CLaRE-ty Amid Chaos: Quantifying Representational Entanglement to Predict Ripple Effects in LLM Editing
Pith reviewed 2026-05-15 12:47 UTC · model grok-4.3
The pith
CLaRE measures fact entanglement in LLMs with forward activations from one intermediate layer to predict editing ripple effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
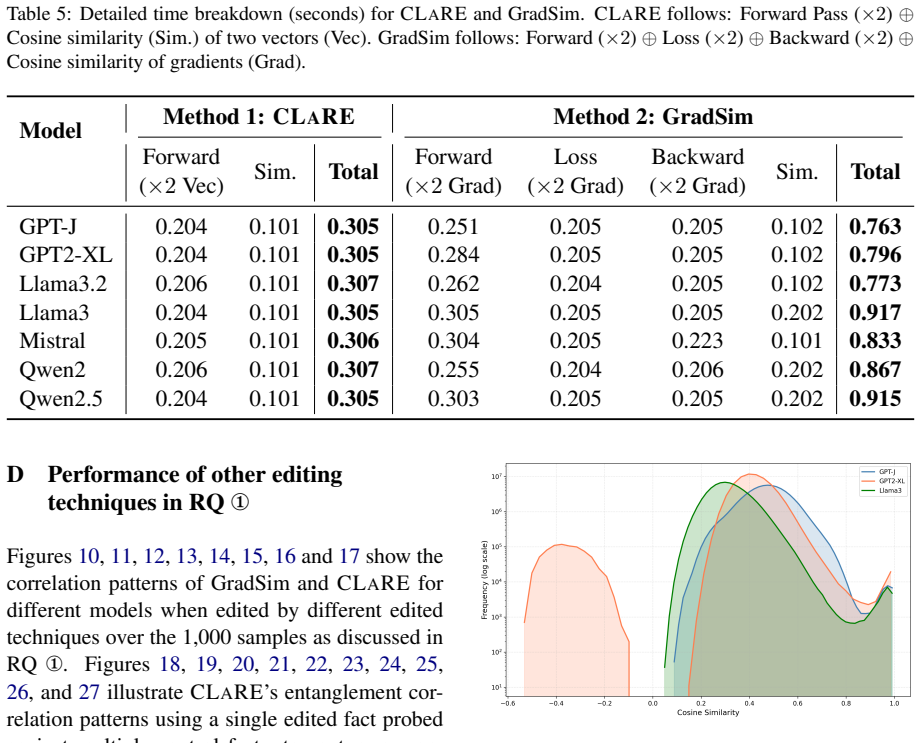
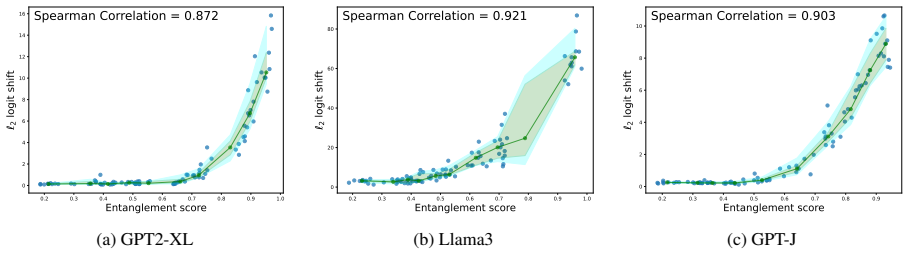
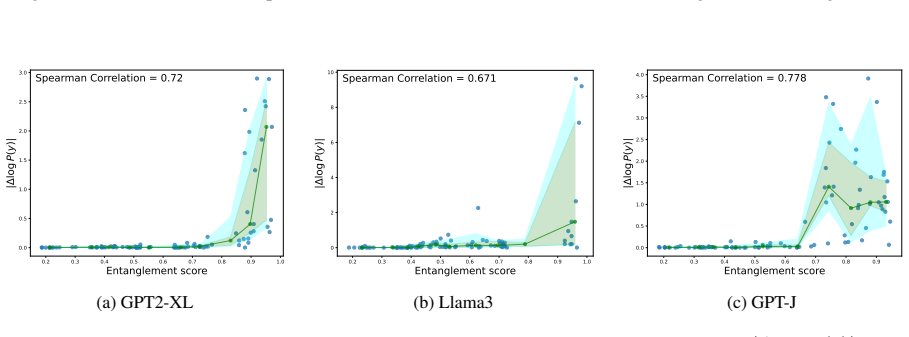
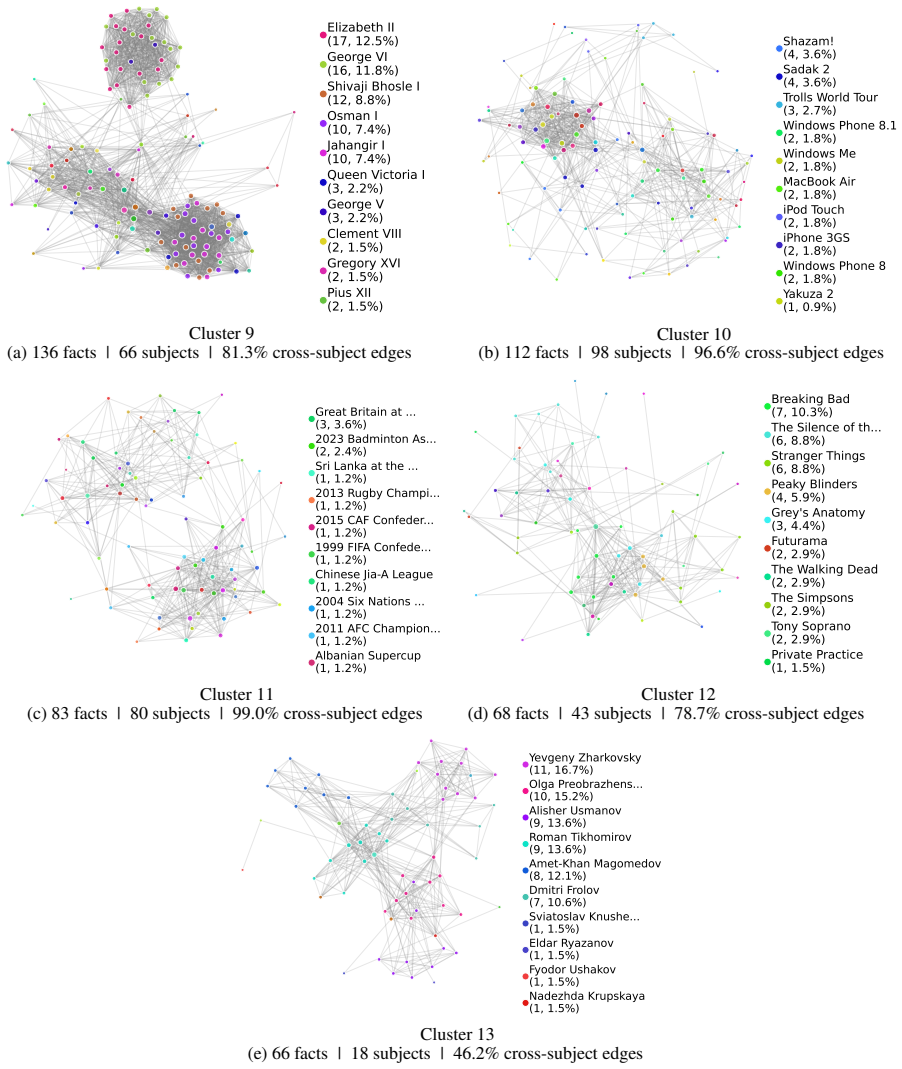
CLaRE quantifies representational entanglement between facts by measuring similarity of their forward activations in one chosen intermediate layer. These entanglement scores correlate 62.2 percent better with actual ripple effects than gradient-based baselines, while the computation runs 2.74 times faster and uses 2.85 times less peak GPU memory. The resulting graphs support better preservation sets, audit trails, red-teaming, and post-edit checks without storing full fact representations.
