How important is Recall for Measuring Retrieval Quality?
Pith reviewed 2026-05-16 20:32 UTC · model grok-4.3
The pith
Recall can be replaced by a simple alternative metric for assessing retrieval quality in realistic settings where the total relevant documents are unknown.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
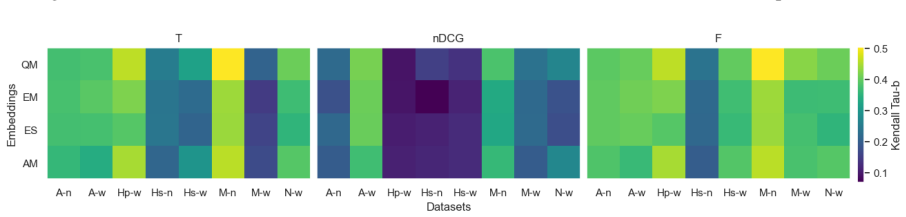
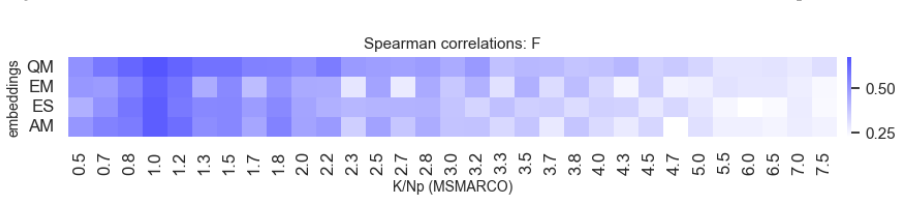
When the total number of relevant documents is unknown, retrieval quality can still be effectively gauged by metrics that do not require this information, as demonstrated by their strong correlation with LLM-assessed response quality from the retrieved set, and a newly introduced simple measure performs particularly well in this regard.
What carries the argument
The simple retrieval quality measure proposed in the paper, which evaluates performance on the retrieved documents without depending on the total number of relevant documents.
If this is right
- Metrics that avoid needing the total relevant count can substitute for recall in many evaluation scenarios.
- LLM-based response quality judgments correlate well enough with retrieval quality to serve as a proxy.
- The new simple measure shows strong performance across the tested datasets with low relevant document counts.
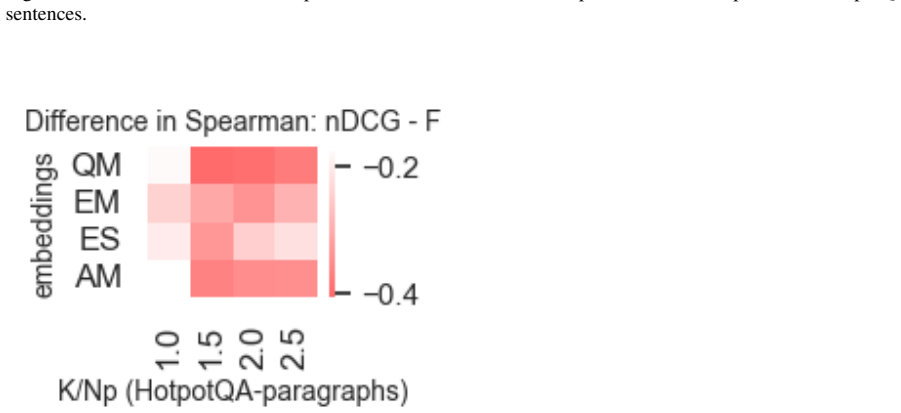
- Different established strategies for dealing with unknown recall have varying levels of success.
Where Pith is reading between the lines
- This method could simplify ongoing monitoring of retrieval systems in environments where relevance sets are incomplete or change frequently.
- It opens the possibility of optimizing retrieval directly for downstream response quality rather than traditional metrics.
- The findings might apply to other domains where complete ground truth is unavailable, such as web search or enterprise knowledge bases.
Load-bearing premise
LLM-based judgments of response quality serve as a reliable and unbiased proxy for true retrieval quality when recall cannot be computed.
