WST-X Series: Wavelet Scattering Transform for Interpretable Speech Deepfake Detection
Pith reviewed 2026-05-16 08:15 UTC · model grok-4.3
The pith
The WST-X series builds deformation-stable multi-scale features via wavelet scattering to detect speech deepfakes more accurately than prior front-ends.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
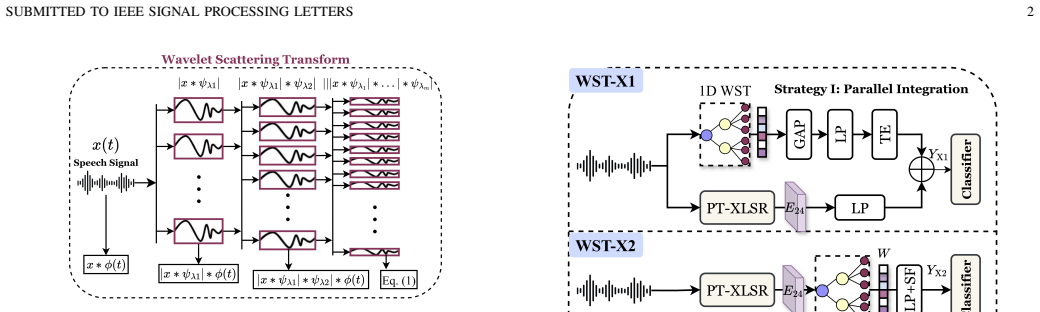
The central claim is that cascading wavelet convolutions with modulus nonlinearities produces deformation-stable, multi-scale features that reliably surface the subtle spectral anomalies in speech deepfakes, delivering higher detection accuracy than hand-crafted filterbank or self-supervised learning front-ends across the Deepfake-Eval-2024 benchmark and cross-dataset evaluations.
What carries the argument
The wavelet scattering transform, which cascades wavelet convolutions followed by modulus nonlinearities to build deformation-stable multi-scale representations of the audio signal.
Load-bearing premise
The wavelet scattering transform's deformation-stable multi-scale features will reliably capture the specific subtle spectral anomalies present in current speech deepfakes without requiring dataset-specific tuning.
What would settle it
A direct comparison on a fresh deepfake test set in which WST-X shows no accuracy improvement over standard MFCC or SSL front-ends would falsify the performance advantage.
Figures

read the original abstract
In this work, we focus on front-end design for speech deepfake detectors, the component that determines the discriminative acoustic cues provided to the classifier. Existing approaches are primarily categorized into two types. Hand-crafted filterbank features are transparent but limited in capturing higher-level information. SSL features, in turn, lack interpretability and may overlook fine-grained spectral anomalies. We propose the WST-X series, a novel family of feature extractors that combines the best of both worlds via the wavelet scattering transform (WST), which cascades wavelet convolutions with modulus nonlinearities to produce deformation-stable, multi-scale features. Experiments on the recent Deepfake-Eval-2024 benchmark, together with cross-dataset evaluations on the SpoofCeleb and In-the-Wild, show that WST-X outperforms existing front-ends by a wide margin. Our analysis reveals that a small averaging scale ($J$), combined with high-frequency and directional resolutions ($Q$, $L$), is critical for capturing subtle artifacts. This underscores the value of stable and translation-invariant features for speech deepfake detection. The code is available at https://github.com/xxuan-acoustics/WST-X-Series.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the WST-X series of front-end feature extractors based on the wavelet scattering transform (WST) for speech deepfake detection. It positions WST-X as combining the interpretability of hand-crafted filterbanks with the multi-scale discriminative power of SSL features, via cascaded wavelet convolutions and modulus nonlinearities that yield deformation-stable representations. Experiments on Deepfake-Eval-2024 plus cross-dataset tests on SpoofCeleb and In-the-Wild are reported to show wide-margin outperformance over existing front-ends; an analysis section identifies small averaging scale J together with high frequency resolution Q and directional resolution L as critical for capturing subtle spectral artifacts.
Significance. If the performance gains prove robust, the work would supply a transparent, parameter-light alternative to opaque SSL embeddings while retaining the stability properties of WST; the public code release is a clear strength for reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of outperformance 'by a wide margin' is presented without error bars, standard deviations across runs, or statistical significance tests (e.g., McNemar or paired t-tests on EER); this directly affects the reliability of both the benchmark and cross-dataset results.
- [Abstract and analysis section] Abstract and analysis section (likely §5): the statement that 'a small averaging scale (J), combined with high-frequency and directional resolutions (Q, L), is critical' is load-bearing for the interpretability narrative, yet no evidence is given that these values were chosen via nested cross-validation on held-out data or transferred from prior WST literature; without such justification the deformation-stability premise is undercut because small J explicitly reduces translation invariance.
