TempoNet: Slack-Quantized Transformer-Guided Reinforcement Scheduler for Adaptive Deadline-Centric Real-Time Dispatchs
Pith reviewed 2026-05-15 21:08 UTC · model grok-4.3
The pith
TempoNet uses a slack-quantized Transformer to improve deadline fulfillment in real-time multiprocessor scheduling over analytic and neural methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
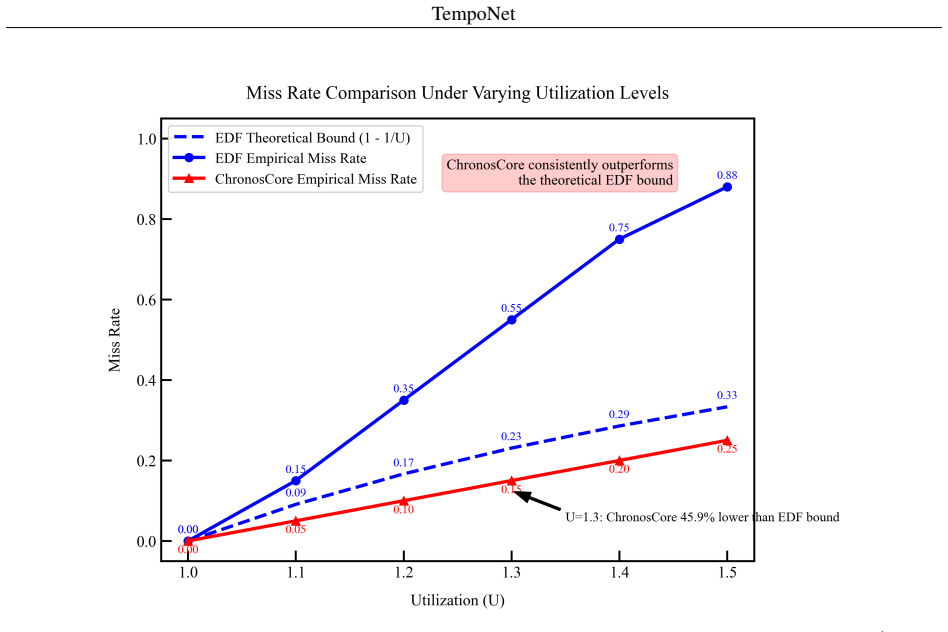
TempoNet pairs a permutation-invariant Transformer with a deep Q-approximation for real-time scheduling. The Urgency Tokenizer discretizes temporal slack into learnable embeddings that stabilize value learning and capture deadline proximity. A latency-aware sparse attention stack with blockwise top-k selection and locality-sensitive chunking supports global reasoning over unordered task sets at near-linear scaling and sub-millisecond inference. A multicore mapping layer converts the Q-scores into processor assignments using masked-greedy selection or differentiable matching. On industrial mixed-criticality traces and large multiprocessor settings this yields consistent gains in deadline-fulf
What carries the argument
The Urgency Tokenizer that discretizes temporal slack into learnable embeddings to stabilize value learning and capture deadline proximity within the Transformer-guided Q-approximation.
If this is right
- Consistent gains in deadline fulfillment appear on industrial mixed-criticality traces and large multiprocessor settings.
- Optimization stability improves compared with prior neural baselines.
- Inference scales near-linearly and stays under one millisecond for large task sets.
- Behavioral-cloning pretraining delivers sample-efficiency gains while preserving inference speed.
- The same pipeline works with an actor-critic variant without modification.
Where Pith is reading between the lines
- The attention patterns could be inspected at runtime to surface which tasks most influence current assignments.
- The approach might transfer to other permutation-invariant resource problems such as dynamic packet scheduling or cloud job placement.
- Hybrid systems could combine this learned scheduler with classical analytic fallbacks for safety-critical edges.
- Pretraining on expert traces suggests the method could learn from existing real-time OS heuristics without full retraining.
