Recognition: no theorem link
Targeted Synthetic Control Method
Pith reviewed 2026-05-16 07:17 UTC · model grok-4.3
The pith
Targeted synthetic control refines initial weights via one-dimensional update to reduce bias while ensuring convex combinations of controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The targeted synthetic control method starts from an initial set of synthetic-control weights via a one-dimensional targeted update through the weight-tilting submodel, which calibrates the weights to reduce bias of weights estimation arising from pre-treatment fit, and ensures that the final counterfactual estimation is a convex combination of observed control outcomes to enable direct interpretation of the synthetic control weights.
What carries the argument
The weight-tilting submodel, a one-dimensional targeted update that refines initial weights to produce stable convex combinations for counterfactual estimation.
If this is right
- TSC produces more stable weights than standard synthetic control methods.
- The final counterfactual estimates remain convex combinations of observed controls, allowing direct weight interpretation.
- TSC avoids unbounded counterfactual estimates that can occur with the augmented synthetic control method.
- The method can be instantiated with arbitrary machine learning models to generate the initial weights.
- Extensive synthetic and real-world experiments demonstrate consistent accuracy gains over state-of-the-art SCM baselines.
Where Pith is reading between the lines
- The targeting step might generalize to multi-unit treatment settings if the submodel is extended accordingly.
- More accurate and interpretable counterfactuals could support improved policy evaluation in settings with panel data.
- Pairing the initial weights with flexible models such as neural networks may yield further gains in high-dimensional data.
Load-bearing premise
The one-dimensional targeted update via the weight-tilting submodel can reliably reduce bias in the initial weights for arbitrary machine learning models without introducing new biases or violating the convexity guarantee.
What would settle it
A controlled simulation with known true counterfactual outcomes shows that the targeted update increases estimation error relative to the initial weights or produces non-convex final weights.
Figures



read the original abstract
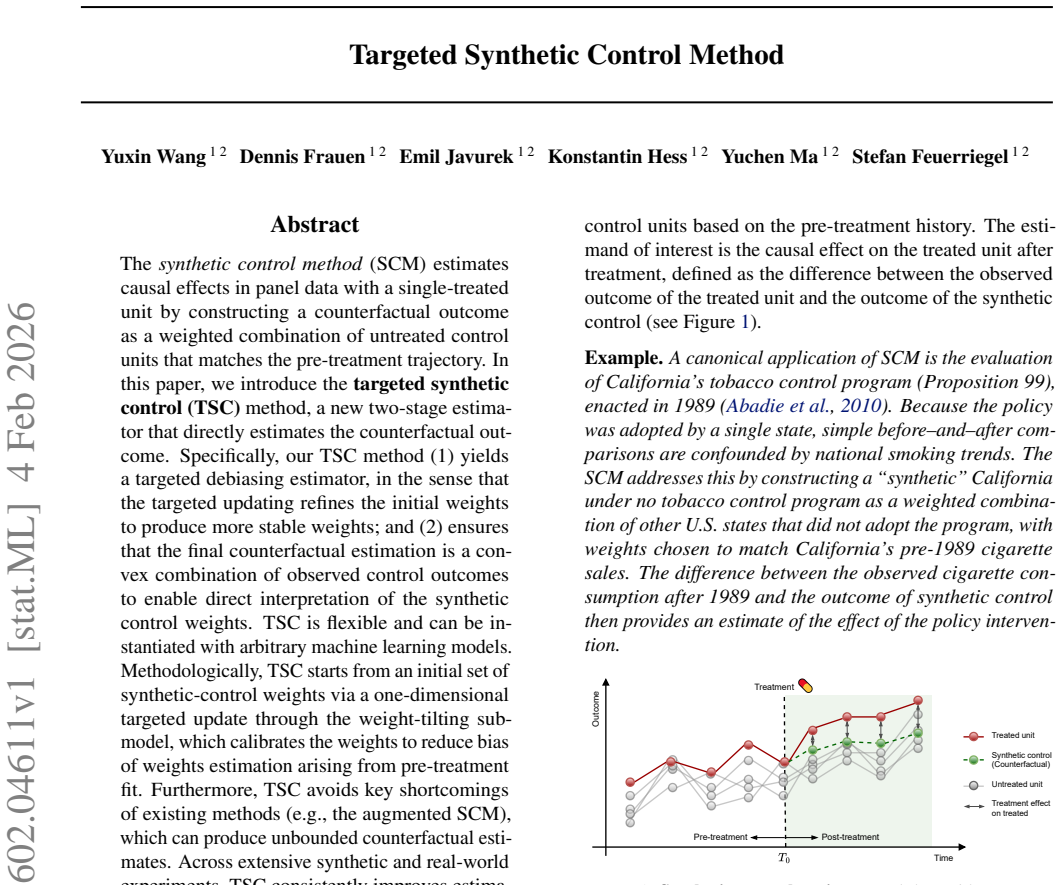
The synthetic control method (SCM) estimates causal effects in panel data with a single-treated unit by constructing a counterfactual outcome as a weighted combination of untreated control units that matches the pre-treatment trajectory. In this paper, we introduce the targeted synthetic control (TSC) method, a new two-stage estimator that directly estimates the counterfactual outcome. Specifically, our TSC method (1) yields a targeted debiasing estimator, in the sense that the targeted updating refines the initial weights to produce more stable weights; and (2) ensures that the final counterfactual estimation is a convex combination of observed control outcomes to enable direct interpretation of the synthetic control weights. TSC is flexible and can be instantiated with arbitrary machine learning models. Methodologically, TSC starts from an initial set of synthetic-control weights via a one-dimensional targeted update through