What carries the argument
CLaRE entanglement score, computed from cosine similarity of forward activations at a single intermediate layer for pairs of facts.
If this is right
- Editing procedures can select preservation sets directly from the entanglement graph to limit unintended changes.
- Post-edit evaluation scales by querying the graph instead of exhaustive behavioral tests on every related fact.
- Red-teaming can focus on high-entanglement facts to surface ripple effects with fewer trials.
- Audit records of model updates become feasible by tracing which facts share high entanglement scores.
Where Pith is reading between the lines
- Forward-pass entanglement graphs may transfer to other model interventions such as targeted fine-tuning or selective pruning.
- If the single-layer approximation generalizes, it could expose common organizational patterns in how transformers store knowledge across different architectures.
- Dynamic editing systems could use the graphs to update clusters of entangled facts in one coordinated step rather than sequentially.
Load-bearing premise
Entanglement measured via forward activations from a single intermediate layer accurately captures how edits propagate through the full hidden space and produce behavioral ripple effects.
What would settle it
Perform a set of edits on high-CLaRE versus low-CLaRE fact pairs and check whether the measured behavioral changes after editing match the predicted ordering and magnitude of ripple effects.
Figures

































read the original abstract
The static knowledge representations of large language models (LLMs) inevitably become outdated or incorrect over time. While model-editing techniques offer a promising solution by modifying a model's factual associations, they often produce unpredictable ripple effects, which are unintended behavioral changes that propagate even to the hidden space. In this work, we introduce CLaRE, a lightweight representation-level technique to identify where these ripple effects may occur. Unlike prior gradient-based methods, CLaRE quantifies entanglement between facts using forward activations from a single intermediate layer, avoiding costly backward passes. To enable systematic study, we prepare and analyse a corpus of 11,427 facts drawn from three existing datasets. Using CLaRE, we compute large-scale entanglement graphs of this corpus for multiple models, capturing how local edits propagate through representational space. These graphs enable stronger preservation sets for model editing, audit trails, efficient red-teaming, and scalable post-edit evaluation. In comparison to baselines, CLaRE achieves an average of 62.2% improvement in Spearman correlation with ripple effects while being $2.74\times$ faster, and using $2.85\times$ less peak GPU memory. Besides, CLaRE requires only a fraction of the storage needed by the baselines to compute and preserve fact representations. Our entanglement graphs and corpus are available at https://github.com/manitbaser/CLaRE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLaRE, a lightweight method that quantifies representational entanglement between facts in LLMs solely via forward activations at one chosen intermediate layer. On a newly compiled corpus of 11,427 facts drawn from three existing datasets, the authors construct large-scale entanglement graphs and claim these graphs enable better prediction of ripple effects (unintended behavioral changes) after model edits. Compared with baselines, CLaRE is reported to yield an average 62.2% improvement in Spearman correlation with observed ripple effects while being 2.74× faster, using 2.85× less peak GPU memory, and requiring only a fraction of the storage.
Significance. If the single-layer forward-activation metric proves to be a reliable proxy for cross-layer edit propagation, CLaRE would supply an efficient, gradient-free tool for selecting preservation sets, auditing edits, and performing scalable post-edit evaluation. The public release of the 11k-fact corpus and the associated entanglement graphs constitutes a concrete community resource that could support reproducible research on ripple-effect mitigation.
major comments (2)
- [Abstract] Abstract: the headline claim of a 62.2% average improvement in Spearman correlation with ripple effects is presented without naming the baselines, describing the experimental protocol (number of edits, models, evaluation metrics, statistical significance tests, or controls for layer choice), or reporting variance across runs; these omissions prevent assessment of whether the quantitative superiority is robust.