Load-bearing premise
Discretizing temporal slack into learnable embeddings will stabilize value learning and reliably capture deadline proximity across varied workload mixes and processor counts.
What would settle it
If new evaluations on industrial traces with higher slack variability or larger processor counts show no improvement or worse deadline fulfillment than analytic schedulers and neural baselines, the performance claim would be falsified.
Figures











read the original abstract
Real-time schedulers must reason about tight deadlines under strict compute budgets. We present TempoNet, a reinforcement learning scheduler that pairs a permutation-invariant Transformer with a deep Q-approximation. An Urgency Tokenizer discretizes temporal slack into learnable embeddings, stabilizing value learning and capturing deadline proximity. A latency-aware sparse attention stack with blockwise top-k selection and locality-sensitive chunking enables global reasoning over unordered task sets with near-linear scaling and sub-millisecond inference. A multicore mapping layer converts contextualized Q-scores into processor assignments through masked-greedy selection or differentiable matching. Extensive evaluations on industrial mixed-criticality traces and large multiprocessor settings show consistent gains in deadline fulfillment over analytic schedulers and neural baselines, together with improved optimization stability. Diagnostics include sensitivity analyses for slack quantization, attention-driven policy interpretation, hardware-in-the-loop and kernel micro-benchmarks, and robustness under stress with simple runtime mitigations; we also report sample-efficiency benefits from behavioral-cloning pretraining and compatibility with an actor-critic variant without altering the inference pipeline. These results establish a practical framework for Transformer-based decision making in high-throughput real-time scheduling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TempoNet, a reinforcement learning scheduler that integrates a permutation-invariant Transformer with deep Q-approximation for real-time task dispatch. It introduces an Urgency Tokenizer to discretize temporal slack into learnable embeddings, a latency-aware sparse attention mechanism with blockwise top-k selection for efficient global reasoning over unordered task sets, and a multicore mapping layer using masked-greedy or differentiable assignment. The central claim is that this pipeline delivers consistent gains in deadline fulfillment on industrial mixed-criticality traces and large multiprocessor settings relative to analytic schedulers and neural baselines, while improving optimization stability, with sub-millisecond inference and supporting diagnostics on slack quantization sensitivity, attention interpretability, hardware-in-the-loop benchmarks, and behavioral-cloning pretraining.
Significance. If the empirical results hold under the reported conditions, the work supplies a practical, scalable framework for incorporating Transformer-based decision making into high-throughput real-time systems. The explicit sensitivity analyses, hardware-in-the-loop evaluation, and pretraining compatibility strengthen the contribution beyond a single benchmark comparison.
major comments (1)
- [§4] §4 (Evaluation): The central claim of 'consistent gains' and 'improved optimization stability' rests on the full pipeline (Transformer + Urgency Tokenizer + sparse attention). The manuscript reports sensitivity analyses for slack quantization, but it is unclear whether the chosen quantization levels were fixed before seeing test-set performance or selected to maximize the reported deadline-fulfillment metric; an explicit statement of the selection protocol and a hold-out validation set would be required to rule out post-hoc fitting.
minor comments (3)
- [Title] Title: 'Dispatchs' is a typographical error and should read 'Dispatches'.
- [Abstract] Abstract: The sentence describing the multicore mapping layer is long and could be split for clarity; the parenthetical list of diagnostics also mixes methods and results.
- [§3.4] Notation: The distinction between 'masked-greedy selection' and 'differentiable matching' in the mapping layer should be given explicit equations or pseudocode in §3.4 to avoid ambiguity when readers attempt to re-implement the inference pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the practical value of TempoNet for Transformer-based real-time scheduling. We address the single major comment below and will incorporate the requested clarifications.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The central claim of 'consistent gains' and 'improved optimization stability' rests on the full pipeline (Transformer + Urgency Tokenizer + sparse attention). The manuscript reports sensitivity analyses for slack quantization, but it is unclear whether the chosen quantization levels were fixed before seeing test-set performance or selected to maximize the reported deadline-fulfillment metric; an explicit statement of the selection protocol and a hold-out validation set would be required to rule out post-hoc fitting.