What would settle it
A study that measures the correlation of the new measure against human judgments of response quality, using a dataset where the total number of relevant documents is fully known, to see if it matches or exceeds recall's correlation.
Figures





































read the original abstract
In realistic retrieval settings with large and evolving knowledge bases, the total number of documents relevant to a query is typically unknown, and recall cannot be computed. In this paper, we evaluate several established strategies for handling this limitation by measuring the correlation between retrieval quality metrics and LLM-based judgments of response quality, where responses are generated from the retrieved documents. We conduct experiments across multiple datasets with a relatively low number of relevant documents (2-15). We also introduce a simple retrieval quality measure that performs well without requiring knowledge of the total number of relevant documents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that recall is often uncomputable in realistic retrieval settings because the total number of relevant documents is unknown. It evaluates established strategies for handling this by measuring correlations between retrieval quality metrics and LLM-based judgments of response quality (generated from the retrieved documents). Experiments are conducted across multiple datasets with 2-15 relevant documents, and a new simple retrieval quality measure is introduced that performs well without requiring knowledge of the total number of relevant documents.
Significance. If the central claim holds after addressing validation gaps, the work could provide a practical alternative for retrieval evaluation in large or evolving knowledge bases where complete relevance sets are infeasible. The multi-dataset experiments add breadth, and the focus on proxy-based evaluation addresses a real operational constraint in IR systems.
major comments (2)
- [Experiments] Experimental description (abstract and methods): Although the datasets contain only 2-15 relevant documents—making ground-truth recall directly computable—the paper reports no direct comparison or correlation of the proposed measure (or baselines) against actual recall values. This is load-bearing for the claim that the measure 'performs well,' because the entire validation rests on unverified LLM judgments as a proxy.
- [Results] Validation approach (results and discussion): The performance of the new measure is established solely via correlation with LLM judgments of response quality. No analysis or controls are described to address potential confounds, such as the LLM drawing on parametric knowledge rather than the retrieved documents, which risks the correlations reflecting factors orthogonal to retrieval quality.
minor comments (2)
- [Abstract] The abstract gives no concrete definition or formula for the new retrieval quality measure, which should be stated explicitly (with any parameters) in the methods section for reproducibility.
- [Results] No mention of statistical significance testing or confidence intervals for the reported correlations, which would clarify whether observed differences are reliable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the experimental validation.
read point-by-point responses
-
Referee: [Experiments] Experimental description (abstract and methods): Although the datasets contain only 2-15 relevant documents—making ground-truth recall directly computable—the paper reports no direct comparison or correlation of the proposed measure (or baselines) against actual recall values. This is load-bearing for the claim that the measure 'performs well,' because the entire validation rests on unverified LLM judgments as a proxy.
Authors: We agree that, given the small number of relevant documents in these datasets, a direct comparison to ground-truth recall is feasible and would strengthen the validation. Although the paper's primary motivation concerns realistic settings where the total number of relevant documents is unknown, we will add correlations between the proposed measure (and baselines) and actual recall values in the revised results section to address this point. revision: yes
-
Referee: [Results] Validation approach (results and discussion): The performance of the new measure is established solely via correlation with LLM judgments of response quality. No analysis or controls are described to address potential confounds, such as the LLM drawing on parametric knowledge rather than the retrieved documents, which risks the correlations reflecting factors orthogonal to retrieval quality.
Authors: We acknowledge the risk of confounds from parametric knowledge in the LLM judgments. We will add controls in the revised manuscript, including explicit prompts instructing the model to rely solely on the retrieved documents for judgments and, where feasible, comparisons using retrieval-only evaluation setups to better isolate retrieval quality effects. revision: yes
Circularity Check
No significant circularity in derivation of new retrieval measure
full rationale
The paper introduces a simple retrieval quality measure and evaluates established strategies plus the new measure solely by their correlation with LLM-based judgments of response quality generated from retrieved documents. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described chain; the measure is presented as independent and the validation proxy (LLM judgments) is external to the measure's definition. On datasets with 2-15 relevant documents, recall remains computable but is deliberately not used for the new measure, keeping the reported performance independent of the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
shallow judging.Information Processing & Management, 54(1):37–59
Intelligent topic selection for low-cost infor- mation retrieval evaluation: A new perspective on deep vs. shallow judging.Information Processing & Management, 54(1):37–59. Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Ken- ton Lee, Kristina Toutanov...
