SOAR: Regression-based LiDAR Relocalization for UAVs
Pith reviewed 2026-05-16 08:08 UTC · model grok-4.3
The pith
SOAR uses sliding-window attention and coordinate-free features to raise UAV LiDAR relocalization success by 40 percent on irregular flight paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SOAR is a regression network that regresses 6-DoF pose from a single LiDAR scan by feeding locally attended features through a coordinate-independent initializer. The locality-preserving sliding window attention with locally invariant positional encoding extracts geometric patterns that stay discriminative when the sensor rotates or changes altitude; the initializer removes global translation and rotation sensitivity before regression.
What carries the argument
Locality-preserving sliding window attention module with locally invariant positional encoding that extracts viewpoint-robust geometric descriptors, together with a coordinate-independent feature initialization module that removes sensitivity to global rigid transformations.
If this is right
- UAVs can maintain meter-level positioning from LiDAR alone during long irregular flights without GNSS.
- Existing car-centric relocalization pipelines become directly usable on aerial platforms once the two modules are added.
- Repeated traversals of the same 3-D environment become a reliable test for viewpoint invariance rather than a niche case.
- Regression networks can now be trained end-to-end on datasets that include large pitch and roll variations without explicit pose augmentation.
Where Pith is reading between the lines
- The same attention pattern could be inserted into visual or radar regression pipelines that also suffer from large viewpoint changes.
- The released dataset supplies a concrete way to measure how much performance drops when a method is moved from ground vehicles to aircraft.
- If the modules generalize, they may reduce the need for expensive 6-DoF pose labels in future UAV datasets.
Load-bearing premise
The attention and initialization modules produce features that remain sufficiently distinctive even when the UAV executes arbitrary rotations and altitude changes not present in the training scenes.
What would settle it
A held-out UAV flight sequence containing rotations or altitude jumps outside the four scenes used for training and testing, on which the reported success rate and mean error fail to improve over prior regression baselines.
Figures














read the original abstract
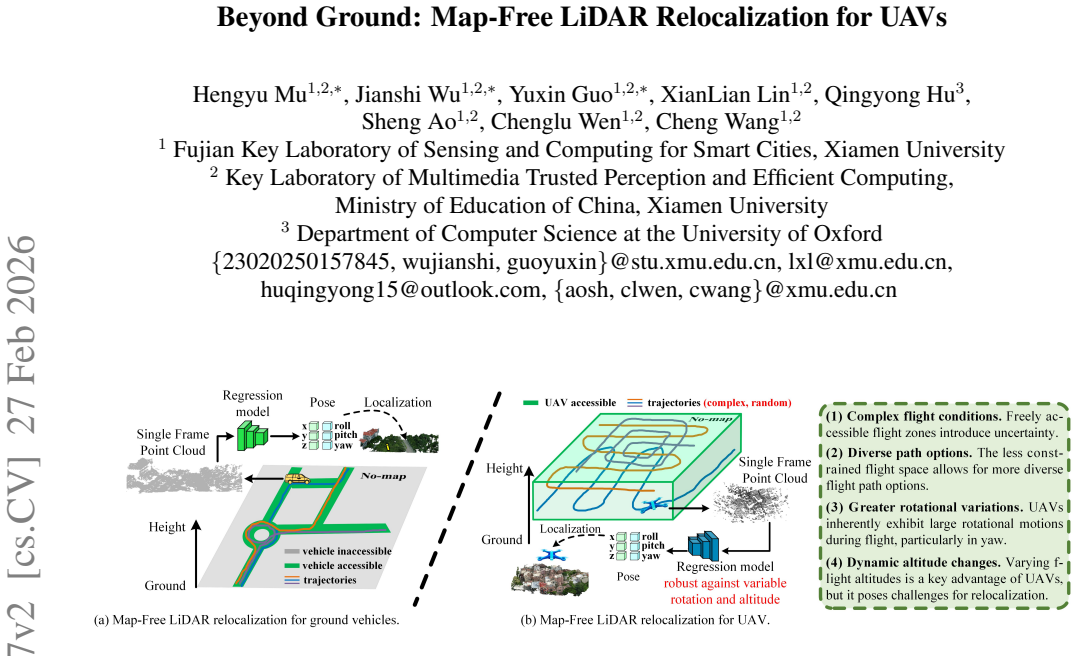
Regression-based LiDAR relocalization has recently emerged as a promising solution for high-precision positioning in GNSS-denied environments. However, these methods are primarily tailored to autonomous driving, exhibiting significantly degraded accuracy in unmanned aerial vehicle (UAV) scenarios due to arbitrary pose variations and irregular flight paths. In this paper, we propose SOAR, a regression-based LiDAR relocalization framework for UAVs. Specifically, we introduce a locality-preserving sliding window attention module with locally invariant positional encoding to capture discriminative geometric structures robust to viewpoint changes. A coordinate-independent feature initialization module is further designed to eliminate sensitivity to global transformations. Furthermore, most existing UAV datasets are limited to evaluate LiDAR relocalization in real-world, due to the lack of synchronized LiDAR scans, accurate 