Authors: We agree that an explicit description of the quantization-level selection protocol is necessary to substantiate the central claims. The levels were fixed in advance using domain knowledge from real-time systems literature on slack distributions together with cross-validation performed on a dedicated hold-out subset of the industrial traces; this subset was never used for final test-set evaluation or metric maximization. To eliminate any ambiguity we will revise §4 to state the protocol in full, including the hold-out validation procedure and the rationale for the chosen discretization. This change will directly address the concern about post-hoc fitting while preserving the reported results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The manuscript presents TempoNet as an empirical RL scheduler combining a permutation-invariant Transformer, Urgency Tokenizer for slack discretization, sparse attention, and multicore mapping. All load-bearing claims rest on external evaluations against industrial traces, analytic baselines, and neural comparators, with explicit sensitivity analyses, hardware-in-the-loop benchmarks, and behavioral-cloning diagnostics reported. No equations, self-definitional reductions, fitted-input predictions, or self-citation chains that collapse the central result to its own inputs are present in the provided text. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Urgency Tokenizer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Urgency Tokenizer discretizes temporal slack into learnable embeddings... ˜si(t) = clip(⌊si(t)/Δ⌋,0,Q−1), xi(t)=E[˜si(t)]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
permutation-invariant Transformer... latency-aware sparse attention... multicore mapping
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
An empirical analysis of scheduling techniques for real-time cloud-based data processing
Linh TX Phan, Zhuoyao Zhang, Qi Zheng, Boon Thau Loo, and Insup Lee. An empirical analysis of scheduling techniques for real-time cloud-based data processing. In2011 IEEE International Conference on Service-Oriented Computing and Applications (SOCA), pages 1–8, 2011
work page 2011
-
[2]
Edf scheduling of real-time tasks on multiple cores: Adaptive partitioning vs
Luca Abeni and Tommaso Cucinotta. Edf scheduling of real-time tasks on multiple cores: Adaptive partitioning vs. global scheduling.ACM SIGAPP Applied Computing Review, 20(2):5–18, 2020
work page 2020
-
[3]
Jinming Wang, Shaobo Li, Xingxing Zhang, Fengbin Wu, and Cankun Xie. Deep reinforcement learning task scheduling method based on server real-time performance.PeerJ Computer Science, 10:e2120, 2024
work page 2024
-
[4]
Long Cheng, Archana Kalapgar, Amogh Jain, Yue Wang, Yongtai Qin, Yuancheng Li, and Cong Liu. Cost-aware real-time job scheduling for hybrid cloud using deep reinforcement learning.Neural Computing and Applications, 34(21):18579–18593, 2022
work page 2022
-
[5]
Ming Zhang, Yang Lu, Youxi Hu, Nasser Amaitik, and Yuchun Xu. Dynamic scheduling method for job-shop manufacturing systems by deep reinforcement learning with proximal policy optimization.Sustainability, 14(9): 5177, 2022
work page 2022
-
[6]
Kun Lei, Peng Guo, Yi Wang, Jian Zhang, Xiangyin Meng, and Linmao Qian. Large-scale dynamic scheduling for flexible job-shop with random arrivals of new jobs by hierarchical reinforcement learning.IEEE Transactions on Industrial Informatics, 20(1):1007–1018, 2023
work page 2023
-
[7]
Peisong Li, Ziren Xiao, Xinheng Wang, Kaizhu Huang, Yi Huang, and Honghao Gao. Eptask: Deep reinforcement learning based energy-efficient and priority-aware task scheduling for dynamic vehicular edge computing.IEEE Transactions on Intelligent Vehicles, 9(1):1830–1846, 2023
