Non-parametric finite-sample credible intervals with one-dimensional priors: a middle ground between Bayesian and frequentist intervals
Pith reviewed 2026-05-16 11:13 UTC · model grok-4.3
The pith
Statistical intervals can be constructed so a p% belief attaches after seeing the interval itself using only a one-dimensional prior on the target parameter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is a method for constructing non-parametric finite-sample credible intervals to which a p% belief can be assigned after observing the interval but not necessarily after inspecting the full dataset. Even in fully non-parametric problems this requires only a one-dimensional prior over the parameter of interest rather than a high-dimensional prior over the full distribution, while retaining many practical and philosophical advantages of Bayesian methods.
What carries the argument
The construction of non-parametric finite-sample credible intervals that use only a one-dimensional prior over the parameter of interest to achieve the post-interval belief property.
If this is right
- In fully non-parametric problems only a prior over the parameter of interest is needed.
- A p% belief attaches after seeing the interval without full data inspection.
- Many practical and philosophical advantages of Bayesian methods are retained.
- The intervals may provide significant advances in statistical methodology across fields.
Where Pith is reading between the lines
- This construction could reduce the barrier to Bayesian-style inference in high-dimensional nonparametric data.
- Direct comparisons of these intervals to standard Bayesian and frequentist ones in applied datasets would test their practical utility.
- The post-interval belief assignment might extend to other summary statistics beyond intervals.
- The approach suggests a way to blend partial data inspection with calibrated belief statements.
Load-bearing premise
Such intervals can be constructed in fully non-parametric problems while maintaining the claimed belief property after observing only the interval using solely a one-dimensional prior.
What would settle it
A concrete nonparametric example where the belief level assigned after constructing and observing the interval is contradicted once the full dataset is examined or by direct comparison to the true parameter value.
Figures
read the original abstract
We present a method of constructing statistical intervals that obtain a natural middle ground between Bayesian and frequentist statistical intervals, previously unexplored in literature: To a p% Bayesian credible interval we should assign a p% belief after observing both the dataset and the interval, to p% frequentist intervals we can generally only assign a p% belief before observing either the data or the interval, while to the intervals proposed here we can assign a p% belief after observing the interval, but not necessarily after inspecting the full dataset ourselves. Even in fully non-parametric problems this only requires a prior over the parameter(s) of interest, not a high-dimensional prior over the full distribution, while maintaining many of the practical and philosophical advantages of Bayesian methods. We belief these methods may therefore provide significant advances in statistical methodology to a number of fields. This work is meant as a proof of principle: We concretely implement such intervals for two different problems and study the properties of resulting intervals. We discuss promising directions where the proposed type of interval may provide significant advantages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a new class of statistical intervals that aim to occupy a middle ground between Bayesian credible intervals and frequentist confidence intervals. After observing only the interval (but not necessarily the full dataset), a p% belief can be assigned to the parameter lying inside it. This property is claimed to hold in fully non-parametric problems using solely a one-dimensional prior on the scalar parameter of interest, without requiring a high-dimensional prior over the full distribution. The authors present concrete implementations for two problems, study the resulting intervals' properties, and discuss potential advantages and future directions.
Significance. If the post-interval belief property can be rigorously established and verified, the approach could provide a practical bridge between Bayesian and frequentist paradigms, allowing belief statements after seeing the interval while avoiding the need for full nonparametric priors. This would be particularly valuable in settings where high-dimensional modeling is infeasible, offering both philosophical and computational advantages over standard methods.
major comments (2)
- [Abstract and implementation sections] The central claim—that finite-sample intervals satisfying P(θ ∈ I | I) = p can be constructed in fully non-parametric problems using only a one-dimensional prior—requires an explicit construction and verification. The abstract asserts implementations for two problems, but the manuscript must demonstrate (via derivation or simulation) that conditioning solely on I yields exactly the claimed conditional probability, given that I is typically a function of the full empirical measure or other infinite-dimensional features of the data.
- [Sections describing the two concrete implementations] The paper must clarify how the interval construction avoids implicit dependence on the remainder of the distribution when conditioning only on I. Without this, the claimed belief property after observing the interval alone risks being undefined or requiring additional modeling assumptions not stated in the one-dimensional prior.
minor comments (2)
- [Abstract] Correct the typo 'We belief' to 'We believe' in the abstract.
