Unified Unsupervised and Sparsely-Supervised 3D Object Detection by Semantic Pseudo-Labeling and Prototype Learning
Pith reviewed 2026-05-15 19:25 UTC · model grok-4.3
The pith
SPL unifies unsupervised and sparsely-supervised 3D object detection by turning fused semantic pseudo-labels into stable prototypes for feature learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
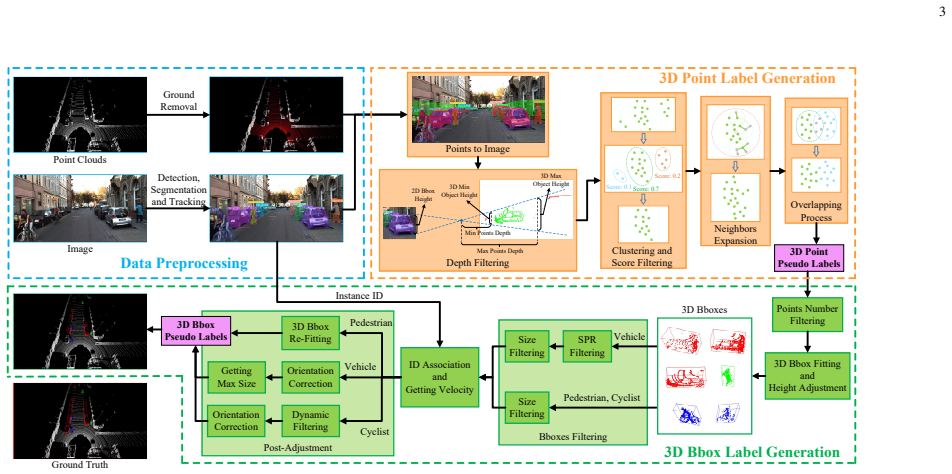
SPL generates high-quality pseudo-labels by integrating image semantics, point cloud geometry, and temporal cues, producing 3D bounding boxes for dense objects and 3D point labels for sparse ones. These serve as probabilistic priors inside a multi-stage prototype learning strategy that uses memory-based initialization and momentum-based prototype updating to stabilize feature mining from both labeled and unlabeled data.
What carries the argument
Multi-stage prototype learning that treats semantic pseudo-labels as probabilistic priors and updates prototypes through memory initialization and momentum to mine stable features.
If this is right
- Produces working 3D detectors from sensor data alone without any manual bounding-box labels.
- Extends naturally to sparse supervision by anchoring the same prototype process on the few available labels.
- Reduces error propagation by keeping pseudo-labels as soft priors rather than hard targets.
- Delivers higher detection accuracy than prior unsupervised or semi-supervised methods on KITTI and nuScenes.
Where Pith is reading between the lines
- The same fusion-plus-prototype pattern could be tested on 3D semantic segmentation where point-wise labels are even harder to obtain.
- Performance may degrade in single-frame or static scenes where temporal consistency is unavailable.
- The memory-bank mechanism suggests a route to continual adaptation when new unlabeled data arrives after initial training.
Load-bearing premise
Fusing image semantics, point cloud geometry, and temporal cues produces sufficiently accurate probabilistic pseudo-label priors that the prototype updates can refine features without spreading errors from the initial noisy labels.
What would settle it
Remove the temporal cue integration or the momentum prototype updates, retrain on KITTI in the unsupervised setting, and check whether average precision falls below existing state-of-the-art unsupervised baselines.
