UCAN: Unified Convolutional Attention Network for Expansive Receptive Fields in Lightweight Super-Resolution
Pith reviewed 2026-05-15 12:27 UTC · model grok-4.3
The pith
UCAN unifies window attention, Hedgehog Attention, and distilled large kernels with cross-layer sharing to expand receptive fields efficiently in lightweight super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UCAN establishes that a lightweight network can expand the effective receptive field by unifying convolution and attention through window-based spatial attention combined with a Hedgehog Attention mechanism for local and long-range modeling, a distillation-based large-kernel module that preserves high-frequency structure without heavy computation, and cross-layer parameter sharing to reduce overall complexity, resulting in higher PSNR on standard super-resolution benchmarks than recent lightweight models at lower MAC counts.
What carries the argument
The Hedgehog Attention mechanism paired with window-based spatial attention, a distillation-based large-kernel module, and cross-layer parameter sharing, which together model local texture and long-range dependencies while keeping computation low.
If this is right
- UCAN-L reaches 31.63 dB PSNR on Manga109 at 4x scale using only 48.4G MACs, exceeding recent lightweight models.
- UCAN attains 27.79 dB on BSDS100 while outperforming methods that employ significantly larger models.
- The design maintains a superior trade-off among accuracy, efficiency, and scalability for image restoration.
- Cross-layer sharing and the unified attention-convolution approach keep the model suitable for resource-constrained devices.
Where Pith is reading between the lines
- The same unification pattern could be tested on related low-level tasks such as denoising or deblurring where receptive-field size directly affects detail recovery.
- Parameter sharing across layers might reduce model size in other attention-heavy vision networks beyond super-resolution.
- If the efficiency holds on real-world noisy or compressed images, the network could support on-device upscaling in mobile applications.
- Scaling the approach to higher upscaling factors like 8x would test whether the receptive-field gains remain effective without additional cost.
Load-bearing premise
That the Hedgehog Attention, distillation-based large kernel, and cross-layer sharing can be combined to enlarge receptive fields without introducing accuracy or efficiency losses that full ablation tests would reveal.
What would settle it
Full ablation experiments that remove or isolate each added component and show either lower PSNR than reported or higher MACs than claimed on Manga109 and BSDS100, or failure to beat larger-model baselines on additional test sets.
Figures

















read the original abstract
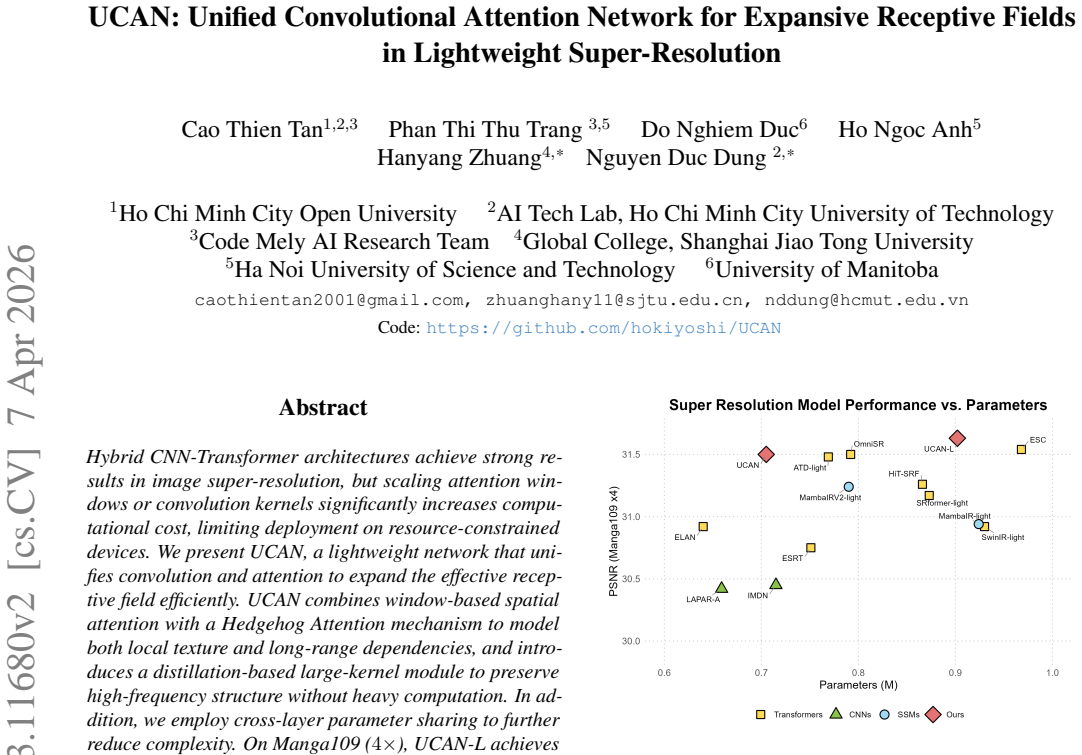
Hybrid CNN-Transformer architectures achieve strong results in image super-resolution, but scaling attention windows or convolution kernels significantly increases computational cost, limiting deployment on resource-constrained devices. We present UCAN, a lightweight network that unifies convolution and attention to expand the effective receptive field efficiently. UCAN combines window-based spatial attention with a Hedgehog Attention mechanism to model both local texture and long-range dependencies, and introduces a distillation-based large-kernel module to preserve high-frequency structure without heavy computation. In addition, we employ cross-layer parameter