the weight-tilting submodel, which calibrates the weights to reduce bias of weights estimation arising from pre-treatment fit. Furthermore, TSC avoids key shortcomings of existing methods (e.g., the augmented SCM), which can produce unbounded counterfactual estimates. Across extensive synthetic and real-world experiments, TSC consistently improves estimation accuracy over state-of-the-art SCM baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Targeted Synthetic Control (TSC) method, a two-stage estimator for causal effects using synthetic controls in panel data with one treated unit. TSC starts with initial weights from any machine learning model and performs a one-dimensional targeted update via a weight-tilting submodel to refine the weights for reduced pre-treatment bias, while maintaining that the final counterfactual is a convex combination of observed control outcomes. It claims to yield more stable weights, avoid issues like unbounded estimates in augmented SCM, and show improved accuracy over baselines in experiments.
Significance. Should the central claims regarding bias reduction and convexity preservation hold under general ML initializations, TSC would represent a meaningful advance in synthetic control methods by bridging flexible ML estimators with interpretable convex combinations. This flexibility could broaden applicability in high-dimensional or complex data settings, and the experimental improvements suggest potential for better finite-sample performance if the method is robust.
major comments (2)
- [Weight-tilting submodel (method section)] The assertion that the 1D targeted update via the weight-tilting submodel reliably reduces bias and preserves the convex hull property (non-negative weights summing to 1) for arbitrary initial weights from ML models is not supported by a derivation. For general ML outputs that may violate non-negativity or sum-to-one initially, the tilting and subsequent normalization may not guarantee convexity without explicit proof or constraints, which is load-bearing for the interpretability claim.
- [Experimental results] While accuracy gains are reported, the manuscript lacks sufficient detail on how initial ML weights are generated and whether the targeted update specifically contributes to debiasing, as opposed to the base ML model. This makes it difficult to evaluate the weakest assumption that the 1D update suffices for high-dimensional bias structures.
minor comments (1)
- [Abstract] The abstract refers to 'arbitrary machine learning models' but does not clarify if the initial weights are constrained to be convex or how the method handles cases where they are not.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address the major comments point-by-point below and outline the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Weight-tilting submodel (method section)] The assertion that the 1D targeted update via the weight-tilting submodel reliably reduces bias and preserves the convex hull property (non-negative weights summing to 1) for arbitrary initial weights from ML models is not supported by a derivation. For general ML outputs that may violate non-negativity or sum-to-one initially, the tilting and subsequent normalization may not guarantee convexity without explicit proof or constraints, which is load-bearing for the interpretability claim.