Figures







read the original abstract
3D object detection is essential for autonomous driving and robotic perception, yet its reliance on large-scale manually annotated data limits scalability and adaptability. To reduce annotation dependency, unsupervised and sparsely-supervised paradigms have emerged. However, they face intertwined challenges: low-quality pseudo-labels, unstable feature mining, and a lack of a unified training framework. This paper proposes SPL, a unified training framework for both unsupervised and sparsely-supervised 3D object detection via \underline{S}emantic \underline{P}seudo-labeling and prototype \underline{L}earning. SPL first generates high-quality pseudo-labels by integrating image semantics, point cloud geometry, and temporal cues, producing both 3D bounding boxes for dense objects and 3D point labels for sparse ones. These pseudo-labels are not used directly but as probabilistic priors within a novel, multi-stage prototype learning strategy. This strategy stabilizes feature representation learning through memory-based initialization and momentum-based prototype updating, effectively mining features from both labeled and unlabeled data. Extensive experiments on KITTI and nuScenes datasets demonstrate that SPL significantly outperforms state-of-the-art methods in both settings. Our work provides a robust and generalizable solution for learning 3D object detectors with minimal or no manual annotations. Our code is available at https://github.com/TossherO/SPL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce SPL, a unified training framework for unsupervised and sparsely-supervised 3D object detection. It generates probabilistic pseudo-labels by integrating image semantics, point cloud geometry, and temporal cues for both dense 3D bounding boxes and sparse 3D point labels. These priors are then used in a multi-stage prototype learning strategy involving memory-based initialization and momentum-based prototype updating to mine features from labeled and unlabeled data. Experiments on KITTI and nuScenes datasets show that SPL significantly outperforms state-of-the-art methods in both settings.
Significance. If the results hold, this provides a robust solution for learning 3D detectors with minimal annotations, which is significant for scalable autonomous driving perception. Strengths include the unified framework, the use of probabilistic priors rather than hard labels, the prototype mechanism for stable feature mining, and the public release of code for reproducibility on public benchmarks.
major comments (2)
- [§4.1] §4.1 (Prototype Updating): the momentum coefficient is listed among free parameters; the manuscript must clarify whether it is held fixed across all experiments or tuned per dataset, as this directly affects the stability claim for the multi-stage learning.
- [Table 2] Table 2 (nuScenes unsupervised row): the reported gains over prior methods are presented without standard deviations or number of runs; this undermines the strength of the outperformance claim given the known variability in pseudo-label quality.
minor comments (2)
- [Abstract] Abstract: the notation for SPL is underlined for emphasis; this is unnecessary in the final version and should be removed for standard formatting.
- [§5] §5 (Experiments): ensure all ablation studies explicitly state the contribution of each cue (semantic, geometric, temporal) with quantitative deltas rather than qualitative description.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. We address the major comments point by point below.
read point-by-point responses
-
Referee: [§4.1] §4.1 (Prototype Updating): the momentum coefficient is listed among free parameters; the manuscript must clarify whether it is held fixed across all experiments or tuned per dataset, as this directly affects the stability claim for the multi-stage learning.
Authors: We thank the referee for this clarification request. The momentum coefficient is held fixed at the same value across all experiments on both KITTI and nuScenes to ensure consistent and stable prototype updating in the multi-stage learning process. We will revise §4.1 to explicitly state the fixed value used and confirm that it is not tuned per dataset. revision: yes
-
Referee: [Table 2] Table 2 (nuScenes unsupervised row): the reported gains over prior methods are presented without standard deviations or number of runs; this undermines the strength of the outperformance claim given the known variability in pseudo-label quality.
Authors: We agree that reporting run information strengthens the claims. We will update Table 2 with a footnote indicating that results are from single runs (due to the high computational cost of nuScenes training) and add a short discussion in the experimental section on the consistency of gains across datasets despite pseudo-label variability. revision: partial
