Sparse Attention as Compact Kernel Regression
Pith reviewed 2026-05-16 09:21 UTC · model grok-4.3
The pith
Sparse attention corresponds to compact kernel regression via the Nadaraya-Watson estimator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
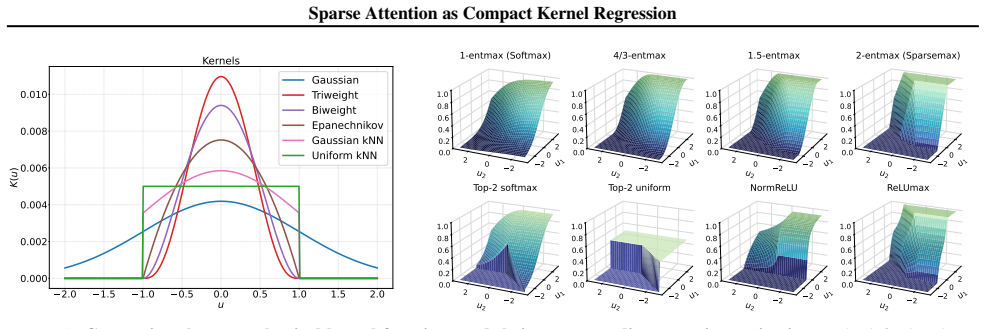
We establish a formal correspondence between sparse attention and compact (bounded support) kernels. We show that normalized ReLU and sparsemax attention arise from Epanechnikov kernel regression under fixed and adaptive normalizations, respectively. More generally, widely used kernels in nonparametric density estimation—including Epanechnikov, biweight, and triweight—correspond to α-entmax attention with α = 1 + 1/n for n in the natural numbers, while the softmax/Gaussian relationship emerges in the limit n to infinity.
What carries the argument
The Nadaraya-Watson kernel regression estimator applied to compact kernels, which produces normalized attention weights that match the regression formula exactly.
If this is right
- Normalized ReLU attention is produced by Epanechnikov kernel regression under fixed normalization.
- Sparsemax attention is produced by the same kernel under adaptive normalization.
- α-entmax attention with α = 1 + 1/n matches the biweight, triweight and related compact kernels.
- The softmax attention mechanism is recovered as the limiting case when the kernel parameter n tends to infinity.
- A kernel-regression replacement for attention inside Memory Mosaics achieves competitive performance on language modeling, in-context learning and length generalization tasks.
Where Pith is reading between the lines
- Other compact kernels outside the entmax parameterization could be used to construct attention layers with different smoothness or cutoff behaviors.
- The bounded-support property of these kernels may directly improve length generalization by restricting effective attention range without explicit masking.
- Analogous kernel correspondences might be derived for memory or retrieval mechanisms that operate outside the standard transformer attention block.
Load-bearing premise
The normalized attention weights exactly reproduce the Nadaraya-Watson estimator for the chosen compact kernel and its normalization scheme.
What would settle it
Compute the explicit Nadaraya-Watson weights for the Epanechnikov kernel on a set of query-key dot products and check whether they equal the normalized ReLU attention weights on the same inputs.
Figures




read the original abstract
Recent work has revealed a link between self-attention mechanisms in transformers and test-time kernel regression via the Nadaraya-Watson estimator, with standard softmax attention corresponding to a Gaussian kernel. However, a kernel-theoretic understanding of sparse attention mechanisms is currently missing. In this paper, we establish a formal correspondence between sparse attention and compact (bounded support) kernels. We show that normalized ReLU and sparsemax attention arise from Epanechnikov kernel regression under fixed and adaptive normalizations, respectively. More generally, we demonstrate that widely used kernels in nonparametric density estimation -- including Epanechnikov, biweight, and triweight -- correspond to $\alpha$-entmax attention with $\alpha = 1 + \frac{1}{n}$ for $n \in \mathbb{N}$, while the softmax/Gaussian relationship emerges in the limit $n \to \infty$. This unified perspective explains how sparsity naturally emerges from kernel design and provides principled alternatives to heuristic top-$k$ attention and other associative memory mechanisms. Experiments with a kernel-regression-based variant of transformers -- Memory Mosaics -- show that kernel-based sparse attention achieves competitive performance on language modeling, in-context learning, and length generalization tasks, offering a principled framework for designing attention mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims a formal correspondence between sparse attention mechanisms and compact (bounded-support) kernel regression via the Nadaraya-Watson estimator. It asserts that normalized ReLU and sparsemax attention arise exactly from Epanechnikov kernel regression under fixed and adaptive normalizations, respectively; more generally, kernels such as Epanechnikov, biweight, and triweight correspond to α-entmax attention for α = 1 + 1/n (with softmax/Gaussian recovered as n → ∞). Experiments with a kernel-regression-based transformer variant (Memory Mosaics) report competitive results on language modeling, in-context learning, and length generalization.
