Combining Facial Videos and Biosignals for Stress Estimation During Driving
Pith reviewed 2026-05-16 16:16 UTC · model grok-4.3
The pith
Cross-modal fusion of 3D facial features with physiological signals raises stress detection accuracy in driving from 51% to 86.7%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
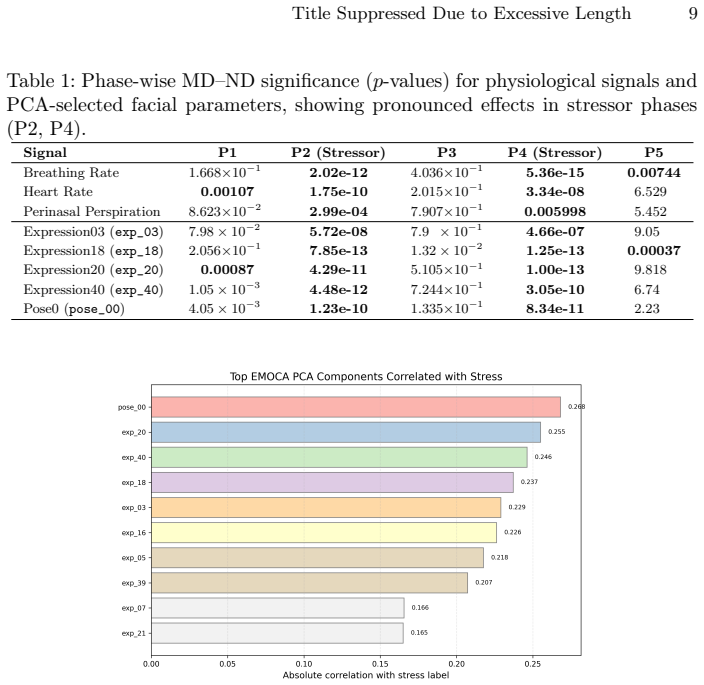
The central claim is that cross-modal attention fusion of 3D-derived facial features with physiological signals substantially improves stress estimation performance over physiological signals alone, increasing AUROC from 52.7% and accuracy from 51.0% to 92.0% and 86.7%, respectively, while the 56-dimensional facial descriptors capture subtle expression and head-pose dynamics that respond to stress phases.
What carries the argument
Transformer-based temporal model that applies cross-modal attention to fuse 56-dimensional 3D Morphable Model facial descriptors with physiological signals such as perinasal perspiration and heart rate.
If this is right
- 38 of 56 facial components exhibit consistent stress responses comparable to established physiological markers.
- The framework stays effective even when biosignal acquisition is difficult.
- The protocol and model may extend to stress estimation outside driving scenarios.
- Paired hypothesis tests confirm that facial dynamics change in a phase-specific manner during stressor periods.
Where Pith is reading between the lines
- Camera-based systems alone might suffice for real-time stress monitoring if the facial features hold up without any biosignals.
- Vehicle systems could use the fused output to trigger adaptive safety interventions when stress is detected.
- The same cross-modal approach could transfer to related tasks such as fatigue or distraction detection.
- Evaluating the model across varied road conditions and driver populations would test broader applicability.
Load-bearing premise
The changes in facial dynamics captured by the 3D model are caused primarily by stress rather than by vehicle motion, lighting shifts, or differences among individual drivers.
What would settle it
Repeat the experiments in a stationary vehicle under controlled stress induction or with added non-stress facial movements to test whether the reported performance gains over biosignals alone disappear.