-
[2]
Filip Radlinski and Nick Craswell
Active testing: An efficient and robust frame- work for estimating accuracy.arXiv. Filip Radlinski and Nick Craswell. 2010. Comparing the sensitivity of information retrieval metrics. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval, SIGIR ’10, page 667–674, New York, NY , USA. Associatio...
-
[3]
Daniel Valcarce, Alejandro Bellogín, Javier Parapar, and Pablo Castells
LLMs can patch up missing relevance judg- ments in evaluation.arXiv, arXiv:2405.04727. Daniel Valcarce, Alejandro Bellogín, Javier Parapar, and Pablo Castells. 2020. Assessing ranking metrics in top-N recommendation.Inf. Retr., 23(4):411–448. C.J. Van Rijsbergen. 1979.Information Retrieval, sec- ond edition. Butterworths, London. Liang Wang, Nan Yang, Xia...
-
[4]
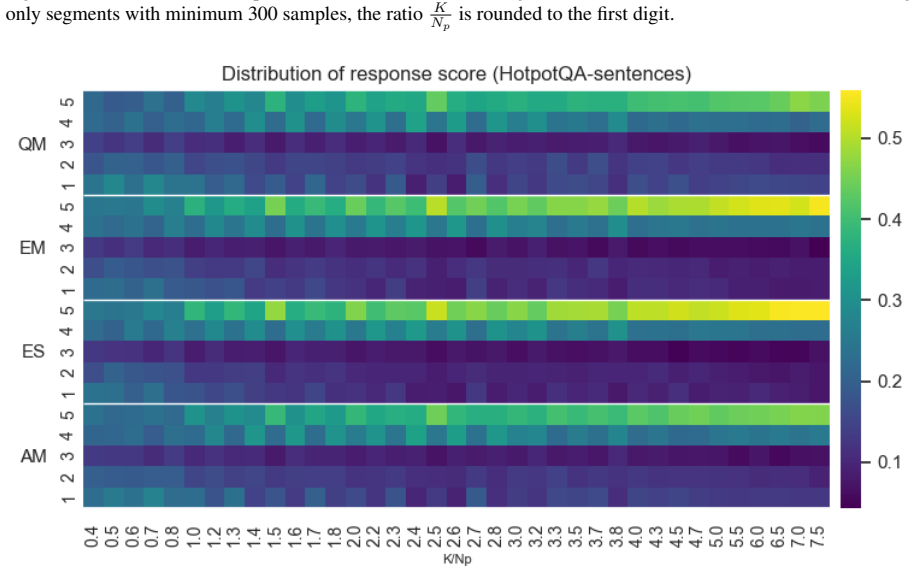
Graded samples 8https://huggingface.co/datasets/primer-ai/retrieval- response Figure 19: Distribution of the response score (1 to 5) for embedding models shown on Y-axis. On Natural Questions; using only segments with minimum 300 samples, the ratio K Np is rounded to the first digit. A.1.1 Query-texts samples Query-texts samples consist of 6112 samples, e...
-
[5]
id”: A string Id of the sample. The Id con- sists of a name of a subset, concatenated by “-
“id”: A string Id of the sample. The Id con- sists of a name of a subset, concatenated by “-” with Id of the item in the subset. For exam- ple, Id=“N-5” means that it is sample #5 from the subset Natural Questions. Each sample is uniquely identified by its Id
-
[6]
“p”: The list of positives
-
[7]
n”: The list of negatives. All the subsets in the dataset: “A
“n”: The list of negatives. All the subsets in the dataset: “A”, “Hp-e”, “Hp-h”, “Hp-m”, “Hs-e”, “Hs-h”, “Hs-m”, “M”, “N”. The short names, as explained in Section 2, are “A” for ARXIV , “H” for HotpotQA, “M” for MSMARCO and “N” for Natural Questions. HotpotQA appears with two different granulari- ties: The positives and negatives are (1) paragraphs in “H...