Significance. If the exact correspondences hold, the work supplies a principled nonparametric-statistics foundation for sparse attention design, explains the origin of sparsity from kernel support, and supplies non-heuristic alternatives to top-k or other associative-memory mechanisms. The Memory Mosaics experiments provide initial empirical grounding, though their strength is tied to the precision of the theoretical matches.
major comments (3)
- [§3.2] §3.2 (normalized ReLU definition): the abstract states that normalized ReLU attention 'arises from Epanechnikov kernel regression under fixed normalization.' Standard Nadaraya-Watson is always adaptive (output = ∑ K_i v_i / ∑ K_i). If the paper's fixed normalization divides by a data-independent constant rather than the realized sum of kernel weights, the claimed exact match to the NW estimator does not hold; this is load-bearing for the central correspondence.
- [§3.3] §3.3 (general α-entmax correspondence): the mapping from kernel order n to α = 1 + 1/n is presented as exact, yet the derivation appears to rely on a specific choice of normalization and support truncation. Provide the explicit step that shows the kernel weight function equals the α-entmax output for arbitrary n, including the handling of the partition function.
- [Table 2] Table 2 / §5.1 (Memory Mosaics results): the reported gains over softmax baselines are modest and lack controls that isolate the kernel choice from other architectural differences (e.g., memory size, normalization scheme). Without these ablations the empirical support for the kernel-regression framing remains indirect.
minor comments (2)
- [Abstract] Notation for 'fixed' versus 'adaptive' normalization is introduced without a one-sentence contrast in the abstract or §2; a brief parenthetical would aid readability.
- [Figure 1] Figure 1 caption should explicitly state the kernel and normalization used for each attention variant shown.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (normalized ReLU definition): the abstract states that normalized ReLU attention 'arises from Epanechnikov kernel regression under fixed normalization.' Standard Nadaraya-Watson is always adaptive (output = ∑ K_i v_i / ∑ K_i). If the paper's fixed normalization divides by a data-independent constant rather than the realized sum of kernel weights, the claimed exact match to the NW estimator does not hold; this is load-bearing for the central correspondence.
Authors: We appreciate the referee's observation. The manuscript distinguishes 'fixed' and 'adaptive' normalizations precisely to address this. Fixed normalization divides by a constant (the kernel integral), yielding a non-adaptive estimator. We will revise the abstract and §3.2 to explicitly note that this is a fixed-normalization kernel regression, not the standard adaptive NW estimator. The correspondence to Epanechnikov kernel still holds under this variant. revision: yes
-
Referee: [§3.3] §3.3 (general α-entmax correspondence): the mapping from kernel order n to α = 1 + 1/n is presented as exact, yet the derivation appears to rely on a specific choice of normalization and support truncation. Provide the explicit step that shows the kernel weight function equals the α-entmax output for arbitrary n, including the handling of the partition function.
Authors: We will include a detailed derivation in the revised §3.3. Starting from the kernel K(x) = c_n (1 - x^2)_+^n for |x| < 1, the normalized weights are K(x_i) / Z where Z is the sum. This form matches the α-entmax output p_i = [ (α-1)^{-1} (z_i - τ) ]_+ ^{1/(α-1)} with α = 1 + 1/n, where the threshold τ and partition function Z are determined by the support truncation to ensure the expression is non-negative. The explicit steps equate the power and the normalization constant for general n. revision: yes
-
Referee: [Table 2] Table 2 / §5.1 (Memory Mosaics results): the reported gains over softmax baselines are modest and lack controls that isolate the kernel choice from other architectural differences (e.g., memory size, normalization scheme). Without these ablations the empirical support for the kernel-regression framing remains indirect.