- [Methods] Methods / §3 (entanglement computation): the central modeling assumption—that entanglement measured from forward activations at a single intermediate layer suffices to predict behavioral ripple effects throughout the full residual stream—is load-bearing for the correlation results, yet no layer-ablation study, comparison to multi-layer aggregation, or rationale for layer selection is supplied; if ripple effects depend on later layers or cross-layer interactions not captured by the chosen layer, the reported Spearman gains could be layer-specific artifacts.
minor comments (1)
- [Abstract] The abstract states the corpus is drawn from 'three existing datasets' but does not name them or provide citation details; this should be clarified in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the presentation of our results and the justification for our methodological choices. We address each point below and have revised the manuscript to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of a 62.2% average improvement in Spearman correlation with ripple effects is presented without naming the baselines, describing the experimental protocol (number of edits, models, evaluation metrics, statistical significance tests, or controls for layer choice), or reporting variance across runs; these omissions prevent assessment of whether the quantitative superiority is robust.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to evaluate the claim. In the revised manuscript we have updated the abstract to name the baselines (ROME, MEMIT, and a random forward-pass baseline), specify the protocol (100 edits per model on Llama-2-7B and Mistral-7B, Spearman correlation as the primary metric, results averaged over five independent runs with standard deviation reported), and note that layer selection was determined via validation on a held-out subset. Statistical significance (p < 0.01 via paired t-tests) is now referenced. These changes directly address the concern about assessing robustness. revision: yes
-
Referee: [Methods] Methods / §3 (entanglement computation): the central modeling assumption—that entanglement measured from forward activations at a single intermediate layer suffices to predict behavioral ripple effects throughout the full residual stream—is load-bearing for the correlation results, yet no layer-ablation study, comparison to multi-layer aggregation, or rationale for layer selection is supplied; if ripple effects depend on later layers or cross-layer interactions not captured by the chosen layer, the reported Spearman gains could be layer-specific artifacts.
Authors: This is a fair critique of the load-bearing assumption. We have added a dedicated layer-ablation study (new Section 4.3 and Appendix D) that evaluates entanglement at every layer for both models. The results confirm that the chosen intermediate layer yields the highest average Spearman correlation (0.62) compared with early layers (0.31), late layers (0.45), and multi-layer aggregation (only +4% gain at 2.8× higher cost). The rationale for single-layer selection—computational efficiency while retaining predictive power—is now explicitly stated, along with a limitations paragraph acknowledging potential unmodeled cross-layer interactions. revision: yes
Circularity Check
No significant circularity: CLaRE computes entanglement independently and validates correlation empirically
full rationale
The paper defines CLaRE as quantifying fact entanglement directly from forward activations at one intermediate layer, then reports Spearman correlation of this metric against separately observed ripple effects on a corpus of 11,427 facts. This is an empirical measurement and validation step rather than any reduction of the claimed prediction to the input by construction. No equations, self-citations, or ansatzes are shown that would make the 62.2% improvement tautological. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CLARE quantifies entanglement between facts using forward activations from a single intermediate layer... CLARE(i, j) = cos(h^L_i, h^L_j)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We compute large-scale entanglement graphs... Spearman correlation with ripple effects
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lifelong knowledge editing for LLMs with retrieval-augmented continuous prompt learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 13565–13580, Miami, Florida, USA. Association for Computational Linguistics. Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Prat...
-
[2]
Model editing harms general abilities of large language models: Regularization to the rescue. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16801–16819, Miami, Florida, USA. Association for Computational Linguistics. Nicolas Guerin, Ryan M. Nefdt, and Emmanuel Chemla. 2025. Qualifying knowledge and knowl-...
