Guided Transfer Learning for Discrete Diffusion Models
Pith reviewed 2026-05-16 22:55 UTC · model grok-4.3
The pith
Guided transfer learning adapts discrete diffusion models to new distributions by guiding a fixed pretrained denoiser at linear cost in vocabulary size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
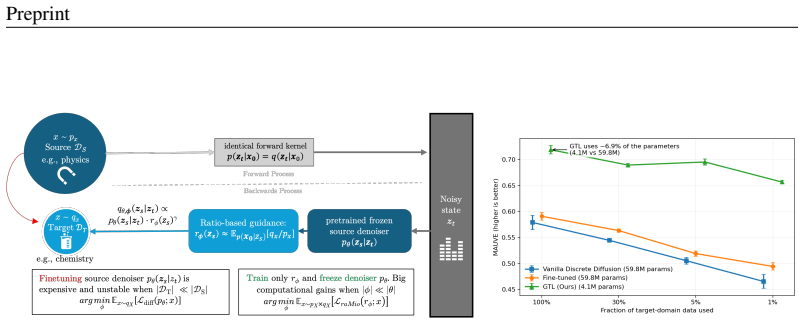
GTL enables sampling from a target distribution without modifying the pretrained denoiser and reduces the cost to linear scaling in vocabulary size, which in turn supports longer sequence generation. The approach is evaluated on sequential data including synthetic Markov chains and language modeling tasks, revealing a clear trade-off: weight fine-tuning is preferable for large target datasets, whereas GTL becomes increasingly effective as target data shrinks. A key failure mode occurs when source and target distributions overlap poorly, rendering the ratio-based classifier unreliable.
What carries the argument
The scheduling mechanism that approximates ratio-based guidance to achieve linear rather than prohibitive scaling with vocabulary size.
Load-bearing premise
The ratio-based classifier remains reliable enough to provide useful guidance when source and target distributions overlap only moderately.
What would settle it
An experiment that varies the degree of overlap between source and target distributions, measures the resulting accuracy of the ratio classifier on held-out samples, and checks whether transfer performance drops sharply below a measurable overlap threshold.
Figures


read the original abstract
Discrete diffusion models (DMs) have achieved strong performance in language and other discrete domains, offering a compelling alternative to autoregressive modeling. Yet this performance typically depends on large training datasets, challenging the performance of DMs in small-data regimes -- common under real-world constraints. Aimed at this challenge, recent work in continuous DMs suggests that transfer learning via classifier ratio-based guidance can adapt a pretrained DM to a related target distribution, often outperforming alternatives such as full-weight fine-tuning on the target data. By contrast, transfer learning for discrete DMs remains unexplored. We address this gap by exploring practical analogues of ratio-based transfer learning for discrete DMs. Our theoretical analysis shows that a direct extension of existing ratio-based guidance is computationally prohibitive, scaling with vocabulary size. To overcome this limitation, we introduce a scheduling mechanism that yields a practical algorithm, Guided Transfer Learning for discrete diffusion models (GTL). GTL enables sampling from a target distribution without modifying the pretrained denoiser and reduces the cost to linear scaling in vocabulary size, which in turn supports longer sequence generation. We evaluate GTL on sequential data, including synthetic Markov chains and language modeling tasks, and provide a detailed empirical analysis of its behavior. The results highlight a clear trade-off: when target datasets are large, weight fine-tuning is often preferable, whereas GTL becomes increasingly effective as target data shrinks. Finally, we experimentally demonstrate a key failure mode of GTL: when the source and target distributions overlap poorly, the ratio-based classifier required for guidance becomes unreliable, limiting transfer performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that direct application of classifier ratio guidance to discrete diffusion models incurs quadratic scaling in vocabulary size, which is prohibitive for long sequences. To address this, the authors derive a scheduling mechanism yielding Guided Transfer Learning (GTL), which enables sampling from a target distribution without modifying the pretrained denoiser at linear cost in vocabulary size. Empirically, GTL is evaluated on synthetic Markov chains and language modeling tasks, showing it outperforms fine-tuning when target data is scarce but fails when source-target overlap is poor because the ratio classifier becomes unreliable.
Significance. If the central claims hold, the work fills a clear gap in transfer learning for discrete DMs by providing a computationally tractable alternative to full fine-tuning in small-data regimes. The explicit linear-scaling derivation and the demonstration of a concrete failure mode are useful contributions that delineate applicability. The use of independent synthetic and language datasets strengthens the empirical component.
major comments (3)
- [Theoretical analysis] Theoretical analysis section: the derivation correctly flags quadratic scaling of naive ratio guidance, but the scheduling mechanism must be accompanied by an explicit before/after complexity table (or big-O derivation) showing that no hidden quadratic terms remain after scheduling; without this the linear-scaling claim is not fully substantiated.
- [Empirical evaluation] Empirical evaluation (key comparison tables/figures): reported performance differences between GTL and fine-tuning lack error bars, standard deviations, or results from multiple random seeds, so the claimed trade-off in the small-data regime cannot be assessed for statistical reliability.
- [Failure-mode analysis] Failure-mode section: the paper documents that the ratio classifier becomes unreliable under moderate source-target overlap, yet provides no quantitative mapping (e.g., overlap metric such as KL divergence versus classifier accuracy versus downstream sampling fidelity) that would bound the operating regime where GTL remains effective.
minor comments (2)
- [Notation and equations] Notation for the guidance schedule parameter should be introduced once and used consistently in all equations and pseudocode.