6-DoF poses, or multiple traversals. Thus, we construct a large-scale UAV LiDAR localization dataset with 4 scenes and 13 irregular paths exhibiting rotation and altitude variations, providing a more realistic benchmark for UAVs. Extensive experiments demonstrate that our method achieves state-of-the-art performance, improving the localization success rate by 40% and reducing mean error over 10m on UAVLoc. Our code and dataset will be released soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SOAR, a regression-based LiDAR relocalization framework for UAVs. It introduces a locality-preserving sliding window attention module with locally invariant positional encoding to capture discriminative geometric structures robust to viewpoint changes, along with a coordinate-independent feature initialization module to eliminate sensitivity to global transformations. The authors also release a new large-scale UAV LiDAR dataset (UAVLoc) comprising 4 scenes and 13 irregular paths that exhibit rotation and altitude variations. Extensive experiments are reported to demonstrate state-of-the-art performance, specifically a 40% improvement in localization success rate and a mean error reduction exceeding 10 m on UAVLoc.
Significance. If the performance claims hold after verification, the work would meaningfully advance regression-based LiDAR relocalization for UAVs in GNSS-denied settings, where existing driving-oriented methods degrade under arbitrary poses. The new UAVLoc benchmark with multiple irregular traversals fills a documented gap in realistic aerial datasets and could become a standard reference for future UAV localization research.
major comments (2)
- [§4.2] §4.2 (Experiments on UAVLoc): The central claim of a 40% success-rate lift and >10 m mean-error reduction rests on the two proposed modules, yet no ablation tables isolate their individual contributions versus a standard regression backbone under the rotation/altitude variations of the 13 paths. This omission makes it impossible to confirm that the locality-preserving attention and coordinate-independent initialization are the load-bearing factors for the reported gains.
- [§3.1] §3.1 (Locality-preserving sliding window attention): The locally invariant positional encoding is asserted to produce viewpoint-robust features, but the manuscript provides neither a derivation showing invariance under the specific 6-DoF variations in UAVLoc nor quantitative verification (e.g., feature similarity metrics before/after rotation). Without this, the robustness assumption underlying the headline numbers remains unsecured.
minor comments (1)
- [Figure 2] Figure 2: The diagram of the coordinate-independent initialization module would be clearer if it explicitly annotated the removal of global translation/rotation components rather than relying on textual description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and will revise the paper accordingly to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Experiments on UAVLoc): The central claim of a 40% success-rate lift and >10 m mean-error reduction rests on the two proposed modules, yet no ablation tables isolate their individual contributions versus a standard regression backbone under the rotation/altitude variations of the 13 paths. This omission makes it impossible to confirm that the locality-preserving attention and coordinate-independent initialization are the load-bearing factors for the reported gains.