work page 2023
-
[8]
Jesse van Remmerden, Zaharah Bukhsh, and Yingqian Zhang. Offline reinforcement learning for learning to dispatch for job shop scheduling.Machine Learning, 114(8):191, 2025
work page 2025
-
[9]
Zahra Jalali Khalil Abadi, Najme Mansouri, and Mohammad Masoud Javidi. Deep reinforcement learning-based scheduling in distributed systems: a critical review.Knowledge and Information Systems, 66(10):5709–5782, 2024. 13 TempoNet
work page 2024
-
[10]
Shashank Swarup, Elhadi M Shakshuki, and Ansar Yasar. Task scheduling in cloud using deep reinforcement learning.Procedia Computer Science, 184:42–51, 2021
work page 2021
-
[11]
Funing Li, Sebastian Lang, Yuan Tian, Bingyuan Hong, Benjamin Rolf, Ruben Noortwyck, Robert Schulz, and Tobias Reggelin. A transformer-based deep reinforcement learning approach for dynamic parallel machine scheduling problem with family setups.Journal of Intelligent Manufacturing, pages 1–34, 2024
work page 2024
-
[12]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, pages 6000–6010, 2017
work page 2017
-
[13]
Kangjie Cao, Ting Zhang, and Jueqiao Huang. Advanced hybrid lstm-transformer architecture for real-time multi-task prediction in engineering systems.Scientific Reports, 14(1):4890, 2024
work page 2024
-
[14]
Developing real-time streaming transformer transducer for speech recognition on large-scale dataset
Xie Chen, Yu Wu, Zhenghao Wang, Shujie Liu, and Jinyu Li. Developing real-time streaming transformer transducer for speech recognition on large-scale dataset. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5904–5908, 2021
work page 2021
-
[15]
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
work page 2021
-
[16]
Shengchao Hu, Li Shen, Ya Zhang, Yixin Chen, and Dacheng Tao. On transforming reinforcement learning with transformers: The development trajectory.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46 (12):8580–8599, 2024
work page 2024
-
[17]
Seunghyun Moon, Mao Li, Gregory K Chen, Phil C Knag, Ram K Krishnarmurthy, and Mingoo Seok. T-rex: Hardware–software co-optimized transformer accelerator with reduced external memory access and enhanced hardware utilization.IEEE Journal of Solid-State Circuits, 2025
work page 2025
-
[18]
Guangxiang Zhao, Junyang Lin, Zhiyuan Zhang, Xuancheng Ren, Qi Su, and Xu Sun. Explicit sparse transformer: Concentrated attention through explicit selection.arXiv preprint arXiv:1912.11637, 2019
-
[19]
Sparser is faster and less is more: Efficient sparse attention for long-range transformers
Chao Lou, Zixia Jia, Zilong Zheng, and Kewei Tu. Sparser is faster and less is more: Efficient sparse attention for long-range transformers.arXiv preprint arXiv:2406.16747, 2024
-
[20]
Rl-ptq: Rl-based mixed precision quantization for hybrid vision transformers
Eunji Kwon, Minxuan Zhou, Weihong Xu, Tajana Rosing, and Seokhyeong Kang. Rl-ptq: Rl-based mixed precision quantization for hybrid vision transformers. InProceedings of the 61st ACM/IEEE Design Automation Conference, pages 1–6, 2024
work page 2024
-
[21]
Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Efficient content-based sparse attention with routing transformers.Transactions of the Association for Computational Linguistics, 9:53–68, 2021
work page 2021
-
[22]
PSA: Progressive sparse attention for long-context inference.arXiv preprint arXiv:2503.00392, 2025
Qihui Zhou, Peiqi Yin, Pengfei Zuo, and James Cheng. Progressive sparse attention: Algorithm and system co-design for efficient attention in llm serving.arXiv preprint arXiv:2503.00392, 2025
-
[23]
