AeroScene: Progressive Scene Synthesis for Aerial Robotics
Pith reviewed 2026-05-15 00:38 UTC · model grok-4.3
The pith
A hierarchical diffusion model generates progressive 3D scenes for aerial robotics by combining global layout reasoning with local detail extraction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
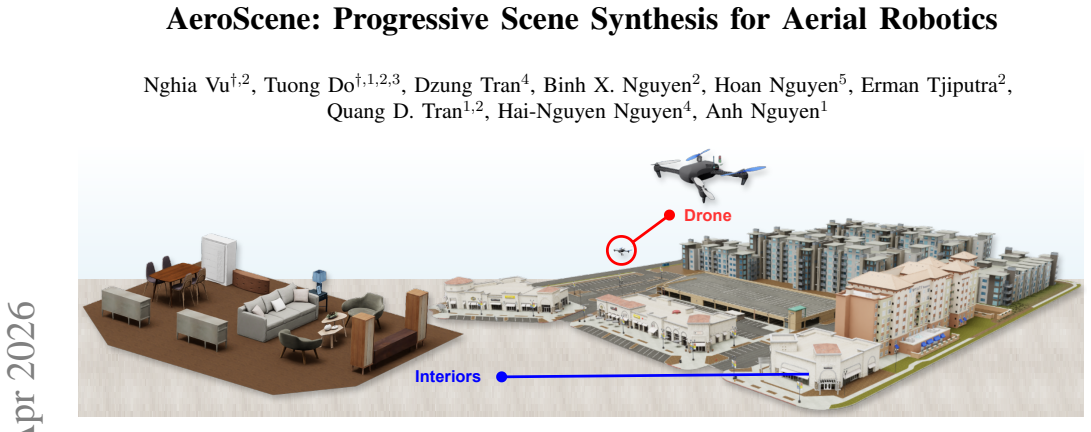
AeroScene leverages hierarchy-aware tokenization and multi-branch feature extraction within a hierarchical diffusion model to reason across global layouts and local details, generating realistic 3D scenes suitable for aerial robotics applications such as navigation and landing.
What carries the argument
Hierarchy-aware tokenization and multi-branch feature extraction that enable progressive scene synthesis from global to local scales in a diffusion framework.
If this is right
- Scenes generated by AeroScene integrate directly into NVIDIA Isaac Sim as physics-ready environments.
- The method produces over 1,000 high-fidelity 3D scenes forming a large-scale public dataset.
- Generated environments improve performance on downstream tasks including drone navigation.
- The progressive synthesis supports tasks such as landing and perching in addition to navigation.
Where Pith is reading between the lines
- Automated generation of simulation scenes could accelerate development cycles in aerial robotics by replacing time-consuming manual modeling.
- Applying similar hierarchical approaches to other robotics domains like ground vehicles might yield comparable scalability benefits.
- Future work could test the scenes in real-world transfer by comparing simulation-trained policies to real drone flights.
Load-bearing premise
The hierarchy-aware tokenization and multi-branch feature extraction will automatically ensure physical plausibility and semantic consistency in the generated scenes.
What would settle it
Load generated scenes into a physics engine such as NVIDIA Isaac Sim and count the fraction that contain invalid configurations like floating objects or interpenetrating geometry, then compare the rate against manually authored scenes.