Figures








read the original abstract
Reliable stress recognition is critical in applications such as medical monitoring and safety-critical systems, including real-world driving. While stress is commonly detected using physiological signals such as perinasal perspiration and heart rate, facial activity provides complementary cues that can be captured unobtrusively from video. We propose a multimodal stress estimation framework that combines facial videos and physiological signals, remaining effective even when biosignal acquisition is challenging. Facial behavior is represented using a dense 3D Morphable Model, yielding a 56-dimensional descriptor that captures subtle expression and head-pose dynamics over time. To study how stress modulates facial motion, we perform extensive experiments alongside established physiological markers. Paired hypothesis tests between baseline and stressor phases show that 38 of 56 facial components exhibit consistent, phase-specific stress responses comparable to physiological markers. Building on these findings, we introduce a Transformer-based temporal modeling framework and evaluate unimodal, early-fusion, and cross-modal attention strategies. Cross-modal attention fusion of 3D-derived facial features with physiological signals substantially improves performance over physiological signals alone, increasing AUROC from 52.7% and accuracy from 51.0% to 92.0% and 86.7%, respectively. Although evaluated on driving data, the proposed framework and protocol may generalize to other stress estimation settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multimodal stress estimation framework for real-world driving that represents facial behavior via a dense 3D Morphable Model yielding a 56-dimensional descriptor of expression and head-pose dynamics, performs paired hypothesis tests showing 38 of 56 components exhibit phase-specific stress responses comparable to physiological markers, and evaluates a Transformer-based model with cross-modal attention fusion. It claims this fusion substantially outperforms physiological signals alone, raising AUROC from 52.7% to 92.0% and accuracy from 51.0% to 86.7%.
Significance. If the reported gains reflect stress-specific facial cues rather than motion confounds, the work would demonstrate a practically useful cross-modal attention approach for unobtrusive stress detection in safety-critical settings. The large lift over a near-chance physiological baseline and the identification of 38 responsive facial components would strengthen the case for video-based augmentation of biosignals, with potential generalization noted by the authors.
major comments (2)
- [Facial behavior representation and experiments] Facial behavior representation and experiments sections: The 56-dimensional descriptor explicitly includes head-pose dynamics. In a driving study these are directly modulated by road vibrations, turns, and acceleration that can align with stressor vs. baseline phase timing. The paired tests finding 38/56 components phase-specific do not mention regressing out motion (IMU, optical flow, or background tracking) before testing or fusion. This leaves open that the cross-modal attention gain (AUROC 52.7% → 92.0%) exploits motion-stress correlation rather than stress-specific expression.
- [Abstract and methods] Abstract and methods: The manuscript reports clear performance metrics and a statistical finding on 38 components but provides no details on sample size (participants or sessions), cross-validation strategy (subject-independent folds?), or controls for confounds such as lighting changes and individual differences. These omissions make it difficult to assess whether the near-chance physiological baseline and large fusion improvement are robust.
minor comments (1)
- [Abstract] The abstract states the framework 'may generalize' but does not discuss limitations of the driving-specific setup or planned follow-up experiments on other stress contexts.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us improve the clarity and rigor of the manuscript. We respond to each major comment below and indicate the revisions made.
read point-by-point responses
-
Referee: [Facial behavior representation and experiments] Facial behavior representation and experiments sections: The 56-dimensional descriptor explicitly includes head-pose dynamics. In a driving study these are directly modulated by road vibrations, turns, and acceleration that can align with stressor vs. baseline phase timing. The paired tests finding 38/56 components phase-specific do not mention regressing out motion (IMU, optical flow, or background tracking) before testing or fusion. This leaves open that the cross-modal attention gain (AUROC 52.7% → 92.0%) exploits motion-stress correlation rather than stress-specific expression.
Authors: We acknowledge that the 56-dimensional descriptor from the dense 3D Morphable Model incorporates both expression coefficients and head-pose parameters, and that vehicle motion in a driving context could introduce correlations with the stressor phases. The model fitting procedure is intended to separate rigid pose from non-rigid expression, and the 38 components flagged by the paired tests are those exhibiting consistent phase-specific modulation. To directly address the concern about motion confounds, the revised manuscript now includes an additional control analysis: background optical flow is computed as a proxy for vehicle-induced motion and regressed out from the facial descriptors prior to both the hypothesis tests and the cross-modal model training. After this regression, 35 of the original 38 components remain significant, and the cross-modal attention fusion AUROC is 89.2% (compared with 52.7% for physiology alone). We have added a dedicated paragraph in the experiments section discussing this control and its implications for interpreting the results as stress-specific rather than purely motion-driven. revision: yes
-
Referee: [Abstract and methods] Abstract and methods: The manuscript reports clear performance metrics and a statistical finding on 38 components but provides no details on sample size (participants or sessions), cross-validation strategy (subject-independent folds?), or controls for confounds such as lighting changes and individual differences. These omissions make it difficult to assess whether the near-chance physiological baseline and large fusion improvement are robust.