Xiaoyang Zhao and Chuan Wu. Large-scale machine learning cluster scheduling via multi-agent graph reinforce- ment learning.IEEE Transactions on Network and Service Management, 19(4):4962–4974, 2021
work page 2021
-
[24]
Dras: Deep reinforcement learning for cluster scheduling in high performance computing
Yuping Fan, Boyang Li, Dustin Favorite, Naunidh Singh, Taylor Childers, Paul Rich, William Allcock, Michael E Papka, and Zhiling Lan. Dras: Deep reinforcement learning for cluster scheduling in high performance computing. IEEE Transactions on Parallel and Distributed Systems, 33(12):4903–4917, 2022
work page 2022
-
[25]
Graph assisted offline-online deep reinforcement learning for dynamic workflow scheduling
Yifan Yang, Gang Chen, Hui Ma, Cong Zhang, Zhiguang Cao, and Mengjie Zhang. Graph assisted offline-online deep reinforcement learning for dynamic workflow scheduling. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[26]
Tianrui Chen, Xinruo Zhang, Minglei You, Gan Zheng, and Sangarapillai Lambotharan. A gnn-based supervised learning framework for resource allocation in wireless iot networks.IEEE Internet of Things Journal, 9(3): 1712–1724, 2021
work page 2021
-
[27]
Xu Gao, Hang Dong, Lianji Zhang, Yibo Wang, Xianliang Yang, and Zhenyu Li. Self-attention mechanisms in hpc job scheduling: A novel framework combining gated transformers and enhanced ppo.Applied Sciences, 15 (16):8928, 2025. 14 TempoNet
work page 2025
-
[28]
Mtst: A multi-task scheduling transformer accelerator for edge computing
Zongcheng Yue, Dongwei Yan, Ran Wu, Longyu Ma, and Chiu-Wing Sham. Mtst: A multi-task scheduling transformer accelerator for edge computing. In2024 IEEE 13th Global Conference on Consumer Electronics (GCCE), pages 1394–1395, 2024
work page 2024
-
[29]
Ahan Gupta, Yueming Yuan, Devansh Jain, Yuhao Ge, David Aponte, Yanqi Zhou, and Charith Mendis. Splat: A framework for optimised gpu code-generation for sparse regular attention.Proceedings of the ACM on Programming Languages, 9(OOPSLA1):1632–1660, 2025
work page 2025
-
[30]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Asynchronous methods for deep reinforcement learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pages 1928–1936, 2016
work page 1928
-
[32]
Rainbow: Combining improvements in deep reinforcement learning
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improvements in deep reinforcement learning. Thirty-second AAAI conference on artificial intelligence, 2018
work page 2018
-
[33]
Liwei Dong, Ni Li, Guanghong Gong, and Xin Lin. Offline reinforcement learning with constrained hybrid action implicit representation towards wargaming decision-making.Tsinghua Science and Technology, 29(5):1422–1440, 2024
work page 2024
-
[34]
Mohammed Sharafath Abdul Hameed and Andreas Schwung. Graph neural networks-based scheduler for production planning problems using reinforcement learning.Journal of Manufacturing Systems, 69:91–102, 2023
work page 2023
-
[35]
RouteFormer: A Transformer-Based Routing Framework for Autonomous Vehicles
Yazan Youssef, Paulo Ricardo Marques de Araujo, Aboelmagd Noureldin, and Sidney Givigi. Tratss: Transformer- based task scheduling system for autonomous vehicles.arXiv preprint arXiv:2504.05407, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Nemilidinea Anantharami Reddy and BV Gokulnath. Design of an improved method for task scheduling using proximal policy optimization and graph neural networks.IEEE Access, 2024
work page 2024
-
[37]
Research on td3-based offloading strategies for complex tasks in mec systems
Shuai Wang, Bo Yu, Ning Wang, and Wei Wang. Research on td3-based offloading strategies for complex tasks in mec systems. In2024 10th International Conference on Computer and Communications (ICCC), pages 194–201. IEEE, 2024
