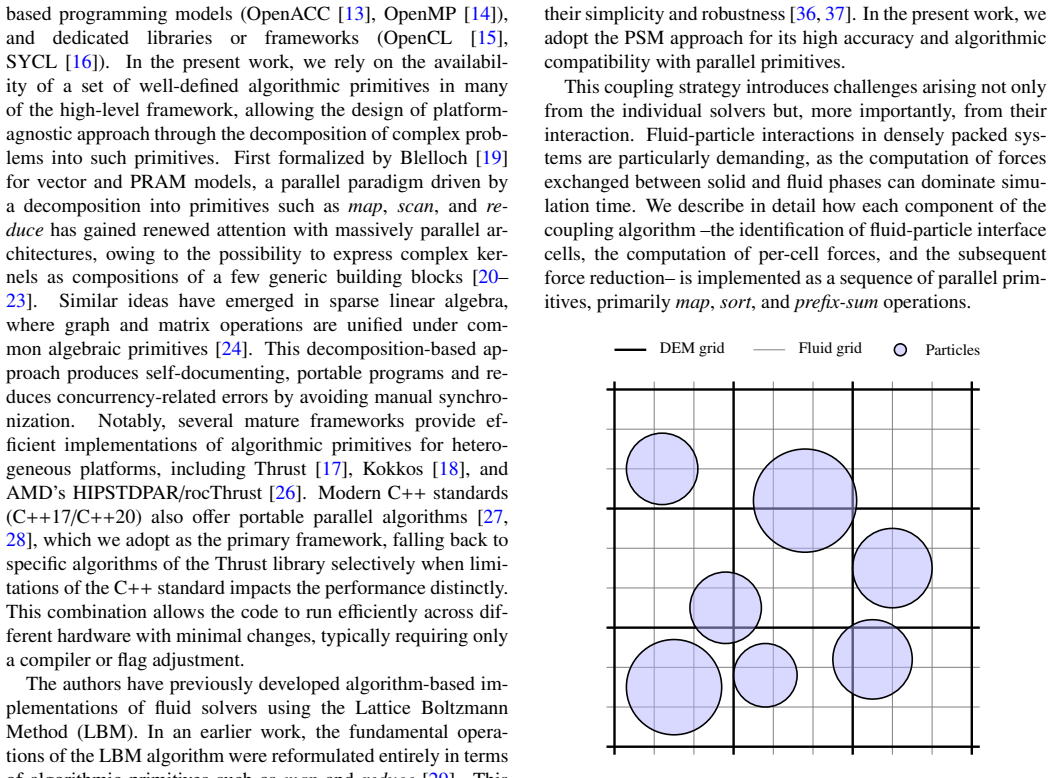
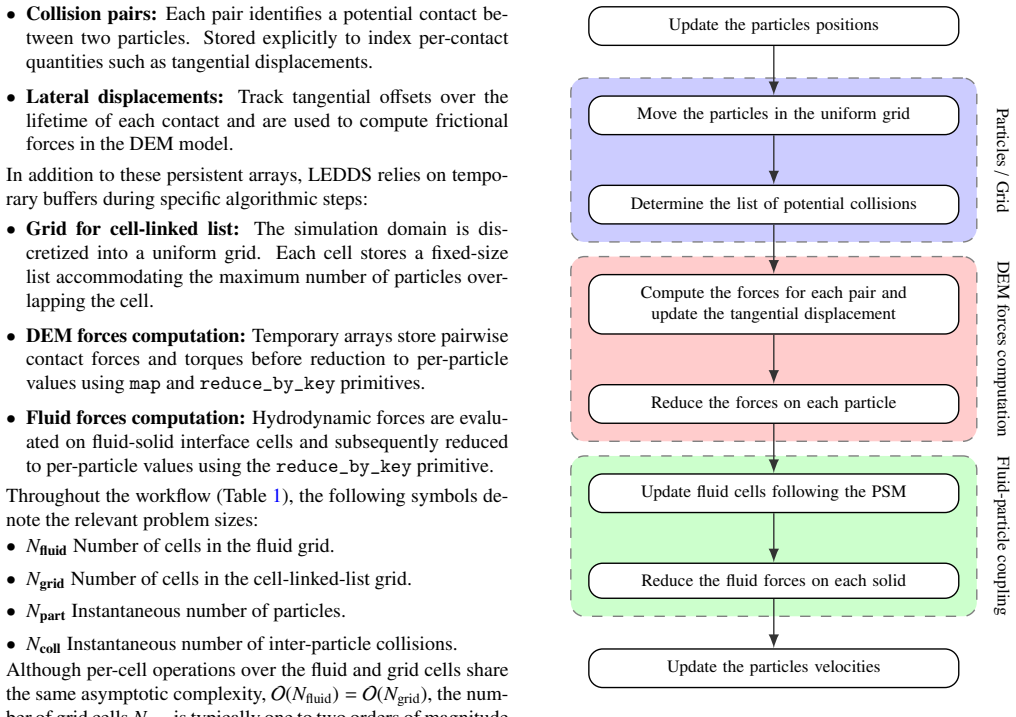
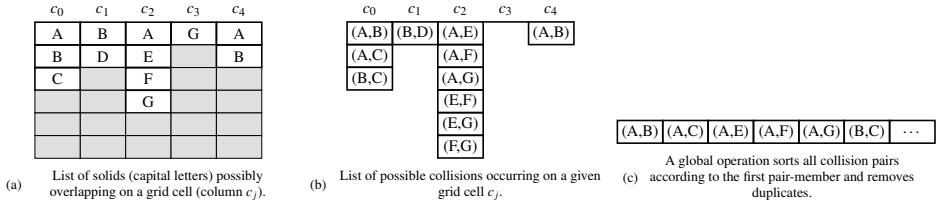
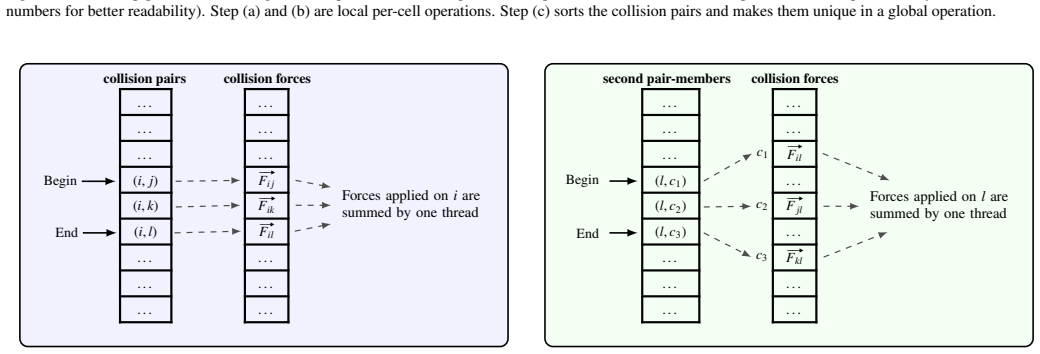
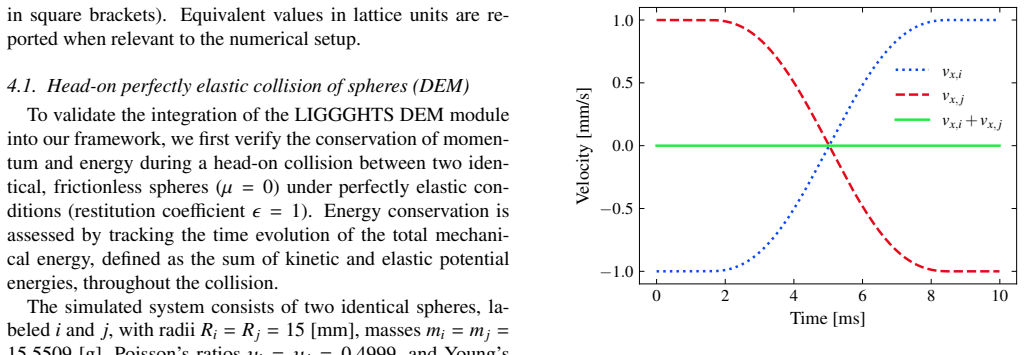
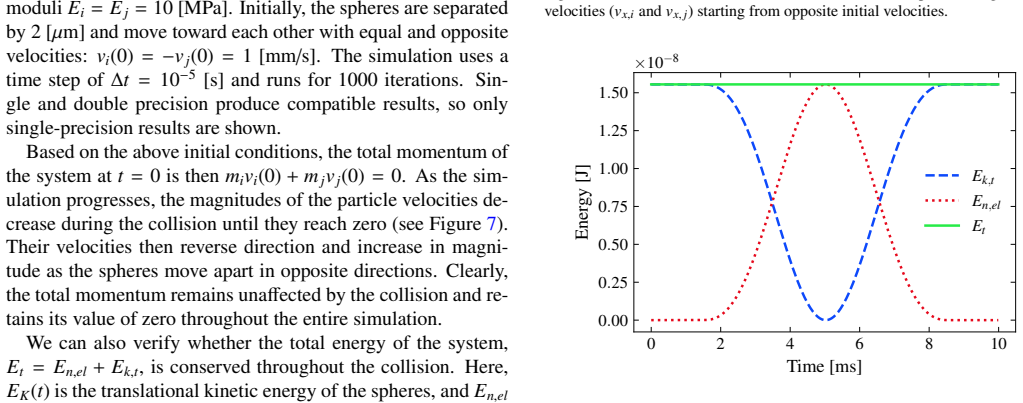
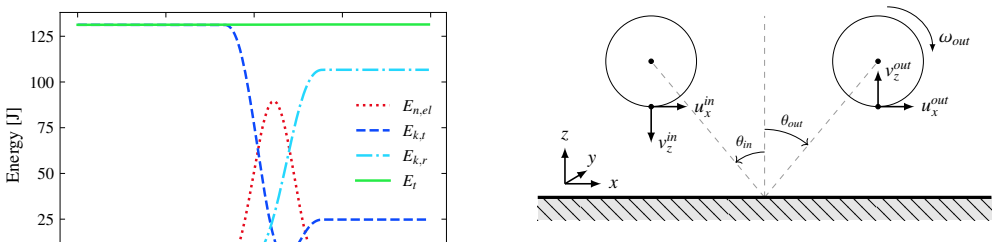
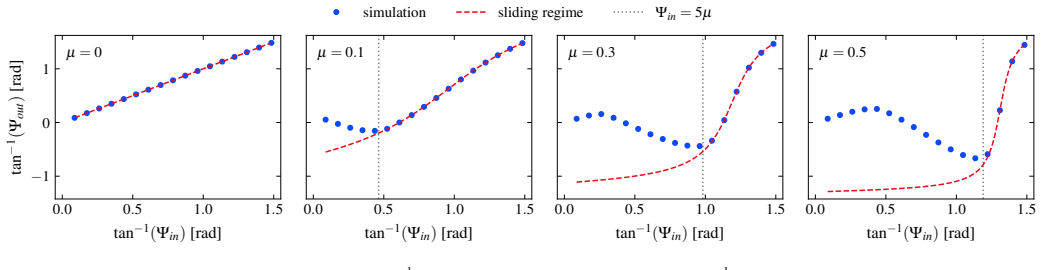
LEDDS demonstrates that fully coupled LBM-DEM simulations can be performed by composing the entire workflow from algorithmic primitives rather than handcrafted GPU kernels. The full process of neighbor search, collision detection, and fluid-particle coupling is expressed as portable operations, and the resulting code runs efficiently on single GPUs. Benchmarks confirm that this high-abstraction implementation matches the performance of hand-tuned CUDA solvers while remaining portable to other HPC environments and keeping the source code clear.
