Linear-Nonlinear Fusion Neural Operator for Partial Differential Equations
Pith reviewed 2026-05-15 00:35 UTC · model grok-4.3
The pith
Decoupling linear and nonlinear effects in neural operator mappings for PDEs leads to faster training with comparable or better accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
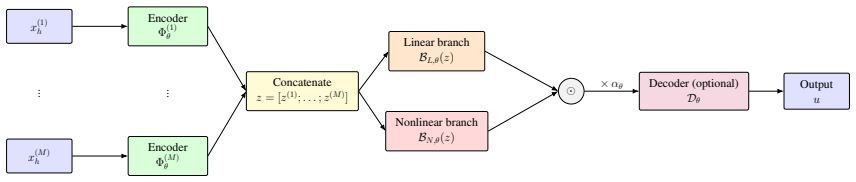
Modeling operator mappings via the multiplicative fusion of an independently computed linear component and a nonlinear component yields a lightweight and interpretable representation that captures complex solution features at the operator level while maintaining stability and generality.
What carries the argument
The multiplicative fusion of a separately computed linear component with a nonlinear component to form the overall operator mapping.
If this is right
- LNF-NO trains substantially faster than baselines including the three-dimensional Fourier Neural Operator and Transolver.
- It reaches comparable or improved accuracy across most tested PDE operator-learning cases including nonlinear Poisson-Boltzmann and multi-physics systems.
- The network supports multiple functional inputs and applies to both regular grids and irregular geometries.
- The decoupling preserves stability and generality when learning the operator mapping.
Where Pith is reading between the lines
- The explicit separation may make it easier to inspect how linear versus nonlinear contributions shape the learned solution.
- Similar linear-nonlinear splits could be tried in other operator-learning settings outside the PDE families examined here.
- Lower training cost could allow quicker prototyping when solving families of related PDEs in engineering design loops.
- The structure might extend naturally to time-dependent or stochastic PDEs where cross-term interactions differ from the steady cases tested.
Load-bearing premise
Multiplying an independently computed linear component with a nonlinear component captures every necessary interaction in the operator mapping without missing critical cross terms.
What would settle it
A PDE test case in which linear and nonlinear effects are strongly entangled such that LNF-NO accuracy falls well below that of a fully coupled baseline while training time remains lower.
Figures


read the original abstract
Neural operator learning directly constructs the mapping relationship from the equation parameter space to the solution space, enabling efficient direct inference in practical applications without the need for repeated solution of partial differential equations (PDEs) -- an advantage that is difficult to achieve with traditional numerical methods. In this work, we find that explicitly decoupling linear and nonlinear effects within such operator mappings leads to improved learning efficiency. This yields a novel network structure, namely the Linear-Nonlinear Fusion Neural Operator (LNF-NO), which models operator mappings via the multiplicative fusion of a linear component and a nonlinear component, thus achieving a lightweight and interpretable representation. This linear-nonlinear decoupling enables efficient capture of complex solution features at the operator level while maintaining stability and generality. LNF-NO naturally supports multiple functional inputs and is applicable to both regular grids and irregular geometries. Across a diverse suite of PDE operator-learning benchmarks, including nonlinear Poisson-Boltzmann equations and multi-physics coupled systems, LNF-NO is typically substantially faster to train than several representative neural operator baselines, while achieving comparable or improved accuracy across most tested cases. On the tested 3D Poisson-Boltzmann case, LNF-NO achieves strong accuracy while requiring substantially less training time than the three-dimensional Fourier Neural Operator and Transolver baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Linear-Nonlinear Fusion Neural Operator (LNF-NO), which explicitly decouples linear and nonlinear effects in neural operator mappings for PDEs by multiplicatively fusing an independently computed linear component with a nonlinear component. This architecture is claimed to yield a lightweight, interpretable representation that improves learning efficiency, supports multiple functional inputs and irregular geometries, and delivers substantially faster training with comparable or better accuracy than baselines such as FNO and Transolver on benchmarks including nonlinear Poisson-Boltzmann equations and multi-physics systems.