Authors: We thank the referee for highlighting this important point. In the revised manuscript, we will include a formal derivation in the methods section demonstrating that the one-dimensional weight-tilting update, followed by normalization, preserves the convex combination property (non-negative weights summing to one) even when the initial ML weights do not satisfy these constraints. The tilting submodel is designed to adjust the weights in a way that maintains interpretability, and we will explicitly show the steps ensuring non-negativity and the sum-to-one condition after normalization. This addresses the load-bearing aspect for the interpretability claim. revision: yes
-
Referee: [Experimental results] While accuracy gains are reported, the manuscript lacks sufficient detail on how initial ML weights are generated and whether the targeted update specifically contributes to debiasing, as opposed to the base ML model. This makes it difficult to evaluate the weakest assumption that the 1D update suffices for high-dimensional bias structures.
Authors: We agree that more detail is needed here. In the revision, we will expand the experimental section to describe precisely how the initial ML weights are generated (e.g., specific models and hyperparameters used). Additionally, we will include an ablation study comparing the performance with and without the targeted update to isolate its contribution to debiasing. This will help demonstrate that the 1D update provides meaningful improvement beyond the base ML model, even in high-dimensional settings. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The TSC method is presented as a two-stage procedure that begins with initial synthetic control weights obtained from arbitrary ML models and then applies a one-dimensional targeted update via the weight-tilting submodel to refine them. The abstract explicitly frames the initial weights as independently obtained inputs and describes the update as a calibration step that reduces bias while preserving convexity. No equations or steps reduce the final counterfactual estimator to a fitted quantity defined in terms of the target result itself, nor do any load-bearing claims collapse into self-definition, renaming of known results, or self-citation chains that are unverified. The derivation remains self-contained against external SCM benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Initial synthetic control weights can be obtained via standard SCM procedures
Reference graph
Works this paper leans on
-
[1]
Arkhangelsky, D., Athey, S., Hirshberg, D. A., Imbens, G. W., and Wager, S. Synthetic difference in differences. arXiv preprint, arXiv:1812.09970,
-
[2]
Che, J., Meng, X., and Miratrix, L. Caliper synthetic match- ing: Generalized radius matching with local synthetic controls.arXiv preprint, arXiv:2411.05246,
-
[3]
Chernozhukov, V ., W¨uthrich, K., and Zhu, Y . An exact and robust conformal inference method for counterfactual and synthetic controls.arXiv preprint, arXiv:1712.09089,
-
[4]
Double/debiased machine learning for treatment and structural parameters
Chernozhukov, V ., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., and Robins, J. Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal, 21(1):C1–C68, 2018a. Chernozhukov, V ., Wuthrich, K., and Zhu, Y . Debiasing and t-tests for synthetic control inference on average causal effects.arXiv prepri...