Authors: We agree that dedicated ablation studies are required to isolate the contributions of each module. In the revised manuscript, we will add new ablation tables in Section 4.2. These will compare: (i) a standard regression backbone, (ii) the backbone augmented only with the locality-preserving sliding window attention, (iii) the backbone augmented only with the coordinate-independent feature initialization, and (iv) the full SOAR model. All variants will be evaluated on the full UAVLoc dataset, with separate reporting for the 13 irregular paths that include rotation and altitude variations, to quantify the individual and synergistic effects on success rate and mean error. revision: yes
-
Referee: [§3.1] §3.1 (Locality-preserving sliding window attention): The locally invariant positional encoding is asserted to produce viewpoint-robust features, but the manuscript provides neither a derivation showing invariance under the specific 6-DoF variations in UAVLoc nor quantitative verification (e.g., feature similarity metrics before/after rotation). Without this, the robustness assumption underlying the headline numbers remains unsecured.
Authors: We acknowledge that a formal derivation and quantitative verification would improve rigor. In the revised Section 3.1 we will add a mathematical derivation establishing the local invariance of the positional encoding under 6-DoF transformations (rotations and translations) consistent with the UAVLoc paths. We will also include new quantitative results in the experiments section, reporting average cosine similarity (and other similarity metrics) of the encoded features before and after applying the observed 6-DoF variations from the 13 paths, thereby empirically confirming viewpoint robustness. revision: yes
Circularity Check
No circularity detected; claims rest on empirical evaluation of proposed modules and new dataset
full rationale
The paper introduces two new modules (locality-preserving sliding window attention with locally invariant positional encoding, and coordinate-independent feature initialization) to address UAV-specific challenges, constructs a new UAVLoc dataset with 4 scenes and 13 paths, and reports experimental improvements (40% success rate lift, >10m error reduction) on that benchmark. No equations, derivations, or first-principles results are shown that reduce by construction to fitted inputs, self-citations, or renamed known results. The performance numbers are presented as outcomes of experiments rather than tautological predictions, and the abstract and described structure contain no load-bearing self-referential steps. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spinnet: Learning a gen- eral surface descriptor for 3d point cloud registration
Sheng Ao, Qingyong Hu, Bo Yang, Andrew Markham, and Yulan Guo. Spinnet: Learning a gen- eral surface descriptor for 3d point cloud registration. In CVPR, pages 11753–11762, 2021. 2
work page 2021
-
[2]
You only train once: Learning general and distinctive 3d local de- scriptors
Sheng Ao, Yulan Guo, Qingyong Hu, Bo Yang, An- drew Markham, and Zengping Chen. You only train once: Learning general and distinctive 3d local de- scriptors. TPAMI, 45(3):3949–3967, 2022. 2
work page 2022
-
[3]
Buffer: Balancing accuracy, efficiency, and generalizability in point cloud registration
Sheng Ao, Qingyong Hu, Hanyun Wang, Kai Xu, and Yulan Guo. Buffer: Balancing accuracy, efficiency, and generalizability in point cloud registration. In CVPR, pages 1255–1264, 2023. 2
work page 2023
-
[4]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Daniyar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. In ECCV, pages 690–708. Springer, 2022. 2
work page 2022
-
[5]
The oxford radar robot- car dataset: A radar extension to the oxford robotcar dataset
