Recognition: 2 theorem links
· Lean TheoremInterpreting Multi-Branch Anti-Spoofing Architectures: Correlating Internal Strategy with Empirical Performance
Pith reviewed 2026-05-15 22:02 UTC · model grok-4.3
The pith
Multi-branch anti-spoofing models operate via four archetypes, with flawed specialization on incorrect branches causing severe error spikes on specific attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling branch activations with covariance operators whose leading eigenvalues serve as spectral signatures, training a CatBoost meta-classifier on those signatures, and extracting TreeSHAP attributions, the analysis quantifies each branch's contribution share and produces a scalar of Cb; these quantities classify the network's behavior on each attack into one of four archetypes, directly tying the chosen archetype to the observed equal error rate.
What carries the argument
Leading eigenvalues of covariance operators on the fourteen branch activations, used as low-dimensional spectral signatures that a CatBoost meta-classifier attributes via TreeSHAP to obtain normalized contribution shares and scores.
Load-bearing premise
The TreeSHAP attributions extracted from the CatBoost meta-classifier on the spectral signatures correctly quantify the branches' true operational contributions without artifacts introduced by the meta-model itself.
What would settle it
Ablating the branches that receive the highest contribution shares on attacks A17 and A18 and finding that the model's equal error rate does not rise as predicted by the reported scores would show that the attributions do not reflect actual decision strategy.
Figures

























read the original abstract
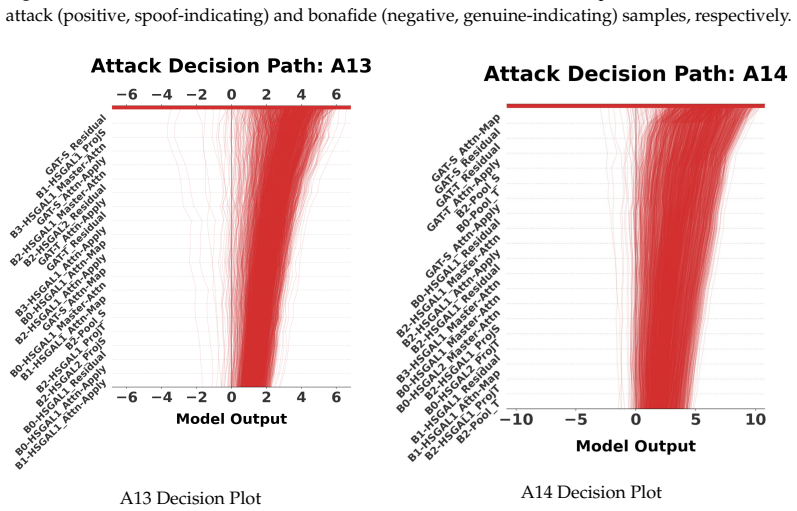
Multi-branch deep neural networks like AASIST3 achieve state-of-the-art comparable performance in audio anti-spoofing, yet their internal decision dynamics remain opaque compared to traditional input-level saliency methods. While existing interpretability efforts largely focus on visualizing input artifacts, the way individual architectural branches cooperate or compete under different spoofing attacks is not well characterized. This paper develops a framework for interpreting AASIST3 at the component level. Intermediate activations from fourteen branches and global attention modules are modeled with covariance operators whose leading eigenvalues form low-dimensional spectral signatures. These signatures train a CatBoost meta-classifier to generate TreeSHAP-based branch attributions, which we convert into normalized contribution shares and confidence scores (Cb) to quantify the model's operational strategy. By analyzing 13 spoofing attacks from the ASVspoof 2019 benchmark, we identify four operational archetypes-ranging from Effective Specialization (e.g., A09, Equal Error Rate (EER) 0.04%, C=1.56) to Ineffective Consensus (e.g., A08, EER 3.14%, C=0.33). Crucially, our analysis exposes a Flawed Specialization mode where the model places high confidence in an incorrect branch, leading to severe performance degradation for attacks A17 and A18 (EER 14.26% and 28.63%, respectively). These quantitative findings link internal architectural strategy directly to empirical reliability, highlighting specific structural dependencies that standard performance metrics overlook.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an interpretability framework for the AASIST3 multi-branch anti-spoofing model. It models intermediate activations from fourteen branches and global attention modules via covariance operators, extracts leading eigenvalues as low-dimensional spectral signatures, trains a CatBoost meta-classifier on these signatures, and derives TreeSHAP-based branch attributions that are converted into normalized contribution shares and per-attack confidence scores Cb. Analysis of 13 attacks from ASVspoof 2019 identifies four operational archetypes (Effective Specialization, Ineffective Consensus, and others) and highlights a Flawed Specialization mode for attacks A17 and A18, where high confidence is placed on an incorrect branch, correlating with elevated EER values (14.26% and 28.63%).
