NeuroPareto: Calibrated Acquisition for Costly Many-Goal Search in Vast Parameter Spaces
Pith reviewed 2026-05-16 08:32 UTC · model grok-4.3
The pith
NeuroPareto integrates calibrated neural classifiers and deep Gaussian process surrogates to guide costly evaluations toward high-quality Pareto fronts in high-dimensional spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NeuroPareto is a single architecture that fuses rank-centric filtering, epistemic uncertainty estimation via a calibrated Bayesian classifier over non-domination tiers, and history-conditioned acquisition via a lightweight network trained on hypervolume improvements; deep Gaussian process surrogates supply refined means and risk-aware signals, all maintained through hierarchical screening and amortized updates so that accuracy holds while evaluation cost drops.
What carries the argument
The integrated architecture of rank-centric filtering, uncertainty disentanglement in a calibrated Bayesian classifier, deep Gaussian process surrogates, and an online-trained lightweight acquisition network.
Load-bearing premise
The rank-centric filtering and uncertainty estimates stay reliable enough in high-dimensional spaces that the hierarchical screening and amortized updates continue to deliver accurate guidance without large extra overhead.
What would settle it
If NeuroPareto is run on the same DTLZ and ZDT problems and the measured hypervolume or Pareto proximity falls below that of the classifier-enhanced or surrogate-assisted baselines, the performance claim does not hold.
Figures





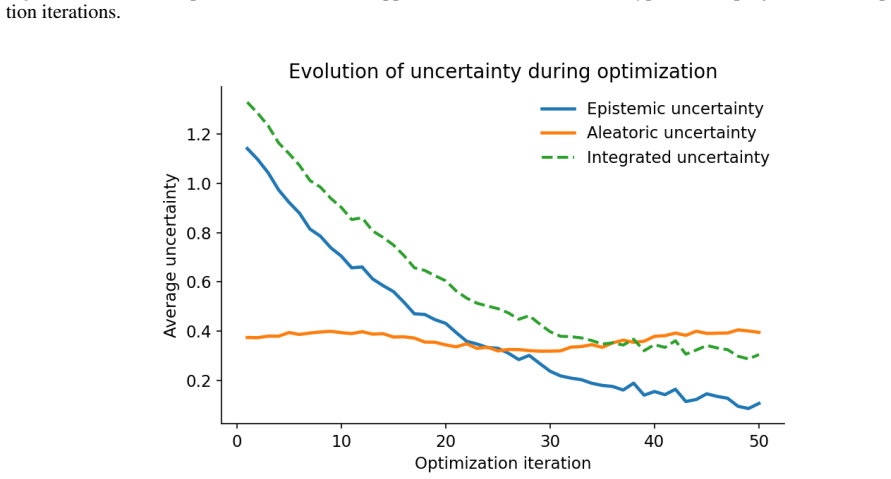













read the original abstract
The pursuit of optimal trade-offs in high-dimensional search spaces under stringent computational constraints poses a fundamental challenge for contemporary multi-objective optimization. We develop NeuroPareto, a cohesive architecture that integrates rank-centric filtering, uncertainty disentanglement, and history-conditioned acquisition strategies to navigate complex objective landscapes. A calibrated Bayesian classifier estimates epistemic uncertainty across non-domination tiers, enabling rapid generation of high-quality candidates with minimal evaluation cost. Deep Gaussian Process surrogates further separate predictive uncertainty into reducible and irreducible components, providing refined predictive means and risk-aware signals for downstream selection. A lightweight acquisition network, trained online from historical hypervolume improvements, guides expensive evaluations toward regions balancing convergence and diversity. With hierarchical screening and amortized surrogate updates, the method maintains accuracy while keeping computational overhead low. Experiments on DTLZ and ZDT suites and a subsurface energy extraction task show that NeuroPareto consistently outperforms classifier-enhanced and surrogate-assisted baselines in Pareto proximity and hypervolume.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NeuroPareto, an integrated architecture for multi-objective optimization in high-dimensional, computationally expensive spaces. It combines rank-centric filtering, a calibrated Bayesian classifier to estimate epistemic uncertainty across non-domination tiers, Deep Gaussian Process surrogates that disentangle reducible and irreducible uncertainty, and a lightweight acquisition network trained online from historical hypervolume improvements. Hierarchical screening and amortized updates are used to control overhead. Experiments on DTLZ/ZDT suites and a subsurface energy extraction task report consistent gains over classifier-enhanced and surrogate-assisted baselines in Pareto proximity and hypervolume.