What carries the argument
Algorithmic formulations that express computations as compositions of well-defined parallel primitives such as map, sort, and reduce, applied to the full LBM-DEM workflow.
If this is right
- Performance comparable to hand-tuned CUDA solvers is achieved despite the high level of abstraction.
- The framework maintains portability across a wide range of modern GPU systems and future accelerators.
- Code clarity is preserved while delivering high performance for complex fluid-particle simulations.
- LEDDS serves as a blueprint for portable multiphysics frameworks based on algorithmic primitives.
- The method applies to both pure DEM and coupled LBM-DEM configurations across the listed validation cases.
Where Pith is reading between the lines
- Developers without specialized GPU programming expertise could more readily implement or modify such simulations.
- The primitive-based abstraction might extend to additional multiphysics couplings such as fluid-structure interactions.
- Standard libraries of parallel primitives could become a common foundation for scientific HPC codes.
- Long-term maintenance costs for simulation software may decrease as hardware changes require fewer code rewrites.
Load-bearing premise
That expressing neighbor search, collision detection, and fluid-particle coupling entirely through portable parallel primitives introduces no significant performance penalty or accuracy loss across the range of DEM and LBM-DEM benchmarks considered.
What would settle it
A side-by-side run of one of the paper's benchmarks, such as particle-laden shear flow or single-particle settling, on identical hardware where the LEDDS version runs substantially slower or produces measurably different physical quantities than a hand-tuned CUDA implementation.
Figures


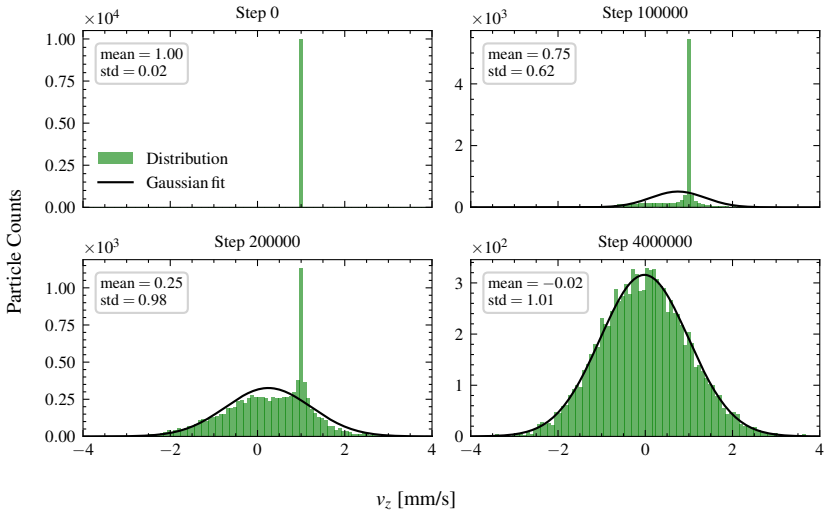
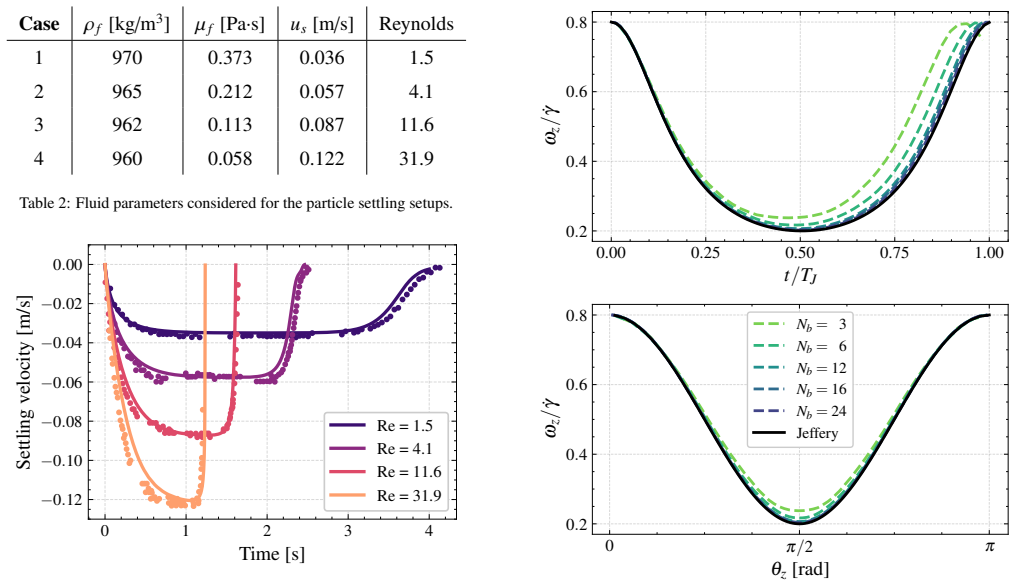

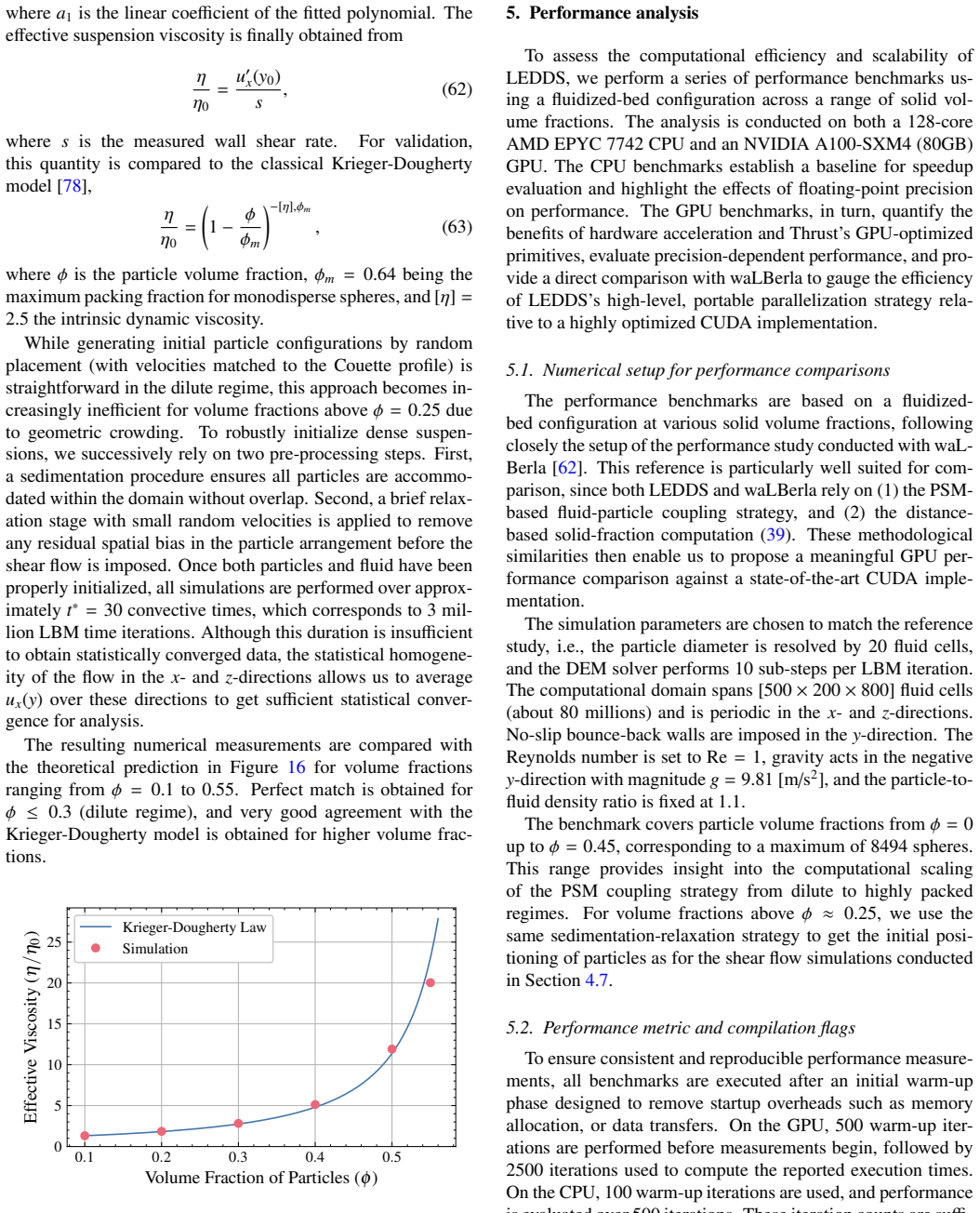
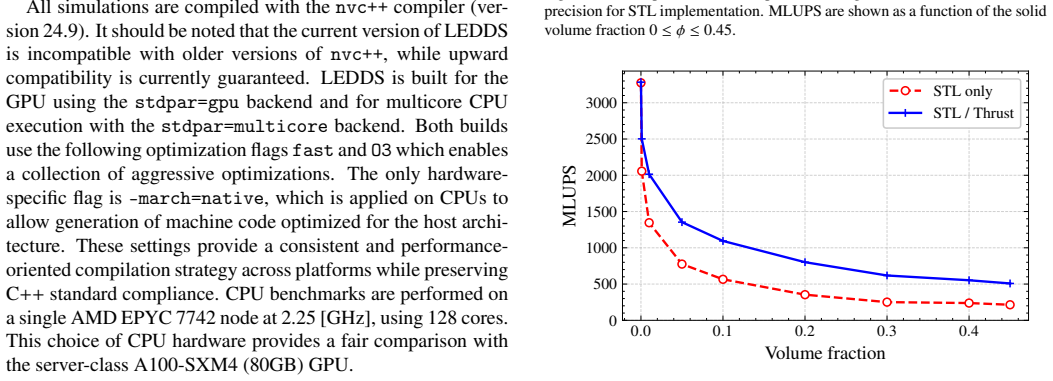
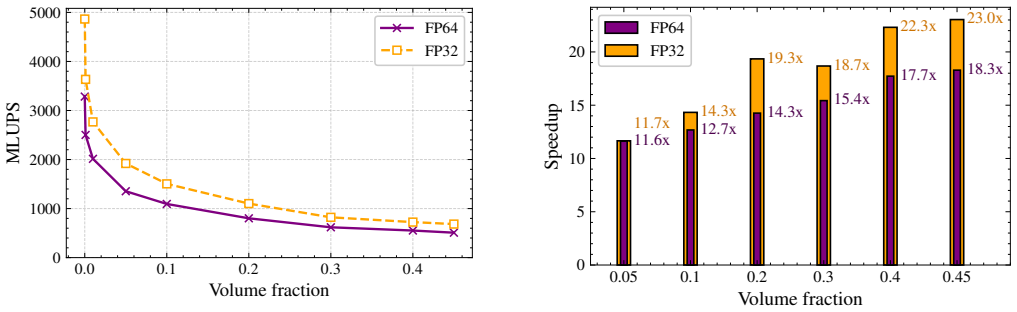
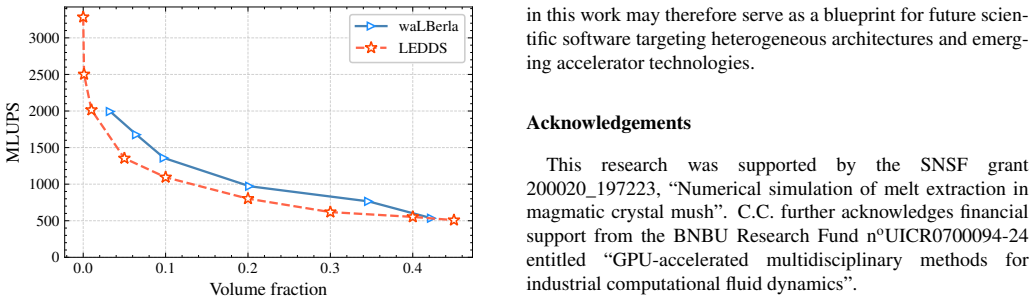
read the original abstract