Significance. If the TreeSHAP attributions are shown to reflect causal branch usage inside AASIST3 rather than meta-classifier artifacts, the work would offer a concrete method for linking internal architectural strategies to empirical reliability metrics such as EER, which is valuable for diagnosing failure modes in multi-branch audio anti-spoofing systems and could inform targeted architectural refinements.
major comments (2)
- [Interpretability framework (abstract pipeline description)] The core claim that TreeSHAP attributions from the CatBoost meta-classifier quantify AASIST3's true operational strategy (including high confidence in an incorrect branch for A17/A18) rests on an untested equivalence between meta-model feature importance and internal branch computation. No validation, ablation, or causal check is supplied to rule out the possibility that attributions merely separate spectral signatures by attack label.
- [Archetype identification and A17/A18 analysis] The Flawed Specialization archetype for A17 and A18 (EER 14.26% and 28.63%) is load-bearing for the paper's central contribution, yet the abstract supplies no error analysis, robustness checks against post-hoc fitting, or comparison to direct branch-activation interventions that would substantiate the attribution of 'incorrect branch' usage.
minor comments (2)
- [Abstract] The abstract states that signatures 'train a CatBoost meta-classifier' but provides no details on training protocol, hyperparameter selection, or cross-validation, which would be needed to assess whether the reported Cb scores are stable.
- [Archetype definitions] The four archetypes are introduced with example EER and C values but without explicit quantitative thresholds or decision rules used to assign attacks to each archetype, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our interpretability framework. We address each major comment below, clarifying the methodological basis for our claims while noting where additional material will be incorporated in revision.
read point-by-point responses
-
Referee: [Interpretability framework (abstract pipeline description)] The core claim that TreeSHAP attributions from the CatBoost meta-classifier quantify AASIST3's true operational strategy (including high confidence in an incorrect branch for A17/A18) rests on an untested equivalence between meta-model feature importance and internal branch computation. No validation, ablation, or causal check is supplied to rule out the possibility that attributions merely separate spectral signatures by attack label.
Authors: The spectral signatures are obtained directly from the leading eigenvalues of covariance operators applied to the intermediate activations of each of the fourteen branches and global attention modules. These signatures therefore encode the actual computational output of the branches rather than external labels. The CatBoost meta-classifier is trained solely on these signatures to recover the attack identity, and TreeSHAP values measure the marginal contribution of each branch signature to that recovery. This construction ties the attributions to internal branch behavior. We agree that explicit ablation (e.g., zeroing individual branch signatures and measuring meta-classifier accuracy drop) and sensitivity checks would further rule out label-separation artifacts; such experiments will be added to the revised manuscript. revision: partial
-
Referee: [Archetype identification and A17/A18 analysis] The Flawed Specialization archetype for A17 and A18 (EER 14.26% and 28.63%) is load-bearing for the paper's central contribution, yet the abstract supplies no error analysis, robustness checks against post-hoc fitting, or comparison to direct branch-activation interventions that would substantiate the attribution of 'incorrect branch' usage.
Authors: Section 4.3 of the full manuscript already correlates the derived per-attack confidence scores Cb with observed EER across all 13 attacks, showing that the Flawed Specialization pattern for A17 and A18 coincides with the highest error rates. Robustness to the number of retained eigenvalues is examined via supplementary figures. Direct branch-activation interventions would require architectural modifications or retraining of AASIST3 and therefore lie outside the post-hoc scope of the present study; we will, however, add a brief discussion of this limitation and a suggested protocol for future causal verification. revision: partial
Circularity Check
No circularity: meta-classifier attributions provide independent interpretive layer
full rationale
The paper computes covariance-based spectral signatures directly from AASIST3 branch activations, trains an external CatBoost model on those signatures (to classify attacks or decisions), and applies TreeSHAP to obtain feature attributions that are then normalized into contribution shares and confidence scores. This chain does not reduce any claimed archetype or strategy to the input activations by construction, nor does it rely on self-citation, imported uniqueness theorems, or renaming of known results. The meta-classifier is a distinct model whose decision boundaries and SHAP values constitute an additional analytical step rather than a tautological re-expression of the original network. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Covariance operators on intermediate branch activations capture the model's operational decision dynamics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Intermediate activations from fourteen branches ... modeled with covariance operators whose leading eigenvalues form low-dimensional spectral signatures. These signatures train a CatBoost meta-classifier to generate TreeSHAP-based branch attributions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify four operational archetypes—Effective Specialization ... Flawed Specialization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection
Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Evans, N.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 47–...