- [Figures] Figure captions for the language-modeling experiments should state the exact evaluation metrics, number of sequences sampled, and whether the same pretrained checkpoint is used across all methods.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important points for strengthening the theoretical and empirical claims. We address each major comment below and will incorporate the suggested revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the derivation correctly flags quadratic scaling of naive ratio guidance, but the scheduling mechanism must be accompanied by an explicit before/after complexity table (or big-O derivation) showing that no hidden quadratic terms remain after scheduling; without this the linear-scaling claim is not fully substantiated.
Authors: We agree that an explicit complexity comparison is needed to fully substantiate the linear-scaling claim. In the revised manuscript we will add a dedicated complexity table in the theoretical analysis section that contrasts the time and space complexity of naive ratio guidance (O(V^2) per step due to the full classifier ratio computation) against GTL after scheduling. We will also include a short big-O derivation showing that the scheduled guidance reduces the per-step cost to O(V) with no hidden quadratic terms, confirming the overall linear scaling in vocabulary size. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation (key comparison tables/figures): reported performance differences between GTL and fine-tuning lack error bars, standard deviations, or results from multiple random seeds, so the claimed trade-off in the small-data regime cannot be assessed for statistical reliability.
Authors: We acknowledge that the current results lack error bars and multi-seed statistics, which limits assessment of reliability. We will rerun all key experiments (synthetic Markov chains and language modeling tasks) using at least five independent random seeds, report means and standard deviations in the updated tables and figures, and add error bars to the performance plots. This will allow readers to evaluate the statistical significance of the observed trade-offs in the small-data regime. revision: yes
-
Referee: [Failure-mode analysis] Failure-mode section: the paper documents that the ratio classifier becomes unreliable under moderate source-target overlap, yet provides no quantitative mapping (e.g., overlap metric such as KL divergence versus classifier accuracy versus downstream sampling fidelity) that would bound the operating regime where GTL remains effective.
Authors: We agree that a quantitative mapping would better delineate the operating regime. In the revised failure-mode section we will compute KL divergence (and other overlap metrics) between source and target distributions across controlled overlap levels, plot these against classifier accuracy and downstream sampling fidelity (e.g., perplexity or generation quality), and include the resulting curves to bound where GTL remains reliable. This will provide readers with concrete guidance on applicability. revision: yes
Circularity Check
No significant circularity; derivation self-contained from first-principles analysis
full rationale
The paper's central derivation begins with a theoretical analysis establishing that a direct extension of continuous-domain ratio-based guidance to discrete DMs scales prohibitively with vocabulary size. It then introduces a scheduling mechanism to obtain the practical GTL algorithm that achieves linear scaling without modifying the pretrained denoiser. No load-bearing step reduces by construction to a fitted parameter, a self-citation, or a renamed input; the scheduling is presented as a new algorithmic choice justified by the scaling analysis. Empirical sections use independent synthetic Markov chains and language-modeling datasets for validation and explicitly document the classifier failure mode under poor overlap, rather than assuming it away. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- guidance schedule parameter
axioms (1)
- domain assumption The pretrained denoiser provides a valid approximation to the source score function.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 1 ... qψ⋆(zs(i) |z t(i)) = p(zs(i) |z t(i)) Ex0∼p(·|zs(i)) [q(x0)/p(x0)] / Σ ...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GTL enables sampling from a target distribution without modifying the pretrained denoiser and reduces the cost to linear scaling in vocabulary size
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
On the Limits of Latent Reuse in Diffusion Models
Reusing source latent spaces in diffusion models under distribution shift produces target score error set by principal-angle misalignment and diffusion-time-amplified ambient noise.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2507.00377. Minkai Xu, Tomas Geffner, Karsten Kreis, Weili Nie, Yilun Xu, Jure Leskovec, Stefano Ermon, and Arash Vahdat. Energy-based diffusion language models for text generation, 2025. URL https://arxiv.org/abs/2410.21357. Jiacheng Ye, Jiahui Gao, Shansan Gong, Lin Zheng, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Beyond autoreg...
-
[2]
For the Off–diagonal casey ′ ̸=y, henceδ y′,y = 0: qψ s|t(y′ |y) = δy′,y + eRθ t (y′,y)∆t rϕ(y′) P ˜y δ˜y,y + eRθ t (˜y,y)∆t rϕ(˜y) +O(∆t 2) = eRθ t (y′,y)r ϕ(y′) ∆t 1 rϕ(y) − ∆t S rϕ(y)2 +O(∆t 2) = eRθ t (y′,y)r ϕ(y′) rϕ(y) ∆t+O(∆t 2),
-
[3]
For the diagonal casey ′ =y: qψ s|t(y|y) = 1 +eRθ t (y,y) ∆t rϕ(y) rϕ(y) + ∆t S +O(∆t 2) = 1 +eRθ t (y,y) ∆t 1 + ∆t S rϕ(y) +O(∆t 2) = 1 +eRθ t (y,y) ∆t 1− ∆t S rϕ(y) +O(∆t 2) = 1 + h eRθ t (y,y)− S rϕ(y) i ∆t+O(∆t 2). Putting these two cases together, we arrive at the following: qψ s|t(y′ |y) =δ y′,y h 1 + eRθ t (y,y)− X ˜y eRθ t (˜y,y) rϕ(˜y) rϕ(y) ∆t i...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.