DRAGNs in the Forest: Identifying Artifacts with Random Forest Models in the VLASS DRAGNs Catalog
Pith reviewed 2026-05-16 20:00 UTC · model grok-4.3
The pith
Random forest models classify VLASS DRAGNs by artifact count to enable extraction of a 99.3% complete and 97.7% artifact-free catalog.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors train random forest models to classify DRAGNs according to the number of artifacts they contain, ranging from zero to three. The optimized model attains a weighted F1 score of 97.01%^{+1.12%}_{-1.32%}. Applying these classifications produces a catalog of VLASS DRAGNs from which an estimated 99.3% complete catalog of 97.7% artifact-free sources can be extracted.
What carries the argument
Random forest classifiers trained to predict artifact multiplicity (0-3) per DRAGN using features from the VLASS Quick Look catalog.
Load-bearing premise
The training labels correctly identify the true number of artifacts in each source and the model generalizes to the full catalog without distribution shift.
What would settle it
Independent visual or higher-resolution inspection of a random sample of sources predicted to contain zero artifacts, to verify whether they are actually free of artifacts.
Figures













read the original abstract
The Quick Look data products from the Very Large Array Sky Survey (VLASS) contain widespread imaging artifacts arising from the simplified imaging algorithm used in their production. The catalog of double radio sources associated with active galactic nuclei (DRAGNs) found in the VLASS first epoch Quick Look release using the DRAGNhunter algorithm suffers from contamination from these artifacts. These sources contain two or three individual components, each of which can be an artifact. We train random forest models to classify these DRAGNs based on the number of artifacts they contain, ranging from zero to three artifacts. We optimize our models and mitigate the class imbalance of our dataset with judicious training set selection, and the best of our models achieves a weighted F1 score of $97.01\%^{+1.12\%}_{-1.32\%}$. Using our classifications, we produce a catalog of VLASS DRAGNs from which an estimated 99.3% complete catalog of 97.7% artifact-free sources can be extracted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains random forest classifiers on human-labeled VLASS DRAGNs to predict the number of imaging artifacts (0–3) per source. The best model reaches a weighted F1 score of 97.01%^{+1.12%}_{-1.32%} on held-out data; applying the model to the full DRAGNhunter catalog yields an estimated 99.3% complete sample that is 97.7% artifact-free.
Significance. If the labeled subset is representative and the model generalizes without distribution shift, the cleaned catalog would be a useful resource for DRAGN population studies. The work demonstrates a practical application of supervised classification to mitigate known imaging artifacts in a large survey catalog.
major comments (2)
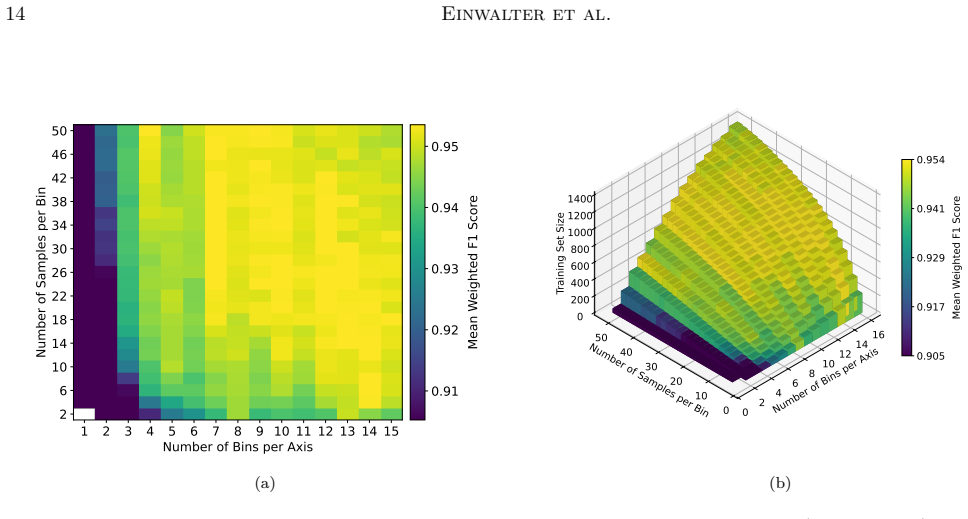
- [Abstract, §3] Abstract and §3 (model training): the reported weighted F1 score and uncertainty bounds are given without any description of the feature set, the cross-validation procedure used to obtain the uncertainty, or the exact method for mitigating class imbalance beyond “judicious training set selection.” These omissions make it impossible to judge whether the 97% figure is robust or over-optimistic.
- [§5] §5 (catalog production): the headline 99.3% completeness and 97.7% artifact-free fractions are obtained by applying the trained classifier to the entire unlabeled DRAGNhunter catalog and then using the model’s predicted artifact fractions. No feature-distribution diagnostics, adversarial validation, or external labeled hold-out drawn from the full catalog are reported, so the translation from test-set F1 to full-catalog purity/completeness rests on an untested representativeness assumption.
minor comments (2)
- [Abstract] The abstract states the F1 score to two decimal places but does not define the weighting scheme or the exact class labels used; this should be stated explicitly in the methods section.