Figures




read the original abstract
Generative models have shown substantial impact across multiple domains, their potential for scene synthesis remains underexplored in robotics. This gap is more evident in drone simulators, where simulation environments still rely heavily on manual efforts, which are time-consuming to create and difficult to scale. In this work, we introduce AeroScene, a hierarchical diffusion model for progressive 3D scene synthesis. Our approach leverages hierarchy-aware tokenization and multi-branch feature extraction to reason across both global layouts and local details, ensuring physical plausibility and semantic consistency. This makes AeroScene particularly suited for generating realistic scenes for aerial robotics tasks such as navigation, landing, and perching. We demonstrate its effectiveness through extensive experiments on our newly collected dataset and a public benchmark, showing that AeroScene significantly outperforms prior methods. Furthermore, we use AeroScene to generate a large-scale dataset of over 1,000 physics-ready, high fidelity 3D scenes that can be directly integrated into NVIDIA Isaac Sim. Finally, we illustrate the utility of these generated environments on downstream drone navigation tasks. Our code and dataset are publicly available at aioz-ai.github.io/AeroScene/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AeroScene, a hierarchical diffusion model for progressive 3D scene synthesis in aerial robotics. It uses hierarchy-aware tokenization and multi-branch feature extraction to generate scenes claimed to ensure physical plausibility and semantic consistency. The method outperforms prior approaches on a newly collected dataset and public benchmark, produces over 1,000 physics-ready high-fidelity 3D scenes directly integrable into NVIDIA Isaac Sim, and demonstrates utility for downstream drone navigation tasks. Code and dataset are released publicly.
Significance. If the central claims hold, AeroScene would meaningfully advance automated, scalable scene generation for drone simulators, reducing reliance on manual environment creation and supporting training for navigation, landing, and perching. The public release of a large physics-ready dataset and code is a notable strength for reproducibility and community use.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central claim that hierarchy-aware tokenization plus multi-branch feature extraction automatically yields 'physical plausibility' for rigid-body integration in Isaac Sim lacks supporting evidence; no physics-based loss terms (collision, stability, gravity consistency) or quantitative post-generation checks (penetration metrics, dynamics pass rates) are described, leaving the 'physics-ready' assertion dependent solely on training data distribution and qualitative results.
- [Experiments] Experiments section: the reported outperformance on downstream drone navigation tasks and the new dataset lacks visible full metrics, complete baseline comparisons, ablation details on hierarchy levels, or error analysis, which weakens the empirical grounding for the claim of significant superiority.
minor comments (2)
- [Abstract] Abstract: briefly quantify the outperformance (e.g., specific metric gains over baselines) to strengthen the summary of results.
- [Dataset] Dataset description: provide clearer statistics on the newly collected dataset size, diversity, and collection protocol to contextualize generalization claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central claim that hierarchy-aware tokenization plus multi-branch feature extraction automatically yields 'physical plausibility' for rigid-body integration in Isaac Sim lacks supporting evidence; no physics-based loss terms (collision, stability, gravity consistency) or quantitative post-generation checks (penetration metrics, dynamics pass rates) are described, leaving the 'physics-ready' assertion dependent solely on training data distribution and qualitative results.
Authors: We agree that the manuscript does not introduce explicit physics-based loss terms (e.g., collision or stability penalties) or report quantitative post-generation physics metrics such as penetration rates or dynamics simulation pass rates. Physical plausibility is achieved implicitly through training on a dataset of real-world aerial scenes that already satisfy rigid-body constraints, combined with the hierarchical tokenization that enforces global layout consistency and reduces local implausibilities. To strengthen the presentation, we will revise §3 to explicitly state this reliance on data distribution and add a short paragraph in the experiments section with qualitative evidence from generated scenes (e.g., absence of floating or intersecting objects in visualizations). Full quantitative physics validation in Isaac Sim is noted as future work, as the current focus is on generation quality. This constitutes a partial revision. revision: partial
-
Referee: [Experiments] Experiments section: the reported outperformance on downstream drone navigation tasks and the new dataset lacks visible full metrics, complete baseline comparisons, ablation details on hierarchy levels, or error analysis, which weakens the empirical grounding for the claim of significant superiority.