Significance. If the performance claims hold under the stated assumptions, the work offers a practical contribution to Bayesian optimization for many-objective problems by explicitly separating uncertainty types and amortizing surrogate updates. The online training of the acquisition network directly from hypervolume improvements is a clear methodological strength that avoids circularity.
major comments (3)
- [Experiments] Experiments section: The headline claim of reliable performance in 'vast parameter spaces' rests on the stability of rank-centric filtering and Deep-GP uncertainty estimates, yet the reported DTLZ/ZDT suites are low-to-moderate dimensional and the subsurface task provides no parameter counts, input dimensionality, or scaling ablation; this leaves the central scalability assertion untested.
- [Method] Method description (hierarchical screening and Deep-GP component): The assumption that epistemic uncertainty signals remain reliable beyond ~20–30 dimensions without extra regularization is load-bearing for the claimed advantage over baselines, but no stress-test or failure-mode analysis is supplied; degradation here would directly inject noise into the acquisition network and erase the reported gains.
- [Results] Results tables/figures: No error bars, statistical significance tests, or ablation isolating the contribution of uncertainty disentanglement versus rank-centric filtering are presented, making it impossible to determine whether the outperformance is robust or sensitive to post-hoc hyperparameter choices.
minor comments (2)
- [Abstract] The abstract would benefit from a single sentence stating the typical input dimensionality and number of objectives used in the experiments.
- [Method] Notation for the acquisition network input (historical hypervolume improvements) could be formalized with an equation to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline revisions to strengthen the experimental validation and methodological discussion.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline claim of reliable performance in 'vast parameter spaces' rests on the stability of rank-centric filtering and Deep-GP uncertainty estimates, yet the reported DTLZ/ZDT suites are low-to-moderate dimensional and the subsurface task provides no parameter counts, input dimensionality, or scaling ablation; this leaves the central scalability assertion untested.
Authors: We appreciate the referee's point on explicit validation. The DTLZ/ZDT suites are standard benchmarks that support configurable dimensionality, and the subsurface task involves a practically high-dimensional parameter space. In revision we will explicitly state the input dimensions for every task (including the subsurface case), add a scaling ablation varying dimension and objective count on a subset of problems, and clarify how hierarchical screening is intended to support larger spaces. This will directly address the untested aspect of the scalability claim. revision: yes
-
Referee: [Method] Method description (hierarchical screening and Deep-GP component): The assumption that epistemic uncertainty signals remain reliable beyond ~20–30 dimensions without extra regularization is load-bearing for the claimed advantage over baselines, but no stress-test or failure-mode analysis is supplied; degradation here would directly inject noise into the acquisition network and erase the reported gains.
Authors: The Deep GP architecture is selected precisely because its layered structure improves uncertainty calibration in higher dimensions relative to shallow GPs, while rank-centric filtering reduces sensitivity to noisy uncertainty estimates. We did not provide dedicated stress tests above 30 dimensions because the primary contribution is the integrated pipeline rather than a standalone high-dimensional GP study. In revision we will add a limitations paragraph discussing expected degradation modes and the stabilizing role of the online acquisition network, but we cannot retroactively run new high-dimensional stress tests within the current experimental budget. revision: partial
-
Referee: [Results] Results tables/figures: No error bars, statistical significance tests, or ablation isolating the contribution of uncertainty disentanglement versus rank-centric filtering are presented, making it impossible to determine whether the outperformance is robust or sensitive to post-hoc hyperparameter choices.
