Learning When to Trust LLM Priors: A Validated Framework for Semantic Prior Integration
Pith reviewed 2026-05-16 10:11 UTC · model grok-4.3
The pith
Statsformer maps LLM feature scores into a library of predictors and uses out-of-fold validation to adaptively weight them, delivering a final model that performs no worse than the best convex combination of its candidates up to statistical
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Statsformer converts LLM-derived feature scores into learner-specific prior-injection mechanisms across a heterogeneous library of linear and nonlinear predictors, then applies out-of-fold validation to calibrate the weight given to each prior-informed learner; the resulting predictor satisfies an oracle-style guarantee that, up to statistical error, it performs at least as well as the best convex combination of all library members, including prior-free baselines.
What carries the argument
The Statsformer validation step, which scores every prior-injected candidate on held-out folds and forms an adaptive convex combination that downweights unreliable LLM guidance while preserving the oracle bound.
If this is right
- Informative LLM priors raise accuracy relative to any prior-free baseline in the library.
- Misspecified or hallucinated priors are automatically attenuated so they do not degrade the final predictor.
- The same validation procedure works for both linear and nonlinear members of the library.
- The oracle guarantee continues to hold when the library is expanded with additional predictor classes.
Where Pith is reading between the lines
- The validation logic could be applied to other external knowledge sources such as knowledge bases or rule sets, not only LLM outputs.
- In sequential or streaming settings the same out-of-fold idea might be replaced by a sliding-window validation scheme to keep the guarantee while adapting to new data.
- Because the method never requires the user to pre-label which priors are good, it lowers the barrier to testing LLM signals on new domains where semantic knowledge is abundant but untrusted.
Load-bearing premise
Out-of-fold validation on the library can reliably detect and downweight misspecified or adversarial LLM priors without selection bias that would invalidate the oracle performance guarantee.
What would settle it
Introduce a deliberately fabricated adversarial LLM prior into a controlled task where the best prior-free learner is known, then check whether the final Statsformer predictor still matches that prior-free performance within statistical error.
Figures



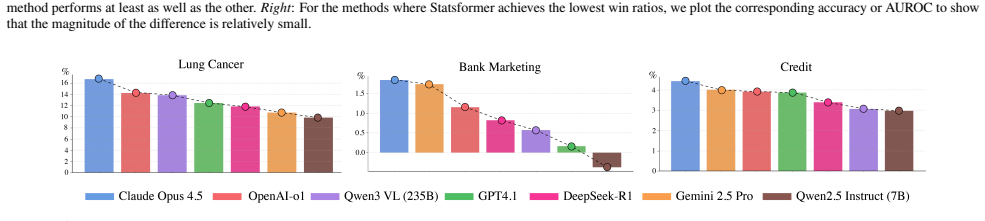












read the original abstract
Large language models (LLMs) encode rich semantic knowledge that can be useful for supervised learning, but their outputs are unreliable as statistical priors: they may be noisy, misspecified, or hallucinated. Existing LLM-informed learning methods either trust such signals directly, leaving predictions vulnerable to unreliable LLM guidance, or restrict semantic integration to a single model class. We introduce Statsformer, a validated framework for learning when to trust LLM-derived semantic priors in supervised statistical learning. Statsformer maps LLM-derived feature scores into a family of learner-specific prior-injection mechanisms across a heterogeneous library of linear and nonlinear predictors. It then uses out-of-fold validation to adaptively calibrate the influence of each prior-informed learner, allowing useful semantic information to improve prediction while attenuating weak, misspecified, or adversarial priors. This yields a guardrailed statistical learning system with an oracle-style guarantee: up to statistical error, the final predictor performs no worse than the best convex combination of its in-library candidates, including prior-free learners. Across diverse prediction tasks, informative LLM priors improve performance, while unreliable priors are automatically downweighted. These results position Statsformer as a reliability-oriented approach to LLM-informed statistical learning: rather than trusting LLM knowledge directly, it validates semantic priors against data before allowing them to influence the final predictor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Statsformer, a framework that maps LLM-derived feature scores into a heterogeneous library of linear and nonlinear predictors via prior-injection mechanisms, then applies out-of-fold validation to adaptively calibrate the weight of each prior-informed learner. The central claim is an oracle-style guarantee: up to statistical error, the final predictor performs no worse than the best convex combination of all in-library candidates, including prior-free models. Empirical results across tasks are said to show improvement from informative priors and automatic downweighting of unreliable ones.