- [§4] §4 (cross-dataset protocol): the transfer of the same (J, Q, L) tuple across Deepfake-Eval-2024, SpoofCeleb, and In-the-Wild is asserted without reporting whether the identical hyper-parameters were used or re-tuned per corpus; this is required to substantiate the 'no dataset-specific tuning' implication.
minor comments (2)
- [§3] §3 (WST definition): the notation for the scattering coefficients (e.g., the precise form of the averaging operator) should be written explicitly with equation numbers so readers can map the chosen J, Q, L directly to the formulas.
- [Figures and Tables] Figure captions and Table 1: ensure all reported metrics include the exact evaluation protocol (e.g., whether EER is computed on the official test partition) and list the competing front-ends with their original references.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of outperformance 'by a wide margin' is presented without error bars, standard deviations across runs, or statistical significance tests (e.g., McNemar or paired t-tests on EER); this directly affects the reliability of both the benchmark and cross-dataset results.
Authors: We agree that the lack of error bars, standard deviations, and statistical tests limits the strength of the performance claims. In the revised manuscript we will report standard deviations computed over multiple independent runs with different random seeds and will include paired t-tests (or McNemar tests where appropriate) on the EER values to establish statistical significance of the reported improvements. revision: yes
-
Referee: [Abstract and analysis section] Abstract and analysis section (likely §5): the statement that 'a small averaging scale (J), combined with high-frequency and directional resolutions (Q, L), is critical' is load-bearing for the interpretability narrative, yet no evidence is given that these values were chosen via nested cross-validation on held-out data or transferred from prior WST literature; without such justification the deformation-stability premise is undercut because small J explicitly reduces translation invariance.
Authors: The (J, Q, L) settings were selected following common practice in prior WST literature for audio tasks that emphasize preservation of fine spectral structure. We acknowledge that the current manuscript does not provide an explicit description of the selection procedure or cross-validation results. We will expand the analysis section to cite the relevant WST references, describe the empirical considerations that led to the chosen values, and explicitly discuss the resulting trade-off between deformation stability and translation invariance. revision: partial
-
Referee: [§4] §4 (cross-dataset protocol): the transfer of the same (J, Q, L) tuple across Deepfake-Eval-2024, SpoofCeleb, and In-the-Wild is asserted without reporting whether the identical hyper-parameters were used or re-tuned per corpus; this is required to substantiate the 'no dataset-specific tuning' implication.
Authors: The identical (J, Q, L) tuple was used for all three datasets with no per-corpus re-tuning; this choice was made deliberately to demonstrate cross-dataset generalization. We will revise §4 to state this explicitly, list the exact hyper-parameter values employed, and confirm that no dataset-specific optimization was performed. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces WST-X as a front-end feature extractor built directly on the established wavelet scattering transform (WST) cascade of wavelet convolutions and modulus nonlinearities, citing prior literature for its deformation-stability properties rather than deriving them internally. The central claims rest on empirical evaluations (Deepfake-Eval-2024, SpoofCeleb, In-the-Wild) showing outperformance, with post-hoc analysis of hyperparameters (J, Q, L) presented as observations from those experiments. No equations or steps reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. The method is self-contained against external benchmarks, with no load-bearing self-citations or ansatz smuggling identified in the provided text. Hyperparameter sensitivity is a methodological concern but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
free parameters (3)
- J (averaging scale)
- Q (frequency resolution)
- L (directional resolution)
axioms (1)
- domain assumption Wavelet scattering transform produces deformation-stable and translation-invariant features
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WST cascades wavelet convolutions with modulus nonlinearities to produce deformation-stable, multi-scale features... small averaging scale (J), combined with high-frequency and directional resolutions (Q, L)
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
translation-invariant representation... hierarchical structure of the scattering coefficients
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Multi-View Collaborative Learning Network for Speech Deepfake Detection
Kai Zhang et al. Multi-View Collaborative Learning Network for Speech Deepfake Detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1075–1083, 2025