Dan Barnes, Matthew Gadd, Paul Murcutt, Paul New- man, and Ingmar Posner. The oxford radar robot- car dataset: A radar extension to the oxford robotcar dataset. In ICRA, pages 6433–6438. IEEE, 2020. 6, 15
work page 2020
-
[6]
Method for regis- tration of 3-d shapes
Paul J Besl and Neil D McKay. Method for regis- tration of 3-d shapes. In Sensor fusion IV: control paradigms and data structures, pages 586–606. Spie,
-
[7]
Accelerated coordinate encod- ing: Learning to relocalize in minutes using rgb and poses
Eric Brachmann, Tommaso Cavallari, and Vic- tor Adrian Prisacariu. Accelerated coordinate encod- ing: Learning to relocalize in minutes using rgb and poses. In CVPR, pages 5044–5053, 2023. 2
work page 2023
-
[8]
Geometry-aware learning of maps for camera localization
Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, and Jan Kautz. Geometry-aware learning of maps for camera localization. In CVPR, pages 2616– 2625, 2018. 2
work page 2018
-
[9]
nuscenes: A multimodal dataset for autonomous driv- ing
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krish- nan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driv- ing. In CVPR, pages 11621–11631, 2020. 2
work page 2020
-
[10]
University of michigan north cam- pus long-term vision and lidar dataset
Nicholas Carlevaris-Bianco, Arash K Ushani, and Ryan M Eustice. University of michigan north cam- pus long-term vision and lidar dataset. IJRR, 35(9): 1023–1035, 2016. 6, 15
work page 2016
-
[11]
Suma++: Efficient lidar-based semantic slam
Xieyuanli Chen, Andres Milioto, Emanuele Palaz- zolo, Philippe Giguere, Jens Behley, and Cyrill Stach- niss. Suma++: Efficient lidar-based semantic slam. In IROS, pages 4530–4537. IEEE, 2019. 2
work page 2019
-
[12]
Gennbv: Generalizable next-best- view policy for active 3d reconstruction
Xiao Chen, Quanyi Li, Tai Wang, Tianfan Xue, and Jiangmiao Pang. Gennbv: Generalizable next-best- view policy for active 3d reconstruction. In CVPR, pages 16436–16445, 2024. 1
work page 2024
-
[13]
Diffusion models in vi- sion: A survey
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vi- sion: A survey. TPAMI, 45(9):10850–10869, 2023. 3
work page 2023
-
[14]
Aritra Dutta, Srijan Das, Jacob Nielsen, Rajatsubhra Chakraborty, and Mubarak Shah. Multiview aerial vi- sual recognition (mavrec): Can multi-view improve aerial visual perception? In CVPR, pages 22678– 22690, 2024. 1
work page 2024
-
[15]
Martin A Fischler and Robert C Bolles. Random sam- ple consensus: a paradigm for model fitting with ap- plications to image analysis and automated cartogra- phy. Communications of the ACM, 24(6):381–395,
-
[16]
Vision meets robotics: The kitti dataset
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. IJRR, 32(11):1231–1237, 2013. 6, 15
work page 2013
-
[17]
Peiyu Guan, Zhiqiang Cao, Junzhi Yu, Chao Zhou, and Min Tan. Scene coordinate regression network with global context-guided spatial feature transforma- tion for visual relocalization. RAL, 6(3):5737–5744,
-
[18]
Denois- ing diffusion probabilistic models.NeurIPS, 33:6840– 6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denois- ing diffusion probabilistic models.NeurIPS, 33:6840– 6851, 2020. 3
work page 2020
-
[19]
Difflo: Semantic- aware lidar odometry with diffusion-based refinement
Yongshu Huang, Chen Liu, Minghang Zhu, Sheng Ao, Chenglu Wen, and Cheng Wang. Difflo: Semantic- aware lidar odometry with diffusion-based refinement. In CVPR, pages 17050–17059, 2025. 2
work page 2025
-
[20]
Prior guided dropout for robust visual localization in dynamic en- vironments
Zhaoyang Huang, Yan Xu, Jianping Shi, Xiaowei Zhou, Hujun Bao, and Guofeng Zhang. Prior guided dropout for robust visual localization in dynamic en- vironments. In ICCV, pages 2791–2800, 2019. 3
