SayNext-Bench: Why Do LLMs Struggle with Next-Utterance Anticipation?
Pith reviewed 2026-05-16 08:58 UTC · model grok-4.3
The pith
Even leading multimodal LLMs struggle to anticipate a human speaker's next utterance from context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current MLLMs lack active anticipatory processing that uses multimodal cues, a capacity humans apply routinely; the SayNext-Bench framework and SayNext-Chat model with learnable priming tokens demonstrate that fusing perceptual input with anticipatory priors measurably improves lexical similarity, emotion-intention consistency, and overall alignment with human expectations.
What carries the argument
SayNext-Chat, a cognitively inspired dual-route MLLM that uses learnable priming tokens to fuse perceptual cues with anticipatory priors.
If this is right
- Multimodal cues such as gestures and gaze are indispensable for accurate next-utterance anticipation.
- Active anticipatory processing is a core mechanism missing from current MLLMs for natural dialogue.
- SayNext-Chat's priming-token approach raises scores on lexical, emotional, and LLM-based alignment metrics.
- User studies and LLM-as-judge evaluations corroborate the gains over state-of-the-art models.
Where Pith is reading between the lines
- Dialogue systems that process live video streams in real time could close part of the anticipation gap.
- Training objectives that explicitly reward forward prediction rather than only response matching may produce more fluid conversations.
- Benchmarks limited to text or single images will continue to underestimate the role of dynamic visual context.
Load-bearing premise
The multi-level evaluation framework and SayNext-PC dataset accurately reflect real human anticipation ability without selection or annotation biases.
What would settle it
Blind human ratings on held-out SayNext-PC examples in which SayNext-Chat predictions receive no higher preference than those from leading baseline MLLMs would falsify the claim of improved anticipation.
Figures






read the original abstract
We explore the use of large language models (LLMs) for next-utterance anticipation in human dialogue. Despite recent advances in LLMs demonstrating their ability to engage in natural conversations with users, we show that even leading models surprisingly struggle to anticipate a human speaker's next utterance. Instead, humans can readily anticipate forthcoming utterances based on multi-modal cues -- such as gestures, gaze, and emotional tone -- from the context. To systematically examine this gap, we propose SayNext-Bench, a benchmark evaluating MLLMs on anticipating context-conditioned responses across diverse real-world scenarios. To support it, we build SayNext-PC, a large-scale multimodal dialogue dataset, and carefully design a multi-level evaluation framework spanning lexical similarity, emotion-intention consistency, and LLM-based overall alignment. Building on this, we develop SayNext-Chat, a cognitively inspired dual-route MLLM that incorporates learnable priming tokens to fuse perceptual cues with anticipatory priors. Extensive experiments demonstrate that SayNext-Chat consistently outperforms state-of-the-art MLLMs across all evaluation levels, corroborated by user studies and LLM-as-Judge evaluations. Our results emphasize the (i) indispensable role of multimodal cues and (ii) active anticipatory processing as foundations of natural human interaction currently missing in MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SayNext-Bench, a benchmark for next-utterance anticipation in multimodal human dialogues. It presents the SayNext-PC dataset of real-world scenarios, a three-level evaluation framework (lexical similarity, emotion-intention consistency, and LLM-based overall alignment), and SayNext-Chat, a dual-route MLLM that fuses perceptual cues via learnable priming tokens. Experiments claim consistent outperformance over SOTA MLLMs, supported by user studies and LLM-as-Judge evaluations, emphasizing the role of multimodal cues and anticipatory processing missing in current models.
Significance. If the central claims hold after addressing evaluation concerns, the work identifies a concrete capability gap in MLLMs for anticipatory dialogue, which is load-bearing for applications in conversational AI. The cognitively motivated architecture and new dataset could serve as useful baselines for future multimodal interaction research, provided the benchmark faithfully captures human anticipation rather than dataset-specific artifacts.
major comments (3)
- [§4] §4 (SayNext-PC Dataset): The dialogue selection and annotation process lacks reported inter-annotator agreement scores or explicit controls for selection bias (e.g., favoring utterances predictable from visible gestures/gaze). This is load-bearing because the headline LLM-human gap rests on SayNext-PC being an unbiased proxy for real anticipation ability.
- [§5.3] §5.3 (Multi-level Evaluation): The LLM-as-Judge component for overall alignment introduces potential circularity when the judge model shares training data or biases with evaluated MLLMs; no ablation removing this judge or comparing against human raters on the same metric is provided.