Circularity Check
No significant circularity; method is empirically grounded
full rationale
The SPL framework is presented as an empirical pipeline that generates probabilistic pseudo-label priors from image semantics, point-cloud geometry and temporal cues, then feeds them into a multi-stage prototype-learning procedure that uses memory initialization and momentum updates to mine features from labeled and unlabeled data. No equations or first-principles derivations appear that reduce by construction to fitted parameters or to self-citations; the central claim of outperformance is supported solely by direct experimental comparisons against prior methods on the public KITTI and nuScenes benchmarks. The pseudo-labels are explicitly described as non-hard priors, and the prototype mechanism is designed to operate across both labeled and unlabeled splits, so the argument does not collapse into a self-definitional loop or a fitted-input-called-prediction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- momentum coefficient for prototype updating
axioms (1)
- domain assumption Integration of image semantics, point cloud geometry, and temporal cues yields high-quality probabilistic pseudo-labels suitable as priors
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-stage prototype learning strategy... memory-based initialization and momentum-based prototype updating... pseudo heatmap priors
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrating image semantics, point cloud geometry, and temporal cues... 3D Bbox pseudo labels and 3D point pseudo labels
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
V oxel r- cnn: Towards high performance voxel-based 3d object detection,
J. Deng, S. Shi, P. Li, W. Zhou, Y . Zhang, and H. Li, “V oxel r- cnn: Towards high performance voxel-based 3d object detection,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 2, 2021, pp. 1201–1209
work page 2021
-
[2]
Pv-rcnn: Point-voxel feature set abstraction for 3d object detection,
S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “Pv-rcnn: Point-voxel feature set abstraction for 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 529–10 538
work page 2020
-
[3]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,”arXiv preprint arXiv:2205.13542, 2022
-
[4]
Cross modal transformer: Towards fast and robust 3d object detection,
J. Yan, Y . Liu, J. Sun, F. Jia, S. Li, T. Wang, and X. Zhang, “Cross modal transformer: Towards fast and robust 3d object detection,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 18 268–18 278
work page 2023
-
[5]
Are we ready for autonomous driving? the kitti vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 3354–3361
work page 2012
-
[6]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631. 10
work page 2020
-
[7]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2446–2454
work page 2020
-
[8]
Towards unsupervised object detection from lidar point clouds,
L. Zhang, A. J. Yang, Y . Xiong, S. Casas, B. Yang, M. Ren, and R. Urtasun, “Towards unsupervised object detection from lidar point clouds,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9317–9328
work page 2023
-
[9]
Commonsense prototype for outdoor unsupervised 3d object detection,
H. Wu, S. Zhao, X. Huang, C. Wen, X. Li, and C. Wang, “Commonsense prototype for outdoor unsupervised 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024, pp. 14 968–14 977
work page 2024
-
[10]
Learning to detect mobile objects from lidar scans without labels,
Y . You, K. Luo, C. P. Phoo, W.-L. Chao, W. Sun, B. Hariharan, M. Campbell, and K. Q. Weinberger, “Learning to detect mobile objects from lidar scans without labels,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1130–1140
work page 2022
-
[11]
Liso: Lidar-only self- supervised 3d object detection,
S. A. Baur, F. Moosmann, and A. Geiger, “Liso: Lidar-only self- supervised 3d object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 253–270
work page 2024
-
[12]
Motal: Unsupervised 3d object detection by modality and task-specific knowledge transfer,
H. Wu, H. Lin, X. Guo, X. Li, M. Wang, C. Wang, and C. Wen, “Motal: Unsupervised 3d object detection by modality and task-specific knowledge transfer,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 6284–6293
work page 2025
-
[13]
Fgr: Frustum-aware geometric reasoning for weakly supervised 3d vehicle detection,
Y . Wei, S. Su, J. Lu, and J. Zhou, “Fgr: Frustum-aware geometric reasoning for weakly supervised 3d vehicle detection,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 4348–4354
work page 2021
-
[14]
Annofreeod: Detecting all classes at low frame rates without human annotations,
B. Sun, Y . Liu, H. He, Y . Tian, and F.-Y . Wang, “Annofreeod: Detecting all classes at low frame rates without human annotations,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5315–5325