Algorithmic formulations of GPU programs provide a high-level alternative to device-specific code by expressing computations as compositions of well-defined parallel primitives (e.g., map, sort, reduce), rather than through handcrafted GPU kernels. In this work, we demonstrate that this paradigm can be extended to complex and challenging problems in computational physics: the simulation of granular flows and fluid-particle interactions. LEDDS, our open-source framework, performs fully coupled Lattice Boltzmann -- Discrete Element Method (LBM-DEM) simulations using only algorithmic primitives, and runs efficiently on single-GPU platforms. The entire workflow, including neighbor search, collision detection, and fluid-particle coupling, is expressed as a sequence of portable primitives. While the current implementation illustrates these principles primarily through algorithms from the C++ Standard Library, with selective use of Thrust primitives for performance, the underlying concept is compatible with any HPC environment offering a rich set of parallel algorithms and is therefore applicable across a wide range of modern GPU systems and future accelerators. LEDDS is validated through benchmarks spanning both DEM and LBM-DEM configurations, including sphere and ellipsoid collisions, wall friction tests, single-particle settling, Jeffery's orbits, and particle-laden shear flows. Despite its high level of abstraction, LEDDS achieves performances comparable to those of hand-tuned CUDA solvers, while maintaining portability and code clarity. These results show that high-performance LBM-DEM coupling can be achieved without sacrificing generality or readability, establishing LEDDS as a blueprint for portable multiphysics frameworks based on algorithmic primitives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LEDDS, an open-source framework for fully coupled LBM-DEM simulations on single-GPU platforms. All components—neighbor search, collision detection, and fluid-particle coupling—are expressed exclusively as compositions of portable parallel primitives drawn from