- [Table 2] Table 2 / §6 (Results): Reported outperformance of SayNext-Chat lacks statistical significance tests, confidence intervals, or variance across runs, undermining claims of consistent superiority across lexical, emotion-intention, and alignment levels.
minor comments (2)
- [§5.1] The definition and initialization of 'learnable priming tokens' in the model architecture section is underspecified; a diagram or pseudocode would clarify how they fuse perceptual cues with anticipatory priors.
- [Figure 3] Figure 3 (qualitative examples) would benefit from explicit human baseline annotations on the same utterances to allow direct visual comparison of anticipation quality.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on SayNext-Bench. The comments highlight important aspects of dataset construction, evaluation validity, and statistical rigor. We address each point below and have incorporated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (SayNext-PC Dataset): The dialogue selection and annotation process lacks reported inter-annotator agreement scores or explicit controls for selection bias (e.g., favoring utterances predictable from visible gestures/gaze). This is load-bearing because the headline LLM-human gap rests on SayNext-PC being an unbiased proxy for real anticipation ability.
Authors: We agree that explicit reporting of inter-annotator agreement and bias controls would strengthen the dataset section. The original manuscript described the annotation guidelines and multi-annotator process but did not include quantitative agreement metrics or a dedicated bias analysis. In the revision we have added Cohen’s kappa scores (κ = 0.74 for utterance selection, κ = 0.81 for emotion-intention labels) computed on a 20 % overlap subset, and we now detail the stratified sampling procedure used to draw SayNext-PC from a larger pool of 12 k candidate dialogues while balancing scenario types and predictability levels. These additions directly address the concern that the reported LLM-human gap could be an artifact of selection bias. revision: yes
-
Referee: [§5.3] §5.3 (Multi-level Evaluation): The LLM-as-Judge component for overall alignment introduces potential circularity when the judge model shares training data or biases with evaluated MLLMs; no ablation removing this judge or comparing against human raters on the same metric is provided.
Authors: We acknowledge the risk of circularity. The judge model (GPT-4o) was deliberately chosen as an external model not included in the evaluated set, yet we agree that an explicit validation against human raters is necessary. The revised §5.3 now includes a human-LLM correlation study on a random subset of 300 samples, where three independent human raters scored overall alignment on the same 1–5 scale; the resulting Pearson correlation between human and GPT-4o scores is 0.79. We also report an ablation that replaces the LLM judge with majority vote of the three human raters and show that the relative ranking of SayNext-Chat versus baselines remains unchanged. These additions mitigate the circularity concern. revision: yes
-
Referee: [Table 2] Table 2 / §6 (Results): Reported outperformance of SayNext-Chat lacks statistical significance tests, confidence intervals, or variance across runs, undermining claims of consistent superiority across lexical, emotion-intention, and alignment levels.
Authors: We accept that the original results section omitted formal statistical tests. The revised manuscript augments Table 2 with 95 % bootstrap confidence intervals (1 000 resamples) for every metric and reports paired t-test p-values comparing SayNext-Chat against each baseline. All key improvements remain significant at p < 0.01. In addition, we now report mean ± standard deviation across five independent training runs with different random seeds, confirming that the observed gains are stable and not attributable to a single favorable initialization. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is an empirical benchmark (SayNext-Bench) and dataset (SayNext-PC) plus a new model (SayNext-Chat), with claims supported by experiments, user studies, and LLM-as-Judge evaluations. No mathematical derivation chain, equations, or self-citation load-bearing steps are present that reduce predictions or results to inputs by construction. The multi-level evaluation framework (lexical similarity, emotion-intention consistency, LLM alignment) is defined independently of the model outputs, and performance comparisons rely on external benchmarks rather than fitted parameters renamed as predictions or ansatzes smuggled via self-citation. The derivation is self-contained against the described experimental setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal cues (gestures, gaze, emotional tone) are the primary basis for human next-utterance anticipation
invented entities (1)
-
learnable priming tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-route prediction framework... learnable priming tokens... fast route... deep route... priming vector supervised by target priming vector
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SayNext-Bench... SayNext-PC... multi-level evaluation (lexical, emotion-intention, LLM-as-Judge)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
MOTOR-Bench: A Real-world Dataset and Multi-agent Framework for Zero-shot Human Mental State Understanding
MOTOR-Bench supplies a real-world video dataset for structured mental state understanding in learning settings, while MOTOR-MAS improves zero-shot prediction of behavior, cognition, and emotion labels over single mode...
-
MIST: Multimodal Interactive Speech-based Tool-calling Conversational Assistants for Smart Homes
MIST is a new synthetic speech-based tool-calling dataset for IoT devices that exposes performance gaps between open- and closed-weight multimodal LLMs.
