MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Pith reviewed 2026-05-16 20:26 UTC · model grok-4.3
The pith
Cascaded motion and appearance experts generate realistic dance videos directly from music.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
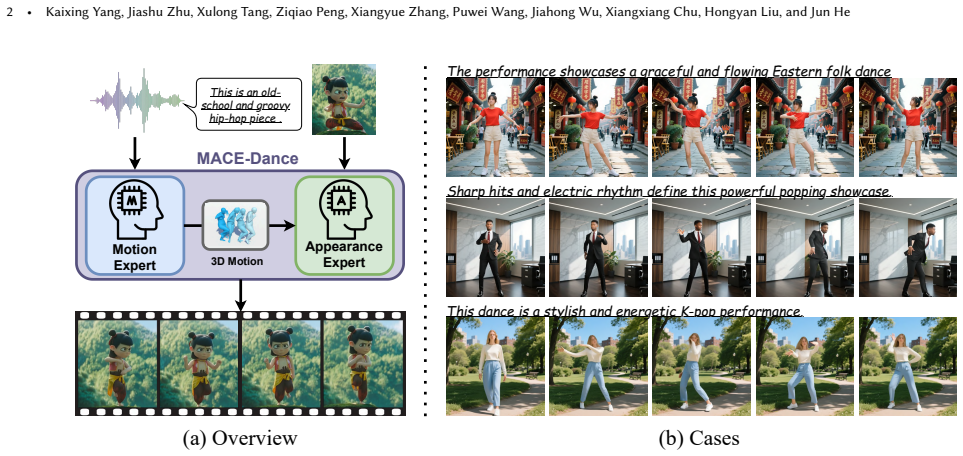
MACE-Dance decomposes music-driven dance video generation into cascaded Mixture-of-Experts stages: the Motion Expert produces 3D motions from audio using a diffusion model equipped with BiMamba-Transformer architecture and Guidance-Free Training to enforce both kinematic validity and artistic quality, while the Appearance Expert synthesizes the final video by conditioning on the generated motions and a reference image through decoupled kinematic-aesthetic fine-tuning that keeps visual identity and spatiotemporal coherence intact.
What carries the argument
The cascaded Motion-Appearance Experts, in which the Motion Expert performs music-to-3D-motion diffusion and the Appearance Expert performs motion- and reference-conditioned video synthesis.
If this is right
- 3D dance generation improves in both physical realism and stylistic variety when diffusion models are trained without classifier guidance.
- Pose-driven image animation reaches higher visual fidelity when kinematic and aesthetic objectives are optimized separately.
- A dedicated motion-appearance benchmark dataset enables consistent comparison across future music-to-video methods.
- The same cascaded structure can be reused for related tasks such as music-driven character animation in virtual environments.
Where Pith is reading between the lines
- The split could reduce compute during inference if the Motion Expert runs at lower frame rate than the video renderer.
- Extending the Appearance Expert to handle multiple reference images might improve robustness to changing outfits or lighting.
- The BiMamba component may offer efficiency gains when applied to other long-sequence motion tasks beyond dance.
Load-bearing premise
The two experts will combine without introducing noticeable motion-appearance mismatches or coherence loss in the final video.
What would settle it
Side-by-side videos in which the cascaded output shows visible jitter, identity drift, or foot-sliding artifacts that an end-to-end baseline avoids.
Figures












read the original abstract
With the rise of online dance-video platforms and rapid advances in AI-generated content (AIGC), music-driven dance generation has emerged as a compelling research direction. Despite substantial progress in related domains such as music-driven 3D dance generation, pose-driven image animation, and audio-driven talking-head synthesis, existing methods cannot be directly adapted to this task. Moreover, the limited studies in this area still struggle to jointly achieve high-quality visual appearance and realistic human motion. Accordingly, we present MACE-Dance, a music-driven dance video generation framework with cascaded Mixture-of-Experts (MoE). The Motion Expert performs music-to-3D motion generation while enforcing kinematic plausibility and artistic expressiveness, whereas the Appearance Expert carries out motion- and reference-conditioned video synthesis, preserving visual identity with spatiotemporal coherence. Specifically, the Motion Expert adopts a diffusion model with a BiMamba-Transformer hybrid architecture and a Guidance-Free Training (GFT) strategy, achieving state-of-the-art (SOTA) performance in 3D dance generation. The Appearance Expert employs a decoupled kinematic-aesthetic fine-tuning strategy, achieving state-of-the-art (SOTA) performance in pose-driven image animation. To better benchmark this task, we curate a large-scale and diverse dataset and design a motion-appearance evaluation protocol. Based on this protocol, MACE-Dance also achieves state-of-the-art performance. Code is available at https://github.com/AMAP-ML/MACE-Dance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MACE-Dance, a cascaded Mixture-of-Experts framework for music-driven dance video generation. The Motion Expert generates 3D dance motions from music via a diffusion model with BiMamba-Transformer hybrid architecture and Guidance-Free Training (GFT), claiming SOTA on 3D dance generation. The Appearance Expert performs motion- and reference-conditioned video synthesis via decoupled kinematic-aesthetic fine-tuning, claiming SOTA on pose-driven image animation. A new large-scale diverse dataset and motion-appearance evaluation protocol are introduced, on which the full cascaded model also claims SOTA performance.