work page 2019
-
[21]
Modelling uncer- tainty in deep learning for camera relocalization
Alex Kendall and Roberto Cipolla. Modelling uncer- tainty in deep learning for camera relocalization. In ICRA, pages 4762–4769. IEEE, 2016. 3
work page 2016
-
[22]
Giseop Kim, Sunwook Choi, and Ayoung Kim. Scan context++: Structural place recognition robust to ro- tation and lateral variations in urban environments. IEEE TRO, 38(3):1856–1874, 2021. 2
work page 2021
-
[23]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 7
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[24]
Minkloc3d: Point cloud based large-scale place recognition
Jacek Komorowski. Minkloc3d: Point cloud based large-scale place recognition. In W ACV, pages 1790– 1799, 2021. 3
work page 2021
-
[25]
Egonn: Egocentric neural network for point cloud based 6dof relocalization at the city scale
Jacek Komorowski, Monika Wysoczanska, and Tomasz Trzcinski. Egonn: Egocentric neural network for point cloud based 6dof relocalization at the city scale. RAL, 7(2):722–729, 2021. 8, 16
work page 2021
-
[26]
Mars-lvig dataset: A multi-sensor aerial robots slam dataset for lidar- visual-inertial-gnss fusion
Haotian Li, Yuying Zou, Nan Chen, Jiarong Lin, Xiyuan Liu, Wei Xu, Chunran Zheng, Rundong Li, Dongjiao He, Fanze Kong, et al. Mars-lvig dataset: A multi-sensor aerial robots slam dataset for lidar- visual-inertial-gnss fusion. IJRR, 43(8):1114–1127,
-
[27]
Sgloc: Scene geome- try encoding for outdoor lidar localization
Wen Li, Shangshu Yu, Cheng Wang, Guosheng Hu, Siqi Shen, and Chenglu Wen. Sgloc: Scene geome- try encoding for outdoor lidar localization. In CVPR, pages 9286–9295, 2023. 3, 4, 7, 16
work page 2023
-
[28]
Dif- floc: Diffusion model for outdoor lidar localization
Wen Li, Yuyang Yang, Shangshu Yu, Guosheng Hu, Chenglu Wen, Ming Cheng, and Cheng Wang. Dif- floc: Diffusion model for outdoor lidar localization. In CVPR, pages 15045–15054, 2024. 3
work page 2024
-
[29]
Lightloc: Learning outdoor lidar localization at light speed
Wen Li, Chen Liu, Shangshu Yu, Dunqiang Liu, Yin Zhou, Siqi Shen, Chenglu Wen, and Cheng Wang. Lightloc: Learning outdoor lidar localization at light speed. In CVPR, pages 6680–6689, 2025. 2, 7, 16
work page 2025
-
[30]
Condo: Continual domain expansion for absolute pose regression
Zijun Li, Zhipeng Cai, Bochun Yang, Xuelun Shen, Siqi Shen, Xiaoliang Fan, Michael Paulitsch, and Cheng Wang. Condo: Continual domain expansion for absolute pose regression. In AAAI, pages 14628– 14636, 2025. 3
work page 2025
-
[31]
Quatro++: Robust global registration exploiting ground segmen- tation for loop closing in lidar slam
Hyungtae Lim, Beomsoo Kim, Daebeom Kim, Eu- ngchang Mason Lee, and Hyun Myung. Quatro++: Robust global registration exploiting ground segmen- tation for loop closing in lidar slam. IJRR, 43(5):685– 715, 2024. 3
work page 2024
-
[32]
Text to point cloud localization with multi-level negative contrastive learning
Dunqiang Liu, Shujun Huang, Wen Li, Siqi Shen, and Cheng Wang. Text to point cloud localization with multi-level negative contrastive learning. In AAAI, pages 5397–5405, 2025. 2
work page 2025
-
[33]
Translo: A window-based masked point transformer framework for large-scale lidar odometry
Jiuming Liu, Guangming Wang, Chaokang Jiang, Zhe Liu, and Hesheng Wang. Translo: A window-based masked point transformer framework for large-scale lidar odometry. In AAAI, pages 1683–1691, 2023. 2
work page 2023
-
[34]
Quan Liu, Hongzi Zhu, Zhenxi Wang, Yunsong Zhou, Shan Chang, and Minyi Guo. Extend your own cor- respondences: Unsupervised distant point cloud reg- istration by progressive distance extension. In CVPR, pages 20816–20826, 2024. 3
work page 2024
-
[35]
Aerialvln: Vision- and-language navigation for uavs
Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Yanning Zhang, and Qi Wu. Aerialvln: Vision- and-language navigation for uavs. In ICCV, pages 15384–15394, 2023. 1
work page 2023
-
[36]
Bevplace: Learning lidar-based place recogni- tion using bird’s eye view images
Lun Luo, Shuhang Zheng, Yixuan Li, Yongzhi Fan, Beinan Yu, Si-Yuan Cao, Junwei Li, and Hui-Liang Shen. Bevplace: Learning lidar-based place recogni- tion using bird’s eye view images. In ICCV, pages 8700–8709, 2023. 2
work page 2023
-
[37]
Bevplace++: Fast, ro- bust, and lightweight lidar global localization for un- manned ground vehicles
Lun Luo, Si-Yuan Cao, Xiaorui Li, Jintao Xu, Rui Ai, Zhu Yu, and Xieyuanli Chen. Bevplace++: Fast, ro- bust, and lightweight lidar global localization for un- manned ground vehicles. IEEE TRO, 41:4479–4498,
-
[38]
Ntu viral: A visual-inertial-ranging-lidar dataset, from an aerial vehicle viewpoint
Thien-Minh Nguyen, Shenghai Yuan, Muqing Cao, Yang Lyu, Thien Hoang Nguyen, and Lihua Xie. Ntu viral: A visual-inertial-ranging-lidar dataset, from an aerial vehicle viewpoint. IJRR, 41(3):270–280, 2022. 2, 6, 15
work page 2022
-
[39]
Yue Pan, Xingguang Zhong, Louis Wiesmann, Thorbj¨orn Posewsky, Jens Behley, and Cyrill Stach- niss. Pin-slam: Lidar slam using a point-based im- plicit neural representation for achieving global map consistency. IEEE TRO, 40:4045–4064, 2024. 2
work page 2024
-
[40]
Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space. NIPS, 30, 2017. 2
work page 2017
-
[41]
Geometric transformer for fast and robust point cloud registration
Zheng Qin, Hao Yu, Changjian Wang, Yulan Guo, Yuxing Peng, and Kai Xu. Geometric transformer for fast and robust point cloud registration. In CVPR, pages 11143–11152, 2022. 3
work page 2022
-
[42]
Understanding the limitations of cnn-based absolute camera pose regression
Torsten Sattler, Qunjie Zhou, Marc Pollefeys, and Laura Leal-Taixe. Understanding the limitations of cnn-based absolute camera pose regression. In CVPR, pages 3302–3312, 2019. 3
work page 2019
-
[43]
Efficient ransac for point-cloud shape detection
Ruwen Schnabel, Roland Wahl, and Reinhard Klein. Efficient ransac for point-cloud shape detection. In Computer graphics forum, pages 214–226, 2007. 4
work page 2007
-
[44]
Lvi-sam: Tightly-coupled lidar-visual-inertial odometry via smoothing and mapping
Tixiao Shan, Brendan Englot, Carlo Ratti, and Daniela Rus. Lvi-sam: Tightly-coupled lidar-visual-inertial odometry via smoothing and mapping. In ICRA, pages 5692–5698. IEEE, 2021. 2
work page 2021
-
[45]
Scene coordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. In CVPR, pages 2930–2937, 2013. 3
work page 2013
-
[46]
Mun-frl: a visual-inertial-lidar dataset for aerial autonomous navigation and map- ping
Ravindu G Thalagala, Oscar De Silva, Awantha Jayasiri, Arthur Gubbels, George KI Mann, and Ray- mond G Gosine. Mun-frl: a visual-inertial-lidar dataset for aerial autonomous navigation and map- ping. IJRR, 43(12):1853–1866, 2024. 6, 15
work page 2024
-
[47]
Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition
Mikaela Angelina Uy and Gim Hee Lee. Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition. In CVPR, pages 4470–4479, 2018. 3
work page 2018
-
[48]
Pwclo-net: Deep lidar odometry in 3d point clouds using hierarchical embedding mask optimiza- tion
Guangming Wang, Xinrui Wu, Zhe Liu, and Hesheng Wang. Pwclo-net: Deep lidar odometry in 3d point clouds using hierarchical embedding mask optimiza- tion. In CVPR, pages 15910–15919, 2021. 2
work page 2021
-
[49]
Hypliloc: To- wards effective lidar pose regression with hyperbolic fusion
Sijie Wang, Qiyu Kang, Rui She, Wei Wang, Kai Zhao, Yang Song, and Wee Peng Tay. Hypliloc: To- wards effective lidar pose regression with hyperbolic fusion. In CVPR, pages 5176–5185, 2023. 3
