Modeling Sampling Workflows for Code Repositories
Pith reviewed 2026-05-16 11:10 UTC · model grok-4.3
The pith
A domain-specific language models sampling strategies for code repositories using composable operators to support explicit reasoning on result generalizability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
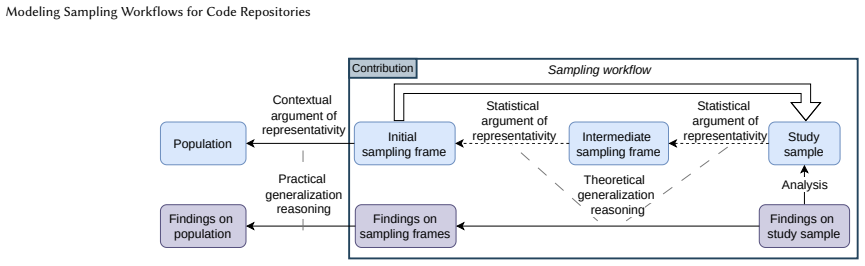
The authors define a DSL whose core is a set of composable sampling operators that together describe full workflows, implement the DSL as a Python-based fluent API, and validate it by showing that it can reconstruct the sampling strategies reported across recent MSR papers while exposing statistical indicators of representativeness.
What carries the argument
Composable sampling operators in a domain-specific language, which build explicit workflows and link them to statistical indicators for assessing sample representativeness.
If this is right
- Sampling decisions become explicit and reusable across different studies.
- Statistical indicators of representativeness can be derived directly from the modeled workflow.
- Generalizability implications of any given sampling choice become traceable through the operator sequence.
- Existing strategies from the literature can be uniformly described and compared.
Where Pith is reading between the lines
- Adoption could push empirical papers toward more standardized and machine-readable descriptions of their sampling methods.
- The same operator-based modeling might apply to sampled datasets in neighboring fields that draw from public repositories.
- Tool support could eventually automate checks that flag when a chosen workflow fails basic representativeness thresholds.
Load-bearing premise
That the sampling strategies appearing in MSR papers can be faithfully expressed using a finite set of composable operators without losing critical details that affect generalizability claims.
What would settle it
A published sampling strategy from an MSR paper that cannot be constructed using any combination of the DSL's operators.
Figures





read the original abstract
Empirical software engineering research often depends on datasets of code repository artifacts, where sampling strategies are employed to enable large-scale analyses. The design and evaluation of these strategies are critical, as they directly influence the generalizability of research findings. However, sampling remains an underestimated aspect in software engineering research: we identify two main challenges related to (1) the design and representativeness of sampling approaches, and (2) the ability to reason about the implications of sampling decisions on generalizability. To address these challenges, we propose a Domain-Specific Language (DSL) to explicitly describe complex sampling strategies through composable sampling operators. This formalism supports both the specification and the reasoning about the generalizability of results based on the applied sampling strategies. We implement the DSL as a Python-based fluent API, and demonstrate how it facilitates representativeness reasoning using statistical indicators extracted from sampling workflows. We validate our approach through a case study of MSR papers involving code repository sampling. Our results show that the DSL can model the sampling strategies reported in recent literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a domain-specific language (DSL) for explicitly modeling sampling strategies in code repository datasets via composable operators, implemented as a Python fluent API. It claims this formalism enables specification of complex workflows and reasoning about generalizability through extracted statistical indicators, validated by a case study showing that the DSL can express sampling strategies reported in recent MSR literature.
Significance. If the DSL operators preserve the critical details of sampling decisions (e.g., stratification criteria and inclusion probabilities) that affect bias and coverage, the approach could improve rigor in empirical software engineering by making sampling explicit and enabling quantitative assessment of generalizability implications. The case study provides direct syntactic evidence of expressiveness on external examples, which is a strength.
major comments (2)
- [case study] Case study section: the demonstration that literature strategies can be modeled is syntactic only; no side-by-side comparison of statistical indicators (e.g., population coverage, bias estimates, or stratification fidelity) is provided between the original workflows and their DSL representations on the same data. This is load-bearing for the claim that the DSL supports reasoning about generalizability.