Authors: We fully agree that error bars, significance testing, and component ablations are necessary. In the revised manuscript we will report mean and standard deviation over 10 independent runs with error bars on all tables and figures, apply Wilcoxon signed-rank tests with p-values to compare NeuroPareto against each baseline, and insert a new ablation table that isolates the Deep-GP uncertainty disentanglement from the rank-centric filtering step. revision: yes
Circularity Check
No significant circularity; derivation relies on standard online training and experimental validation
full rationale
The paper describes a NeuroPareto architecture integrating rank-centric filtering, uncertainty disentanglement via Bayesian classifiers and Deep GPs, and a lightweight acquisition network trained online from historical hypervolume improvements. This training approach is a standard, non-circular practice in Bayesian optimization and does not reduce the central performance claims (Pareto proximity and hypervolume gains on DTLZ/ZDT and subsurface tasks) to fitted inputs by construction. No self-definitional equations, uniqueness theorems imported from self-citations, or ansatz smuggling appear in the provided derivation chain. The claims rest on empirical outperformance against baselines rather than tautological reductions. The reader's noted assumption about uncertainty reliability in high dimensions is a validity concern, not a circularity issue.
Axiom & Free-Parameter Ledger
free parameters (2)
- acquisition network weights
- uncertainty disentanglement hyperparameters
axioms (1)
- domain assumption Non-domination ranking remains informative in high-dimensional objective spaces
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A calibrated Bayesian classifier estimates epistemic uncertainty across non-domination tiers... Deep Gaussian Process surrogates further separate predictive uncertainty into reducible and irreducible components... history-aware acquisition learner that predicts expected hypervolume improvement
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on DTLZ and ZDT suites... NeuroPareto consistently outperforms... in Pareto proximity and hypervolume
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yong Pang, Yitang Wang, Shuai Zhang, Xiaonan Lai, Wei Sun, and Xueguan Song. An expensive many-objective optimization algorithm based on efficient expected hypervolume improvement.IEEE Transactions on Evolutionary Computation, 27(6):1822–1836, 2022
work page 2022
-
[2]
Guodong Chen, Jiu Jimmy Jiao, Xiaoming Xue, and Zhongzheng Wang. Rank-based learning and local model based evolutionary algorithm for high-dimensional expensive multi-objective problems.arXiv preprint arXiv:2304.09444, 2023
-
[3]
MengChu Zhou, Meiji Cui, Dian Xu, Shuwei Zhu, Ziyan Zhao, and Abdullah Abusorrah. Evolutionary optimiza- tion methods for high-dimensional expensive problems: A survey.IEEE/CAA Journal of Automatica Sinica, 11 (5):1092–1105, 2024
work page 2024
-
[4]
Yuan Yuan and Wolfgang Banzhaf. Expensive multiobjective evolutionary optimization assisted by dominance prediction.IEEE Transactions on Evolutionary Computation, 26(1):159–173, 2021. 9 NeuroPareto
work page 2021
-
[5]
Masksembles for uncertainty estimation
Nikita Durasov, Timur Bagautdinov, Pierre Baque, and Pascal Fua. Masksembles for uncertainty estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13539–13548, 2021
work page 2021
-
[6]
A surrogate-assisted multi-objective evolutionary algorithm guided by hybrid reference points
Shuxian Li, Yong Zhang, Qing Wang, Linchun He, Huijun Li, and Bin Ye. A surrogate-assisted multi-objective evolutionary algorithm guided by hybrid reference points. InInternational Conference on Swarm Intelligence, pages 442–450. Springer, 2024
work page 2024
-
[7]
Rtdk-bo: High dimensional bayesian optimization with reinforced transformer deep kernels