Authors: We acknowledge that the main paper presents summarized results to maintain readability, with complete numerical tables, full baseline comparisons, hierarchy-level ablations, and error analysis placed in the supplementary material. To address the concern, we will expand the experiments section to include the key quantitative tables and ablation results directly in the main text, along with a concise error analysis paragraph. This will make the empirical claims more self-contained. The revision will be incorporated in the next version. revision: yes
Circularity Check
No significant circularity detected in AeroScene derivation
full rationale
The paper presents a hierarchical diffusion model trained end-to-end on collected data, with performance claims grounded in experiments on an independent public benchmark and downstream task evaluations. Hierarchy-aware tokenization and multi-branch extraction are architectural choices whose outputs are validated externally rather than defined to equal the inputs by construction. No equations, fitted parameters renamed as predictions, or self-citation chains reduce the central claims (outperformance, physics-ready scenes, navigation utility) to tautologies. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Diffusion model hyperparameters and hierarchy levels
axioms (1)
- domain assumption Diffusion models conditioned on hierarchical features can produce physically plausible and semantically consistent 3D scenes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach leverages hierarchy-aware tokenization and multi-branch feature extraction to reason across both global layouts and local details, ensuring physical plausibility and semantic consistency.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We ensure the physical plausibility ... by guiding the conditional scene diffusion process with physics-based guidance functions ... Lcol(xt) = Σ max(0, IoU(Bi,Bj)−δd)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Autonomous drone for room exploration and 3d reconstruction,
B. Sandikci and I. Colak, “Autonomous drone for room exploration and 3d reconstruction,” inSmartNets, 2025
work page 2025
-
[2]
S. Cascarano, M. Milazzo, A. Vannini, A. Spezzaneve, and S. Roccella, “Design and development of drones to autonomously interact with objects in unstructured outdoor scenarios,”Field Robotics, 2021
work page 2021
-
[3]
Aerial vision-and-dialog navigation,
Y . Fan, W. Chen, T. Jiang, C. Zhou, Y . Zhang, and X. E. Wang, “Aerial vision-and-dialog navigation,”arXiv, 2022
work page 2022
-
[4]
Y . Liu, M. Zhao, K. Hou, J. Xia, C. Carver, S. Xia, X. Zhou, and X. Jiang, “Aira: A low-cost ir-based approach towards autonomous precision drone landing and nlos indoor navigation,”arXiv, 2024
work page 2024
-
[5]
Affordmatcher: Affordance learning in 3d scenes from visual signifiers,
N. Vu, T. Do, K. Nguyen, B. Huang, N. Le, B. X. Nguyen, E. Tjiputra, Q. D. Tran, R. Prakash, T.-C. Chiu, and A. Nguyen, “Affordmatcher: Affordance learning in 3d scenes from visual signifiers,” inCVPR, 2026
work page 2026
-
[6]
Precision uav landing in unstructured environments,
K. Pluckter and S. Scherer, “Precision uav landing in unstructured environments,” inISER, 2018
work page 2018
- [7]
-
[8]
Airsim: High-fidelity visual and physical simulation for autonomous vehicles,
S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” inFSR, 2017
work page 2017
-
[9]
Comparative review of drone simulators,
M. Nikolaiev and M. Novotarskyi, “Comparative review of drone simulators,”Information, Computing and Intelligent systems, 2024
work page 2024
-
[10]
