Herding CATs: ALARA for Agent Harness Engineering in Portable Composable Multi-Agent Teams
Pith reviewed 2026-05-21 11:07 UTC · model grok-4.3
The pith
Interrelated plain-text files apply the ALARA principle to context so users can directly declare and modify tool access for each agent in multi-agent teams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
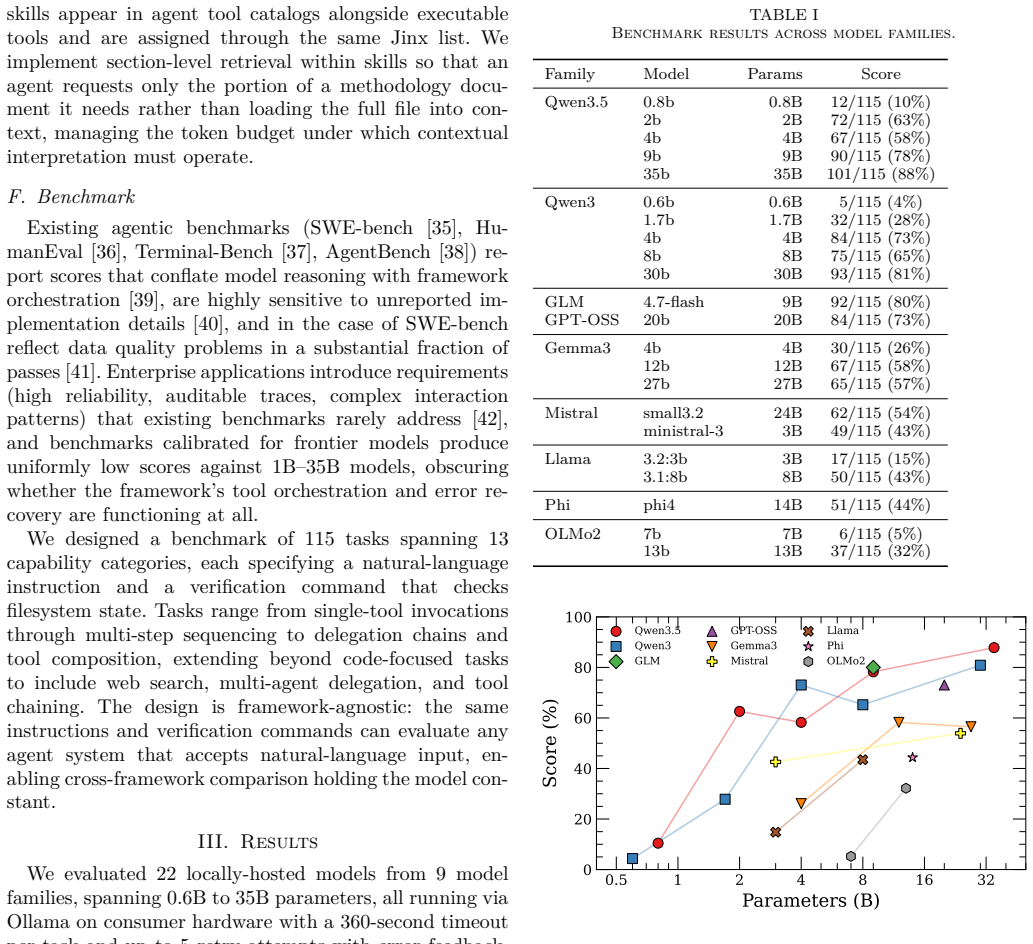
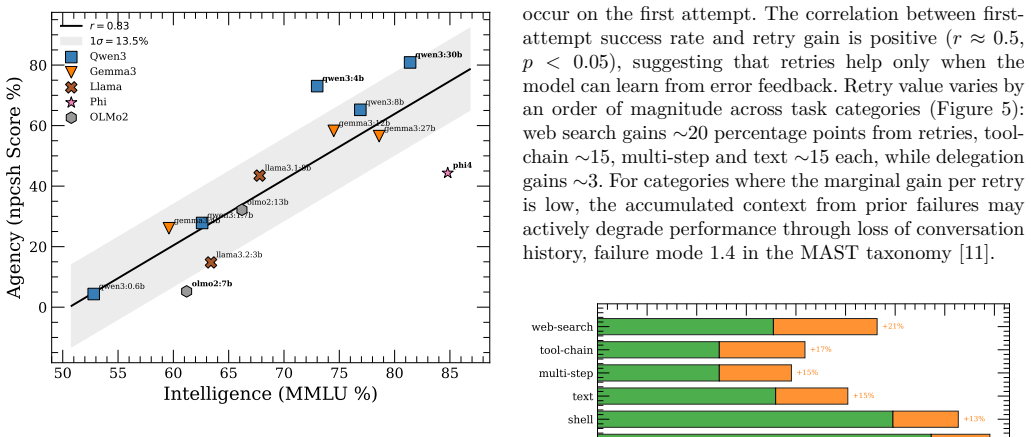
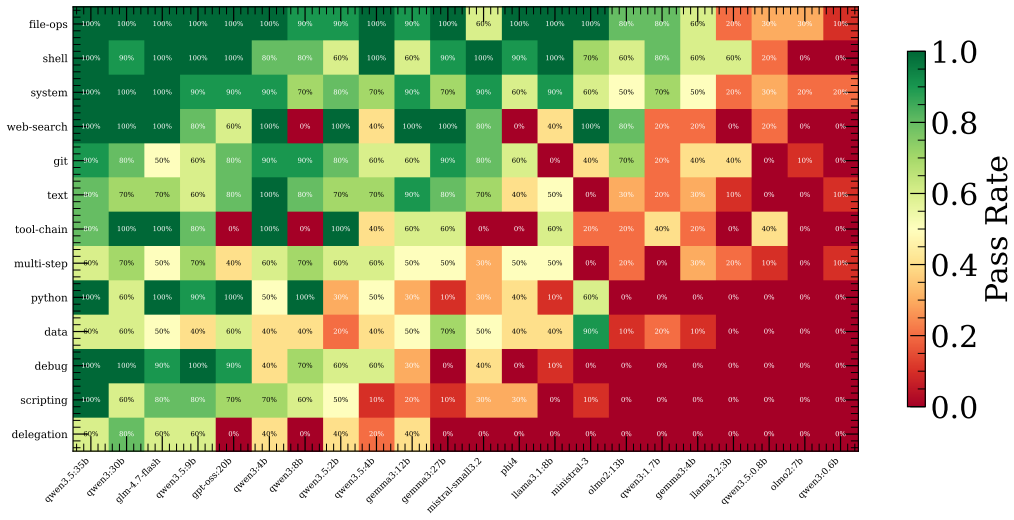
Applying the ALARA principle from radiation safety to context, we introduce a context-agent-tool (CAT) data layer expressed through interrelated plain-text files, allowing users to directly declare tool access for each agent and to modify the tools themselves that are used by the agents when processing. We demonstrate capability of this CAT data layer to enable real agentic usage by using a command-line shell that loads the team and executes agent runs -- npcsh -- and evaluating 22 locally-hosted models from 0.6B to 35B parameters across 115 practical tasks spanning file operations, web search, multi-step scripting, tool chaining, and multi-agent delegation. We characterize which model fami
What carries the argument
The CAT data layer of interrelated plain-text files that declare context, agents, and tools for each team member, which carries the argument by turning fragmented behavioral specifications into a single, versionable, and directly editable structure.
If this is right
- Agent behaviors become portable across projects because the harness specifications live in ordinary files rather than inside any particular framework.
- Teams can coordinate context engineering work by editing and reviewing the same set of plain-text declarations.
- Individual human-agent interactions improve because tool access can be adjusted precisely for each agent instead of relying on general instructions.