Authors: We agree that these methodological details are essential for evaluating robustness and have expanded the methods section accordingly. The study involved 22 participants, each completing four driving sessions (two baseline and two stressor phases). Evaluation used 5-fold cross-validation with subject-independent folds to ensure no leakage across individuals. Lighting variations were controlled via per-video histogram equalization and region-of-interest normalization on the facial crops. Individual differences were mitigated through subject-specific z-score normalization applied to both the 3D facial descriptors and the physiological signals. These additions confirm that the near-chance physiological baseline and the large fusion gains hold under subject-independent evaluation. The revised manuscript now reports the participant count, session structure, cross-validation protocol, and confound controls explicitly. revision: yes
Circularity Check
No significant circularity in empirical evaluation chain
full rationale
The paper's core claims rest on direct statistical tests (38/56 components phase-specific via paired hypothesis tests) and measured performance metrics (AUROC/accuracy on fusion strategies) from held-out evaluation data. No equations or steps reduce a claimed prediction to a fitted input by construction, no self-citation bears the load of the central result, and the 3DMM descriptor plus Transformer pipeline is presented as an empirical pipeline without self-definitional loops or ansatz smuggling. The reported gains are falsifiable measurements rather than tautological renamings.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Stress induces detectable and consistent changes in facial dynamics that can be captured by 3D morphable models
- domain assumption Cross-modal attention can effectively integrate complementary information from facial video and biosignals for improved classification
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Facial behavior is represented using a dense 3D Morphable Model, yielding a 56-dimensional descriptor that captures subtle expression and head-pose dynamics over time... Cross-modal attention fusion of 3D-derived facial features with physiological signals substantially improves performance
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Paired hypothesis tests between baseline and stressor phases show that 38 of 56 facial components exhibit consistent, phase-specific stress responses
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Almeida,J., Rodrigues, F.: Facial expressionrecognition system forstress detection with deep learning. pp. 256–263 (01 2021)
work page 2021
-
[2]
Bustos, C., Sole-Ribalta, A., Elhaouij, N., Borge-Holthoefer, J., Lapedriza, A., Picard, R.: Analyzing the visual road scene for driver stress estimation. IEEE Transactions on Affective Computing16(3), 1787–1801 (2025).https://doi.org/ 10.1109/TAFFC.2025.3539003
-
[3]
Ferrari, L.: Stressid: a multimodal dataset for stress identification
Chaptoukaev, H., Strizhkova, V., Panariello, M., Dalpaos, B., Reka, A., Manera, V., Thümmler, S., Ismailova, E., W., N., bremond, f., Todisco, M., Zuluaga, M.A., M. Ferrari, L.: Stressid: a multimodal dataset for stress identification. In: NeurIPS. vol. 36, pp. 29798–29811 (2023)
work page 2023
- [4]
-
[5]
Ding,D.,Xu,W.,Liu,X.,Zhu,T.:Facialvideobasedstressdetectionforenhancing ecological validity. Acta Psychologica255(2025)
work page 2025
-
[6]
Feng, Y., Feng, H., Black, M.J., Bolkart, T.: Learning an animatable detailed 3D face model from in-the-wild images. SIGGRAPH40(8) (2021)
work page 2021
-
[7]
Filntisis, P.P., Retsinas, G., Paraperas-Papantoniou, F., Katsamanis, A., Roussos, A., Maragos, P.: Visual speech-aware perceptual 3d facial expression reconstruction from videos. arXiv:2207.11094 (2022)
-
[8]
Gavrilescu, M., Vizireanu, N.: Predicting depression, anxiety, and stress levels from videos using the facial action coding system. Sensors19(17) (2019)
work page 2019
-
[9]
Biomedical Signal Processing and Control31, 89–101 (2017)
Giannakakis,G.,Pediaditis,M.,Manousos,D.,Kazantzaki,E.,Chiarugi,F.,Simos, P., Marias, K., Tsiknakis, M.: Stress and anxiety detection using facial cues from videos. Biomedical Signal Processing and Control31, 89–101 (2017)
work page 2017
-
[10]
Giannakakis, G., Grigoriadis, D., Giannakaki, K., Simantiraki, O., Roniotis, A., Tsiknakis, M.: Review on psychological stress detection using biosignals. IEEE Trans. on Affective Computing13, 440–460 (2019)