- [§3] §3 (DSL definition): the composable operators are presented as sufficient to capture 'critical details' of sampling, but the manuscript provides no formal argument or empirical check that compositions preserve conditional inclusion probabilities or repository-specific filters that determine generalizability.
minor comments (2)
- [abstract] The abstract states that the DSL 'facilitates representativeness reasoning using statistical indicators' but the extraction and computation of these indicators is not detailed with an example or algorithm.
- [§3] Notation for operator composition in the fluent API could be clarified with a small grammar or BNF in §3 to avoid ambiguity in how parameters are passed.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [case study] Case study section: the demonstration that literature strategies can be modeled is syntactic only; no side-by-side comparison of statistical indicators (e.g., population coverage, bias estimates, or stratification fidelity) is provided between the original workflows and their DSL representations on the same data. This is load-bearing for the claim that the DSL supports reasoning about generalizability.
Authors: We agree with this observation. The current case study validates expressiveness through syntactic equivalence but does not include quantitative comparisons of statistical indicators. To address this, we will revise the case study section to perform a side-by-side analysis on a common dataset. This will involve computing and comparing indicators such as population coverage, bias estimates, and stratification fidelity for the original sampling workflows and their DSL representations. We believe this will provide stronger evidence for the generalizability reasoning claim. revision: yes
-
Referee: [§3] §3 (DSL definition): the composable operators are presented as sufficient to capture 'critical details' of sampling, but the manuscript provides no formal argument or empirical check that compositions preserve conditional inclusion probabilities or repository-specific filters that determine generalizability.
Authors: The operators are defined to explicitly include the necessary details for sampling, such as stratification criteria and inclusion rules, allowing the extraction of statistical indicators from the workflow specification. However, we acknowledge the absence of a formal argument or empirical verification of probability preservation under composition. In the revised version, we will add a subsection to §3 that provides a formal argument for preservation of conditional inclusion probabilities and includes an empirical check on a synthetic repository dataset to validate the compositions. revision: yes
Circularity Check
DSL definition and literature case study are self-contained with no circular reductions
full rationale
The paper introduces a DSL for sampling workflows as an independent formalism, implements it as a Python fluent API, and validates coverage via direct application to external MSR literature examples. No equations, fitted parameters, or predictions are defined in terms of the paper's own outputs or prior author results; the modeling claim rests on syntactic expressiveness demonstrated on independent sources rather than any self-referential derivation or self-citation chain. This matches the default expectation of a non-circular modeling paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sampling strategies used in code repository studies can be expressed as compositions of a small set of primitive operators without loss of essential information
invented entities (1)
-
Composable sampling operators
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a Domain-Specific Language (DSL) to explicitly describe complex sampling strategies through composable sampling operators... We validate our approach through a case study of MSR papers involving code repository sampling.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2022. The Galaxy platform for accessible, reproducible and collaborative biomed- ical analyses: 2022 update. Nucleic acids research 50, W1 (2022), W345–W351
work page 2022
-
[2]
Khairul Alam, Banani Roy, Chanchal K Roy, and Kartik Mittal. 2025. An empirical investigation on the challenges in scientific workflow systems development. Empirical Software Engineering 30, 5 (2025), 151
work page 2025
-
[3]