work page 2023
-
[50]
Distilvpr: Cross-modal knowledge distillation for visual place recognition
Sijie Wang, Rui She, Qiyu Kang, Xingchao Jian, Kai Zhao, Yang Song, and Wee Peng Tay. Distilvpr: Cross-modal knowledge distillation for visual place recognition. In AAAI, pages 10377–10385, 2024. 2
work page 2024
-
[51]
Uavscenes: A multi-modal dataset for uavs
Sijie Wang, Siqi Li, Yawei Zhang, Shangshu Yu, Shenghai Yuan, Rui She, Quanjiang Guo, JinXuan Zheng, Ong Kang Howe, Leonrich Chandra, et al. Uavscenes: A multi-modal dataset for uavs. InCVPR, pages 28946–28958, 2025. 5, 6, 7, 15, 16
work page 2025
-
[52]
Pointloc: Deep pose regressor for lidar point cloud localization
Wei Wang, Bing Wang, Peijun Zhao, Changhao Chen, Ronald Clark, Bo Yang, Andrew Markham, and Niki Trigoni. Pointloc: Deep pose regressor for lidar point cloud localization. IEEE Sensors Journal, 22(1):959– 968, 2021. 3
work page 2021
-
[53]
Point transformer v3: Simpler faster stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler faster stronger. In CVPR, pages 4840–4851, 2024. 4, 8
work page 2024
-
[54]
Zhenyu Wu, Karthik Suresh, Priya Narayanan, Hongyu Xu, Heesung Kwon, and Zhangyang Wang. Delving into robust object detection from unmanned aerial vehicles: A deep nuisance disentanglement ap- proach. In ICCV, pages 1201–1210, 2019. 1
work page 2019
-
[55]
Soe-net: A self-attention and orientation encoding network for point cloud based place recognition
Yan Xia, Yusheng Xu, Shuang Li, Rui Wang, Juan Du, Daniel Cremers, and Uwe Stilla. Soe-net: A self-attention and orientation encoding network for point cloud based place recognition. In CVPR, pages 11348–11357, 2021. 2
work page 2021
-
[56]
Casspr: Cross attention single scan place recognition
Yan Xia, Mariia Gladkova, Rui Wang, Qianyun Li, Uwe Stilla, Joao F Henriques, and Daniel Cremers. Casspr: Cross attention single scan place recognition. In ICCV, pages 8461–8472, 2023. 2, 3
work page 2023
-
[57]
Lisa: Lidar localization with semantic aware- ness
Bochun Yang, Zijun Li, Wen Li, Zhipeng Cai, Chenglu Wen, Yu Zang, Matthias Muller, and Cheng Wang. Lisa: Lidar localization with semantic aware- ness. In CVPR, pages 15271–15280, 2024. 2, 3
work page 2024
-
[58]
One- inlier is first: Towards efficient position encoding for point cloud registration
Fan Yang, Lin Guo, Zhi Chen, and Wenbing Tao. One- inlier is first: Towards efficient position encoding for point cloud registration. In NIPS, pages 6982–6995,
-
[59]
Raloc: Enhancing outdoor lidar local- ization via rotation awareness
Yuyang Yang, Wen Li, Sheng Ao, Qingshan Xu, Shangshu Yu, Yu Guo, Yin Zhou, Siqi Shen, and Cheng Wang. Raloc: Enhancing outdoor lidar local- ization via rotation awareness. In ICCV, pages 3304– 3313, 2025. 2, 3, 4, 7, 16
work page 2025
-
[60]
A survey on global lidar localization: Chal- lenges, advances and open problems
Huan Yin, Xuecheng Xu, Sha Lu, Xieyuanli Chen, Rong Xiong, Shaojie Shen, Cyrill Stachniss, and Yue Wang. A survey on global lidar localization: Chal- lenges, advances and open problems. IJCV, 132(8): 3139–3171, 2024. 2
work page 2024
-
[61]
Stcloc: Deep lidar localization with spatio-temporal constraints
Shangshu Yu, Cheng Wang, Yitai Lin, Chenglu Wen, Ming Cheng, and Guosheng Hu. Stcloc: Deep lidar localization with spatio-temporal constraints. TITS, 24(1):489–500, 2022. 2
work page 2022
-
[62]
Std: Stable triangle descriptor for 3d place recognition
Chongjian Yuan, Jiarong Lin, Zuhao Zou, Xiaoping Hong, and Fu Zhang. Std: Stable triangle descriptor for 3d place recognition. In ICRA, pages 1897–1903,
work page 1903
-
[63]
Dongkun Zhang, Jiaming Liang, Ke Guo, Sha Lu, Qi Wang, Rong Xiong, Zhenwei Miao, and Yue Wang. Carplanner: Consistent auto-regressive trajec- tory planning for large-scale reinforcement learning in autonomous driving. In CVPR, pages 17239–17248,