the C++ Standard Library with selective Thrust usage. The work validates the approach on DEM and LBM-DEM benchmarks (sphere/ellipsoid collisions, wall friction, single-particle settling, Jeffery orbits, particle-laden shear flow) and claims that the resulting performance remains comparable to hand-tuned CUDA implementations while preserving portability and readability.
Significance. If the reported benchmark outcomes hold, the result is significant: it supplies a concrete, reproducible demonstration that complex multiphysics codes can be written at a high level of algorithmic abstraction without incurring prohibitive performance penalties. The open-source release, the explicit mapping of physical operations onto standard parallel primitives, and the absence of device-specific kernels constitute clear strengths that could serve as a template for portable HPC frameworks on current and future accelerators.
minor comments (3)
- §4 (Implementation): the description of how the neighbor-search primitive is composed from std::sort and std::transform should include a short pseudocode listing or explicit call sequence so that readers can reproduce the mapping without inspecting the source repository.
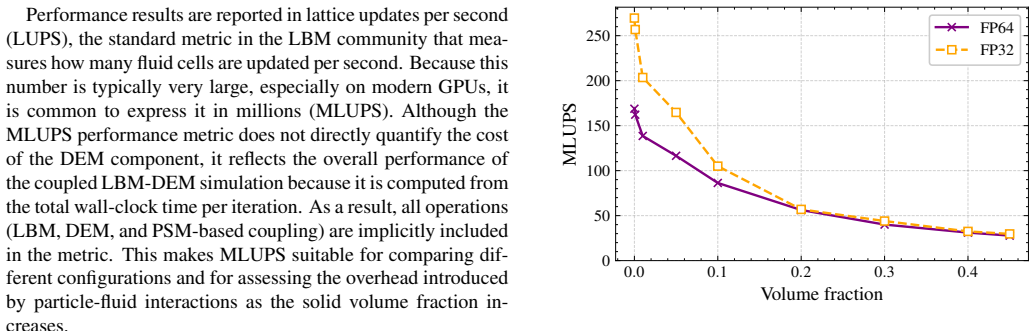
- Table 2 (Performance comparison): the reported wall-clock times for the LBM-DEM cases should be accompanied by the corresponding grid sizes, particle counts, and number of time steps to allow direct scaling comparisons with the cited hand-tuned CUDA references.
- §5.3 (Jeffery orbits): the statement that the computed orbits 'match analytical solutions' would be strengthened by reporting the L2 error norm or maximum angular deviation rather than a qualitative visual comparison alone.
Simulated Author's Rebuttal
We thank the referee for their positive and accurate summary of the LEDDS framework, its use of portable algorithmic primitives for LBM-DEM coupling, and the recommendation for minor revision. The significance assessment aligns with our goals of demonstrating high-level abstractions without prohibitive performance loss.