- [Introduction and methods] Provide more precise notation for the post-interval belief assignment and the conditioning event to avoid ambiguity between P(θ ∈ I | I) and related quantities.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive suggestions. We agree that the manuscript requires stronger explicit demonstrations of the central conditional-probability claim and will revise the abstract, implementation sections, and related derivations to address this. The revisions will include detailed constructions for both examples together with verification (analytic where possible, simulation-based otherwise) that the stated belief property holds when conditioning solely on the observed interval I.
read point-by-point responses
-
Referee: [Abstract and implementation sections] The central claim—that finite-sample intervals satisfying P(θ ∈ I | I) = p can be constructed in fully non-parametric problems using only a one-dimensional prior—requires an explicit construction and verification. The abstract asserts implementations for two problems, but the manuscript must demonstrate (via derivation or simulation) that conditioning solely on I yields exactly the claimed conditional probability, given that I is typically a function of the full empirical measure or other infinite-dimensional features of the data.
Authors: We accept the need for explicit verification. In the revised manuscript we will supply, for the first implementation, a direct derivation showing that the interval boundaries are chosen so that the one-dimensional prior on θ induces P(θ ∈ I | I) = p exactly, with the non-parametric components of the data distribution integrated out by construction. For the second implementation we will add a simulation study that conditions only on the realized interval I (discarding the remainder of the sample) and reports the empirical coverage of the conditional probability. These additions will be placed in the implementation sections and cross-referenced from the abstract. revision: yes
-
Referee: [Sections describing the two concrete implementations] The paper must clarify how the interval construction avoids implicit dependence on the remainder of the distribution when conditioning only on I. Without this, the claimed belief property after observing the interval alone risks being undefined or requiring additional modeling assumptions not stated in the one-dimensional prior.
Authors: We will insert a new subsection that spells out the construction rule: the interval I is defined via a mapping that depends on the data only through a one-dimensional functional whose distribution, conditional on θ, is fully determined by the scalar prior. Because the prior is placed solely on θ, the conditional distribution of θ given I is obtained by Bayes’ rule applied to the marginal likelihood of I; all other aspects of the unknown distribution are marginalized implicitly and do not enter the final expression. This structure ensures that no additional modeling assumptions beyond the stated one-dimensional prior are required. The subsection will contain the explicit functional forms used in each of the two examples. revision: yes
Circularity Check
No circularity: derivation chain not exhibited in text
full rationale
The abstract asserts existence of intervals achieving p% belief after observing only the interval in fully non-parametric settings using a one-dimensional prior, and states that concrete implementations for two problems were performed. However, the provided text contains no equations, no explicit construction, no fitted parameters, and no self-citations. Absent any derivation chain or load-bearing steps that can be quoted and shown to reduce to inputs by construction, no circularity is identifiable. The central claim remains an assertion whose verification would require the missing construction details.