Significance. If the integration of independently trained experts succeeds without coherence loss, the modular separation of motion generation and appearance synthesis offers a practical path to higher-quality music-driven dance videos, with direct applications in AIGC platforms. The new dataset and protocol provide independent benchmarking value for the community. Separate SOTA results on the two sub-tasks strengthen the case for the individual components, but the joint pipeline performance is the load-bearing claim.
major comments (2)
- [§4 and §3.2] §4 (Experiments) and §3.2 (Appearance Expert): the overall SOTA claim for the full video generation task is not supported by any reported metric quantifying the performance drop when the Appearance Expert receives model-generated motions instead of ground-truth motions. This ablation is required to validate that distributional shift between the two experts does not produce foot-skating, identity drift, or spatiotemporal artifacts.
- [Abstract and §3.1] Abstract and §3.1 (Motion Expert): the kinematic plausibility and artistic expressiveness claims rest on the GFT strategy and BiMamba-Transformer, yet no quantitative comparison (e.g., foot-contact error, motion diversity scores) is supplied against the strongest baselines when the full cascade is evaluated end-to-end.
minor comments (2)
- [§4.1] The dataset curation details (size, diversity metrics, train/test split) are referenced but not tabulated; adding a summary table would improve reproducibility.
- [§3.3] Notation for the cascaded inference pipeline (how motion latents are passed to the Appearance Expert) is described in prose but would benefit from an explicit diagram or pseudocode block.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that additional ablations are needed to strengthen the end-to-end claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 and §3.2] §4 (Experiments) and §3.2 (Appearance Expert): the overall SOTA claim for the full video generation task is not supported by any reported metric quantifying the performance drop when the Appearance Expert receives model-generated motions instead of ground-truth motions. This ablation is required to validate that distributional shift between the two experts does not produce foot-skating, identity drift, or spatiotemporal artifacts.
Authors: We agree this ablation is important to validate the cascaded pipeline. In the revised manuscript, we will add a dedicated ablation in §4 comparing Appearance Expert outputs conditioned on ground-truth motions versus Motion Expert-generated motions. Metrics will include foot-contact error for skating, face similarity for identity drift, and temporal consistency scores for artifacts, directly quantifying any performance drop due to distributional shift. revision: yes
-
Referee: [Abstract and §3.1] Abstract and §3.1 (Motion Expert): the kinematic plausibility and artistic expressiveness claims rest on the GFT strategy and BiMamba-Transformer, yet no quantitative comparison (e.g., foot-contact error, motion diversity scores) is supplied against the strongest baselines when the full cascade is evaluated end-to-end.
Authors: The Motion Expert's SOTA results in §3.1 and §4 already include kinematic metrics against baselines for the isolated 3D generation task. To address the full-cascade request, we will extend the motion-appearance evaluation protocol in the revision to report foot-contact error and motion diversity scores for the complete MACE-Dance pipeline versus end-to-end baselines, confirming preservation of kinematic plausibility. revision: yes
Circularity Check
No circularity: derivation relies on new dataset, protocol, and independent expert training
full rationale
The paper presents a cascaded MoE architecture with separately trained Motion Expert (diffusion + BiMamba-Transformer + GFT) and Appearance Expert (decoupled kinematic-aesthetic fine-tuning), supported by a newly curated large-scale dataset and a custom motion-appearance evaluation protocol. These elements provide external grounding for the SOTA claims rather than reducing any prediction or uniqueness result to fitted inputs or self-citations by construction. No equations or steps in the provided text exhibit self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central claim.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MACE-Dance, a music-driven dance video generation framework with cascaded Mixture-of-Experts (MoE). The Motion Expert performs music-to-3D motion generation while enforcing kinematic plausibility... The Appearance Expert carries out motion- and reference-conditioned video synthesis
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Motion Expert adopts Diffusion Model with BiMamba-Transformer hybrid architecture and Guidance-Free Training (GFT) strategy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Interactive Multi-Turn Retrieval for Health Videos
DATR combines coarse CLIP-based retrieval with multi-turn query fusion and cross-encoder re-ranking to improve health video retrieval, supported by the new MHVRC corpus.
-
CustomDancer: Customized Dance Recommendation by Text-Dance Retrieval
CustomDancer achieves state-of-the-art text-to-dance retrieval with 10.23% Recall@1 on the new TD-Data dataset by aligning text, music, and motion features through a CLIP-based framework.
-
MG-Former: A Transformer-Based Framework for Music-Driven 3D Conducting Gesture Generation
TransConductor generates 3D conducting gestures from music via a Trans-Temporal Music Encoder and Gesture Decoder, outperforming baselines on retrieval-based alignment metrics with a new ConductorMotion dataset.
Reference graph
Works this paper leans on
-
[1]
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen
Echomimicv3: 1.3 b parameters are all you need for unified multi-modal and multi-task human animation.arXiv preprint arXiv:2507.03905(2025). Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. 2023. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505(2023). Ziqiao Peng, Yi Chen, Yifeng Ma, Guozhen Zhang, Zhiy...
-
[2]
Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, Vol. 32. Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. 2022. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. InProceedings of the IEEE/CVF Conference ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.