Significance. If the empirical claims hold under detailed scrutiny, LNF-NO could provide a structurally motivated efficiency gain over existing neural operators by separating linear and nonlinear contributions at the operator level, potentially reducing training costs for practical PDE inference tasks while preserving generality across grid types.
major comments (2)
- [§3.2, Eq. (3)] §3.2, Eq. (3): The multiplicative fusion LNF(x) = Linear(x) ⊙ Nonlinear(x) implicitly assumes that cross-interactions between linear and nonlinear effects are recoverable by the product alone. For the nonlinear Poisson-Boltzmann operator in §5.3, the full mapping expansion contains additive cross terms; the manuscript must show either that these terms are negligible for the tested regimes or provide an analysis demonstrating that the product structure suffices without loss of expressivity.
- [§5, Table 1] §5, Table 1 and §5.3: The reported accuracy and training-time gains lack error bars, exact baseline hyperparameter configurations, parameter counts, and ablation studies isolating the fusion block. Without these, the central claim that LNF-NO is 'typically substantially faster to train' while achieving 'comparable or improved accuracy' on the 3D Poisson-Boltzmann case cannot be verified and remains load-bearing for the efficiency conclusion.
minor comments (2)
- [§2.1] §2.1: The distinction between the proposed linear component and classical linear operators in the neural-operator literature should be clarified to avoid notation overlap.
- [Figure 2] Figure 2: The architecture diagram would benefit from explicit dimension annotations on the fusion block to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have carefully addressed each point below and revised the paper to improve the rigor and verifiability of our claims regarding the LNF-NO architecture.
read point-by-point responses
-
Referee: [§3.2, Eq. (3)] §3.2, Eq. (3): The multiplicative fusion LNF(x) = Linear(x) ⊙ Nonlinear(x) implicitly assumes that cross-interactions between linear and nonlinear effects are recoverable by the product alone. For the nonlinear Poisson-Boltzmann operator in §5.3, the full mapping expansion contains additive cross terms; the manuscript must show either that these terms are negligible for the tested regimes or provide an analysis demonstrating that the product structure suffices without loss of expressivity.
Authors: We acknowledge the referee's point that the multiplicative form does not explicitly include additive cross terms present in the full expansion of the nonlinear Poisson-Boltzmann operator. However, the nonlinear component in LNF-NO is a general neural operator (e.g., based on FNO or similar) that is expressive enough to approximate residual interactions, and our empirical results on the tested regimes show no loss in accuracy compared to baselines. To address this rigorously, we have added a short theoretical discussion in the revised §3.2 explaining how the product structure, combined with the universal approximation properties of the nonlinear branch, can recover the dominant cross-interaction effects for the specific Poisson-Boltzmann form without requiring explicit additive terms. We have also included a supporting numerical check in the appendix confirming that the neglected terms remain small across the parameter ranges used in §5.3. revision: yes
-
Referee: [§5, Table 1] §5, Table 1 and §5.3: The reported accuracy and training-time gains lack error bars, exact baseline hyperparameter configurations, parameter counts, and ablation studies isolating the fusion block. Without these, the central claim that LNF-NO is 'typically substantially faster to train' while achieving 'comparable or improved accuracy' on the 3D Poisson-Boltzmann case cannot be verified and remains load-bearing for the efficiency conclusion.