Authors: We concur that the experiments lack isolating ablations, and the gains are modest. The Memory Mosaics architecture bundles multiple modifications. We will revise §5.1 to acknowledge this limitation and state that the results provide preliminary support for the framework, with the primary contribution being the theoretical correspondence. We are unable to perform additional experiments for this revision. revision: partial
Circularity Check
Correspondence extends kernel regression theory to sparse attention without reducing to self-definition or fitted inputs
full rationale
The paper derives normalized ReLU and sparsemax attention as arising from Epanechnikov kernel regression (with fixed vs. adaptive normalization) and generalizes to α-entmax for other compact kernels. These steps equate attention outputs to Nadaraya-Watson estimators by direct substitution of the kernel forms into the regression formula, which is a standard mathematical correspondence rather than a self-referential loop or parameter fit. No load-bearing claim reduces to a self-citation chain or renames a known result as novel; the unification is self-contained against external nonparametric estimation benchmarks. Minor score accounts for possible normalization variants noted in skeptic analysis, but these do not collapse the central equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanisms correspond to the Nadaraya-Watson kernel regression estimator.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
normalized ReLU and sparsemax attention arise from Epanechnikov kernel regression under fixed and adaptive normalizations, respectively... α-entmax attention with α=1+1/n ... K(u)∝[1−∥u∥²]ᵣ₊ where r=(α−1)⁻¹
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
softmax attention corresponding to a Gaussian kernel... rectified polynomial kernels
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2401.12973. Barbero, F., Banino, A., Kapturowski, S., Kumaran, D., Madeira Ara ´ujo, J., Vitvitskyi, O., Pascanu, R., and Veliˇckovi´c, P. Transformers need glasses! information over-squashing in language tasks.Advances in Neural Information Processing Systems, 37:98111–98142,
-
[2]
Titans: Learning to Memorize at Test Time
Behrouz, A., Zhong, P., and Mirrokni, V . Titans: Learning to memorize at test time.arXiv preprint arXiv:2501.00663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL http://arxiv.org/abs/2004. 05150. arXiv: 2004.05150. Epanechnikov, V . A. Non-parametric estimation of a multi- variate probability density.Theory of Probability & Its Ap- plications, 14(1):153–158,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[5]
URLhttps://doi.org/10.1137/1114019
doi: 10.1137/1114019. URLhttps://doi.org/10.1137/1114019. Fu, D. Y ., Dao, T., Saab, K. K., Thomas, A. W., Rudra, A., and R ´e, C. Hungry Hungry Hippos: Towards lan- guage modeling with state space models. InInternational Conference on Learning Representations,
-
[7]
Key-value memory in the brain.arXiv preprint arXiv:2501.02950, 2025
URL https://arxiv.org/abs/2501.02950. Preprint, Jan
-
[8]
doi: 10.1016/j.neuron.2020.07.011. Epub 2020 Aug
-
[9]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
doi: 10.18653/v1/2021.sustainlp-1.5
Association for Computational Linguis- tics. doi: 10.18653/v1/2021.sustainlp-1.5. URL https: //aclanthology.org/2021.sustainlp-1.5/. H¨ardle, W.Applied nonparametric regression. Number
-
[11]
URL https://doi.org/10.1137/ 1109020
doi: 10.1137/1109020. URL https://doi.org/10.1137/ 1109020. Nakanishi, K. M. Scalable-softmax is superior for attention. arXiv preprint arXiv:2501.19399,
- [12]
-
[13]
neurips.cc/paper_files/paper/2015/file/ 8fb21ee7a2207526da55a679f0332de2-Paper.pdf
URL https://proceedings. neurips.cc/paper_files/paper/2015/file/ 8fb21ee7a2207526da55a679f0332de2-Paper.pdf. Sun, Y ., Dong, L., Huang, S., Ma, S., Xia, Y ., Xue, J., Wang, J., and Wei, F. Retentive network: A successor to transformer for large language models,