sharing to further reduce complexity. On Manga109 ($4\times$), UCAN-L achieves 31.63 dB PSNR with only 48.4G MACs, surpassing recent lightweight models. On BSDS100, UCAN attains 27.79 dB, outperforming methods with significantly larger models. Extensive experiments show that UCAN achieves a superior trade-off between accuracy, efficiency, and scalability, making it well-suited for practical high-resolution image restoration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UCAN, a lightweight hybrid CNN-Transformer architecture for image super-resolution that unifies window-based spatial attention with Hedgehog Attention to capture local textures and long-range dependencies, incorporates a distillation-based large-kernel module to preserve high-frequency details, and applies cross-layer parameter sharing to reduce complexity. It reports concrete performance gains, including UCAN-L reaching 31.63 dB PSNR on Manga109 (4×) at 48.4G MACs and 27.79 dB on BSDS100, outperforming recent lightweight models while maintaining low computational cost.
Significance. If the central claims hold under rigorous verification, the work would advance efficient super-resolution by demonstrating a practical unification of attention mechanisms that expands receptive fields without proportional increases in parameters or MACs, offering a scalable design suitable for resource-constrained devices. The reported accuracy-efficiency trade-offs on standard benchmarks represent a potentially useful empirical contribution to lightweight SR literature.
major comments (2)
- [§4] §4 (Experiments and Ablations): The ablation studies report incremental additions of Hedgehog Attention, the distillation module, and cross-layer sharing but lack full factorial designs that isolate each component while strictly holding total parameters and MACs fixed. This is load-bearing for the central claim, as the headline PSNR/MAC numbers (e.g., 31.63 dB at 48.4G on Manga109) could arise from a single dominant module, training dynamics, or unaccounted compute rather than the unified architecture.
- [Results tables] Results tables (e.g., Table 1 or equivalent benchmark tables): Reported PSNR values such as 31.63 dB and 27.79 dB lack error bars, standard deviations from multiple runs, or details on dataset splits and training seeds, making it impossible to assess whether the improvements over baselines are statistically reliable or reproducible.
minor comments (2)
- [Abstract and §3] The abstract and §3 would benefit from a brief explicit statement of the total parameter count for UCAN-L alongside the MAC figure to allow direct comparison with cited baselines.
- [Figures] Figure captions for architecture diagrams should clarify whether the Hedgehog Attention and distillation modules operate in parallel or sequentially within each block.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, indicating planned revisions where feasible while being transparent about limitations.
read point-by-point responses
-
Referee: [§4] §4 (Experiments and Ablations): The ablation studies report incremental additions of Hedgehog Attention, the distillation module, and cross-layer sharing but lack full factorial designs that isolate each component while strictly holding total parameters and MACs fixed. This is load-bearing for the central claim, as the headline PSNR/MAC numbers (e.g., 31.63 dB at 48.4G on Manga109) could arise from a single dominant module, training dynamics, or unaccounted compute rather than the unified architecture.