Circularity Check
No significant circularity
full rationale
This is an implementation and benchmarking paper with no mathematical derivations, fitted parameters, predictions, or first-principles results. The central claims rest on reported benchmark outcomes (sphere/ellipsoid collisions, Jeffery orbits, particle-laden flows) and direct performance comparisons between the primitive-based approach and hand-tuned CUDA. No step reduces by construction to its own inputs, and the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parallel primitives available in C++ Standard Library and Thrust are sufficient to express neighbor search, collision detection, and fluid-particle coupling at high performance on GPUs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LEDDS achieves performances comparable to those of hand-tuned CUDA solvers, while maintaining portability and code clarity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. A. Cundall, O. D. L. Strack, A discrete numerical model for granular assemblies, Géotechnique 29 (1) (1979) 47– 65. 22
work page 1979
-
[2]
H. Zhu, Z. Zhou, R. Yang, A. Yu, Discrete particle sim- ulation of particulate systems: Theoretical developments, Chem. Eng. Sci. 62 (13) (2007) 3378–3396, frontier of Chemical Engineering - Multi-scale Bridge between Re- ductionism and Holism
work page 2007
-
[3]
H. Zhu, Z. Zhou, R. Yang, A. Yu, Discrete particle simu- lation of particulate systems: A review of major applica- tions and findings, Chem. Eng. Sci. 63 (23) (2008) 5728– 5770
work page 2008
-
[4]
J. Zhao, T. Shan, Coupled CFD-DEM simulation of fluid- particle interaction in geomechanics, Powder Technol. 239 (2013) 248–258
work page 2013
- [5]
-
[6]
P. Kieckhefen, S. Pietsch, M. Dosta, S. Heinrich, Possibil- ities and limits of computational fluid dynamics – discrete element method simulations in process eengineering: A review of recent advancements and future trends, Annual Review of Chemical and Biomolecular Engineering 11 (1) (2020) 397–422, pMID: 32169000
work page 2020
-
[7]
H. Ma, L. Zhou, Z. Liu, M. Chen, X. Xia, Y . Zhao, A review of recent development for the CFD-DEM investi- gations of non-spherical particles, Powder Technol. 412 (2022) 117972
work page 2022
-
[8]
J. Gan, Z. Zhou, A. Yu, A GPU-based DEM approach for modelling of particulate systems, Powder Technology 301 (2016) 1172–1182
work page 2016
-
[9]
L. Lu, GPU accelerated MFiX-DEM simulations of gran- ular and multiphase flows, Particuology 62 (2022) 14–24
work page 2022
-
[10]
S. Fu, L. Wang, GPU-based unresolved LBM-DEM for fast simulation of gas–solid flows, Chemical Engineering Journal 465 (2023) 142898
work page 2023
-
[11]
J. Nickolls, I. Buck, M. Garland, K. Skadron, Scalable parallel programming with CUDA: Is CUDA the paral- lel programming model that application developers have been waiting for?, Queue 6 (2) (2008) 40–53
work page 2008
-
[12]
HIP (C++Heterogeneous- Compute Interface for Portability): https://rocm.docs.amd.com/projects/HIP/en/latest/. [link]
- [13]
-
[14]
R. Chandra, R. Menon, L. Dagum, D. Kohr, D. Maydan, J. McDonald, Parallel Programming in OpenMP, 1st Edi- tion, Elsevier, 2018
work page 2018
-
[15]
Munshi, The OpenCL specification, in: IEEE Hot Chips 21 Symposium (HCS), 2009, pp
A. Munshi, The OpenCL specification, in: IEEE Hot Chips 21 Symposium (HCS), 2009, pp. 1–314
work page 2009
- [16]
-
[17]
N. Bell, J. Hoberock, Thrust: A Productivity-Oriented Li- brary for CUDA, in: W. mei W. Hwu (Ed.), GPU Comput- ing Gems Jade Edition, Applications of GPU Computing Series, Morgan Kaufmann, Boston, 2012, pp. 359–371
work page 2012
-
[18]
H. Carter Edwards, C. R. Trott, D. Sunderland, Kokkos: Enabling manycore performance portability through poly- morphic memory access patterns, Journal of Parallel and Distributed Computing 74 (12) (2014) 3202–3216, domain-Specific Languages and High-Level Frameworks for High-Performance Computing
work page 2014
-
[19]
G. E. Blelloch, Prefix sums and their applications, Tech. Rep. CMU-CS-90-190, Carnegie Mellon Univer- sity, Pittsburgh, PA, technical Report, School of Computer Science (1990)
work page 1990
-
[20]
S. Sengupta, M. Harris, Y . Zhang, J. D. Owens, Scan primitives for gpu computing, in: Proceedings of the 22nd ACM SIGGRAPH/EUROGRAPHICS Symposium on Graphics Hardware, Eurographics Association, Aire- la-Ville, Switzerland, 2007, pp. 97–106
work page 2007
-
[21]
J. Shun, G. E. Blelloch, A simple and practical linear- work parallel algorithm for connectivity, in: Proceedings of the 26th ACM Symposium on Parallelism in Algo- rithms and Architectures (SPAA ’14), ACM, New York, NY , USA, 2014, pp. 143–153
work page 2014
-
[22]
D. Dhulipala, G. E. Blelloch, J. Shun, Theoretically effi- cient parallel graph algorithms can be fast and scalable, ACM Transactions on Parallel Computing 5 (1) (2018) 1– 49
work page 2018
-
[23]
A. Brahmakshatriya, A. Brahmakshatriya, P. Sadayappan, J. D. Owens, Compilation techniques for graph algorithms on gpus, arXiv preprint arXiv:2012.07990 (2020)