work page 2025
-
[2]
Zhe Ye et al. Amplifying discriminative distortions: A generative latent feature reinforcement framework for audio spoofing detection.Expert Systems with Applications, page 130206, 2025
work page 2025
-
[3]
Audio deepfake detection with self-supervised wavlm and multi-fusion attentive classifier
Yinlin Guo et al. Audio deepfake detection with self-supervised wavlm and multi-fusion attentive classifier. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12702–12706. IEEE, 2024
work page 2024
-
[4]
Xi Xuan et al. Fake-mamba: Real-time speech deepfake detection using bidirectional mamba as self-attention’s alternative. InProceedings of the IEEE ASRU, 2025
work page 2025
-
[5]
Leveraging SSL Speech Features and Mamba for Enhanced DeepFake Detection
Hoan My Tran et al. Leveraging SSL Speech Features and Mamba for Enhanced DeepFake Detection. InInterspeech 2025, 2025
work page 2025
-
[6]
Allm4add: Unlocking the capabilities of audio large language models for audio deepfake detection
Hao Gu et al. Allm4add: Unlocking the capabilities of audio large language models for audio deepfake detection. InProceedings of the 33rd ACM International Conference on Multimedia, pages 11736– 11745, 2025
work page 2025
-
[7]
A comparison of features for synthetic speech detection
Md Sahidullah et al. A comparison of features for synthetic speech detection. InProceedings of Interspeech 2015, pages 2087–2091, 2015
work page 2015
-
[8]
Mel-spectrogram image-based end-to-end audio deepfake detection under channel-mismatched conditions
Abderrahim Fathan et al. Mel-spectrogram image-based end-to-end audio deepfake detection under channel-mismatched conditions. In2022 IEEE international conference on multimedia and expo (ICME), pages 1–6. IEEE, 2022
work page 2022
-
[9]
Massimiliano Todisco et al. Constant q cepstral coefficients: A spoofing countermeasure for automatic speaker verification.Computer Speech & Language, 45:516–535, 2017
work page 2017
-
[10]
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Arun Babu and others. XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale. InInterspeech 2022, 2022
work page 2022
-
[11]
Wei-Ning Hsu et al. Hubert: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM transactions on audio, speech, and language processing, 29:3451–3460, 2021
work page 2021
-
[12]
Scaling speech technology to 1,000+ languages
Vineel Pratap et al. Scaling speech technology to 1,000+ languages. Journal of Machine Learning Research, 25(97):1–52, 2024
work page 2024
-
[13]
Abdelrahman Mohamed, Hung-yi Lee, Lasse Borgholt, Jakob D Hav- torn, Joakim Edin, Christian Igel, Katrin Kirchhoff, Shang-Wen Li, Karen Livescu, Lars Maaløe, et al. Self-supervised speech represen- tation learning: A review.IEEE Journal of Selected Topics in Signal Processing, 16(6):1179–1210, 2022
work page 2022
-
[14]
International Organization for Standardization. ISO/IEC 30107-3:2023: Information technology – Biometric presentation attack detection – Part 3: Testing and reporting. Technical report, International Organization for Standardization, 2023
work page 2023
-
[15]
J. Chen, X. Liao, Z. Qian, and Z. Qin. Prest-net: Multi-domain probability estimation network for robust image forgery detection. ACM Transactions on Multimedia Computing, Communications, and Applications, 2025
work page 2025
-
[16]
M. Chen, X. Liao, H. Fang, J. Guo, Y . Chen, and X. Wu. Flexible partial screen-shooting watermarking with provable robustness.IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[17]
Y . Li, X. Liao, and X. Wu. Screen-shooting resistant watermarking with grayscale deviation simulation.IEEE Transactions on Multimedia, 2024
work page 2024
-
[18]
L. Fu, X. Liao, J. Guo, L. Dong, and Z. Qin. Waverecovery: Screen- shooting watermarking based on wavelet and recovery.IEEE Transac- tions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[19]
Group invariant scattering.Communications on Pure and Applied Mathematics, 65:1331–1398, 2012
St ´ephane Mallat. Group invariant scattering.Communications on Pure and Applied Mathematics, 65:1331–1398, 2012
work page 2012
-
[20]
Joan Bruna et al. Invariant scattering convolution networks.IEEE transactions on pattern analysis and machine intelligence, 35(8):1872– 1886, 2013
work page 2013
-
[21]
Georgios Valogiannis et al. Towards an optimal estimation of cosmolog- ical parameters with the wavelet scattering transform.Physical Review D, 105(10):103534, 2022
work page 2022
-
[22]
Fatemeh Khatami et al. Origins of scale invariance in vocalization sequences and speech.PLoS computational biology, 14(4):e1005996, 2018
work page 2018
-
[23]
Alessandro Licciardi et al. Whalenet: A novel deep learning architecture for marine mammals vocalizations on watkins marine mammal sound database.IEEE Access, 2024
work page 2024
-
[24]
Deepfake-eval-2024: A multi-modal in-the- wild benchmark of deepfakes circulated in 2024, 2025
Nuria Alina Chandra et al. Deepfake-eval-2024: A multi-modal in-the- wild benchmark of deepfakes circulated in 2024, 2025