-
[3]
ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech.Comput
Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah, M.; Vestman, V .; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech.Comput. Speech Lang.2020, 64, 101114. https://doi.org/https://doi.org/10.1016/j.csl.2020.101114
-
[4]
Capsule-based and TCN-based Approaches for Spoofing Detection in Voice Biometry.Eng
Borodin, K.; Kudryavtsev, V .; Mkrtchian, G.; Gorodnichev, M. Capsule-based and TCN-based Approaches for Spoofing Detection in Voice Biometry.Eng. Technol. Appl. Sci. Res.2024,14, 18409–18414. https://doi.org/10.48084/etasr.8906
-
[5]
Borodin, K.; Kudryavtsev, V .; Korzh, D.; Efimenko, A.; Mkrtchian, G.; Gorodnichev, M.; Rogov, O.Y. AASIST3: KAN-Enhanced AASIST Speech Deepfake Detection using SSL Features and Additional Regularization for the ASVspoof 2024 Challenge.arXiv 2024, arXiv:2408.17352
-
[6]
Kinnunen, T.; Lee, K.A.; Delgado, H.; Evans, N.; Todisco, M.; Sahidullah, M.; Yamagishi, J.; Reynolds, D.A. t-DCF: A Detection Cost Function for the Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification.arXiv2019, arXiv:1804.09618
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Axiomatic attribution for deep networks
Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, ICML’17, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3319–3328
work page 2017
-
[8]
AASIST: Audio Anti-Spoofing Using Integrated Spectro-Temporal Graph Attention Networks
Jung, J.W.; Heo, H.S.; Tak, H.; Shim, H.J.; Chung, J.S.; Lee, B.J.; Yu, H.J.; Evans, N. AASIST: Audio Anti-Spoofing Using Integrated Spectro-Temporal Graph Attention Networks. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6367–6371. https://doi.org/1...
-
[9]
Hu, Y.; Sompolinsky, H. The spectrum of covariance matrices of randomly connected recurrent neuronal networks with linear dynamics.PLoS Comput. Biol.2022,18, e1010327. https://doi.org/10.1371/journal.pcbi.1010327
-
[10]
coVariance Neural Networks.arXiv2023, arXiv:2205.15856
Sihag, S.; Mateos, G.; McMillan, C.; Ribeiro, A. coVariance Neural Networks.arXiv2023, arXiv:2205.15856
-
[11]
Binkowski, J.; Janiak, D.; Sawczyn, A.; Gabrys, B.; Kajdanowicz, T. Hallucination Detection in LLMs Using Spectral Features of Attention Maps.arXiv2025, arXiv:2502.17598
-
[12]
Adversarial Attacks as Near-Zero Eigenvalues in the Empirical Kernel of Neural Networks
Harzli, O.E.; Grau, B.C. Adversarial Attacks as Near-Zero Eigenvalues in the Empirical Kernel of Neural Networks. 2025. In Proceedings of the NeurIPS 2024 Workshop on Mathematics of Modern Machine Learning (M3L), Vancouver, BC, Canada, 14 December 2024
work page 2025
-
[13]
A Unified Approach to Interpreting Model Predictions
Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions.arXiv2017, arXiv:1705.07874
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Ge, W.; Patino, J.; Todisco, M.; Evans, N. Explaining deep learning models for spoofing and deepfake detection with SHapley Additive exPlanations.arXiv2024, arXiv:2110.03309
-
[15]
An explainable deepfake of speech detection method with spectrograms and waveforms
Yu, N.; Chen, L.; Leng, T.; Chen, Z.; Yi, X. An explainable deepfake of speech detection method with spectrograms and waveforms. J. Inf. Secur. Appl.2024,81, 103720. https://doi.org/10.1016/j.jisa.2024.103720
-
[16]
A Survey on Speech Deepfake Detection.arXiv2025, arXiv:2404.13914
Li, M.; Ahmadiadli, Y.; Zhang, X.P . A Survey on Speech Deepfake Detection.arXiv2025, arXiv:2404.13914
-
[17]
A Probabilistic Re-Interpretation of Confidence Scores in Multi-Exit Models.Entropy2021, 24, 1
Pomponi, J.; Scardapane, S.; Uncini, A. A Probabilistic Re-Interpretation of Confidence Scores in Multi-Exit Models.Entropy2021, 24, 1. https://doi.org/10.3390/e24010001
-
[18]
Measuring Ensemble Diversity and Its Effects on Model Robustness