-
[24]
Buluç, Linear algebraic primitives for parallel comput- ing on large graphs, Ph.D
A. Buluç, Linear algebraic primitives for parallel comput- ing on large graphs, Ph.D. thesis, University of California, Santa Barbara (2010)
work page 2010
-
[25]
H. C. Edwards, C. R. Trott, D. Sunderland, Kokkos: En- abling manycore performance portability through poly- morphic memory access patterns, Journal of Parallel and Distributed Computing 74 (12) (2014) 3202–3216
work page 2014
-
[26]
AMD, Hipstdpar: Standard c++parallel algorithms on amd gpus,https://gpuopen.com/learn/ hipstdpar/, accessed: 2025-10-14 (2023). 23
work page 2025
-
[27]
J. Larkin, No More Porting: Coding for GPUs with Standard C++, Fortran, and Python, in: NVIDIA GTC (spring), 2022
work page 2022
- [28]
-
[29]
J. Latt, C. Coreixas, J. Beny, Cross-platform programming model for many-core lattice Boltzmann simulations, PLoS One 16 (4) (2021) 1–29
work page 2021
- [30]
-
[31]
C. Coreixas, J. Latt, Gpu-based compressible lattice boltz- mann simulations on non-uniform grids using standard c++parallelism: From best practices to aerodynamics, aeroacoustics and supersonic flow simulations, Computer Physics Communications 317 (2025) 109833
work page 2025
-
[32]
C. Coreixas, J. Latt, X. Shan, No more porting: GPU acceleration of lattice Boltzmann and finite difference solvers via C++parallel algorithms, in: Symposium on high fidelity LES/DNS (HiFiLeD) for industrial relevant flow configurations, 2022
work page 2022
-
[33]
C. Rettinger, U. Rüde, A comparative study of fluid– particle coupling methods for fully resolved lattice boltz- mann simulations, Computers & Fluids 154 (2017) 74–89
work page 2017
-
[34]
C. Rettinger, U. Rüde, A coupled lattice boltzmann method and discrete element method for discrete particle simulations of particulate flows, Computers & Fluids 172 (2018) 706–719
work page 2018
-
[35]
Y . Thorimbert, F. Marson, A. Parmigiani, B. Chopard, J. Latt, Lattice boltzmann simulation of dense rigid spherical particle suspensions using immersed boundary method, Computers & Fluids 166 (2018) 286–294
work page 2018
-
[36]
D. R. Noble, J. R. Torczynski, A Lattice-Boltzmann Method for Partially Saturated Computational Cells, In- ternational Journal of Modern Physics C 09 (08) (1998) 1189–1201
work page 1998
-
[37]
C. Rettinger, U. Rüde, An efficient four-way coupled lat- tice boltzmann – discrete element method for fully re- solved simulations of particle-laden flows, J. Comput. Phys. 453 (2022) 110942
work page 2022
- [38]
- [39]
-
[40]
B. Lambert, L. Weynans, M. Bergmann, Methodology for numerical simulations of ellipsoidal particle-laden flows, International Journal for Numerical Methods in Fluids 92 (8) (2020) 855–873
work page 2020
-
[41]
R. D. Mindlin, Compliance of Elastic Bodies in Contact, Journal of Applied Mechanics 16 (3) (2021) 259–268
work page 2021
-
[42]
R. Maggio-Aprile, GPU-based simulation of dense sus- pensions: Coupling the DEM and the LBM in standard C++, Master thesis (2017)
work page 2017
-
[43]
L. Verlet, Computer "experiments" on classical flu- ids. I. Thermodynamical properties of Lennard-Jones molecules, Phys. Rev. 159 (1967) 98–103
work page 1967
-
[44]
R. D. Skeel, Integration schemes for molecular dynam- ics and related applications, Springer Berlin Heidelberg, Berlin, Heidelberg, 1999, pp. 119–176
work page 1999
-
[45]
X. Shan, X.-F. Yuan, H. Chen, Kinetic theory representa- tion of hydrodynamics: A way beyond the Navier–Stokes equation, J. Fluid Mech. 550 (2006) 413–441
work page 2006
-
[46]
P. J. Dellar, An interpretation and derivation of the lattice Boltzmann method using Strang splitting, Comput. Math. Appl. 65 (2) (2013) 129 – 141
work page 2013
-
[47]
F. Schornbaum, U. Rüde, Massively parallel algorithms for the lattice Boltzmann method on nonuniform grids, SIAM J. Sci. Comput 38 (2) (2016) C96–C126
work page 2016
- [48]
-
[49]
A. Suss, I. Mary, T. Le Garrec, S. Marié, Comprehensive comparison between the lattice Boltzmann and Navier- Stokes methods for aerodynamic and aeroacoustic appli- cations, Comput. Fluids 257 (2023) 105881
work page 2023
-
[50]
P. L. Bhatnagar, E. P. Gross, M. Krook, A Model for Col- lision Processes in Gases. I. Small Amplitude Processes in Charged and Neutral One-Component Systems, Physi- cal Review 94 (3) (1954) 511–525, publisher: American Physical Society
work page 1954
-
[51]
C. Coreixas, B. Chopard, J. Latt, Comprehensive compar- ison of collision models in the lattice Boltzmann frame- work: Theoretical investigations, Phys. Rev. E 100 (2019) 033305
work page 2019
-
[52]
C. Coreixas, G. Wissocq, B. Chopard, J. Latt, Impact of collision models on the physical properties and the stabil- ity of lattice Boltzmann methods, Phil. Trans. R. Soc. A 378 (2175) (2020) 20190397
work page 2020
-
[53]
I. Ginzburg, F. Verhaeghe, D. d’Humières, Two- relaxation-time lattice Boltzmann scheme: About parametrization, velocity, pressure and mixed boundary conditions, Commun. Comput. Phys. 3 (2) (2008) 427– 478. 24