- Model selection for practical work becomes more informed once performance patterns across task categories are measured under the same harness.
- Tool chaining and delegation steps gain reliability when each agent's allowed actions are stated explicitly in the data layer.
Where Pith is reading between the lines
- The plain-text approach would integrate naturally with existing version-control workflows, letting agent configurations participate in the same review and branching processes as code.
- Extending the same ALARA-style minimalism to other context elements such as memory stores or output formats could further reduce unintended agent actions.
- The evaluation method of running thousands of executions across model sizes offers a template for future benchmarks that test harness engineering rather than isolated model capability.
- Adoption in domains with strict audit requirements could follow directly because every tool access declaration is human-readable and traceable.
Load-bearing premise
That plain-text files applying the ALARA principle to context will deliver a more scalable, versionable, and collaboratively maintainable way to declare and change agent tool access than prose instructions or internal framework configurations.
What would settle it
A side-by-side test in which two teams maintain the same multi-agent project for several weeks, one using CAT plain-text files and the other using prose instructions, then measure the number of unintended tool calls and the time required to propagate a change across all agents.
Figures

read the original abstract
Industry practitioners and academic researchers regularly use multi-agent systems to accelerate their work, but the applications through which users operate these systems do not provide a simple, unified mechanism for scalably managing critical components of the agent harness. This lack of control adversely impacts both the quality of individual human-agent interactions and reduces the capacity for practitioners to coordinate context engineering efforts. The behavioral specifications that define what agents in such systems can do remain fragmented across prose instruction files -- for which compliance cannot be guaranteed -- or framework-internal configurations, making these specifications difficult to share, version, or collaboratively maintain across teams and projects. Applying the ALARA principle from radiation safety (exposures kept as low as reasonably achievable) to context, we introduce a context-agent-tool (CAT) data layer expressed through interrelated plain-text files, allowing users to directly declare tool access for each agent and to modify the tools themselves that are used by the agents when processing. We demonstrate capability of this CAT data layer to enable real agentic usage by using a command-line shell that loads the team and executes agent runs -- \texttt{npcsh} -- and evaluating 22 locally-hosted models from 0.6B to 35B parameters across 115 practical tasks spanning file operations, web search, multi-step scripting, tool chaining, and multi-agent delegation. We characterize which model families succeed in certain task categories and where they break down across $\sim$2500 total executions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Context-Agent-Tool (CAT) data layer of interrelated plain-text files that applies the ALARA principle to context in multi-agent systems. This is presented as a scalable, versionable, and collaboratively maintainable mechanism for declaring and modifying agent tool access, superior to fragmented prose instructions or framework-internal configurations. The authors implement the approach in the npcsh command-line shell and report an evaluation of 22 locally-hosted models (0.6B–35B parameters) on 115 tasks spanning file operations, web search, multi-step scripting, tool chaining, and multi-agent delegation, across approximately 2500 total executions, with characterization of model-family performance.
Significance. If the claimed advantages of the CAT data layer hold, the work could meaningfully advance practical engineering of portable, composable multi-agent teams by aligning harness management with standard software practices such as version control and collaborative editing. The broad empirical runs across model scales and task categories provide a useful snapshot of local-model agentic capabilities, which is a concrete strength for an engineering-focused contribution.