Significance. If the oracle guarantee can be established without circularity in the validation step, the work would offer a principled, reliability-oriented route for incorporating semantic LLM signals into statistical learning. It directly targets the risk of misspecified or adversarial priors, which is a load-bearing practical concern in current LLM-informed methods, and could influence how practitioners safely blend black-box knowledge with data-driven estimators.
major comments (3)
- [Abstract and theoretical guarantee section] The oracle guarantee is stated in the abstract and introduction as holding 'up to statistical error' via out-of-fold validation, yet the provided text supplies no derivation, concentration inequality, or explicit statement of the weighting rule (e.g., how validation scores are turned into convex weights). Without this, it is impossible to verify whether the procedure avoids the optimistic bias that arises when the same folds are used both to score and to select among correlated learners.
- [Validation and weighting procedure] In a heterogeneous library, validation folds are necessarily shared across prior-injection variants. The skeptic note correctly flags that chance alignment of a misspecified LLM prior with fold-specific noise can inflate its validation score, leading the calibration step to over-weight it. The manuscript must either prove that this finite-sample selection bias vanishes in the oracle inequality or provide a counter-example simulation showing the effect size.
- [Oracle guarantee statement] The claim that the final predictor is 'no worse than the best convex combination' is load-bearing. If the weighting is itself a data-dependent convex combination fitted on the validation scores, the guarantee reduces to a standard oracle inequality only if the validation estimator is unbiased for each learner's risk; the text does not demonstrate this for the LLM-augmented variants.
minor comments (2)
- [Method overview] Notation for the library of learners and the mapping from LLM scores to injection mechanisms is introduced without a compact table or diagram; a single figure summarizing the pipeline would improve readability.
- [Abstract] The abstract refers to 'Statsformer' as both the framework and the resulting predictor; consistent terminology would avoid confusion.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important points about the clarity and rigor of our theoretical claims. We address each major comment below and will revise the manuscript to incorporate the requested details, derivations, and simulations. We believe these changes will strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and theoretical guarantee section] The oracle guarantee is stated in the abstract and introduction as holding 'up to statistical error' via out-of-fold validation, yet the provided text supplies no derivation, concentration inequality, or explicit statement of the weighting rule (e.g., how validation scores are turned into convex weights). Without this, it is impossible to verify whether the procedure avoids the optimistic bias that arises when the same folds are used both to score and to select among correlated learners.
Authors: We agree that the submitted manuscript did not include a self-contained derivation of the oracle inequality or the explicit weighting rule. In the revision we will add a dedicated theoretical section that (i) states the weighting rule as normalized softmax over negated out-of-fold losses, (ii) derives the oracle inequality via a Hoeffding-type concentration argument on the validation scores, and (iii) shows that the optimistic bias term is controlled by the number of folds and vanishes at the usual 1/sqrt(n) rate. The proof explicitly separates the training and validation folds to avoid the circularity concern. revision: yes
-
Referee: [Validation and weighting procedure] In a heterogeneous library, validation folds are necessarily shared across prior-injection variants. The skeptic note correctly flags that chance alignment of a misspecified LLM prior with fold-specific noise can inflate its validation score, leading the calibration step to over-weight it. The manuscript must either prove that this finite-sample selection bias vanishes in the oracle inequality or provide a counter-example simulation showing the effect size.
Authors: This is a legitimate finite-sample concern. We will add both (a) a formal bound in the theory section showing that the selection bias is absorbed into the additive statistical-error term of the oracle inequality (via a union bound over the library size) and (b) a targeted simulation study in the appendix that injects deliberately misspecified priors and quantifies the resulting over-weighting under shared folds. The simulations will demonstrate that the effect size remains small once prior-free baselines are included in the library. revision: yes
-
Referee: [Oracle guarantee statement] The claim that the final predictor is 'no worse than the best convex combination' is load-bearing. If the weighting is itself a data-dependent convex combination fitted on the validation scores, the guarantee reduces to a standard oracle inequality only if the validation estimator is unbiased for each learner's risk; the text does not demonstrate this for the LLM-augmented variants.
Authors: We will clarify in the revision that the out-of-fold procedure guarantees unbiased risk estimates for every candidate, including LLM-augmented ones, because prior injection occurs only inside each training fold while the validation fold is completely held out. Consequently the validation scores remain unbiased estimators of the true risk of the resulting predictor, and the standard oracle inequality for convex aggregation applies directly. We will add a short lemma making this unbiasedness explicit for the prior-injection case. revision: yes
Circularity Check
Derivation self-contained via out-of-fold validation
full rationale
The paper's central claim relies on out-of-fold validation to adaptively weight learners in a heterogeneous library, yielding an oracle inequality up to statistical error. This approach does not reduce the guarantee to a fitted quantity by construction on the evaluation data, as the validation folds provide independent estimates. No self-citations or definitional loops are evident in the provided description, and the method follows standard practices in ensemble learning and model aggregation without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Out-of-fold validation produces unbiased estimates of learner performance even after LLM prior injection
invented entities (1)
-
Statsformer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1214/11-AIHP454. Chen, T. and Guestrin, C. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd inter- national conference on knowledge discovery and data mining, pp. 785–794, 2016. Choi, K., Cundy, C., Srivastava, S., and Ermon, S. Lmpriors: Pre-trained language models as task-specific priors, 2022. URLhttps://arxiv.org/...