Alexander Shmakov, Avisek Naug, Vineet Gundecha, Sahand Ghorbanpour, Ricardo Luna Gutierrez, Ash- win Ramesh Babu, Antonio Guillen, and Soumyendu Sarkar. Rtdk-bo: High dimensional bayesian optimization with reinforced transformer deep kernels. In2023 IEEE 19th International Conference on Automation Science and Engineering (CASE), pages 1–8. IEEE, 2023
work page 2023
-
[8]
Expensive multi-objective bayesian optimization based on diffusion models
Bingdong Li, Zixiang Di, Yongfan Lu, Hong Qian, Feng Wang, Peng Yang, Ke Tang, and Aimin Zhou. Expensive multi-objective bayesian optimization based on diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27063–27071, 2025
work page 2025
-
[9]
Yuanchao Liu, Jinliang Ding, Qian Li, Fei Li, and Jianchang Liu. A two-level model management-based surrogate- assisted evolutionary algorithm for medium-scale expensive multiobjective optimization.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025
work page 2025
-
[10]
Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. Parallel bayesian optimization of multiple noisy objectives with expected hypervolume improvement.Advances in neural information processing systems, 34: 2187–2200, 2021
work page 2021
-
[11]
Expected hypervolume improvement is a particular hypervolume improvement
Jingda Deng, Jianyong Sun, Qingfu Zhang, and Hui Li. Expected hypervolume improvement is a particular hypervolume improvement. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 16217–16225, 2025
work page 2025
-
[12]
Fei Li, Zhengkun Shang, Yuanchao Liu, Hao Shen, and Yaochu Jin. Inverse distance weighting and radial basis function based surrogate model for high-dimensional expensive multi-objective optimization.Applied Soft Computing, 152:111194, 2024
work page 2024
-
[13]
Poompol Buathong, Jiayue Wan, Raul Astudillo, Samuel Daulton, Maximilian Balandat, and Peter I Frazier. Bayesian optimization of function networks with partial evaluations.arXiv preprint arXiv:2311.02146, 2023
-
[14]
Lei Song, Ke Xue, Xiaobin Huang, and Chao Qian. Monte carlo tree search based variable selection for high dimensional bayesian optimization.Advances in Neural Information Processing Systems, 35:28488–28501, 2022
work page 2022
-
[15]
Dropout as a bayesian approximation: representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on Machine Learning (ICML), pages 1050–1059, 2016
work page 2016
-
[16]
Zaid Abulawi, Rui Hu, Prasanna Balaprakash, and Yang Liu. Bayesian optimized deep ensemble for uncertainty quantification of deep neural networks: a system safety case study on sodium fast reactor thermal stratification modeling.Reliability Engineering & System Safety, page 111353, 2025
work page 2025
-
[17]
Hamzeh Asgharnezhad, Afshar Shamsi, Roohallah Alizadehsani, Arash Mohammadi, and Hamid Alinejad-Rokny. Enhancing monte carlo dropout performance for uncertainty quantification.arXiv preprint arXiv:2505.15671, 2025
-
[18]
Arne De Temmerman, Matthias De Ryck, and Mathias Verbeke. Handling uncertainty with parametric surrogate- assisted optimization for dynamic multi-objective problems.Neural Computing and Applications, pages 1–30, 2025
work page 2025
-
[19]
Amortized variational inference for deep gaussian processes.arXiv preprint arXiv:2409.12301, 2024
Qiuxian Meng and Yongyou Zhang. Amortized variational inference for deep gaussian processes.arXiv preprint arXiv:2409.12301, 2024
-
[20]
Sparse gaussian neural processes.arXiv preprint arXiv:2504.01650, 2025
Tommy Rochussen and Vincent Fortuin. Sparse gaussian neural processes.arXiv preprint arXiv:2504.01650, 2025
-
[21]
Xiao-Qi Guo, Feng-Feng Wei, Jun Zhang, and Wei-Neng Chen. A classifier-ensemble-based surrogate-assisted evolutionary algorithm for distributed data-driven optimization.IEEE Transactions on Evolutionary Computation, 2024. 10 NeuroPareto
work page 2024
-
[22]