Scalable modular synthetic data generation for advancing aerial autonomy,
M. Sabet, P. Palanisamy, and S. Mishra, “Scalable modular synthetic data generation for advancing aerial autonomy,”RA-S, 2023
work page 2023
-
[11]
Survey of simulators for aerial robots: An overview and in-depth systematic comparisons,
C. A. Dimmig, G. Silano, K. McGuire, C. Gabellieri, W. H ˇsnig, J. Moore, and M. Kobilarov, “Survey of simulators for aerial robots: An overview and in-depth systematic comparisons,”RA-M, 2024
work page 2024
-
[12]
Isaac gym: High performance gpu- based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Mack- lin, A. Allshire, A. Handa,et al., “Isaac gym: High performance gpu- based physics simulation for robot learning,”arXiv, 2021
work page 2021
-
[13]
Omnidrones: An efficient and flexible platform for reinforcement learning in drone control,
B. Xu, F. Gao, C. Yu, R. Zhang, Y . Wu, and Y . Wang, “Omnidrones: An efficient and flexible platform for reinforcement learning in drone control,”RA-L, 2024
work page 2024
-
[14]
Z. Huang, S. Batra, T. Chen, R. Krupani, T. Kumar, A. Molchanov, A. Petrenko, J. A. Preiss, Z. Yang, and G. S. Sukhatme, “Quadswarm: A modular multi-quadrotor simulator for deep reinforcement learning with direct thrust control,”arXiv, 2023
work page 2023
-
[15]
Visfly: An efficient and versatile simulator for training vision-based flight,
F. Li, F. Sun, T. Zhang, and D. Zou, “Visfly: An efficient and versatile simulator for training vision-based flight,”arXiv, 2024
work page 2024
-
[16]
High-fidelity integrated aerial platform simulation for control, perception, and learning,
J. Du, K. Wang, Y . Fan, G. Lai, and Y . Yu, “High-fidelity integrated aerial platform simulation for control, perception, and learning,”IEEE Transactions on Automation Science and Engineering, 2025
work page 2025
-
[17]
Automatic furniture layout with a single image,
H. Fu, M. Gong, C. Wang, K. Batmanghelich, and D. Tao, “Automatic furniture layout with a single image,” inIEEE ICCV, 2017
work page 2017
-
[18]
Synthesizing open worlds with constraints using locally annealed reversible jump mcmc,
Y .-T. Yeh, L. Yang, M. Watson, N. D. Goodman, and P. Hanrahan, “Synthesizing open worlds with constraints using locally annealed reversible jump mcmc,” inToG, 2012
work page 2012
-
[19]
Learning generative models of scene graphs,
S.-H. Zhang, Z. Zhang, J. Wu, S. Tulsiani, and A. X. Chang, “Learning generative models of scene graphs,” inNIPS, 2020
work page 2020
-
[20]
Infinicity: Infinite-scale city synthesis,
C. H. Lin, H.-Y . Lee, W. Menapace, M.-H. Yang, and S. Tulyakov, “Infinicity: Infinite-scale city synthesis,” inICCV, 2023
work page 2023
-
[21]
Citydreamer: Compositional generative model of unbounded 3d cities,
H. Xie, Z. Chen, F. Hong, and Z. Liu, “Citydreamer: Compositional generative model of unbounded 3d cities,” inCVPR, 2024
work page 2024
-
[22]
Atiss: Autoregressive transformers for indoor scene synthesis,
D. Paschalidou, A. Kar, M. Shugrina, A. Geiger, and S. Fidler, “Atiss: Autoregressive transformers for indoor scene synthesis,”NIPS, 2021
work page 2021
-
[23]
Equiv- ariant diffusion for molecule generation in 3d,
E. Hoogeboom, V . G. Satorras, C. Vignac, and M. Welling, “Equiv- ariant diffusion for molecule generation in 3d,” inICLR, 2022
work page 2022
-
[24]
Diffuscene: Denoising diffusion models for generative indoor scene synthesis,
J. Tang, Y . Nie, and M. Nießner, “Diffuscene: Denoising diffusion models for generative indoor scene synthesis,” inCVPR, 2024
work page 2024
-
[25]
Language-driven scene synthesis using multi-conditional diffusion model,