-
[64]
Increasing gps local- ization accuracy with reinforcement learning
Ethan Zhang and Neda Masoud. Increasing gps local- ization accuracy with reinforcement learning. TITS, 22(5):2615–2626, 2020. 2
work page 2020
-
[65]
Loam: Lidar odometry and mapping in real-time
Ji Zhang, Sanjiv Singh, et al. Loam: Lidar odometry and mapping in real-time. In RSS, pages 1–9. Berke- ley, CA, 2014. 2
work page 2014
-
[66]
Multi-constellation-inspired single-shot global lidar localization
Tongzhou Zhang, Gang Wang, Yu Chen, Hai Zhang, and Jue Hu. Multi-constellation-inspired single-shot global lidar localization. In AAAI, pages 10404– 10412, 2024. 2
work page 2024
-
[67]
Kfnet: Learning temporal camera relocalization using kalman filtering
Lei Zhou, Zixin Luo, Tianwei Shen, Jiahui Zhang, Mingmin Zhen, Yao Yao, Tian Fang, and Long Quan. Kfnet: Learning temporal camera relocalization using kalman filtering. In CVPR, pages 4919–4928, 2020. 3 Beyond Ground: Map-Free LiDAR Relocalization for UA Vs Supplementary Material In this document, we present supplementary material, including the implement...
work page 2020
-
[68]
MAILS Details 6.1. Parameter Settings In this section, we provide detailed parameter settings for MAILS, as illustrated in Fig. 8. In the preprocessing stage, we set the voxel size to 0.3 m and the pooling kernel size of the downsampling layer tok= 2. In the Feature Ini- tialization module, we configure the feature dimension of the Softmax-free LoSW Att m...
-
[69]
content termQK ⊤ depending only onF w i ,
-
[70]
Figure 9.Data collection platform of UA VLoc
positional-bias termQ 2K ⊤ 2 depending only onG i. Figure 9.Data collection platform of UA VLoc. Both remain unchanged underR, and sinceVis linearF w i , the outputf ′ i is invariant. Theorem 1(Local Yaw–Altitude Invariance of MAILS). For the full encoderΦ(P t)(CIPCS + LoSWAtt), and any R∈SO(2)×R, Φ(R◦P t) = Φ(Pt). Proof.Each outputf ′ i is invariant by P...
-
[71]
UA VLoc Details Here, we provide additional details of the UA VLoc dataset, and a summary is presented in Tab. 5. UA VLoc exhibits several distinctive characteristics that make it challenging and representative for UA V relocalization: 1) Multiple flight paths. 2) Irregular flight paths. 3) Altitude variation. 7.1. Data Collection Platform The data collec...
-
[72]
Additional Experiments on UA VLocU Here, we report the results of BEVPlace++ [37], Egonn [25], SGLoc [27], SGLoc+RA [27], LightLoc [29], RALoc
-
[73]
and our MAILS on the UA VLocU dataset. As shown in Tab. 6, the relatively high-altitude flights introduce ad- ditional challenges for UA V relocalization, particularly in the School scene. Most methods—especially the map-free ones—show a clear increase in both position and orientation errors compared with their performance on UA VLocU. De- (a) BEVPlace++ ...
-
[74]
Failure Case In UA VLocU, nearly all methods exhibited localization er- rors significantly higher than in other scenarios. Although our MAILS achieves significantly better performance than other methods, it also exhibits substantial errors on a small subset of test data. We consider the primary reasons for these failure cases to be the following two point...
-
[75]
To address these limitations, in future works, we will proceed along several research directions
Future Work The above analysis of failure cases has revealed the limi- tations that currently exist in our MAILS. To address these limitations, in future works, we will proceed along several research directions. First, we plan to incorporate altitude- and rotation- robust geometric priors into the feature extraction pipeline. While our current design intr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.