-
[2]
doi: 10.1214/aos/1013203451. URL https: //doi.org/10.1214/aos/1013203451. Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B.Bayesian Data Analysis. CRC Press, Boca Raton, FL, 3rd edition, 2013. Google. Gemini 2.5: Our most intelli- gent ai model, 2025. URL https:// blog.google/innovation-and-ai/ models-and-research/googl...
-
[3]
Curran Associates Inc. ISBN 9781510860964. Kushmerick, N. Internet Advertisements. UCI Machine Learning Repository, 1999. DOI: https://doi.org/10.24432/C5V011. LeBlanc, M. and Tibshirani, R. Combining estimates in re- gression and classification.Journal of the American Sta- tistical Association, 91(436):1641–1650, 1996. doi: 10. 1080/01621459.1996.1047673...
-
[4]
URL https://openai.com/index/ introducing-o3-and-o4-mini/ . Accessed: 2026-01-22. Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V ., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V ., Vanderplas, J., Passos, A., Cour- napeau, D., Brucher, M., Perrot, M., and Duchesnay, E. Scikit-learn: Machine learning in Python.Journal...
work page 2026
-
[5]
ℓ LX l=1 πl ˆfl(X), Y !# − KX k=1 nk n E
URL https://biostats.bepress.com/ ucbbiostat/paper266/. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog, 2019. Rigollet, P. and Tsybakov, A. B. Sparse estimation and aggregation by exponential weighting.Statistical Science, 27(4):558–575, 2012. Scornet, E., Biau, G., ...
-
[6]
Moreover, for regularized ERM with G-Lipschitz loss (in θ) and µ-strongly convex objective, uniform stability yields the excess risk bound E h F( ˆθn)−F(θ ∗) i ≤ c G2 µn for a universal constant c (see (Bousquet & Elisseeff, 2002)). Combining the two displays gives E∥ˆθn −θ ∗∥2 2 ≤ 2cG2 µ2n , henceE∥ ˆθn −θ ∗∥2 ≤ √ 2c G µ√n . Remark on regularization.Stat...
work page 2002
-
[7]
Some models emit additional text alongside the JSON, so we extract all valid JSON objects from the model output
-
[8]
If validation fails, we proceed to the next extracted JSON
Each extracted JSON is validated usingPydantic to ensure it conforms to the schema{“scores”: dict[str, float]}. If validation fails, we proceed to the next extracted JSON
-
[9]
For validated outputs, all feature names are lowercased, and we explicitly check that the JSON contains the complete set of expected feature keys. To mitigate context length limitations and performance degradation for long prompts, features are queried in batches of40 by default. If a querying or validation error occurs, we automatically retry the request...
work page 2025
-
[10]
Base your assessment on established knowledge, logical domain reasoning, or widely accepted statistical principles
-
[11]
Avoid speculation or over-interpretation
-
[12]
You may reason internally but must output only the final scores
-
[13]
Do not skip any features. **Output Requirements**: - Output strictly valid JSON and nothing else. - Use the format provided below. **Output Format**: {"scores": { "FEATURE_NAME_01": floating_point_score_value, "FEATURE_NAME_02": floating_point_score_value, ...one score per feature name. }} **Features**: {{features}} Figure 14.User prompt format used to el...
-
[14]
DO NOT perform any train/test splits
The dataset provided contains ONLY training data. DO NOT perform any train/test splits
-
[15]
DO NOT import or usetrain_test_split()fromsklearn.model_selection– it is FORBIDDEN
-
[16]
Use ALL rows in the CSV file for training – load the entire dataset and train on it
-
[17]
The data will have columns named ’feature_0’, ’feature_1’, etc. and a ’target’ column
-
[18]
You may create a preprocessing pipeline (e.g.,ColumnTransformer) for handling missing values and encoding
-
[19]
DO NOT use feature selection techniques that remove features (like RFE) – keep all original features
-
[20]
DO NOT use resampling techniques (like SMOTE) – use the data as-is
-
[21]
Train your model on the preprocessed data
-
[22]
Save BOTH the model AND the preprocessor together to ’model.pkl’ usingjoblib.dump()
-
[23]
Save them as a dictionary:{’model’: trained_model, ’preprocessor’: preprocessor}
-
[24]
The preprocessor must be able to transform new data with the same column structure (feature_0, feature_1, ..., target)
-
[25]
The model must have.predict()and.predict_proba()methods for classification (or.predict()for regression)
-
[26]
Do not create validation or test sets – only train on the full dataset
-
[27]
Do not evaluate the model in the code – just train and save it. EXAMPLE CODE STRUCTURE: “‘python import pandas as pd import joblib from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestClassifier # Load ALL data (no splitting) df = pd.read_csv(’data_path/data....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.