work page 2025
-
[15]
Enhancing pseudo-boxes via data- level lidar-camera fusion for unsupervised 3d object detection,
M. Ji, J. Yang, and S. Zhang, “Enhancing pseudo-boxes via data- level lidar-camera fusion for unsupervised 3d object detection,” in Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 896–904
work page 2025
-
[16]
Approaching outside: scaling unsupervised 3d object detection from 2d scene,
R. Zhang, H. Zhang, H. Yu, and Z. Zheng, “Approaching outside: scaling unsupervised 3d object detection from 2d scene,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 249–266
work page 2024
-
[17]
Union: Unsupervised 3d ob- ject detection using object appearance-based pseudo-classes,
T. Lentsch, H. Caesar, and D. M. Gavrila, “Union: Unsupervised 3d ob- ject detection using object appearance-based pseudo-classes,”Advances in Neural Information Processing Systems, vol. 37, pp. 22 028–22 046, 2024
work page 2024
-
[18]
Q. Xia, J. Deng, C. Wen, H. Wu, S. Shi, X. Li, and C. Wang, “Coin: Contrastive instance feature mining for outdoor 3d object detection with very limited annotations,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 6254–6263
work page 2023
-
[19]
Learning class prototypes for unified sparse-supervised 3d object detection,
Y . Zhu, L. Hui, H. Yang, J. Qian, J. Xie, and J. Yang, “Learning class prototypes for unified sparse-supervised 3d object detection,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 9911–9920
work page 2025
-
[20]
V oxelnet: End-to-end learning for point cloud based 3d object detection,
Y . Zhou and O. Tuzel, “V oxelnet: End-to-end learning for point cloud based 3d object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490–4499
work page 2018
-
[21]
Second: Sparsely embedded convolutional detection,
Y . Yan, Y . Mao, and B. Li, “Second: Sparsely embedded convolutional detection,”Sensors, vol. 18, no. 10, p. 3337, 2018
work page 2018
-
[22]
Center-based 3d object detection and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793
work page 2021
-
[23]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705
work page 2019
-
[24]
Smoke: Single-stage monocular 3d object detection via keypoint estimation,
Z. Liu, Z. Wu, and R. T ´oth, “Smoke: Single-stage monocular 3d object detection via keypoint estimation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 996–997
work page 2020
-
[25]
Categorical depth distribution network for monocular 3d object detection,
C. Reading, A. Harakeh, J. Chae, and S. L. Waslander, “Categorical depth distribution network for monocular 3d object detection,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8555–8564
work page 2021
-
[26]
Petr: Position embedding trans- formation for multi-view 3d object detection,
Y . Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding trans- formation for multi-view 3d object detection,” inEuropean conference on computer vision. Springer, 2022, pp. 531–548
work page 2022
-
[27]
Mvx-net: Multimodal voxelnet for 3d object detection,
V . A. Sindagi, Y . Zhou, and O. Tuzel, “Mvx-net: Multimodal voxelnet for 3d object detection,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7276–7282
work page 2019
-
[28]
X. Zhang, K. Bi, S. Chan, S. Lu, and X. Zhou, “Synet: A synergistic network for 3d object detection through geometric-semantic-based multi- interaction fusion,”IEEE Transactions on Multimedia, 2025
work page 2025
-
[29]
Detection, classification and tracking of moving objects in a 3d environment,
A. Azim and O. Aycard, “Detection, classification and tracking of moving objects in a 3d environment,” in2012 IEEE Intelligent Vehicles Symposium. IEEE, 2012, pp. 802–807
work page 2012
-
[30]
Robust moving objects detection in lidar data exploiting visual cues,
G. Postica, A. Romanoni, and M. Matteucci, “Robust moving objects detection in lidar data exploiting visual cues,” in2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 1093–1098
work page 2016
-
[31]
Dynamic multi-lidar based multiple object detection and tracking,
M. Sualeh and G.-W. Kim, “Dynamic multi-lidar based multiple object detection and tracking,”Sensors, vol. 19, no. 6, p. 1474, 2019
work page 2019
-
[32]
Ss3d: Sparsely- supervised 3d object detection from point cloud,
C. Liu, C. Gao, F. Liu, J. Liu, D. Meng, and X. Gao, “Ss3d: Sparsely- supervised 3d object detection from point cloud,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8428–8437
work page 2022
-
[33]
Q. Xia, W. Ye, H. Wu, S. Zhao, L. Xing, X. Huang, J. Deng, X. Li, C. Wen, and C. Wang, “Hinted: Hard instance enhanced detector with mixed-density feature fusion for sparsely-supervised 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 321–15 330
work page 2024
-
[34]
Sp3d: Boosting sparsely-supervised 3d object detection via accurate cross-modal semantic prompts,