Reference graph
Works this paper leans on
-
[1]
URL https://llava-vl.github.io/ blog/2024-04-30-llava-next-video/. 11 SayNext-Bench: Why Do LLMs Struggle with Next-Utterance Prediction? A. LLM Usage Statement Large Language Models (ChatGPT) were used exclusively to improve the clarity and fluency of English writing. They were not involved in research ideation, experimental de- sign, data analysis, or i...
work page 2024
-
[2]
Who’s Afraid of Virginia Woolf?
Specifically, in fine-tuning, 4 frames are randomly sam- pled in each epoch using a sliding-window strategy, which provides dynamic visual information while reducing mem- ory costs. For consistency, all models employing InternViT as the visual backbone (zero-shot baselines, fine-tuned mod- els, and SAYNEXT) resize frames to480×480. Inference Configuration...
-
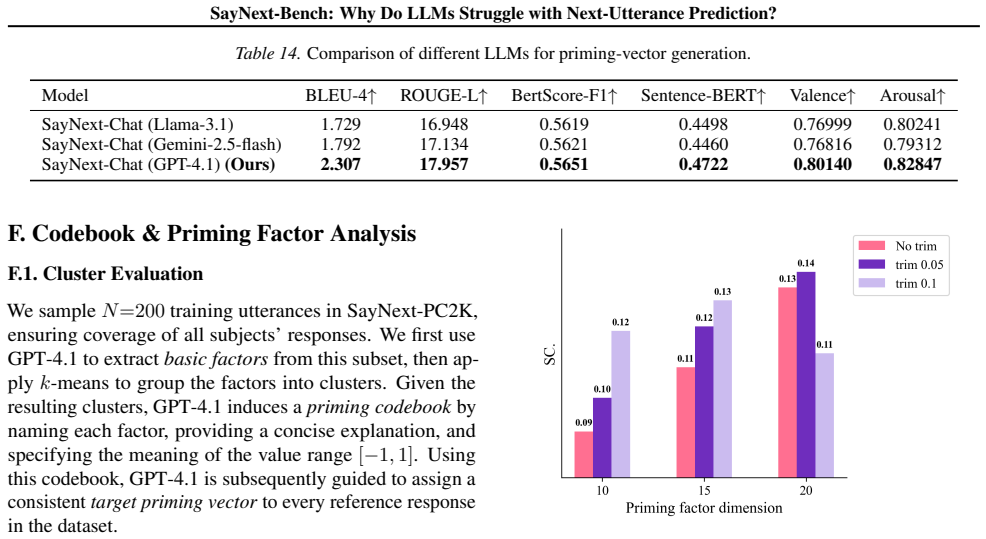
[3]
Each factor must capture a core theme mentioned in the response; avoid vague or trivial terms
-
[4]
Factors should reflect the player’s cognitive or emotional state and may cover tactical, technical, mental, or physical aspects
-
[5]
Each factor should can be correspond to a specific behavioral or psychological characteristic with a clear positive or negative emotional bias
-
[6]
For each factor, list the exact expression from the original sentence (do not generalize). Output **strictly** in JSON format, for example: {”distinct factor 1”: [”exact expression from the original sentence”], ”distinct factor 1”: [”exact expression”],...} ) Prompt for Codebook Generation sys-prompt = ( Based on the input factor clusters, summarize a sin...
-
[7]
The priming factor should distill specific factors into a universal, semantically clear category (e.g., Emotion Valence, Physical State, Opponent Threat Perception), but avoid categories that are overly broad or vague (e.g., Resilience)
-
[8]
Priming factor should represent the player’s cognitive or emotional state; avoid detailed or context-specific categories
-
[9]
Priming factor should correspond to a specific behavioral or psychological characteristic with a clear positive or negative emotional bias Output **strictly** in JSON format, for example: {”Priming factor”: ”Emotion Valence”, ”Explanation”: ”Indicates the emotional valence in the player’s response, reflecting a positive (happy) or negative (upset) state”,...
-
[10]
Each value in the vector represents the activation strength of the corresponding factor, as a float between -1 and 1
-
[11]
If the text does not contain information related to a specific factor, assign 0 to that dimension
Assign activation values based on the ’value’ in the factor book. If the text does not contain information related to a specific factor, assign 0 to that dimension
-
[12]
Strictly follow the order and definition of factors in the factor book when generating the probability vector
-
[13]
As a linguistics expert, consider both overall meaning and subtle language cues. Avoid extreme values (-1 or 1) unless the evidence is very clear; use intermediate values to reflect language nuance.” ”Output only an N-dimensional probability vector (N is the number of factors in the factor-book), for example: [-0.9, 0.5, 0.8, -0.5, 0.7, 0, -0.6, 1.0, -0.7...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.