A. D. Vuong, M. N. Vu, T. Nguyen, B. Huang, D. Nguyen, T. V o, and A. Nguyen, “Language-driven scene synthesis using multi-conditional diffusion model,”NeurIPS, 2023
work page 2023
-
[26]
Scenefactor: Factored latent 3d diffusion for controllable 3d scene generation,
A. Bokhovkin, Q. Meng, and A. Dai, “Scenefactor: Factored latent 3d diffusion for controllable 3d scene generation,” inCVPR, 2025
work page 2025
-
[27]
Airsim: High-fidelity visual and physical simulation for autonomous vehicles,
S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” inFSR, 2018
work page 2018
-
[28]
Airs: Aerial indoor robot simulation for navigation,
R. Madaan, H. Zhu, D. Hsu, and W. S. Lee, “Airs: Aerial indoor robot simulation for navigation,” inICRA, 2020
work page 2020
-
[29]
J. Wang and G. Joshi, “Cooperative sgd: A unified framework for the design and analysis of communication-efficient sgd algorithms,” inICLRW, 2018
work page 2018
-
[30]
V oxnet: A 3d convolutional neural network for real-time object recognition,
D. Maturana and S. Scherer, “V oxnet: A 3d convolutional neural network for real-time object recognition,” inIROS, 2015
work page 2015
-
[31]
3d shapenets: A deep representation for volumetric shapes,
Z. Wu, L. Song, Shuranand Zhang, and J. Xiao, “3d shapenets: A deep representation for volumetric shapes,” inCVPR, 2015
work page 2015
-
[32]
Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies,
X. Ren, J. Huang, S. Fidler, and F. Williams, “Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies,” inCVPR, 2024
work page 2024
-
[33]
Instructscene: Instruction-driven 3d indoor scene synthesis with semantic graph prior,
C. Lin and Y . Mu, “Instructscene: Instruction-driven 3d indoor scene synthesis with semantic graph prior,” inICLR, 2024
work page 2024
-
[34]
Nuiscene: Exploring efficient generation of unbounded outdoor scenes,
H.-H. Lee, Q. Han, and A. X. Chang, “Nuiscene: Exploring efficient generation of unbounded outdoor scenes,”arXiv, 2025
work page 2025
-
[35]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inCVPR, 2017
work page 2017
-
[36]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” inNIPS, 2017
work page 2017
-
[37]
3d-front: 3d furnished rooms with layouts and semantics,
H. Fu, B. Cai, L. Gao, L.-X. Zhang, J. Wang, C. Li, Q. Zeng, C. Sun, R. Jia, B. Zhao,et al., “3d-front: 3d furnished rooms with layouts and semantics,” inICCV, 2021
work page 2021
-
[38]
Physcene: Physically inter- actable 3d scene synthesis for embodied ai,
Y . Yang, B. Jia, P. Zhi, and S. Huang, “Physcene: Physically inter- actable 3d scene synthesis for embodied ai,” inCVPR, 2024
work page 2024
-
[39]
Open-fusion: Real-time open-vocabulary 3d mapping and queryable scene representation,
K. Yamazaki, T. Hanyu, K. V o, T. Pham, M. Tran, G. Doretto, A. Nguyen, and N. Le, “Open-fusion: Real-time open-vocabulary 3d mapping and queryable scene representation,” inICRA, 2024
work page 2024
-
[40]
Procthor: Large- scale embodied ai using procedural generation,
M. Deitke, E. VanderBilt, A. Herrasti, L. Weihs, K. Ehsani, J. Salvador, W. Han, E. Kolve, A. Kembhavi, and R. Mottaghi, “Procthor: Large- scale embodied ai using procedural generation,”NIPS, 2022
work page 2022
-
[41]
Dynscene: Scalable generation of dynamic robotic manipulation scenes for embodied ai,
S. Lee and H. Kim, “Dynscene: Scalable generation of dynamic robotic manipulation scenes for embodied ai,” inCVPR, 2025
work page 2025
-
[42]
Architect: Generating vivid and interactive 3d scenes with hierarchical 2d inpainting,
Y . Wang, X. Qiu, J. Liu, Z. Chen, J. Cai, Y . Wang, T.-H. Wang, Z. Xian, and C. Gan, “Architect: Generating vivid and interactive 3d scenes with hierarchical 2d inpainting,”NIPS, 2024