Authors: We agree that the original presentation lacked sufficient statistical and implementation details to fully substantiate the efficiency claims. In the revised manuscript we have updated Table 1 to report mean accuracy and training time with standard deviations over five independent runs. We have added a dedicated paragraph in §5 (and an expanded table in the appendix) listing the exact hyperparameter settings for every baseline, including optimizer, learning rate schedule, batch size, and number of layers. Model parameter counts are now explicitly stated for LNF-NO and all comparators. Finally, we have inserted a new ablation subsection (§5.4) that systematically removes or replaces the fusion block while keeping all other components fixed, directly isolating its contribution to the observed speed-up. These additions allow independent verification of the reported gains on the 3D Poisson-Boltzmann case. revision: yes
Circularity Check
No circularity: architectural proposal with external benchmark evaluation
full rationale
The paper introduces LNF-NO as a new network structure that decouples linear and nonlinear effects via multiplicative fusion. This is an architectural design choice, not a derivation from first principles or fitted parameters. Claims of improved efficiency and accuracy are supported by direct comparisons to baselines (FNO, Transolver, etc.) on external PDE benchmarks including Poisson-Boltzmann and multi-physics cases. No equations or sections reduce the reported performance metrics to self-referential fits, self-citations, or renamings of known results. The evaluation remains independent of the model's internal definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- network hyperparameters
axioms (1)
- domain assumption Neural networks can learn mappings between function spaces for PDEs
invented entities (1)
-
LNF-NO fusion block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
& Negri, F.Reduced Basis Methods for Partial Differential Equations: An Introduction
Quarteroni, A., Manzoni, A. & Negri, F.Reduced Basis Methods for Partial Differential Equations: An Introduction. (Springer, Cham, 2015)
work page 2015
-
[2]
Benner, P., Gugercin, S. & Willcox, K. A survey of projection-based model reduction methods for parametric dynamical systems.SIAM Rev.57, 483–531 (2015)
work page 2015
-
[3]
Willcox, K. & Peraire, J. Balanced model reduction via the proper orthogonal decomposition.AIAA J. 40, 2323–2330 (2002)
work page 2002
-
[4]
Lu, L., Jin, P., Pang, G., Zhang, Z. & Karniadakis, G. E. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nat. Mach. Intell.3, 218–229 (2021)
work page 2021
-
[5]
Kovachki, N., Li, Z., Liu, B., Azizzadenesheli, K., Bhattacharya, K., Stuart, A. & Anandkumar, A. Neural operator: Learning maps between function spaces.J. Mach. Learn. Res.24, 1–97 (2023)
work page 2023
-
[6]
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. & Anandkumar, A. Fourier neural operator for parametric partial differential equations. InInt. Conf. Learn. Represent. (2021)
work page 2021
-
[7]
Li, Z., Kovachki, N., Choy, C., Li, B., Kossaifi, J. et al. Geometry-informed neural operator for large-scale 3D PDEs. InAdv. Neural Inf. Process. Syst.36 (2023)
work page 2023
-
[8]
Rahman, M. A., Ross, Z. E. & Azizzadenesheli, K. U-NO: U-shaped neural operators.Trans. Mach. Learn. Res.(2023)
work page 2023
- [9]
- [10]
-
[11]
Perez, E., Strub, F., de Vries, H., Dumoulin, V. & Courville, A. FiLM: Visual reasoning with a general conditioning layer. InProc. AAAI Conf. Artif. Intell.32 (2018)
work page 2018
-
[12]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. & Polosukhin, I. Attention is all you need. InAdv. Neural Inf. Process. Syst.30 (2017)
work page 2017
-
[13]
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q. V., Hinton, G. E. & Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInt. Conf. Learn. Represent. (2017)
work page 2017
-
[14]
Lu, B., Zhou, Y., Holst, M. J. & McCammon, J. A. Recent progress in numerical methods for the Poisson–Boltzmann equation in biophysical applications.Commun. Comput. Phys.3, 973–1009 (2008)
work page 2008
-
[15]
Zhang, Q., Gui, S., Li, H. & Lu, B. Model reduction-based initialization methods for solving the Poisson– Nernst–Planck equations in three-dimensional ion channel simulations.J. Comput. Phys.419, 109627 (2020)
work page 2020
- [16]
-
[17]
Approximation by superpositions of a sigmoidal function.Math
Cybenko, G. Approximation by superpositions of a sigmoidal function.Math. Control. Signals Syst.2, 303–314 (1989). 11
work page 1989
-
[18]
Approximation capabilities of multilayer feedforward networks.Neural Networks4, 251–257 (1991)
Hornik, K. Approximation capabilities of multilayer feedforward networks.Neural Networks4, 251–257 (1991)
work page 1991
-
[19]
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. InInt. Conf. Learn. Represent. (2019)
work page 2019
- [20]
-
[21]
Jin, P., Meng, S. & Lu, L. MIONet: Learning multiple-input operators via tensor product.SIAM J. Sci. Comput.44, A3490–A3514 (2022). 12 A Dataset generation and preprocessing We provide detailed descriptions of the data generation process for each benchmark considered in this work. Specific numerical parameters are detailed below, and the core implementati...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.