Sebastian Baltes and Paul Ralph. 2022. Sampling in software engineering research: a critical review and guidelines. 27, 4 (2022), 94. doi:10.1007/s10664-021-10072-8
-
[4]
Berthold, Nicolas Cebron, Fabian Dill, Thomas R
Michael R. Berthold, Nicolas Cebron, Fabian Dill, Thomas R. Gabriel, Tobias Köt- ter, Thorsten Meinl, Peter Ohl, Christoph Sieb, Kilian Thiel, and Bernd Wiswedel
-
[5]
KNIME: The Konstanz Information Miner. InData Analysis, Machine Learn- ing and Applications, Christine Preisach, Hans Burkhardt, Lars Schmidt-Thieme, and Reinhold Decker (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 319– 326
-
[6]
Juan Andrés Carruthers, Jorge Andrés Diaz-Pace, and Emanuel Irrazábal. 2024. A longitudinal study on the temporal validity of software samples. Information and Software Technology 168 (2024), 107404
work page 2024
-
[7]
Alejandra Cervera, Ville Rantanen, Kristian Ovaska, Marko Laakso, Javier Nunez- Fontarnau, Amjad Alkodsi, Julia Casado, Chiara Facciotto, Antti Häkkinen, Riku Louhimo, et al. 2019. Anduril 2: upgraded large-scale data integration framework. Bioinformatics 35, 19 (2019), 3815–3817
work page 2019
-
[8]
William G Cochran. 1977. Sampling Techniques. John Wiley & Sons, Nashville, TN
work page 1977
-
[9]
dblp Team. 2025. dblp computer science bibliography – Monthly Snapshot XML Release of July 2025. doi:10.4230/dblp.xml.2025-07-02
-
[10]
Paolo Di Tommaso, Maria Chatzou, Evan W Floden, Pablo Prieto Barja, Emilio Palumbo, and Cedric Notredame. 2017. Nextflow enables reproducible computa- tional workflows. Nature biotechnology 35, 4 (2017), 316–319
work page 2017
-
[11]
Robert Dyer, Hoan Anh Nguyen, Hridesh Rajan, and Tien N. Nguyen. 2015. Boa: Ultra-Large-Scale Software Repository and Source-Code Mining. ACM Trans. Softw. Eng. Methodol. 25, 1 (Dec. 2015), 34 pages. doi:10.1145/2803171
-
[12]
Martin Fowler. 2010. Domain-specific languages. Pearson Education
work page 2010
-
[13]
June Gorostidi, Adem Ait, Jordi Cabot, and Javier Luis Canovas Izquierdo. 2024. On the Creation of Representative Samples of Software Repositories. In Pro- ceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (Barcelona, Spain) (ESEM ’24). Association for Com- puting Machinery, New York, NY, USA, 434–439....
-
[14]
Eirini Kalliamvakou, Georgios Gousios, Kelly Blincoe, Leif Singer, Daniel M. German, and Daniela Damian. 2014. The promises and perils of mining GitHub. In Proceedings of the 11th Working Conference on Mining Software Repositories (Hyderabad, India) (MSR 2014). Association for Computing Machinery, New York, NY, USA, 92–101. doi:10.1145/2597073.2597074
-
[15]
Johannes Köster and Sven Rahmann. 2012. Snakemake—a scalable bioinformatics workflow engine. Bioinformatics 28, 19 (2012), 2520–2522
work page 2012
-
[16]
William Kruskal and Frederick Mosteller. 1979. Representative sampling, I: Non-scientific literature. International Statistical Review/Revue Internationale de Statistique (1979), 13–24. doi:10.2307/1403202
-
[17]
William Kruskal and Frederick Mosteller. 1979. Representative sampling, II: Scientific literature, excluding statistics. International Statistical Review/Revue Internationale de Statistique (1979), 111–127. doi:10.2307/1402564
-
[18]
William Kruskal and Frederick Mosteller. 1979. Representative Sampling, III: The Current Statistical Literature. International Statistical Review / Revue Inter- nationale de Statistique 47, 3 (1979), 245–265. doi:10.2307/1402647
-
[19]
Romain Lefeuvre, Jessie Galasso, Benoit Combemale, Houari Sahraoui, and Ste- fano Zacchiroli. 2023. Fingerprinting and Building Large Reproducible Datasets. In Proceedings of the 2023 ACM Conference on Reproducibility and Replicability (Santa Cruz, CA, USA) (ACM REP ’23). Association for Computing Machinery, New York, NY, USA, 27–36. doi:10.1145/3589806.3600043
-
[20]
Yuxing Ma, Tapajit Dey, Chris Bogart, Sadika Amreen, Marat Valiev, Adam Tutko, David Kennard, Russell Zaretzki, and Audris Mockus. 2021. World of code: enabling a research workflow for mining and analyzing the universe of open source VCS data. Empirical Softw. Engg. 26, 2 (March 2021), 42 pages. doi:10.1007/s10664-020-09905-9
-
[21]
Yuzhan Ma, Sarah Fakhoury, Michael Christensen, Venera Arnaoudova, Waleed Zogaan, and Mehdi Mirakhorli. 2018. Automatic classification of software arti- facts in open-source applications. In Proceedings of the 15th International Confer- ence on Mining Software Repositories(Gothenburg, Sweden)(MSR ’18). Association for Computing Machinery, New York, NY, US...