work page 2024
-
[25]
Jee-weon Jung et al. Spoofceleb: Speech deepfake detection and sasv in the wild.IEEE Open Journal of Signal Processing, 2025
work page 2025
-
[26]
Does Audio Deepfake Detection Generalize? InInterspeech 2022, pages 2783–2787, 2022
Nicolas M ¨uller, Pavel Czempin, Franziska Diekmann, Adam Froghyar, and Konstantin B ¨ottinger. Does Audio Deepfake Detection Generalize? InInterspeech 2022, pages 2783–2787, 2022
work page 2022
-
[27]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[28]
Kymatio: Scattering transforms in python
Mathieu Andreux et al. Kymatio: Scattering transforms in python. Journal of Machine Learning Research, 21(60):1–6, 2020
work page 2020
-
[29]
Fast wavelet transforms and numerical algorithms i
Beylkin et al. Fast wavelet transforms and numerical algorithms i. Communications on pure and applied mathematics, 44(2):141–183, 1991
work page 1991
-
[30]
A wavelet tour of signal processing, 1999
Mallat Stephane. A wavelet tour of signal processing, 1999
work page 1999
-
[31]
Deep scattering spectrum.IEEE Transactions on Signal Processing, 62(16):4114–4128, 2014
Joakim And ´en and St ´ephane Mallat. Deep scattering spectrum.IEEE Transactions on Signal Processing, 62(16):4114–4128, 2014
work page 2014
-
[32]
Research on front-end of asv system based on mel spectrum in noise scenario
Xi Xuan et al. Research on front-end of asv system based on mel spectrum in noise scenario. In2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), volume 10, pages 2638–2642, 2022
work page 2022
-
[33]
Research on acoustic feature extractor for automatic speaker verification systerm
Xi Xuan and RunPing Han. Research on acoustic feature extractor for automatic speaker verification systerm. In2022 IEEE 10th Joint Inter- national Information Technology and Artificial Intelligence Conference (ITAIC), volume 10, pages 2628–2633, 2022
work page 2022
-
[34]
Multi-scene robust speaker verification system built on improved ecapa-tdnn
Xi Xuan et al. Multi-scene robust speaker verification system built on improved ecapa-tdnn. In2022 IEEE 6th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC ), pages 1689–1693, 2022
work page 2022
-
[35]
Research on speaker identification models based on cnn and additive angular margin loss
Xi Xuan et al. Research on speaker identification models based on cnn and additive angular margin loss. In2021 2nd International Conference on Electronics, Communications and Information Technology (CECIT), pages 1046–1050, 2021
work page 2021
-
[36]
Investigating self-supervised front ends for speech spoofing countermeasures
Xin W. Investigating self-supervised front ends for speech spoofing countermeasures. InThe Speaker and Language Recognition Workshop (Odyssey 2022), pages 112–119, 2022
work page 2022
-
[37]
Multilingual Source Tracing of Speech Deepfakes: A First Benchmark
Xi Xuan et al. Multilingual Source Tracing of Speech Deepfakes: A First Benchmark. In5th Symposium on Security and Privacy in Speech Communication, pages 27–34, 2025
work page 2025
-
[38]
Wavesp-net: Learnable wavelet-domain sparse prompt tuning for speech deepfake detection
Xi Xuan et al. Wavesp-net: Learnable wavelet-domain sparse prompt tuning for speech deepfake detection. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026
work page 2026
-
[39]
Detect all-type deepfake audio: Wavelet prompt tuning for enhanced auditory perception
Yuankun Xie et al. Detect all-type deepfake audio: Wavelet prompt tuning for enhanced auditory perception. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
work page 2026
-
[40]
Asvspoof 5 evaluation plan.https://www
H ´ector Delgado et al. Asvspoof 5 evaluation plan.https://www. asvspoof. org/file/ASVspoof5 Evaluation Plan Phase2. pdf, 2024
work page 2024
-
[41]
Bradley Efron et al. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy.Statistical science, pages 54–75, 1986
work page 1986
-
[42]
librosa: Audio and music signal analysis in python
Brian McFee et al. librosa: Audio and music signal analysis in python. SciPy, 2015:18–24, 2015
work page 2015
-
[43]
Hideyuki Oiso et al. Prompt Tuning for Audio Deepfake Detection: Computationally Efficient Test-time Domain Adaptation with Limited Target Dataset. InInterspeech 2024, pages 2710–2714, 2024
work page 2024
-
[44]
Juan M. Mart ´ın-Do˜nas et al. Exploring Self-supervised Embeddings and Synthetic Data Augmentation for Robust Audio Deepfake Detection. In Interspeech 2024, pages 2085–2089, 2024
work page 2024
-
[45]
Xi Xuan et al. Conformer-based speaker recognition model for real-time multi-scenarios.Computer Engineering and Applications, 60(7):147– 156, 2024
work page 2024
-
[46]
Xi Xuan et al. Efficient real-time multi-scenario speaker recognition with mel-spectrogram-based hybrid tdnn for edge system. InINTERSPEECH 2024-Young Female* Researchers in Speech Workshop (YFRSW 2024), 2024
work page 2024
-
[47]
Audio deepfake detection at the first greeting:” hi!”
Haohan Shi et al. Audio deepfake detection at the first greeting:” hi!”. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.