work page 2015
-
[14]
doi: 10.1037/0735-7044.100.2.147. Tsai, Y .-H. H., Bai, S., Yamada, M., Morency, L.-P., and Salakhutdinov, R. Transformer dissection: An unified understanding for transformer’s attention via the lens of kernel. InEMNLP,
-
[15]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
doi: 10.1146/ annurev.psych.53.100901.135114. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need.Advances in neural information processing systems, 30,
-
[16]
URL https://papers.nips.cc/paper/2017/hash/ 3f5ee243547dee91fbd053c1c4a845aa-Abstract. html. Vasylenko, P., Pitorro, H., Martins, A. F. T., and Treviso, M. Long-context generalization with sparse attention,
work page 2017
-
[17]
Veliˇckovi´c, P., Perivolaropoulos, C., Barbero, F., and Pas- canu, R
URLhttps://arxiv.org/abs/2506.16640. Veliˇckovi´c, P., Perivolaropoulos, C., Barbero, F., and Pas- canu, R. Softmax is not enough (for sharp size gener- alisation). InForty-second International Conference on Machine Learning,
-
[18]
Test-time regression: a unifying framework for design- ing sequence models with associative memory,
URL https://arxiv.org/ abs/2501.12352. Watson, G. S. Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A (1961-2002), 26(4): 359–372,
-
[19]
ISSN 0581572X. URL http://www. jstor.org/stable/25049340. Wu, D., Hu, J. Y .-C., Li, W., Chen, B.-Y ., and Liu, H. Stanhop: Sparse tandem hopfield model for memory- enhanced time series prediction. InThe Twelfth Interna- tional Conference on Learning Representations,
-
[21]
Gated Linear Attention Transformers with Hardware-Efficient Training
URL https://arxiv.org/abs/2312.06635. Yassa, M. A. and Stark, C. E. L. Pattern separation in the hippocampus.Trends in Neurosciences, 34(10):515–525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Zaheer, M., Guruganesh, G., Dubey, K
doi: 10.1016/j.tins.2011.06.006. Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Al- berti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., et al. Big bird: Transformers for longer se- quences.Advances in Neural Information Processing Systems, 33,
-
[23]
Zhang, J., Nolte, N., Sadhukhan, R., Chen, B., and Bottou, L. Memory mosaics. In Yue, Y ., Garg, A., Peng, N., Sha, F., and Yu, R. (eds.),International Conference on Representation Learning, volume 2025, pp. 36412–36433,
work page 2025
-
[24]
iclr.cc/paper_files/paper/2025/file/ 59c3ac496e6fe7be0c2c2b95014e2210-Paper-Conference
URLhttps://proceedings. iclr.cc/paper_files/paper/2025/file/ 59c3ac496e6fe7be0c2c2b95014e2210-Paper-Conference. pdf. 11 Sparse Attention as Compact Kernel Regression A. Proof of Proposition 1 Proof. Let q≡k n and r= 1 α−1. Since ∥ki∥=∥q∥= 1 , we have 1 2 ∥ki −q∥ 2 = 1−k ⊤ i q. The r-weight polynomial kernel is defined as: Kh(ki −q) = 1− ∥ki −q∥ 2 h2 r + (...
work page 2025
-
[25]
All models use the GPT-2 tokenizer (Radford et al.,
(Zhang et al., 2025), complementing the results in the main text (Figure 3). All models use the GPT-2 tokenizer (Radford et al.,
work page 2025
-
[26]
Experiments cover different numbers of parallel layers of persistent and contextual memories
and share a sequence length of 512 tokens. Experiments cover different numbers of parallel layers of persistent and contextual memories. For single-layer models, we vary k∈16,32,64 and report results for the best-performing value (k= 32 ), which is then used for all multi-layer configurations. Each contextual memory unit computes leaky-average keys and on...
work page 2019
-
[27]
B.3. Length Generalization For biological agents, episodic memory scales with the length of life rather than a fixed context window, placing memory retrieval inherently in the long-context regime and requiring continual length generalization. In such settings, dense aggregation over all stored memories would lead to severe interference, motivating the use...
work page 1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.