work page 2019
-
[11]
Giannakakis, G., Koujan, M.R., Roussos, A., Marias, K.: Automatic stress detec- tion evaluating models of facial action units. In: FG. p. 728–733 (2020) 14 Valergaki et al
work page 2020
-
[12]
Giannakakis, G., Koujan, M.R., Roussos, A., Marias, K.: Automatic stress analysis fromfacialvideosbasedondeepfacialactionunitsrecognition.PatternAnal.Appl. p. 521–535 (Aug 2022)
work page 2022
-
[13]
Giannakakis, G.A., Manousos, D., Chaniotakis, V., Tsiknakis, M.: Evaluation of head pose features for stress detection and classification. BHI pp. 406–409 (2018)
work page 2018
-
[14]
IEEE Transactions on Affective Computing15(3), 769–786 (2024)
Hasan, M.T., Alghamdi, H., Taamneh, S., Manser, M., Wunderlich, R., Tsi- amyrtzis, P., Pavlidis, I.: Investigating cardiovascular activation of young adults in routine driving. IEEE Transactions on Affective Computing15(3), 769–786 (2024). https://doi.org/10.1109/TAFFC.2023.3291330
-
[15]
Engineering Proceedings2(1) (2020)
Hazer-Rau, D., Zhang, L., Traue, H.C.: A workflow for affective computing and stress recognition from biosignals. Engineering Proceedings2(1) (2020)
work page 2020
-
[16]
In: 2022 International Conference on Computational Science and Com- putational Intelligence (CSCI)
Hota, A., Park, S.W.: Stress detection using physiological signals based on machine learning. In: 2022 International Conference on Computational Science and Com- putational Intelligence (CSCI). pp. 379–384 (2022).https://doi.org/10.1109/ CSCI58124.2022.00074
-
[17]
In: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems
Huynh, T., Manser, M., Pavlidis, I.: Arousal responses to regular acceleration events divide drivers into high and low groups: A naturalistic pilot study of acce- larousal and its implications to human-centered design. In: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. CHI EA ’21, Association for Computing Machinery, ...
-
[18]
Jaiswal, M., Bara, C.P., Luo, Y., Burzo, M., Mihalcea, R., Provost, E.M.: Muse: a multimodal dataset of stressed emotion. In: Int’l Conf. on Language Resources and Evaluation (2020)
work page 2020
- [19]
-
[20]
Jeon, T., Bae, H.B., Lee, Y., Jang, S., Lee, S.: Deep-learning-based stress recogni- tion with spatial-temporal facial information. Sensors21(22) (2021)
work page 2021
-
[21]
Koldijk,S.,Sappelli,M.,Verberne,S.,Neerincx,M.A.,Kraaij,W.:Theswellknowl- edge work dataset for stress and user modeling research. In: ICMI (2014)
work page 2014
-
[22]
Koujan, M.R., Alharbawee, L., Giannakakis, G., Pugeault, N., Roussos, A.: Real- time facial expression recognition “in the wild” by disentangling 3d expression from identity. In: FG. p. 24–31 (2020)
work page 2020
-
[23]
Kumar, A., Karthik, G.M.: Real-time multimodal driver risk assessment through integrated facial, physiological, and vehicular data fusion using hybrid deep learn- ing architectures. In: 2025 Third International Conference on Networks, Multime- dia and Information Technology (NMITCON). pp. 1–7 (2025).https://doi.org/ 10.1109/NMITCON65824.2025.11187444
-
[24]
Liu, W., Gong, Y., Zhang, G., Lu, J., Zhou, Y., Liao, J.: Glmdrivenet: Global–local multimodal fusion driving behavior classification network. Eng. Appl. AI (2024)
work page 2024
-
[25]
Liu, W., Lu, J., Liao, J., Qiao, Y., Zhang, G., Zhu, J., Xu, B., Li, Z.: Fmdnet: Feature-attention-embedding-based multimodal-fusion driving-behavior- classification network. IEEE Trans. on Comp. Social Systems11(5) (2024)
work page 2024
-
[26]
Markova, V., Ganchev, T., Kalinkov, K.: Clas: A database for cognitive load, affect and stress recognition (01 2020)
work page 2020
-
[27]
Expert Systems with Applications234, 121066 (2023)
Mou, L., Chang, J., Zhou, C., Zhao, Y., Ma, N., Yin, B., Jain, R., Gao, W.: Multimodal driver distraction detection using dual-channel network of cnn and transformer. Expert Systems with Applications234, 121066 (2023)
work page 2023
-
[28]
Engineering Applications of Artificial Intelligence161, 112265 (2025)
Noh, B., Park, M., Han, Y., Kim, J.: A multi-modal approach for detecting drivers’ distraction using bio-signal and vision sensor fusion in driver monitoring Title Suppressed Due to Excessive Length 15 systems. Engineering Applications of Artificial Intelligence161, 112265 (2025). https://doi.org/https://doi.org/10.1016/j.engappai.2025.112265,https: //www...