major comments (2)
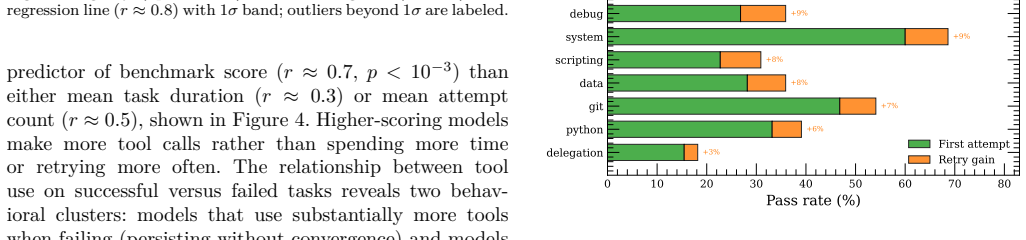
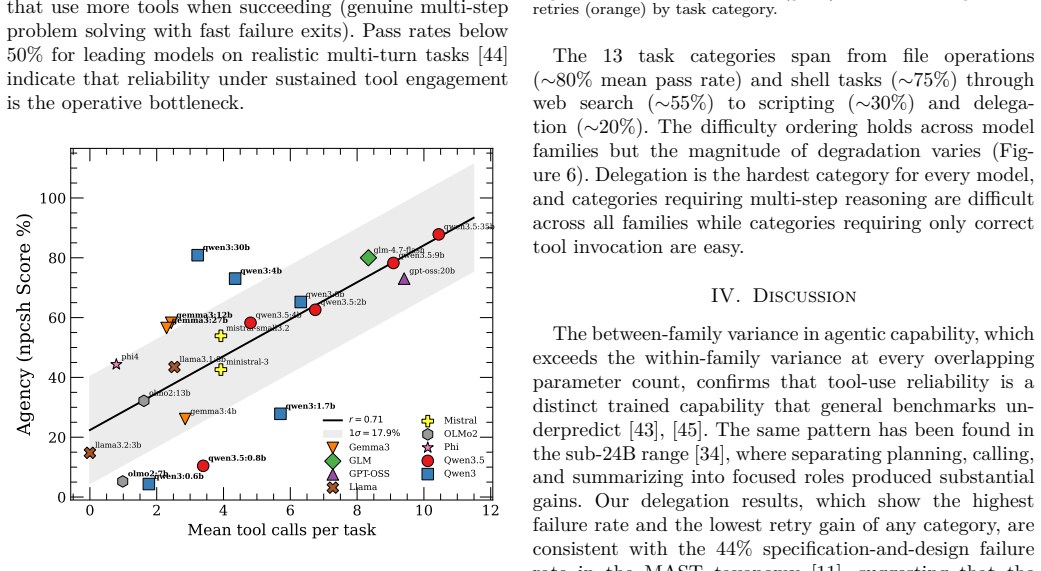
- [Evaluation] Evaluation (as described in the abstract and results): The reported ~2500 executions demonstrate task completion with npcsh but include no baseline comparisons against prose instruction files or existing framework configurations, nor any metrics, ablations, or examples quantifying scalability, versionability, collaborative maintenance effort, or outperformance. These omissions are load-bearing for the central claim that the CAT layer delivers superior practical advantages.
- [Methods] Experimental design: No details are supplied on controls, success/failure criteria, error bars, statistical analysis, or how the 115 tasks were selected and scored. This prevents assessment of whether the results reliably support the assertion of enabling 'real agentic usage'.
minor comments (1)
- [Abstract] Abstract: The expansion and application of 'ALARA' to context is introduced without a concise parenthetical reminder, which may reduce immediate accessibility for readers outside radiation-safety contexts.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the potential of the CAT data layer to advance practical multi-agent harness engineering. We address each major comment below, indicating the revisions we will make to improve the manuscript while preserving its engineering focus and empirical characterization of local models.
read point-by-point responses
-
Referee: [Evaluation] Evaluation (as described in the abstract and results): The reported ~2500 executions demonstrate task completion with npcsh but include no baseline comparisons against prose instruction files or existing framework configurations, nor any metrics, ablations, or examples quantifying scalability, versionability, collaborative maintenance effort, or outperformance. These omissions are load-bearing for the central claim that the CAT layer delivers superior practical advantages.