Neurolgp-sm: A surrogate-assisted neuroevolution approach using linear genetic programming
Fergal Stapleton, Brendan Cody-Kenny, and Edgar Galván. Neurolgp-sm: A surrogate-assisted neuroevolution approach using linear genetic programming. InInternational Conference on Optimization and Learning, pages 67–81. Springer, 2024
work page 2024
-
[23]
Raquel Espinosa, Gracia Sánchez, José Palma, and Fernando Jiménez. Permutation-based multi-objective evolutionary feature selection for high-dimensional data.arXiv preprint arXiv:2501.14310, 2025
-
[24]
Xiaoxu Jiang, Qingda Chen, Jinliang Ding, and Xingyi Zhang. Dual-population evolution based dynamic constrained multiobjective optimization with discontinuous and irregular feasible regions.IEEE Transactions on Emerging Topics in Computational Intelligence, 2025
work page 2025
-
[25]
A classification and pareto domination based multiobjective evolutionary algorithm
Jinyuan Zhang, Aimin Zhou, and Guixu Zhang. A classification and pareto domination based multiobjective evolutionary algorithm. In2015 IEEE congress on evolutionary computation (CEC), pages 2883–2890. IEEE, 2015
work page 2015
-
[26]
Tinkle Chugh, Yaochu Jin, Kaisa Miettinen, Jussi Hakanen, and Karthik Sindhya. A surrogate-assisted refer- ence vector guided evolutionary algorithm for computationally expensive many-objective optimization.IEEE Transactions on Evolutionary Computation, 22(1):129–142, 2016
work page 2016
-
[27]
Linqiang Pan, Cheng He, Ye Tian, Handing Wang, Xingyi Zhang, and Yaochu Jin. A classification-based surrogate-assisted evolutionary algorithm for expensive many-objective optimization.IEEE Transactions on Evolutionary Computation, 23(1):74–88, 2018
work page 2018
-
[28]
Qiuzhen Lin, Xunfeng Wu, Lijia Ma, Jianqiang Li, Maoguo Gong, and Carlos A Coello Coello. An ensemble surrogate-based framework for expensive multiobjective evolutionary optimization.IEEE Transactions on Evolutionary Computation, 26(4):631–645, 2021
work page 2021
-
[29]
Takumi Sonoda and Masaya Nakata. Multiple classifiers-assisted evolutionary algorithm based on decomposition for high-dimensional multiobjective problems.IEEE Transactions on Evolutionary Computation, 26(6):1581– 1595, 2022
work page 2022
-
[30]
Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions.Journal of Global optimization, 13(4):455–492, 1998
work page 1998
-
[31]
Sequential model-based optimization for general algorithm configuration
Frank Hutter, Holger H Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. InInternational conference on learning and intelligent optimization, pages 507–523. Springer, 2011
work page 2011
-
[32]
Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. Differentiable expected hypervolume improvement for parallel multi-objective bayesian optimization.Advances in neural information processing systems, 33:9851–9864, 2020
work page 2020
-
[33]
Theoretical analyses of multi-objective evolutionary algorithms on multi-modal objectives
Benjamin Doerr and Weijie Zheng. Theoretical analyses of multi-objective evolutionary algorithms on multi-modal objectives. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 12293–12301, 2021
work page 2021
-
[34]
Multi-objective bayesian optimization over high-dimensional search spaces
Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Multi-objective bayesian optimization over high-dimensional search spaces. InUncertainty in Artificial Intelligence, pages 507–517. PMLR, 2022
work page 2022
-
[35]
Andre KY Low, Flore Mekki-Berrada, Abhishek Gupta, Aleksandr Ostudin, Jiaxun Xie, Eleonore Vissol-Gaudin, Yee-Fun Lim, Qianxiao Li, Yew Soon Ong, Saif A Khan, et al. Evolution-guided bayesian optimization for constrained multi-objective optimization in self-driving labs.npj Computational Materials, 10(1):104, 2024. 6 Integrated complexity-reduced algorith...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.