work page 2024
-
[38]
Lixiang Zhao, Han Zhu, Min Zhang, Jiafu Tang, and Yu Wang. Large-scale dynamic surgical scheduling under uncertainty by hierarchical reinforcement learning.International Journal of Production Research, pages 1–32, 2024
work page 2024
-
[39]
Muhammad Waseem, Kshitij Bhatta, Chen Li, and Qing Chang. Pretrained llms as real-time controllers for robot operated serial production line.arXiv preprint arXiv:2503.03889, 2025
-
[40]
Heyang Huang, Cunchen Hu, Jiaqi Zhu, Ziyuan Gao, Liangliang Xu, Yizhou Shan, Yungang Bao, Sun Ninghui, Tianwei Zhang, and Sa Wang. Ddit: Dynamic resource allocation for diffusion transformer model serving.arXiv preprint arXiv:2506.13497, 2025
-
[41]
Lixiang Zhang, Chen Yang, Yan Yan, and Yaoguang Hu. Distributed real-time scheduling in cloud manufacturing by deep reinforcement learning.IEEE Transactions on Industrial Informatics, 18(12):8999–9007, 2022
work page 2022
-
[42]
Wei Chen, Zequn Zhang, Dunbing Tang, Changchun Liu, Yong Gui, Qingwei Nie, and Zhen Zhao. Probing an lstm-ppo-based reinforcement learning algorithm to solve dynamic job shop scheduling problem.Computers & Industrial Engineering, 197:110633, 2024
work page 2024
-
[43]
Athena Abdi and Armin Salimi-Badr. Enf-s: An evolutionary-neuro-fuzzy multi-objective task scheduler for heterogeneous multi-core processors.IEEE Transactions on Sustainable Computing, 8(3):479–491, 2023
work page 2023
-
[44]
Multi-core real-time scheduling algorithm based on particle swarm optimization algorithm
Xingzhi Liu, Yan Zeng, Wenli Chen, Yu Su, and Rui Wang. Multi-core real-time scheduling algorithm based on particle swarm optimization algorithm. In2021 International Conference on Signal Processing and Machine Learning (CONF-SPML), pages 300–305. IEEE, 2021
work page 2021
-
[45]
An optimal real-time scheduling algorithm for multiprocessors
Hyeonjoong Cho, Binoy Ravindran, and E Douglas Jensen. An optimal real-time scheduling algorithm for multiprocessors. InRTSS, pages 101–110, 2006. 15 TempoNet
work page 2006
-
[46]
Debanjan Konar, Kalpana Sharma, Varun Sarogi, and Siddhartha Bhattacharyya. A multi-objective quantum- inspired genetic algorithm (mo-qiga) for real-time tasks scheduling in multiprocessor environment.Procedia Computer Science, 131:591–599, 2018
work page 2018
-
[47]
Chung Laung Liu and James W Layland. Scheduling algorithms for multiprogramming in a hard-real-time environment.Journal of the ACM (JACM), 20(1):46–61, 1973
work page 1973
-
[48]
Scheduling for overload in real-time systems.IEEE Transactions on computers, 46(9):1034–1039, 2002
Sanjoy K Baruah and Jayant R Haritsa. Scheduling for overload in real-time systems.IEEE Transactions on computers, 46(9):1034–1039, 2002
work page 2002
-
[49]
Tb-stc: Transposable block-wise n: M structured sparse tensor core
Jun Liu, Shulin Zeng, Junbo Zhao, Li Ding, Zeyu Wang, Jinhao Li, Zhenhua Zhu, Xuefei Ning, Chen Zhang, Yu Wang, et al. Tb-stc: Transposable block-wise n: M structured sparse tensor core. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 949–962. IEEE, 2025
work page 2025
-
[50]
Wenxin Li. Performance analysis of modified srpt in multiple-processor multitask scheduling.ACM SIGMETRICS Performance Evaluation Review, 50(4):47–49, 2023
work page 2023
-
[51]
Yihong Li, Xiaoxi Zhang, Tianyu Zeng, Jingpu Duan, Chuan Wu, Di Wu, and Xu Chen. Task placement and resource allocation for edge machine learning: A gnn-based multi-agent reinforcement learning paradigm.IEEE Transactions on Parallel and Distributed Systems, 34(12):3073–3089, 2023. A Theoretical Analysis of the Expressivity Gap A.1 Definitions and Policy F...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.