Authors: We acknowledge that the evaluation section emphasizes demonstration of functional agentic capability rather than head-to-head comparisons. The core argument for the CAT data layer rests on its structural properties: plain-text files enable direct use of version control, diffing, and collaborative editing, which prose instructions and opaque framework configs do not. The ~2500 executions across 22 models and 115 tasks serve to show that this layer supports real usage at scale. To strengthen the presentation, we will add a dedicated discussion subsection with concrete examples of versionability (e.g., git-tracked changes to tool-access declarations) and collaborative maintenance, plus a small-scale quantitative illustration on a subset of tasks measuring file-modularity and edit effort relative to equivalent prose prompts. A full comparative ablation across all tasks lies outside the current scope and will be noted as future work. revision: partial
-
Referee: [Methods] Experimental design: No details are supplied on controls, success/failure criteria, error bars, statistical analysis, or how the 115 tasks were selected and scored. This prevents assessment of whether the results reliably support the assertion of enabling 'real agentic usage'.
Authors: We agree that the current manuscript under-specifies the experimental protocol. In revision we will expand the Evaluation section to describe: task curation (115 tasks drawn from representative practical categories: file operations, web search, multi-step scripting, tool chaining, and delegation); explicit success criteria per category (e.g., correct file state for I/O tasks, factual accuracy for search, successful delegation for multi-agent cases); scoring procedure (automated log checks supplemented by author verification on a stratified sample); and controls (identical system prompts, tool schemas, and environment across all models). Because the study is observational—intended to characterize model-family behavior rather than test hypotheses—we did not compute error bars or perform statistical tests; we will state this explicitly and report results as descriptive success rates by category and model scale. These additions will make the support for 'real agentic usage' more transparent. revision: yes
Circularity Check
No circularity: engineering proposal with independent empirical demonstration
full rationale
The paper proposes a CAT data layer by applying the external ALARA principle to agent context management and demonstrates it via the npcsh shell executing 22 models on 115 tasks (~2500 runs). No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the provided text. The central claims rest on practical task performance rather than reducing to inputs by construction, satisfying the self-contained criterion with external falsifiability through model runs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ALARA principle from radiation safety can be productively applied to context and tool access management in agent systems
invented entities (2)
-
CAT data layer
no independent evidence
-
npcsh
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Applying the ALARA principle from radiation safety ... we introduce a declarative context-agent-tool (CAT) data layer expressed through interrelated files that scope each agent’s tool access and context to the minimum its role requires
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Jinx list enforces its constraint structurally rather than interpretively. ... tools not on the Jinx list do not exist in the agent’s schema
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic, “Building effective agents,” 2024. [Online]. Available: https://www.anthropic.com/research/building-effective-agents
work page 2024
-
[2]
P. Gauthier, “Aider,” 2023. [Online]. Available: https://github. com/paul-gauthier/aider
work page 2023
-
[3]
H. Chase, “Langchain,” 2022. [Online]. Available: https: //github.com/langchain-ai/langchain
work page 2022
-
[4]
Autogen: Enabling next-gen LLM applications via multi-agent conversation,
Q. Wuet al., “Autogen: Enabling next-gen LLM applications via multi-agent conversation,” 2023
work page 2023
-
[5]
J. ao Moura, “Crewai,” 2024. [Online]. Available: https: //github.com/crewai/crewai
work page 2024
-
[6]
A quantum semantic framework for natural language processing,
C. J. Agostino, Q. Le Thien, M. Apsel, D. Pak, E. Lesyk, and A. Majumdar, “A quantum semantic framework for natural language processing,” inInternational Conference on Quan- tum Artificial Intelligence and Natural Language Processing. Springer, 2025, pp. 134–155
work page 2025
-
[7]
The production of meaning in the pro- cessing of natural language,
C. J. Agostinoet al., “The production of meaning in the pro- cessing of natural language,” inProc. HAXD, 2026, submitted
work page 2026
-
[8]
Trouillas,A Quantum Theory of Syntax
P. Trouillas,A Quantum Theory of Syntax. Nova Science Publishers, 2024
work page 2024
-
[9]
Fundamental limits of quantum semantic communication via sheaf cohomology,
C. K. Thomas and M. Chen, “Fundamental limits of quantum semantic communication via sheaf cohomology,”arXiv preprint arXiv:2601.10958, 2026
-
[10]
Lost in the middle: How language models use long contexts
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”Trans. Assoc. Comput. Linguist., vol. 12, pp. 157–173, 2024, arXiv:2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Why Do Multi-Agent LLM Systems Fail?