Authors: We acknowledge that a full factorial ablation with strictly fixed parameters and MACs would offer stronger isolation of each module. However, the components in UCAN are intentionally interdependent within the unified CNN-Transformer design, and enforcing identical compute budgets across all 2^3 combinations would require substantial redesigns that alter the architecture's core efficiency claims. Our sequential ablations demonstrate incremental PSNR gains at each step while preserving the low-MAC target, and the final model outperforms strong baselines. In revision we will expand §4 with additional justification for the sequential approach, a discussion of module interactions, and a note on the prohibitive cost of exhaustive factorial experiments under fixed compute. This constitutes a partial revision. revision: partial
-
Referee: [Results tables] Results tables (e.g., Table 1 or equivalent benchmark tables): Reported PSNR values such as 31.63 dB and 27.79 dB lack error bars, standard deviations from multiple runs, or details on dataset splits and training seeds, making it impossible to assess whether the improvements over baselines are statistically reliable or reproducible.
Authors: We agree that reproducibility details strengthen the results. We will revise the manuscript to explicitly report the training seeds, dataset splits, and full experimental protocol used for all benchmarks. However, computing error bars and standard deviations would require multiple independent training runs for every model and dataset, which exceeds our available computational resources. We note that the reported gains are consistent across five standard benchmarks and multiple scales, aligning with practices in the lightweight SR literature. A limitation statement will be added to the text. revision: partial
- Providing numerical error bars or standard deviations from multiple independent runs, as this cannot be supplied without new multi-seed experiments beyond current resources.
Circularity Check
No circularity; empirical architecture claims rest on benchmarks without self-referential derivations
full rationale
The paper introduces UCAN as a hybrid CNN-Transformer architecture for lightweight super-resolution, describing components such as window-based spatial attention, Hedgehog Attention, a distillation-based large-kernel module, and cross-layer parameter sharing. Performance claims (e.g., 31.63 dB PSNR on Manga109 4× at 48.4G MACs) are presented solely as outcomes of experimental evaluation on standard datasets. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The derivation chain is absent; results are independent empirical measurements rather than reductions to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UCAN combines window-based spatial attention with a Hedgehog Attention mechanism... distillation-based large-kernel module... cross-layer parameter sharing
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Hedgehog Feature Map... ϕH(X) = [exp(W⊤X+b1),...,exp(−W⊤X−bm)]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yuang Ai, Huaibo Huang, Tao Wu, Qihang Fan, and Ran He. Breaking complexity barriers: High-resolution image restoration with rank enhanced linear attention.arXiv preprint arXiv:2505.16157, 2025. 2
-
[2]
Low-complexity single-image super-resolution based on nonnegative neighbor embedding
Marco Bevilacqua, Aline Roumy, Christine Guillemot, and Marie Line Alberi-Morel. Low-complexity single-image super-resolution based on nonnegative neighbor embedding
-
[3]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022. 8
work page 2022
-
[4]
Learning a deep convolutional network for image super- resolution
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super- resolution. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Pro- ceedings, Part IV 13, pages 184–199. Springer, 2014. 2
work page 2014
-
[5]
Compression artifacts reduction by a deep convolu- tional network
Chao Dong, Yubin Deng, Chen Change Loy, and Xiaoou Tang. Compression artifacts reduction by a deep convolu- tional network. InProceedings of the IEEE international conference on computer vision, pages 576–584, 2015. 2
work page 2015
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Interpreting super-resolution net- works with local attribution maps
Jinjin Gu and Chao Dong. Interpreting super-resolution net- works with local attribution maps. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 9199–9208, 2021. 7
work page 2021
-
[8]
Mambairv2: Attentive state space restoration.arXiv preprint arXiv:2411.15269, 2024
Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, and Yawei Li. Mambairv2: Attentive state space restoration.arXiv preprint arXiv:2411.15269,
-
[9]
Mambairv2: Attentive state space restoration, 2024
Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, and Yawei Li. Mambairv2: Attentive state space restoration, 2024. 7