work page 2024
-
[43]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,” inNIPS, 2021
work page 2021
-
[44]
Lightweight language-driven grasp detection using con- ditional consistency model,
N. Nguyen, M. N. Vu, B. Huang, A. Vuong, N. Le, T. V o, and A. Nguyen, “Lightweight language-driven grasp detection using con- ditional consistency model,” inIROS, 2024
work page 2024
-
[45]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inarXiv, 2022
work page 2022
-
[46]
Dreamfusion: Text-to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text-to-3d using 2d diffusion,” inNIPS, 2022
work page 2022
-
[47]
Sdedit: Guided image synthesis and editing with stochastic differential equations,
C. Meng, J. Ho, and S. Ermon, “Sdedit: Guided image synthesis and editing with stochastic differential equations,” inICLR, 2023
work page 2023
-
[48]
Compositional visual genera- tion with energy-based diffusion,
X. Liu, Z. Li, Y . Song, and S. Ermon, “Compositional visual genera- tion with energy-based diffusion,” inNIPS, 2022
work page 2022
-
[49]
Motion guidance for human- scene interaction synthesis with diffusion models,
X. Jiang, F. Yang, W. Xu, and B. Chen, “Motion guidance for human- scene interaction synthesis with diffusion models,” inToG, 2023
work page 2023
-
[50]
Controllable group choreography using contrastive dif- fusion,
N. Le, T. Do, K. Do, H. Nguyen, E. Tjiputra, Q. D. Tran, and A. Nguyen, “Controllable group choreography using contrastive dif- fusion,”TOG, 2023
work page 2023
-
[51]
Zero-1-to-3: Controllable object synthesis with diffusion,
A. Jain, B. Zhang, B. Poole, and P. Abbeel, “Zero-1-to-3: Controllable object synthesis with diffusion,” inNIPS, 2022
work page 2022
-
[52]
Language-driven 6-dof grasp detection using negative prompt guidance,
T. Nguyen, M. N. Vu, B. Huang, A. Vuong, Q. Vuong, N. Le, T. V o, and A. Nguyen, “Language-driven 6-dof grasp detection using negative prompt guidance,” inECCV, 2024
work page 2024
-
[53]
Phyrecon: Physically plausible neural scene reconstruction,
J. Ni, Y . Chen, B. Jing, N. Jiang, S.-C. Zhu, and S. Huang, “Phyrecon: Physically plausible neural scene reconstruction,”NIPS, 2024
work page 2024
-
[54]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”NIPS, 2020
work page 2020
-
[55]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”NIPS, 2017
work page 2017
-
[56]
Vision transformer adapter for dense predictions,
H. Chen, F. Wei, B. Ni, J. Bao, D. Zhang, D. Chen, and B. Guo, “Vision transformer adapter for dense predictions,” inICLR, 2022
work page 2022
-
[57]
Iou loss for 2d/3d object detection,
D. Zhou, J. Fang, X. Song, C. Guan, J. Yin, Y . Dai, and R. Yang, “Iou loss for 2d/3d object detection,” in3DV, 2019
work page 2019
-
[58]
Diffusion-sdf: Conditional genera- tive modeling of signed distance functions,
G. Chou, Y . Bahat, and F. Heide, “Diffusion-sdf: Conditional genera- tive modeling of signed distance functions,” inICCV, 2023
work page 2023
-
[59]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”NIPS, 2017
work page 2017
-
[60]
M. Bi ´nkowski, D. J. Sutherland, M. Arbel, and A. Gretton, “Demys- tifying mmd gans,”arXiv, 2018
work page 2018
-
[61]
A computationally efficient motion primitive for quadrocopter trajectory generation,
M. W. Mueller, M. Hehn, and R. D’Andrea, “A computationally efficient motion primitive for quadrocopter trajectory generation,” Transactions on Robotics, 2015
work page 2015
-
[62]
Geometric tracking control of a quadrotor uav on se (3),
T. Lee, M. Leok, and N. H. McClamroch, “Geometric tracking control of a quadrotor uav on se (3),” inCDC, 2010
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.