work page 2008
-
[54]
D. d’Humières, I. Ginzburg, Viscosity independent nu- merical errors for lattice Boltzmann models: From recur- rence equations to “magic” collision numbers, Comput. Math. Appl. 58 (5) (2009) 823 – 840
work page 2009
- [55]
-
[56]
A. J. C. Ladd, Numerical simulations of particulate suspensions via a discretized Boltzmann equation. Part
- [57]
-
[58]
T. Krüger, Computer Simulation Study of Collective Phe- nomena in Dense Suspensions of Red Blood Cells under Shear, Vieweg+Teubner Verlag, Wiesbaden, 2012
work page 2012
-
[59]
C. Rettinger, S. Eibl, U. Rüde, B. V owinckel, Rheology of mobile sediment beds in laminar shear flow: effects of creep and polydispersity, Journal of Fluid Mechanics 932 (2022) A1
work page 2022
-
[60]
G. T. Nguyen, E. L. Chan, T. Tsuji, T. Tanaka, K. Washino, Resolved cfd–dem coupling simulation using volume penalisation method, Advanced Powder Technol- ogy 32 (1) (2021) 225–236
work page 2021
-
[61]
C. Tsigginos, J. Meng, X.-J. Gu, D. R. Emerson, Cou- pled LBM-DEM simulations using the partially saturated method: Theoretical and computational aspects, Powder Technology 405 (2022) 117556
work page 2022
-
[62]
B. D. Jones, J. R. Williams, Fast computation of accurate sphere-cube intersection volume, Engineering Computa- tions 34 (4) (2017) 1204–1216, publisher: Emerald Pub- lishing Limited
work page 2017
-
[63]
S. Kemmler, C. Rettinger, U. Rüde, P. Cuéllar, H. Köstler, Efficiency and scalability of fully-resolved fluid-particle simulations on heterogeneous cpu-gpu architectures, The International Journal of High Performance Computing Applications 39 (3) (2025) 345–363
work page 2025
-
[64]
P. Seil, LBDEMcoupling: implementation, validation, and applications of a coupled open-source solver for fluid- particle systems/eingereicht von Dipl.-Ing. Philippe Seil, 2016
work page 2016
-
[65]
Y . C. Chung, J. Y . Ooi, Benchmark tests for verifying discrete element modelling codes at particle impact level, Granular Matter 13 (5) (2011) 643–656
work page 2011
-
[66]
C. Rettinger, U. Rüde, An efficient four-way coupled lat- tice Boltzmann - discrete element method for fully re- solved simulations of particle-laden flows, Tech. Rep. arXiv:2003.01490, arXiv, arXiv:2003.01490 [physics] type: article (Mar. 2020)
-
[67]
A. Doménech-Carbó, Analysis of rolling friction effects on oblique rebound by redefining tangential restitution and friction, Physics of Fluids 31 (4) (2019) 043302
work page 2019
-
[68]
S. F. Foerster, M. Y . Louge, H. Chang, K. Allia, Measure- ments of the collision properties of small spheres, Physics of Fluids 6 (3) (1994) 1108–1115
work page 1994
-
[69]
Boltzmann, Weitere studien über das wärmegle- ichgewicht unter gasmolekülen, Wien
L. Boltzmann, Weitere studien über das wärmegle- ichgewicht unter gasmolekülen, Wien. Ber. 66 (1872) 275–370
-
[70]
P. Bhatnagar, E. Gross, M. Krook, A model for colli- sion processes in gases. I. Small amplitude processes in charged and neutral one-component systems, Phys. Rev. 94 (1954) 511–525
work page 1954
-
[71]
A. ten Cate, C. H. Nieuwstad, J. J. Derksen, H. E. A. Van den Akker, Particle imaging velocimetry experiments and lattice-Boltzmann simulations on a single sphere set- tling under gravity, Physics of Fluids 14 (11) (2002) 4012–4025
work page 2002
-
[72]
G. B. Jeffery, L. N. G. Filon, The motion of ellipsoidal particles immersed in a viscous fluid, Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character 102 (715) (1922) 161–179
work page 1922
-
[73]
Einstein, Eine neue bestimmung der moleküldimensio- nen, Annalen der Physik 324 (2) (1906) 289–306
A. Einstein, Eine neue bestimmung der moleküldimensio- nen, Annalen der Physik 324 (2) (1906) 289–306
work page 1906
-
[74]
I. M. Krieger, T. J. Dougherty, A mechanism for non- newtonian flow in suspensions of rigid spheres, Transac- tions of The Society of Rheology 3 (1) (1959) 137–152
work page 1959
-
[75]
S. V . Lishchuk, I. Halliday, C. M. Care, Shear viscosity of bulk suspensions at low reynolds number with the three- dimensional lattice boltzmann method, Phys. Rev. E 74 (2006) 017701
work page 2006
- [76]
-
[77]
Y . Thorimbert, F. Marson, A. Parmigiani, B. Chopard, J. Lätt, Lattice Boltzmann simulation of dense rigid spherical particle suspensions using immersed boundary method, Computers & Fluids (2018) 286–294
work page 2018
-
[78]
J. Guo, Q. Zhou, R. C.-K. Wong, Effects of volume frac- tion and particle shape on the rheological properties of oblate spheroid suspensions, Physics of Fluids 33 (8) (2021) 081703
work page 2021
-
[79]
I. M. Krieger, T. J. Dougherty, A Mechanism for Non- Newtonian Flow in Suspensions of Rigid Spheres, Trans- actions of The Society of Rheology 3 (1) (1959) 137–152. 25
work page 1959
-
[80]
T. Bhowmick, J. Latt, Y . Wang, G. Bagheri, Palabos turret: A particle-resolved numerical framework for settling dy- namics of arbitrary-shaped particles, Computers & Fluids 299 (2025) 106696
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.