S. Zhao, Q. Xia, X. Guo, P. Zou, M. Zheng, H. Wu, C. Wen, and C. Wang, “Sp3d: Boosting sparsely-supervised 3d object detection via accurate cross-modal semantic prompts,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 29 374– 29 384
work page 2025
-
[35]
Hardness-aware scene syn- thesis for semi-supervised 3d object detection,
S. Zeng, W. Zheng, J. Lu, and H. Yan, “Hardness-aware scene syn- thesis for semi-supervised 3d object detection,”IEEE Transactions on Multimedia, vol. 26, pp. 9644–9656, 2024
work page 2024
-
[36]
Weakly supervised object detection with class prototypical network,
H. Li, Y . Li, Y . Cao, Y . Han, Y . Jin, and Y . Wei, “Weakly supervised object detection with class prototypical network,”IEEE Transactions on Multimedia, vol. 25, pp. 1868–1878, 2022
work page 2022
-
[37]
Break- ing immutable: Information-coupled prototype elaboration for few-shot object detection,
X. Lu, W. Diao, Y . Mao, J. Li, P. Wang, X. Sun, and K. Fu, “Break- ing immutable: Information-coupled prototype elaboration for few-shot object detection,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 2, 2023, pp. 1844–1852
work page 2023
-
[38]
Query- guided prototype evolution network for few-shot segmentation,
R. Cong, H. Xiong, J. Chen, W. Zhang, Q. Huang, and Y . Zhao, “Query- guided prototype evolution network for few-shot segmentation,”IEEE Transactions on Multimedia, vol. 26, pp. 6501–6512, 2024
work page 2024
-
[39]
Prototypical votenet for few-shot 3d point cloud object detection,
S. Zhao and X. Qi, “Prototypical votenet for few-shot 3d point cloud object detection,”Advances in neural information processing systems, vol. 35, pp. 13 838–13 851, 2022
work page 2022
-
[40]
Z. Li, J. Guo, T. Cao, L. Bingbing, and W. Yang, “Gpa-3d: Geometry- aware prototype alignment for unsupervised domain adaptive 3d object detection from point clouds,” inProceedings of the IEEE/CVF interna- tional conference on computer vision, 2023, pp. 6394–6403
work page 2023
-
[41]
Cl3d: Unsupervised domain adaptation for cross-lidar 3d detection,
X. Peng, X. Zhu, and Y . Ma, “Cl3d: Unsupervised domain adaptation for cross-lidar 3d detection,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 2, 2023, pp. 2047–2055
work page 2023
-
[42]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738
work page 2020
-
[43]
S. Lee, H. Lim, and H. Myung, “Patchwork++: Fast and robust ground segmentation solving partial under-segmentation using 3d point cloud,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 13 276–13 283
work page 2022
-
[44]
YOLOv12: Attention-Centric Real-Time Object Detectors
Y . Tian, Q. Ye, and D. Doermann, “Yolov12: Attention-centric real-time object detectors,”arXiv preprint arXiv:2502.12524, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Available from: https://arxiv.org/ abs/2206.14651
N. Aharon, R. Orfaig, and B.-Z. Bobrovsky, “Bot-sort: Robust associa- tions multi-pedestrian tracking,”arXiv preprint arXiv:2206.14651, 2022
-
[46]
A density-based algorithm for discovering clusters in large spatial databases with noise,
M. Ester, H.-P. Kriegel, J. Sander, X. Xuet al., “A density-based algorithm for discovering clusters in large spatial databases with noise,” inkdd, vol. 96, no. 34, 1996, pp. 226–231
work page 1996
-
[47]
L. E. Peterson, “K-nearest neighbor,”Scholarpedia, vol. 4, no. 2, p. 1883, 2009
work page 2009
-
[48]
Efficient l-shape fitting for vehicle detection using laser scanners,
X. Zhang, W. Xu, C. Dong, and J. M. Dolan, “Efficient l-shape fitting for vehicle detection using laser scanners,” in2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017, pp. 54–59
work page 2017
-
[49]
V oxelnext: Fully sparse voxelnet for 3d object detection and tracking,
Y . Chen, J. Liu, X. Zhang, X. Qi, and J. Jia, “V oxelnext: Fully sparse voxelnet for 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 21 674–21 683. 11 APPENDIX A. Implementation Details In this section, we provide comprehensive implementation details of SPL, including pseud...
work page 2023
-
[50]
Pseudo-Label Generation:The detailed parameters of pseudo-label generation are summarized in Table VIII. These settings are selected according to the characteristics of KITTI and nuScenes to balance pseudo-label precision and recall. Concretely, the mask-dilation and depth-range constraints are used to improve point association quality in crowded scenes, ...
-
[51]
Network and Training:Following the baseline detector settings, we report only the additional parameters introduced by SPL and its multi-stage prototype learning strategy. The re- ported settings are directly tied to the core method components in sections III-B and III-C: prototype construction and update, pseudo-label-guided feature mining, contrastive ob...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.