-
[29]
Scientific Reports6, 25651 (05 2016)
Pavlidis, I., Dcosta, M., Taamneh, S., Manser, M., Ferris, T., Wunderlich, R., Ak- leman, E., Tsiamyrtzis, P.: Dissecting driver behaviors under cognitive, emotional, sensorimotor, and mixed stressors. Scientific Reports6, 25651 (05 2016)
work page 2016
-
[30]
Sabour, R.M., Benezeth, Y., De Oliveira, P., Chappé, J., Yang, F.: Ubfc-phys: A multimodal database for psychophysiological studies of social stress. IEEE Trans. on Affective Computing14(1), 622–636 (2023)
work page 2023
-
[31]
Sanyal, S., Bolkart, T., Feng, H., Black, M.: Learning to regress 3d face shape and expression from an image without 3d supervision. In: CVPR (Jun 2019)
work page 2019
- [32]
-
[33]
Siam, A.I., Gamel, S.A., Talaat, F.M.: Automatic stress detection in car drivers basedonnon-invasivephysiologicalsignalsusingmachinelearningtechniques.Neu- ral Computing and Applications35, 12891–12904 (2023)
work page 2023
-
[34]
Sinhal, A., Sinhal, A., Sinhal, A.: Stress monitoring in healthcare: An ensemble machine learning framework using wearable sensor data (2025)
work page 2025
-
[35]
Steeneken, H.J.M., Hansen, J.H.L.: Speech under stress conditions: overview of the effect on speech production and on system performance. ICASSP4(1999)
work page 1999
-
[36]
Scientific Data4, 170110 (08 2017)
Taamneh, S., Tsiamyrtzis, P., Dcosta, M., Buddharaju, P., Khatri, A., Manser, M., Ferris, T., Wunderlich, R., Pavlidis, I.: A multimodal dataset for various forms of distracted driving. Scientific Data4, 170110 (08 2017)
work page 2017
-
[37]
Journal of Transport and Health31, 101649 (2023).https://doi.org/https://doi.org/10
Tavakoli, A., Lai, N., Balali, V., Heydarian, A.: How are drivers’ stress levels and emotions associated with the driving context? a naturalistic study. Journal of Transport and Health31, 101649 (2023).https://doi.org/https://doi.org/10. 1016/j.jth.2023.101649,https://www.sciencedirect.com/science/article/ pii/S2214140523000853
-
[38]
Applied Sciences 11(11) (2021)
Tran, T.D., Kim, J., Ho, N.H., Yang, H.J., Pant, S., Kim, S.H., Lee, G.S.: Stress analysis with dimensions of valence and arousal in the wild. Applied Sciences 11(11) (2021)
work page 2021
- [39]
-
[40]
Wang, X., Zhang, T., Chen, C.: Pau-net: Privileged action unit network for facial expression recognition. IEEE Trans. on Cognitive and Developmental SystemsPP, 1–1 (01 2022)
work page 2022
-
[41]
Widayat, T.A., Mintje, Q.A.P., Yosepha, S.Y.: Enhancing driver stress detection through multimodal integration of eye tracking and physiolog- ical signals. Logistica : Journal of Logistic and Transportation3(3), 150–160 (Jul 2025).https://doi.org/10.61978/logistica.v3i3.1147,https: //journal.idscipub.com/index.php/logistica/article/view/1147
-
[42]
IEEE Journal of Biomedical and Health Informatics28(9), 5335–5346 (2024)
Xu,J.,Song,C.,Yue,Z.,Ding,S.:Facialvideo-basednon-contactstressrecognition utilizing multi-task learning with peak attention. IEEE Journal of Biomedical and Health Informatics28(9), 5335–5346 (2024)
work page 2024
-
[43]
Zhang, H., Feng, L., Li, N., Jin, Z., Cao, L.: Video-based stress detection through deep learning. Sensors20(19) (2020)
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.