M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ram- chandran, M. Zaharia, J. E. Gonzalez, and I. Stoica, “Why do multi-agent LLM systems fail?” inProc. NeurIPS Datasets and Benchmarks, 2025, arXiv:2503.13657
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Harms from increasingly agentic algorithmic systems,
A. Chanet al., “Harms from increasingly agentic algorithmic systems,” inProc. FAccT, 2023
work page 2023
-
[13]
Progent: Programmable privilege control for LLM agents,
T. Shi, J. He, Z. Wang, L. Wu, H. Li, W. Guo, and D. Song, “Progent: Programmable privilege control for LLM agents,” 2025
work page 2025
-
[14]
Prompt flow integrity to prevent privilege escalation in LLM agents,
others, “Prompt flow integrity to prevent privilege escalation in LLM agents,” 2025
work page 2025
-
[15]
Design patterns for securing LLM agents against prompt injections,
F. Tram` eret al., “Design patterns for securing LLM agents against prompt injections,” 2025
work page 2025
-
[16]
Recommendations of the international commission on radiological protection,
ICRP, “Recommendations of the international commission on radiological protection,”ICRP Publication 26, Annals of the ICRP, vol. 1, no. 3, 1977
work page 1977
-
[17]
Nuclear Regulatory Commission, “ALARA
U.S. Nuclear Regulatory Commission, “ALARA. ” [On- line]. Available: https://www.nrc.gov/reading-rm/basic-ref/ glossary/alara.html
-
[18]
National Institute of Standards and Technology, “Least privilege,” nIST SP 800-53 Rev. 5. [Online]. Available: https://csrc.nist.gov/glossary/term/least privilege
-
[19]
Taskbench: Benchmarking large language mod- els for task automation,
Y. Shenet al., “Taskbench: Benchmarking large language mod- els for task automation,” inProc. NeurIPS, 2024
work page 2024
-
[20]
Everything is context: Agentic file system abstrac- tion for context engineering,
X. Xuet al., “Everything is context: Agentic file system abstrac- tion for context engineering,” 2025
work page 2025
-
[21]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess` ı, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inProc. NeurIPS, 2023
work page 2023
-
[22]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “ReAct: Synergizing reasoning and acting in language models,” inProc. ICLR, 2023
work page 2023
-
[23]
Principles of mixed-initiative user interfaces,
E. Horvitz, “Principles of mixed-initiative user interfaces,” in Proc. CHI. ACM, 1999, pp. 159–166
work page 1999
-
[24]
ADL: A declarative language for agent- based chatbots,
S. Zeng and X. Yan, “ADL: A declarative language for agent- based chatbots,” 2025
work page 2025
-
[25]
When single-agent with skills replace multi-agent sys- tems and when they fail,
X. Li, “When single-agent with skills replace multi-agent sys- tems and when they fail,” 2026
work page 2026
-
[26]
B. Shneiderman,Human-Centered AI. Oxford University Press, 2022
work page 2022
-
[27]
A model for types and levels of human interaction with automation,
R. Parasuraman, T. B. Sheridan, and C. D. Wickens, “A model for types and levels of human interaction with automation,” IEEE Trans. Syst. Man Cybern. A, vol. 30, no. 3, pp. 286–297, 2000
work page 2000
-
[28]
Levels of autonomy for AI agents,
K. Fenget al., “Levels of autonomy for AI agents,” 2025
work page 2025
-
[29]
S. Zhanget al., “Exploring collaboration patterns and strategies in human-AI co-creation through the lens of agency: A scop- ing review of the top-tier HCI literature,”Proc. ACM Hum.- Comput. Interact., 2025, arXiv:2507.06000
-
[30]
MetaGPT: Meta programming for a multi-agent collaborative framework,