work page 2024
-
[10]
Mambair: A simple baseline for image restoration with state-space model
Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia. Mambair: A simple baseline for image restoration with state-space model. InEuropean Conference on Computer Vision, pages 222–241. Springer, 2025. 6, 7, 3
work page 2025
-
[11]
Fourier position embedding: Enhancing attention’s periodic extension for length generalization,
Ermo Hua, Che Jiang, Xingtai Lv, Kaiyan Zhang, Youbang Sun, Yuchen Fan, Xuekai Zhu, Biqing Qi, Ning Ding, and Bowen Zhou. Fourier position embedding: Enhancing at- tention’s periodic extension for length generalization.arXiv preprint arXiv:2412.17739, 2024. 5
-
[12]
Single image super-resolution from transformed self-exemplars
Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5197–5206, 2015. 6
work page 2015
-
[13]
Fast and accurate single image super-resolution via information distillation net- work
Zheng Hui, Xiumei Wang, and Xinbo Gao. Fast and accurate single image super-resolution via information distillation net- work. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 723–731, 2018. 2
work page 2018
-
[14]
Deeply- recursive convolutional network for image super-resolution
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Deeply- recursive convolutional network for image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1637–1645, 2016. 2
work page 2016
-
[15]
Cansu Korkmaz and A Murat Tekalp. Training transformer models by wavelet losses improves quantitative and visual performance in single image super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6661–6670, 2024. 6
work page 2024
-
[16]
Kin Wai Lau, Lai-Man Po, and Yasar Abbas Ur Rehman. Large separable kernel attention: Rethinking the large kernel attention design in cnn.Expert Systems with Applications, 236:121352, 2024. 3
work page 2024
-
[17]
Dongheon Lee, Seokju Yun, and Youngmin Ro. Emulat- ing self-attention with convolution for efficient image super- resolution.arXiv preprint arXiv:2503.06671, 2025. 3, 5
-
[18]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 1833– 1844, 2021. 5, 6, 4
work page 2021
-
[19]
Jie Liang, Hui Zeng, and Lei Zhang. Details or artifacts: A locally discriminative learning approach to realistic im- age super-resolution. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5657–5666, 2022. 6
work page 2022
-
[20]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. InProceedings of the IEEE confer- ence on computer vision and pattern recognition workshops, pages 136–144, 2017. 2
work page 2017
-
[21]
Residual feature aggregation network for image super- resolution
Jie Liu, Wenjie Zhang, Yuting Tang, Jie Tang, and Gangshan Wu. Residual feature aggregation network for image super- resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2359–2368,
-
[22]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 2
work page 2021
-
[23]
Progressive focused transformer for single image super- resolution
Wei Long, Xingyu Zhou, Leheng Zhang, and Shuhang Gu. Progressive focused transformer for single image super- resolution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2279–2288, 2025. 4
work page 2025
-
[24]
Transformer for single image super-resolution
Zhisheng Lu, Juncheng Li, Hong Liu, Chaoyan Huang, Linlin Zhang, and Tieyong Zeng. Transformer for single image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 457–466,
-
[25]
David Martin, Charless Fowlkes, Doron Tal, and Jitendra Malik. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. InProceedings eighth IEEE international conference on computer vision. ICCV 2001, pages 416–423. IEEE, 2001. 6
work page 2001
-
[26]
Yusuke Matsui, Kota Ito, Yuji Aramaki, Azuma Fujimoto, Toru Ogawa, Toshihiko Yamasaki, and Kiyoharu Aizawa. Sketch-based manga retrieval using manga109 dataset.Mul- timedia tools and applications, 76(20):21811–21838, 2017. 6
work page 2017
-
[27]
Karam Park, Jae Woong Soh, and Nam Ik Cho. Effi- cient attention-sharing information distillation transformer for lightweight single image super-resolution. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 6416–6424, 2025. 2, 3, 4, 6, 7
work page 2025
-
[28]
Vi- sion transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 2
work page 2021
-
[29]
Wenzhe Shi, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1874–1883, 2016. 3
work page 2016
-
[30]
Vmambair: Visual state space model for image restoration.arXiv preprint arXiv:2403.11423, 2024
Yuan Shi, Bin Xia, Xiaoyu Jin, Xing Wang, Tianyu Zhao, Xin Xia, Xuefeng Xiao, and Wenming Yang. Vmambair: Visual state space model for image restoration.arXiv preprint arXiv:2403.11423, 2024. 2
-
[31]
Long Sun, Jinshan Pan, and Jinhui Tang. Shufflemixer: An efficient convnet for image super-resolution.Advances in Neural Information Processing Systems, 35:17314–17326,
-
[32]