- [Results figures] Figure captions and axis labels in the results section use inconsistent notation for the artifact classes (e.g., “0 artifacts” vs. “class 0”); standardize throughout.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review. We have revised the manuscript to provide the requested methodological details and additional validation diagnostics. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (model training): the reported weighted F1 score and uncertainty bounds are given without any description of the feature set, the cross-validation procedure used to obtain the uncertainty, or the exact method for mitigating class imbalance beyond “judicious training set selection.” These omissions make it impossible to judge whether the 97% figure is robust or over-optimistic.
Authors: We agree that these details were insufficiently described in the original submission. In the revised manuscript we have expanded §3 with a complete list of the 15 input features (component flux ratios, angular separations, peak-to-total flux ratios, and morphological parameters extracted from the VLASS Quick Look images; now summarized in new Table 2). The reported uncertainty bounds were obtained from 10 repetitions of stratified 5-fold cross-validation; the asymmetric errors are the 16th–84th percentiles of the weighted F1 distribution across all folds. Class imbalance was addressed by a combination of (i) judicious training-set selection to ensure each fold contained at least 20 examples of the minority classes and (ii) inverse-frequency class weighting inside the random-forest implementation. We have added an ablation study confirming that both steps improve minority-class recall. These changes are now fully documented in §3 and the associated supplementary material. revision: yes
-
Referee: [§5] §5 (catalog production): the headline 99.3% completeness and 97.7% artifact-free fractions are obtained by applying the trained classifier to the entire unlabeled DRAGNhunter catalog and then using the model’s predicted artifact fractions. No feature-distribution diagnostics, adversarial validation, or external labeled hold-out drawn from the full catalog are reported, so the translation from test-set F1 to full-catalog purity/completeness rests on an untested representativeness assumption.
Authors: We acknowledge that direct external validation on the full catalog is not possible without additional human labeling. In the revision we have added (i) Kolmogorov–Smirnov tests and quantile–quantile plots comparing the distributions of all 15 features between the labeled training set and the full DRAGNhunter catalog (new Figure 8), (ii) an adversarial validation experiment in which a random forest trained to discriminate labeled versus unlabeled sources achieved only 51.8 % accuracy, consistent with no strong distribution shift, and (iii) a sensitivity test in which models trained on random 80 % subsets of the labeled data were applied to the remaining 20 % and yielded stable purity/completeness estimates. We have inserted an explicit discussion of these supporting checks together with the remaining caveat that the quoted 99.3 % / 97.7 % figures assume the labeled subset is representative. These additions appear in the revised §5. revision: partial
Circularity Check
No circularity: standard ML classification with held-out F1 and downstream application to full catalog
full rationale
The reported weighted F1 of 97.01% is measured on a held-out test set against human labels. The 99.3% completeness and 97.7% artifact-free estimates are obtained by applying the trained model to the unlabeled full catalog and counting predicted clean sources; these are downstream counts, not quantities defined in terms of the F1 score or fitted parameters by construction. No equations reduce the headline figures to the training inputs, no self-citations are load-bearing for the central claims, and no uniqueness theorems or ansatzes are invoked. The derivation chain is self-contained against the external human-labeled benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- random forest hyperparameters
axioms (1)
- domain assumption Training labels accurately reflect true artifact counts
Reference graph
Works this paper leans on
-
[1]
Asadi, V., Haghi, H., & Zonoozi, A. H. 2025, Astronomy and Astrophysics, 700, A259, doi: 10.1051/0004-6361/202555620 Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33, doi: 10.1051/0004-6361/201322068 Astropy Collaboration, Price-Whelan, A. M., Sip˝ ocz, B. M., et al. 2018, AJ, 156, 123, doi: 10.3847/1538-3881/aabc4f As...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1051/0004-6361/202555620 2025
-
[2]
1979, The Annals of Statistics, 7,
https://www.jstor.org/stable/2246110 Efron, B. 1979, The Annals of Statistics, 7,
-
[3]
2014, Journal of Machine Learning Research, 15,
https://www.jstor.org/stable/2958830 Fern´ andez-Delgado, M., Cernadas, E., Barro, S., & Amorim, D. 2014, Journal of Machine Learning Research, 15,
-
[4]
M., Torres, S., Rebassa-Mansergas, A., & Ferrer-Burjachs, A
http://jmlr.org/papers/v15/delgado14a.html Garc´ ıa-Zamora, E. M., Torres, S., Rebassa-Mansergas, A., & Ferrer-Burjachs, A. 2025, Astronomy and Astrophysics, 699, A3, doi: 10.1051/0004-6361/202554414 Gordon, Y. A., Boyce, M. M., O’Dea, C. P., et al. 2021, The Astrophysical Journal Supplement Series, 255, 30, doi: 10.3847/1538-4365/ac05c0 Gordon, Y. A., Ru...
-
[5]
2011, Journal of Machine Learning Research, 12,
https://ui.adsabs.harvard.edu/abs/2003ASPC..295.....P Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, Journal of Machine Learning Research, 12,
work page 2011
-
[6]
http://jmlr.org/papers/v12/pedregosa11a.html Probst, P., Wright, M. N., & Boulesteix, A. 2019, WIREs: Data Mining & Knowledge Discovery, 9, N.PAG, doi: 10.1002/widm.1301 Ramdhanie, S., Gordon, Y. A., Andernach, H., Hooper, E. J., & Sampson, B. 2023, Research Notes of the American Astronomical Society, 7, 243, doi: 10.3847/2515-5172/ad0cc6 Solorio-Ram´ ıre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.