Axiom & Free-Parameter Ledger
free parameters (1)
- one-dimensional prior
axioms (1)
- ad hoc to paper Existence of finite-sample intervals satisfying the post-interval belief property in non-parametric settings
invented entities (1)
-
post-interval belief assignment
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Any interval S_p can be computed that satisfies p ≤ ∫_{S_p} dθ l(θ) b(θ) / ∫ dθ l(θ) b(θ) for some likelihood function l(θ).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
l(μ) defined piecewise with g±(x) ≡ exp(−2(m±δ−x)²/N) from Hoeffding bounds
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. V. Lindley, The future of statistics: A bayesian 21st century, Advances in Applied Probability7, 106 (1975)
work page 1975
-
[2]
Efron, Why isn’t everyone a bayesian?, The American Statistician40, 1 (1986)
B. Efron, Why isn’t everyone a bayesian?, The American Statistician40, 1 (1986)
work page 1986
-
[3]
S. Ghosal and A. van der Vaart,Fundamentals of Non- parametric Bayesian Inference, Cambridge Series in Sta- tistical and Probabilistic Mathematics (Cambridge Uni- versity Press, 2017)
work page 2017
-
[4]
I. Hacking and J.-W. Romeijn,Logic of Statistical Infer- ence, Cambridge Philosophy Classics (Cambridge Uni- versity Press, 2016)
work page 2016
-
[5]
S. McGrayne,The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, & Emerged Triumphant from Two Centuries of C, Matematicas (E-libro) (Yale University Press, 2011)
work page 2011
-
[6]
Methods that combine the favorable properties of both are generally accurate onlyasymptotically(e.g. reference priors) [3], but we generally have no way of bounding their accuracy when we only have access to a finite num- ber of samples
-
[7]
I.e., the algorithm takespas argument and returns an interval or set of intervals
-
[8]
Barring peculiar constructions, e.g., ignoring outliers
-
[9]
Wasserman,All of Nonparametric Statistics, Springer Texts in Statistics (Springer New York, 2006)
L. Wasserman,All of Nonparametric Statistics, Springer Texts in Statistics (Springer New York, 2006)
work page 2006
-
[10]
M. Sunn˚ aker, A. G. Busetto, E. Numminen, J. Corander, M. Foll, and C. Dessimoz, Approximate bayesian compu- tation, PLOS Computational Biology9, 1 (2013)
work page 2013
-
[11]
C. J. Clopper and E. S. Pearson, The use of confidence or fiducial limits illustrated in the case of the binomial, Biometrika26, 404 (1934). 7
work page 1934
-
[12]
By the Bernstein-von Mises theorem this should not come as a surprise, since, like the interval here, frequentist con- fidence intervals typically only usestoo
-
[13]
We will not focus on asymptotic frequentist methods, as regarding the given criteria these perform very sim- ilarly to asymptotic Bayesian methods (largely due to Bernstein-von Mises), with the exception of the flexibil- ity criterion
-
[14]
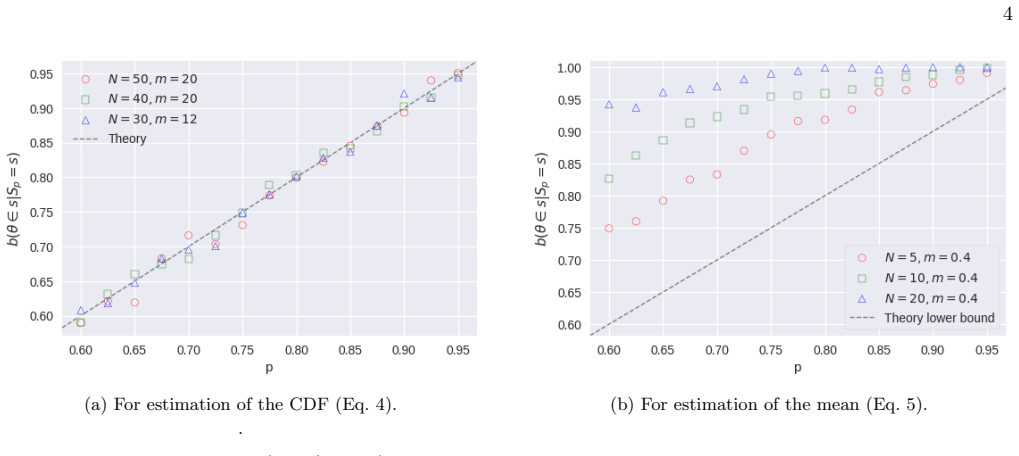
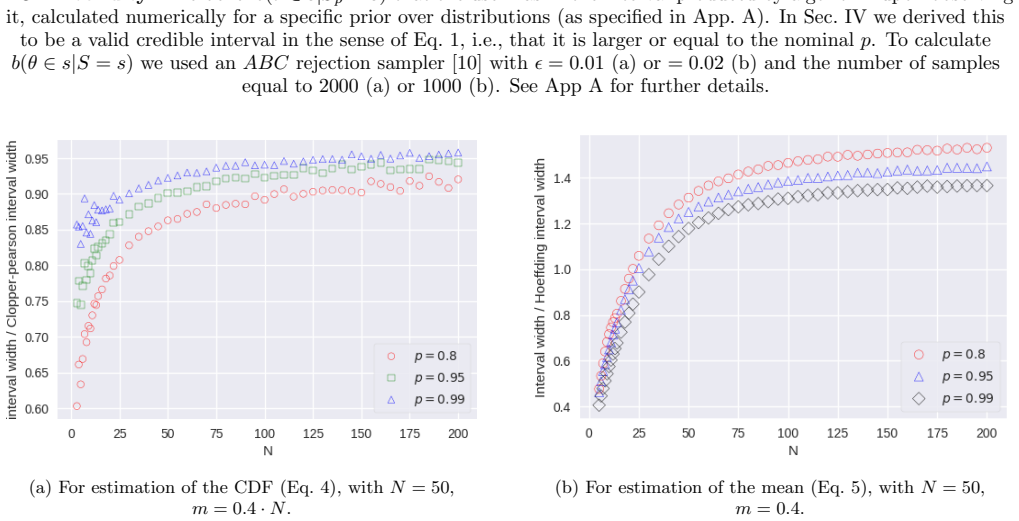
Appendix A: Numerical verification In Fig
For example, if you are using samples from different com- passes to estimate where North is, one can justify a lack of prior knowledge as corresponding to a circularly sym- metric, i.e., uniform, prior. Appendix A: Numerical verification In Fig. 1 we verify that the resulting algorithms satisfy Eq. 1 by plotting the relation between the left and right han...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.