-
[22]
Petr Maj, Stefanie Muroya, Konrad Siek, Luca Di Grazia, and Jan Vitek. 2024. The Fault in Our Stars: Designing Reproducible Large-scale Code Analysis Ex- periments. In 38th European Conference on Object-Oriented Programming (ECOOP
work page 2024
-
[23]
313) , Jonathan Aldrich and Guido Salvaneschi (Eds.)
(Leibniz International Proceedings in Informatics (LIPIcs), Vol. 313) , Jonathan Aldrich and Guido Salvaneschi (Eds.). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, Dagstuhl, Germany, 27:1–27:23. doi:10.4230/LIPIcs.ECOOP.2024.27
-
[24]
Frank J Massey Jr. 1951. The Kolmogorov-Smirnov test for goodness of fit. Journal of the American statistical Association 46, 253 (1951), 68–78
work page 1951
-
[25]
Felix Mölder, Kim Philipp Jablonski, Brice Letcher, Michael B. Hall, Christopher Tomkins-Tinch, Vanessa V. Sochat, Jan Forster, Soohyun Lee, Sven Twardziok, Alexander Kanitz, Andreas Wilm, Manuel Holtgrewe, Sven Rahmann, Sven Nahnsen, and Johannes Köster. 2021. Sustainable data analysis with Snakemake. F1000Research 10 (2021), 33. doi:10.12688/F1000RESEAR...
-
[26]
Marcus R Munafò, Brian A Nosek, Dorothy VM Bishop, Katherine S Button, Christopher D Chambers, Nathalie Percie du Sert, Uri Simonsohn, Eric-Jan Wagenmakers, Jennifer J Ware, and John PA Ioannidis. 2017. A manifesto for reproducible science. Nature human behaviour 1, 1 (2017), 0021
work page 2017
-
[27]
Meiyappan Nagappan, Thomas Zimmermann, and Christian Bird. 2013. Diversity in software engineering research. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering (Saint Petersburg, Russia) (ESEC/FSE 2013). Association for Computing Machinery, New York, NY, USA, 466–476. doi:10.1145/2491411.2491415
-
[28]
Karl Pearson. 1992. On the Criterion that a Given System of Deviations from the Probable in the Case of a Correlated System of Variables is Such that it Can be Reasonably Supposed to have Arisen from Random Sampling . Springer New York, New York, NY, 11–28. doi:10.1007/978-1-4612-4380-9_2
-
[29]
Rolf-Helge Pfeiffer. 2020. What constitutes Software? An Empirical, Descriptive Study of Artifacts. In Proceedings of the 17th International Conference on Mining Software Repositories (Seoul, Republic of Korea) (MSR ’20). Association for Com- puting Machinery, New York, NY, USA, 481–491. doi:10.1145/3379597.3387442
-
[30]
Antoine Pietri, Diomidis Spinellis, and Stefano Zacchiroli. 2019. The Software Heritage Graph Dataset: Public Software Development Under One Roof. In 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR) . 138–142. doi:10.1109/MSR.2019.00030
-
[31]
Per Runeson and Martin Höst. 2009. Guidelines for conducting and reporting case study research in software engineering. Empirical Softw. Engg. 14, 2 (April 2009), 131–164. doi:10.1007/s10664-008-9102-8
-
[32]
Ravindra Singh and Naurang Singh Mangat. 1996. Stratified Sampling. Springer Netherlands, Dordrecht, 102–144. doi:10.1007/978-94-017-1404-4_5
-
[33]
M. Vidoni. 2022. A systematic process for Mining Software Repositories: Results from a systematic literature review. 144 (2022), 106791. doi:10.1016/j.infsof.2021. 106791
-
[34]
Yanming Yang, Xin Xia, David Lo, Tingting Bi, John Grundy, and Xiaohu Yang
-
[35]
Predictive Models in Software Engineering: Challenges and Opportunities. ACM Trans. Softw. Eng. Methodol. 31, 3 (apr 2022), 72 pages. doi:10.1145/3503509
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.