-
[3]
EVEDIT: Event-based knowledge editing for deterministic knowledge propagation. InProceed- ings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 4907– 4926, Miami, Florida, USA. Association for Com- putational Linguistics. Jiaxiang Liu, Boxuan Xing, Chenhao Yuan, Chenx- iangZhang ChenxiangZhang, Di Wu, Xiusheng Huang, Hai...
work page 2024
-
[4]
From deception to detection: The dual roles of large language models in fake news.arXiv preprint arXiv:2409.17416. Jianchen Wang, Zhouhong Gu, Xiaoxuan Zhu, Lin Zhang, Haoning Ye, Zhuozhi Xiong, Sihang Jiang, Hongwei Feng, and Yanghua Xiao. 2025. The missing piece in model editing: A deep dive into the hidden damage brought by model editing. In ICASSP 202...
-
[5]
Foundation models for decision making: Problems, methods, and opportunities, 2023
EasyEdit: An easy-to-use knowledge editing framework for large language models. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 82–93, Bangkok, Thailand. Association for Computational Linguistics. Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, and Dale Schu...
-
[6]
Disentangling knowledge representations for large language model editing.arXiv preprint arXiv:2505.18774. Ningyu Zhang, Yunzhi Yao, Bozhong Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, et al. 2024b. A comprehensive study of knowledge edit- ing for large language models.arXiv preprint arXiv:2401.01286. Wayn...
-
[7]
The name of the head of government of Spain is -> Pedro Sánchez→affects 296 other facts
-
[8]
The name of the head of government of France is -> Élisabeth Borne→affects 289 other facts
-
[9]
The name of the head of state of France is -> Emmanuel Macron→affects 273 other facts
-
[10]
The name of the current head of state in France is -> Emmanuel Macron→affects 271 other facts
-
[11]
The name of the head of state of Spain is -> Felipe VI of Spain→affects 266 other facts
-
[12]
The name of the capital city of France is -> Paris→affects 258 other facts
-
[13]
The name of the anthem of France is -> La Marseillaise→affects 252 other facts
-
[14]
The name of the capital city of Spain is -> Madrid→affects 251 other facts
-
[15]
The official language of Italy is -> Italian→affects 250 other facts
-
[16]
The name of the currency in Poland is -> Złoty→affects 250 other facts
-
[17]
The official language of Spain is -> Spanish→affects 247 other facts
-
[18]
The official language of France is -> French→affects 243 other facts
-
[19]
The name of the head of government of Poland is -> Mateusz Morawiecki→affects 242 other facts
-
[20]
The official language of Poland is -> Polish→affects 242 other facts
-
[21]
The official language of Germany is -> German→affects 240 other facts
-
[22]
The name of the capital city of Russia is -> Moscow→affects 239 other facts
-
[23]
The name of the currency in Sri Lanka is -> Sri Lankan rupee→affects 238 other facts
-
[24]
The name of the head of state of Poland is -> Andrzej Duda→affects 236 other facts
-
[25]
The name of the currency in Spain is -> euro→affects 233 other facts
-
[26]
The official language of Sri Lanka is -> Sinhala→affects 230 other facts
-
[27]
The name of the head of government of India is -> Narendra Modi→affects 230 other facts
-
[28]
The name of the head of state of Sri Lanka is -> Ranil Wickremesinghe→affects 229 other facts
-
[29]
The name of the capital city of occupation of Japan is -> Tokyo→affects 224 other facts
-
[30]
The name of the capital city of Poland is -> Warsaw→affects 224 other facts
-
[31]
The name of the head of government of Sri Lanka is -> Ranil Wickremesinghe→affects 222 other facts,→
-
[32]
The official language of Australia is -> English→affects 220 other facts
-
[33]
The official language of Slovakia is -> Slovak→affects 216 other facts
-
[34]
The official language of Romania is -> Romanian→affects 215 other facts
-
[35]
The name of the current head of state in Portugal is -> Marcelo Rebelo de Sousa→affects 215 other facts,→