-
[5]
Fry, J. A method of moments approach to asymp- totically unbiased synthetic controls.arXiv preprint, arXiv:2312.01209,
-
[6]
Fry, J. Robust inference when nuisance parameters may be partially identified with applications to synthetic controls. arXiv preprint, arXiv:2507.00307,
- [7]
- [8]
-
[9]
Ma, H., Frauen, D., and Feuerriegel, S. Deepblip: Estimat- ing conditional average treatment effects over time.arXiv preprint, arXiv:2511.14545,
-
[10]
Morzywolek, P., Decruyenaere, J., and Vansteelandt, S. On weighted orthogonal learners for heterogeneous treatment effects.arXiv preprint, arXiv:2303.12687,
-
[11]
Nie, X. and Wager, S. Quasi-oracle estimation of heterogeneous treatment effects.arXiv preprint, arXiv:1712.04912,
-
[12]
O’Riordan, M. and Gilligan-Lee, C. M. Spillover detection for donor selection in synthetic control models.arXiv preprint, arXiv:2406.11399,
- [13]
-
[14]
J.How the States Shaped the Nation: Ameri- can Electoral Institutions and Voter Turnout, 1920-2000
Springer, M. J.How the States Shaped the Nation: Ameri- can Electoral Institutions and Voter Turnout, 1920-2000. Chicago Studies in American Politics. University of Chicago Press, Chicago, IL,
work page 1920
-
[15]
Sun, Y ., Xie, H., and Zhang, Y
ISBN 978-0-226- 11421-7. Sun, Y ., Xie, H., and Zhang, Y . Difference-in-differences meets synthetic control: Doubly robust identification and estimation.arXiv preprint, arXiv:2503.11375,
-
[16]
Tian, W. The synthetic control method with nonlinear out- comes: Estimating the impact of the 2019 anti-extradition law amendments bill protests on hong kong’s economy. arXiv preprint, arXiv:2306.01967,
-
[17]
Synthetic controls with multiple outcomes.arXiv preprint, arXiv:2304.02272,
Tian, W., Lee, S., and Panchenko, V . Synthetic controls with multiple outcomes.arXiv preprint, arXiv:2304.02272,
-
[18]
van der Laan, M. J., Benkeser, D., and Cai, W. Efficient estimation of pathwise differentiable target parameters with the undersmoothed highly adaptive lasso.arXiv preprint, arXiv:1908.05607,
-
[19]
11 Targeted Synthetic Control Method A. Extended related work Semiparametric inference and orthogonal learning:The concept of Neyman orthogonality is deeply rooted in semipara- metric efficiency theory (Kennedy, 2022; van der Vaart, 2000). Neyman-orthogonal and efficient influence function-based estimators have a long tradition in causal inference, primar...
work page 2022
-
[20]
However, these models provide no formal identifiability guarantee for the prediction
predict the treated unit from trajectories and the control pool, effectively turning the problem into a flexible forecasting task. However, these models provide no formal identifiability guarantee for the prediction. (b) Difference-in-differences (DiD) style methods (e.g., Card & Krueger, 1993; Lan et al., 2025; Arkhangelsky et al., 2018; Sun et al.,
work page 1993
-
[21]
leverage non-linear learners but still rely on strong identifying restrictions, most notably a parallel-trends assumption. (c) Proxy causal inference approaches (e.g., Shi et al., 2021; Liu et al., 2024; Park & Tchetgen Tchetgen, 2025; O’Riordan & Gilligan-Lee, 2024; Zeitler et al.,
work page 2021
-
[22]
attempt to recover causal effects by introducing proxy variables, and identifiability hinges on additional proxy assumptions.Overall, while these non-linear methods can improve predictive fit, their causal interpretation typically requires additional, method-specific assumptions. More synthetic control variants:A related line of work localizes control con...
work page 2024
-
[23]
and denote Y(a) as the potential outcome corresponding to a treatment A=a . We define theresponse functionsas µa(x) =E[Y|X=x, A=a] for a∈ {0,1} and thepropensity score as π(x) =P[A= 1|X=x] . We refer to these functions asnuisance functions, denoted by η= (µ 1, µ0, π). Besides, we impose standard causal inference assumptions (van der Laan & Rubin, 2006; Ch...
work page 2006
-
[24]
More generally, ifY j˜t ∈[a, b], then ˆψTSC ˜t ∈[a, b]by the same argument
Therefore, ˆψTSC ˜t ∈[a, b]. More generally, ifY j˜t ∈[a, b], then ˆψTSC ˜t ∈[a, b]by the same argument. For the one-step estimator, note that it takes the affine form ˆψ1-step ˜t = ˆm˜t(X1) + NX j=2 ˆwjYj˜t − NX j=2 ˆwj ˆm˜t(Xj),(30) which is a difference of two convex combinations plus ˆm˜t(X1). Even if each term individually lies in [a, b], their signe...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.