-
[8]
“c1”: The symbolic name of a category for positives. (The name of this category serves as the query and is stored with the key “q”.)
-
[9]
“c2”: The symbolic name of a category for negatives
-
[10]
q2”: The name of the category for negatives (not used). For example, a sample with id=“A-0
“q2”: The name of the category for negatives (not used). For example, a sample with id=“A-0” has c1=“math.ca”, c2=“math.pr”, q=“classical analysis and ODEs” and q2=“probability” (it also has a list of positives “p” and a list of negatives “n”). A.1.2 Ranked samples Each of the query-texts samples (Appendix A.1.1) can be used as a retrieval example with di...
-
[12]
The embedding used for ranking of all the candidates and selecting top- K candidates
“E”: The embedding’s short notation, as spec- ified in Section 2. The embedding used for ranking of all the candidates and selecting top- K candidates
-
[13]
“Nc”: Total number of candidates (positives and negatives), taken from the corresponding query-texts sample (with the same “id”)
-
[14]
Np”: Total number of positives, taken as the first Np positives “p
“Np”: Total number of positives, taken as the first Np positives “p” of the corresponding query-texts sample. (Negatives are also taken as firstN c-Np from the negatives “n”.)
-
[15]
K”: A sorted list of all the K (number of retrieved candidates, “top-K
“K”: A sorted list of all the K (number of retrieved candidates, “top-K”) used for this sample
-
[16]
P”: A list of precisions calculated for the top- K specified in the list “K
“P”: A list of precisions calculated for the top- K specified in the list “K”, in the same order. Has the same length as the list “K”
-
[17]
R”: A list of recalls calculated for the top-K specified in the list “K
“R”: A list of recalls calculated for the top-K specified in the list “K”, in the same order
-
[18]
“rank”: A list (length Nc) of indexes of all the candidates, sorted by ranks accordingly to co- sine similarities with query, by the embedding “E”. Each ranked sample is uniquely identified by the tuple (id, E, Nc, Np). In order to get the ranked texts corresponding to the “rank” list of a ranked sample Sr, its query- texts sample Sq (the sample with the ...
-
[19]
“id”: A string Id of the sample, the same as in the query-texts samples
-
[20]
“E”: The embedding’s short notation
-
[21]
“Nc”: Total number of candidates (positives and negatives)
-
[22]
“Np”: Total number of positives
-
[23]
“K”: A value of K (“top-K”) taken from the list of “K” in the corresponding ranked sample
-
[24]
rank”: A list equal to the first K elements of the list “rank
“rank”: A list equal to the first K elements of the list “rank” of the corresponding ranked sampleS r, i.e. Sr[“rank”][:K]
-
[25]
inK”: A list created from the “rank
“inK”: A list created from the “rank” (the item above), by replacement of each index by 1 (if positive) or 0 (if negative)
-
[26]
“answer_ideal”: LLM-generated answer to the query, obtained by using all the positives from the corresponding query-texts sample
-
[27]
“answer_topK”: LLN-generated answer to the query, obtained by using the retrieved K can- didates, given to LLM in their ranking order
-
[28]
“grade”: The LLM-generated score (on Link- ert scale from 1 to 5), obtained by comparing the top-K answer to the ideal answer, with the knowledge of the query
-
[29]
“P”: A value of precision corresponding to the selected K; given here for convenience
-
[30]
“R”: A value of recall corresponding to the selected K; given here for convenience. Each graded sample is uniquely identified by the tuple (id, E, Nc, Np, K) and it is related to its ranked sample by the tuple (id, E, Nc, Np). To assure an understanding of the data of a graded sample Sg and of the corresponding ranked sample Sr, see a few assertions in Fi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.