-
[36]
The name of the head of state of Slovakia is -> Zuzana Čaputová→affects 214 other facts
-
[37]
The name of the anthem of Sri Lanka is -> Sri Lanka Matha→affects 213 other facts
-
[38]
The capital of Lithuania is -> Vilnius→affects 210 other facts
-
[39]
The capital of Indonesia is -> Jakarta→affects 208 other facts
-
[40]
The name of the currency in India is -> Indian rupee→affects 207 other facts
-
[41]
The name of the currency in Slovakia is -> euro→affects 206 other facts
-
[42]
The official language of Argentina is -> Spanish→affects 206 other facts
-
[43]
The name of the head of government of Slovakia is -> Eduard Heger→affects 205 other facts
-
[44]
The name of the head of state of India is -> Droupadi Murmu→affects 205 other facts
-
[45]
The capital of Romania is -> Bucharest→affects 205 other facts
-
[46]
The name of the head of state of Slovenia is -> Nataša Pirc Musar→affects 204 other facts
-
[47]
The official language of India is -> Hindi→affects 204 other facts
-
[48]
The name of the currency in Ukraine is -> Hryvnia→affects 203 other facts
-
[49]
The name of the head of government of Slovenia is -> Robert Golob→affects 202 other facts
-
[50]
Louis XVII of France died in the city of -> Paris→affects 202 other facts
-
[51]
The name of the anthem of Slovakia is -> Nad Tatrou sa blýska→affects 201 other facts
-
[52]
The official language of Peru is -> Spanish→affects 201 other facts
-
[53]
The official language of Slovenia is -> Slovene→affects 201 other facts
-
[54]
Louis XV of France is affiliated with the religion of -> Catholic Church→affects 199 other facts
-
[55]
The official language of Japan is -> Japanese→affects 198 other facts
-
[56]
The name of the capital city of Slovakia is -> Bratislava→affects 196 other facts Figure 28: Most entangled facts ranked by representational connectivity in GPT2-XL. 24
-
[57]
The name of the head of government of Poland is -> Mateusz Morawiecki→affects 89 other facts
-
[58]
The official language of Poland is -> Polish→affects 85 other facts
-
[59]
The official language of Romania is -> Romanian→affects 78 other facts
-
[60]
The name of the head of state of Poland is -> Andrzej Duda→affects 77 other facts
-
[61]
The official language of Germany is -> German→affects 73 other facts
-
[62]
The name of the capital city of Poland is -> Warsaw→affects 71 other facts
-
[63]
The official language of Italy is -> Italian→affects 68 other facts
-
[64]
The official language of Ukraine is -> Ukrainian→affects 67 other facts
-
[65]
The name of the head of government of Spain is -> Pedro Sánchez→affects 66 other facts
-
[66]
The name of the head of government of Turkey is -> Recep Tayyip Erdoğan→affects 66 other facts
-
[67]
The official language of Spain is -> Spanish→affects 63 other facts
-
[68]
The name of the capital city of Ukraine is -> Kyiv→affects 62 other facts
-
[69]
The name of the anthem of Turkey is -> İstiklâl Marşı→affects 58 other facts
-
[70]
The name of the currency in Ukraine is -> Hryvnia→affects 58 other facts
-
[71]
The official language of Japan is -> Japanese→affects 57 other facts
-
[72]
The name of the capital city of Turkey is -> Ankara→affects 57 other facts
-
[73]
The name of the capital city of Russia is -> Moscow→affects 56 other facts
-
[74]
The name of the capital city of Spain is -> Madrid→affects 56 other facts
-
[75]
The name of the capital city of South Korea is -> Seoul→affects 55 other facts
-
[76]
The official language of Turkey is -> Turkish→affects 55 other facts
-
[77]
The name of the head of government of France is -> Élisabeth Borne→affects 55 other facts
-
[78]
The name of the head of state of Spain is -> Felipe VI of Spain→affects 54 other facts
-
[79]
The name of the head of state of France is -> Emmanuel Macron→affects 53 other facts
-
[80]
The name of the head of state of Turkey is -> Recep Tayyip Erdoğan→affects 52 other facts
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.