Rethinking the inception ar- chitecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception ar- chitecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016. 3
work page 2016
-
[33]
Image super- resolution via deep recursive residual network
Ying Tai, Jian Yang, and Xiaoming Liu. Image super- resolution via deep recursive residual network. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3147–3155, 2017. 2
work page 2017
-
[34]
Image processing gnn: Breaking rigidity in super-resolution
Yuchuan Tian, Hanting Chen, Chao Xu, and Yunhe Wang. Image processing gnn: Breaking rigidity in super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24117, 2024. 4
work page 2024
-
[35]
Omni aggregation networks for lightweight image super-resolution
Hang Wang, Xuanhong Chen, Bingbing Ni, Yutian Liu, and Jinfan Liu. Omni aggregation networks for lightweight image super-resolution. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 22378–22387, 2023. 2, 6, 7
work page 2023
-
[36]
Gang Wu, Junjun Jiang, Junpeng Jiang, and Xianming Liu. Transforming image super-resolution: a convformer-based efficient approach.IEEE Transactions on Image Processing,
-
[37]
Large kernel distillation network for efficient single image super-resolution
Chengxing Xie, Xiaoming Zhang, Linze Li, Haiteng Meng, Tianlin Zhang, Tianrui Li, and Xiaole Zhao. Large kernel distillation network for efficient single image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1283–1292, 2023. 2
work page 2023
-
[38]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5728–5739,
-
[39]
On single image scale-up using sparse-representations
Roman Zeyde, Michael Elad, and Matan Protter. On single image scale-up using sparse-representations. InInternational conference on curves and surfaces, pages 711–730. Springer,
-
[40]
Leheng Zhang, Yawei Li, Xingyu Zhou, Xiaorui Zhao, and Shuhang Gu. Transcending the limit of local window: Ad- vanced super-resolution transformer with adaptive token dic- tionary. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2856–2865,
-
[41]
Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher Ré. The hedgehog & the porcupine: Expres- sive linear attentions with softmax mimicry.arXiv preprint arXiv:2402.04347, 2024. 3
-
[42]
Efficient long-range attention network for image super-resolution
Xindong Zhang, Hui Zeng, Shi Guo, and Lei Zhang. Efficient long-range attention network for image super-resolution. In European conference on computer vision, pages 649–667. Springer, 2022. 2, 6, 4
work page 2022
-
[43]
Hit-sr: Hierar- chical transformer for efficient image super-resolution
Xiang Zhang, Yulun Zhang, and Fisher Yu. Hit-sr: Hierar- chical transformer for efficient image super-resolution. In European Conference on Computer Vision, pages 483–500. Springer, 2024. 6, 7
work page 2024
-
[44]
Image super-resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. InProceedings of the European conference on computer vision (ECCV), pages 286– 301, 2018. 2, 6, 7
work page 2018
-
[45]
Residual dense network for image super-resolution
Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2472–2481, 2018. 2, 6, 7
work page 2018
-
[46]
Srformer: Permuted self-attention for single image super-resolution
Yupeng Zhou, Zhen Li, Chun-Le Guo, Song Bai, Ming-Ming Cheng, and Qibin Hou. Srformer: Permuted self-attention for single image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12780–12791, 2023. 6, 7 UCAN: Unified Convolutional Attention Network for Expansive Receptive Fields in Lightweight Super-Resoluti...
work page 2023
-
[47]
FLK-S (X) =S d(S(X, k core), kcore, d) (12)
Standard Configuration (FLK-S):This is a two-stage stack, used for smaller receptive fields. FLK-S (X) =S d(S(X, k core), kcore, d) (12)
-
[48]
Large Configuration (FLK-L):To achieve maximum receptive fields, this configuration extends the standard block into a three-stage stack. The first two stages are identical to the Standard Configuration, after which a third dilated separable depthwise convolution block using kextra is appended. FLK-L (X) =S d(Sd(S(X, k core), kcore, d), kextra, d) (13) The...
-
[49]
The base S(·, kcore) block (specifically f 1×kcore dw ) estab- lishes an ERFin =k core
-
[50]
The second stage, Sd(·, kcore, d), (specifically f 1×kcore,d dw ) adds(k core −1)d. The total ERF is therefore: ERFS =k core + (kcore −1)d (16) Large Configuration (FLK-L).This configuration stacks S(·, kcore)andS d(·, kextra, d)
-
[51]
The base S(·, kcore) block establishes an ERFin =k core
-
[52]
The second stage,S d(·, kcore, d), adds(k core −1)d
-
[53]
The third stage,S d(·, kextra, d), adds(k extra −1)d. The total ERF is therefore: ERFL =k core + (kcore −1)d+ (k extra −1)d (17) This derivation confirms the formulas used to generate the configurations in Table 4. A.3. Feature Fusion and Final Output Finally, the outputs from the three branches are fused. The local and large-kernel spatial features are c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.