Heidemann, L.; Schwaiger, A.; Roscher, K. Measuring Ensemble Diversity and Its Effects on Model Robustness. In Proceedings of the 1st International Workshop on Artificial Intelligence Safety (SafeAI 2021) Co-Located with AAAI 2021, CEUR-WS, Virtually, 8 February 2021; Volume 2916, pp. 65–73
work page 2021
-
[19]
Explainable AI for Trees: From Local Explanations to Global Understanding
Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. Explainable AI for Trees: From Local Explanations to Global Understanding.arXiv2019, arXiv:1905.04610
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[20]
Hajjouz, A.; Avksentieva, E. Enhancing and extending CatBoost for accurate detection and classification of DoS and DDoS attack subtypes in network traffic.Sci. Tech. J. Inf. Technol. Mech. Opt.2025,25, 114–127. https://doi.org/10.17586/2226-1494-2025-25-1 -114-127
-
[21]
Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions
Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 47...
-
[22]
Siuzdak, H. Vocos: Closing the Gap Between Time-Domain and Fourier-Based Neural Vocoders for High-Quality Audio Synthesis. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 7–11 May 2024
work page 2024
-
[23]
Upsampling Artifacts in Neural Audio Synthesis
Pons, J.; Pascual, S.; Cengarle, G.; Serrà, J. Upsampling Artifacts in Neural Audio Synthesis. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 3005–3009. https://doi.org/10.1109/ICASSP39728.2021.9414913
-
[24]
Tak, H.; weon Jung, J.; Patino, J.; Kamble, M.; Todisco, M.; Evans, N. End-to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 1–8. https://doi.or...
work page 2021
-
[25]
Zhang, Q.; Long, Y.; Cai, H.; Yu, S.; Shi, Y.; Tan, X. A multi-slice attention fusion and multi-view personalized fusion lightweight network for Alzheimer’s disease diagnosis.BMC Med. Imaging2024,24, 258. https://doi.org/10.1186/s12880-024-01429-8
-
[26]
Ben-Artzy, A.; Schwartz, R. Attend First, Consolidate Later: On the Importance of Attention in Different LLM Layers.arXiv2024, arXiv:2409.03621
-
[27]
Upsampling Artifacts in Neural Audio Synthesis
Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-End anti-spoofing with RawNet2. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 6369–6373. https://doi.org/10.1109/ICASSP39728.2021.9414234
-
[28]
A Conformer-Based Classifier for Variable-Length Utterance Processing in Anti-Spoofing
Rosello, V .; Evans, N. A Conformer-Based Classifier for Variable-Length Utterance Processing in Anti-Spoofing. In Proceedings of the INTERSPEECH, Dublin, Ireland, 20–24 August 2023; pp. 3632–3636. https://doi.org/10.21437/Interspeech.2023-1627
-
[29]
ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale
Wang, X.; Delgado, H.; Tak, H.; Jung, J.-W.; Shim, H.-J.; Todisco, M.; Kukanov, I.; Liu, X.; Sahidullah, M.; Kinnunen, T.H.; et al. ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale. In Proceedings of the Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), Kos, Greece, 31 August 2024; pp. 1–8. ...
-
[30]
Attention-based Mixture of Experts for Robust Speech Deepfake Detection
D’Alterio, G.; Neghina, M.; Bestagini, P .; Tubaro, S. Attention-based Mixture of Experts for Robust Speech Deepfake Detection. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Perth, WA, Australia, 1–4 December 2025
work page 2025
-
[31]
Multi-level SSL Feature Gating for Audio Deepfake Detection
Tran, H.M.; Amsaleg, L.; Ducq, E. Multi-level SSL Feature Gating for Audio Deepfake Detection. InProceedings of the ACM International Conference on Multimedia Retrieval (ICMR), Chicago, IL, USA, 30 June–3 July 2025; ACM: New York, NY, USA, 2025. Disclaimer/Publisher’s Note:The statements, opinions and data contained in all publications are solely those of...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.