S. Honget al., “MetaGPT: Meta programming for a multi-agent collaborative framework,” inProc. ICLR, 2024
work page 2024
-
[31]
Agentverse: Facilitating multi-agent collabora- tion and exploring emergent behaviors,
W. Chenet al., “Agentverse: Facilitating multi-agent collabora- tion and exploring emergent behaviors,” inProc. ICLR, 2024
work page 2024
-
[32]
A dynamic LLM-powered agent network for task- oriented agent collaboration,
Z. Liuet al., “A dynamic LLM-powered agent network for task- oriented agent collaboration,” inProc. COLM, 2024
work page 2024
-
[33]
ChatDev: Communicative agents for software development,
C. Qianet al., “ChatDev: Communicative agents for software development,” inProc. ACL, 2024
work page 2024
-
[34]
Small LLMs are weak tool learners: A multi- LLM agent,
W. Shenet al., “Small LLMs are weak tool learners: A multi- LLM agent,” inProc. EMNLP, 2024, pp. 16 658–16 680
work page 2024
-
[35]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenezet al., “SWE-bench: Can language models resolve real-world GitHub issues?” inProc. ICLR, 2024
work page 2024
-
[36]
Evaluating large language models trained on code,
M. Chenet al., “Evaluating large language models trained on code,” 2021
work page 2021
- [37]
-
[38]
Agentbench: Evaluating LLMs as agents,
Y. Liuet al., “Agentbench: Evaluating LLMs as agents,” in Proc. ICLR, 2024
work page 2024
-
[39]
S. Kapooret al., “AI agents that matter,”Trans. Mach. Learn. Res., 2025
work page 2025
-
[40]
Lessons from the trenches on reproducible evaluation of language models,
S. Bidermanet al., “Lessons from the trenches on reproducible evaluation of language models,” 2024
work page 2024
-
[41]
SWE-Bench+: Enhanced coding benchmark for LLMs,
R. Aleithanet al., “SWE-Bench+: Enhanced coding benchmark for LLMs,” 2024
work page 2024
-
[42]
Evaluation and benchmarking of LLM agents: A survey,
“Evaluation and benchmarking of LLM agents: A survey,” in Proc. KDD, 2025, arXiv:2507.21504
-
[43]
S. G. Patil, H. Maoet al., “The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models,” inProc. ICML, 2025
work page 2025
-
[44]
τ-bench: A benchmark for tool-agent-user interaction in real-world do- mains,
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan, “τ-bench: A benchmark for tool-agent-user interaction in real-world do- mains,” 2024
work page 2024
-
[45]
Gorilla: Large language model connected with massive APIs,
S. G. Patilet al., “Gorilla: Large language model connected with massive APIs,” inProc. NeurIPS, 2024
work page 2024
-
[46]
DSPy: Compiling declarative language model calls into self-improving pipelines,
O. Khattabet al., “DSPy: Compiling declarative language model calls into self-improving pipelines,” inProc. ICLR, 2024
work page 2024
-
[47]
D. B. Piskala, “From everything-is-a-file to files-are-all-you- need: How unix philosophy informs the design of agentic AI systems,” 2026
work page 2026
-
[48]
Guidelines for human-AI interaction,
S. Amershiet al., “Guidelines for human-AI interaction,” in Proc. CHI. ACM, 2019
work page 2019
-
[49]
Engineering AI agents for clinical workflows: A case study in architecture, MLOps, and governance,
C. Lopeset al., “Engineering AI agents for clinical workflows: A case study in architecture, MLOps, and governance,” inProc. CAIN, 2026
work page 2026
-
[50]
Machine learning operations (MLOps): Overview, definition, and architecture,
D. Kreuzberger, N. K¨ uhl, and S. Hirschl, “Machine learning operations (MLOps): Overview, definition, and architecture,” IEEE Access, vol. 11, pp. 31 866–31 879, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.